Command Palette
Search for a command to run...
LocateAnything:基于并行框解码的快速且高质量视觉-语言定位
LocateAnything:基于并行框解码的快速且高质量视觉-语言定位
摘要
视觉语言模型(VLMs)通常将视觉定位与检测建模为坐标-token生成问题,将每个2D框序列化为多个1D tokens,这些tokens在训练与解码过程中很大程度上相互独立。这种逐token的解码方式与框几何的耦合结构不匹配,并且由于严格的顺序生成机制,造成了实际的推理瓶颈。我们提出LocateAnything,这是一种基于并行框解码(PBD)的统一生成式定位与检测框架。通过将边界框和点等几何元素作为原子单元在单步内完成解码,LocateAnything保留了框内几何一致性,并释放了显著的并行计算能力。实验表明,PBD同时提升了解码吞吐量与定位精度。我们进一步开发了一套可扩展的数据引擎,并构建了LocateAnything-Data数据集,该数据集包含超过1.38亿个训练样本,大幅提升了高精度定位任务的数据多样性。广泛的评估结果表明,LocateAnything推动了速度-精度前沿的发展,在多项基准测试中实现了显著更高的解码吞吐量,同时提升了高IoU定位质量。研究结果凸显了并行框解码与大规模训练数据在实现高效且精确的统一视觉定位与检测方面的互补优势。
一句话总结
作者提出了 LocateAnything,这是一种统一的生成式视觉定位与检测框架。该框架采用并行框解码(Parallel Box Decoding)取代串行 token 解码,将边界框作为原子单元在单步中处理,从而保持几何一致性并实现高度并行化。配合包含 1.38 亿样本的 LocateAnything-Data 数据集,该方法通过提升解码吞吐量及改善多基准测试下的高 IoU 定位精度,推动了速度与精度的前沿发展。
核心贡献
- 提出 LocateAnything,一种统一的视觉定位与检测框架,采用并行框解码(PBD)取代顺序坐标 token 生成,将边界框或点作为原子单元在单步并行中预测。
- 保持框内几何一致性,并支持灵活的推理流水线,可动态选择并行、自回归或混合解码模式,以平衡计算吞吐量与输出稳定性。
- 在多种基准测试中展现出最先进的定位精度及最高 2.5 倍的推理加速效果。该成果得益于 LocateAnything-Data,这是一个通过可扩展数据引擎精心构建的、包含超过 1.38 亿个训练样本的大规模数据集。
引言
视觉语言模型正迅速成为交互式与具身系统的主流骨干网络,然而它们需要精确且低延迟的空间定位能力,才能可靠地将自然语言转化为可执行指令。现有的定位方法通常将二维坐标序列化为一维 token 流,并依赖自回归的下一个 token 预测,这造成了严重的吞吐量瓶颈。试图通过多 token 预测实现解码并行化的尝试往往忽略了空间坐标固有的几何耦合关系,容易生成虚假关联和不稳定的输出。作者利用并行框解码重构视觉定位任务,将完整的边界框视为原子预测单元。这种结构对齐实现了坐标的同时生成,在保持最先进精度的同时,实现了最高 2.5 倍的加速效果。该框架进一步引入了灵活的推理模式,以在实际部署中平衡吞吐量与可靠性。
数据集

• 数据集构成与来源 作者构建了 LocateAnything-Data,这是一个包含 1200 万张独立图像、1.38 亿条自然语言查询及 7.85 亿个标注边界框的大规模语料库。该集合整合了高质量开源检测与定位基准数据集,包括 Flickr30k Entities、gRefCOCO、RefCOCO、HumanPart、HumanRef、OpenImages 和 Objects365。此外,它还整合了图形用户界面数据集、专用的指代表达理解语料库,以及来自 Unsplash 和 SA-1B 的大量未标注图像。
• 子集划分与关键细节 数据集围绕六种不同的定位任务进行构建,每种任务均保持特定的比例与特征:
- 通用目标检测:占查询量的 66.9% 和边界框的 83.1%,奠定核心空间对齐基础。
- GUI 元素定位:占查询量的 16.5%,针对界面导航与具身 agent 工作流进行优化。
- 指代表达理解:占查询量的 7.3%,旨在将复杂的语言描述与精确的空间区域关联。
- 文本定位:占查询量的 3.6%,专注于将图像中的可见文本进行精确锚定。
- 文档与场景布局定位:占查询量的 3.5%,增强结构推理能力。
- 基于点的定位:占查询量的 2.2%,优化细粒度空间预测。 该语料库还跨所有领域整合了超过 2200 万条显式构建的负样本,以防止模型产生幻觉,查询与负样本的比例已根据各领域统计数据进行校准。每个查询的目标数量遵循长尾分布,查询长度差异显著,以反映多样化的语言定位范式。
• 数据处理与合成流水线 作者对所有原始数据源应用统一的格式清洗与标准化处理。针对 GroundCUA 界面数据集,团队实施了定向裁剪与数据增强策略。他们在原始截图上渲染每个真实边界框,围绕其裁剪局部区域,并将完整截图与裁剪后的图像块连同标签、类别及平台元数据一同输入 Qwen3-VL。随后,模型从外观、空间定位和功能意图三个角度生成丰富且多维度的查询文本。 为扩展多目标定位的覆盖范围,团队部署了自动化数据引擎。对于带标签的检测数据集,类别提示词被发送至 Qwen3-VL 以合成详细的以物体为中心的查询文本,进而引导 Molmo 预测候选点。仅保留落在已知真实边界框内的点作为可靠的监督信号。对于未标注图像,Qwen3-VL 直接生成多样化的自然语言提示词,这些提示词要么触发 Molmo 随后结合 SAM 3 生成边界框,要么直接调用 Rex-Omni 进行框预测。所有合成生成的边界框均经过 Qwen3-VL 的后验证,以过滤不一致的预测结果。
• 训练使用与混合策略 处理后的数据集作为 LocateAnything 模型的主要训练语料库。作者根据自然比例混合这六个领域子集,保持 66.9% 通用检测、16.5% GUI、7.3% 指代表达、3.6% 文本定位、3.5% 布局定位和 2.2% 基于点定位的混合比例。该构成提供了密集的多领域监督信号,使模型能够学习精确的坐标对齐,处理异构视觉场景,并在不存在有效目标时果断放弃定位。
实验
评估涵盖了一套全面的基准测试,包括目标检测、指代表达理解、GUI 与文档定位以及 OCR,旨在验证模型在不同视觉语境下的空间推理与定位能力。主要结果与消融实验证实,与传统的生成方法相比,所提出的并行框解码架构与多 token 预测公式显著提升了几何精度与推理吞吐量。定性分析进一步证明了该框架在处理复杂组合查询时的鲁棒性,能够在密集或遮挡场景中保持准确的实例分离,并通过灵活的解码策略有效平衡速度与精度。最终,这些发现确立了该方法作为统一视觉定位与检测任务的高效且具备强泛化能力的解决方案。
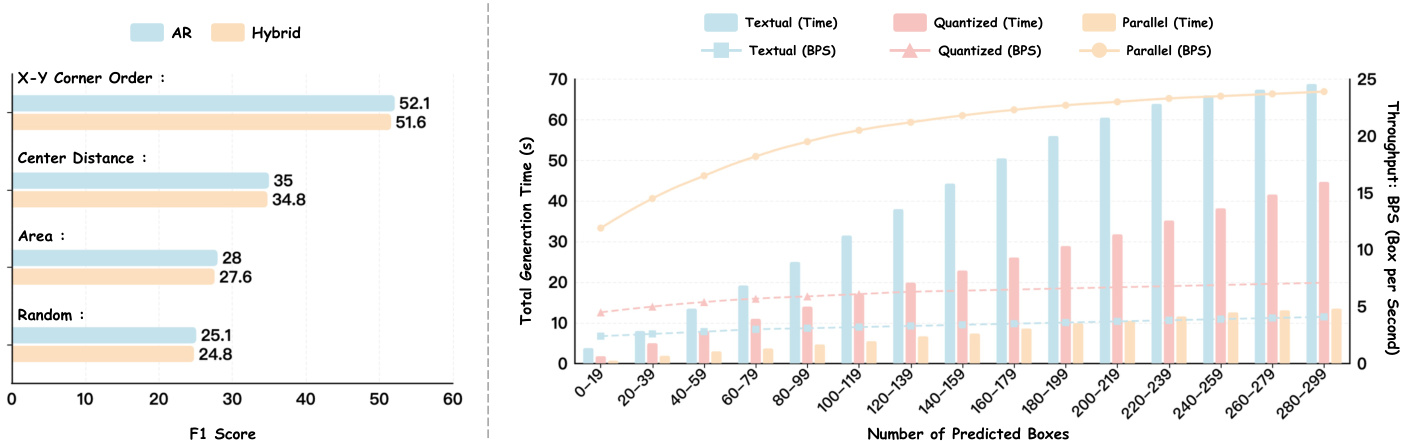
作者分析了不同框排序策略与解码方法对模型性能的影响。左侧图表显示,在测试的排序方法中,XY 角点顺序取得了最高的 F1 分数;右侧图表表明,与文本和量化方法相比,并行解码显著缩短了生成时间并提高了吞吐量,尤其是在预测框数量增加时更为明显。XY 角点顺序在测试的框排序策略中表现最佳。并行解码相比文本和量化方法降低了生成时间并提升了吞吐量。随着预测框数量的增加,并行解码带来的吞吐量提升效果更加显著。
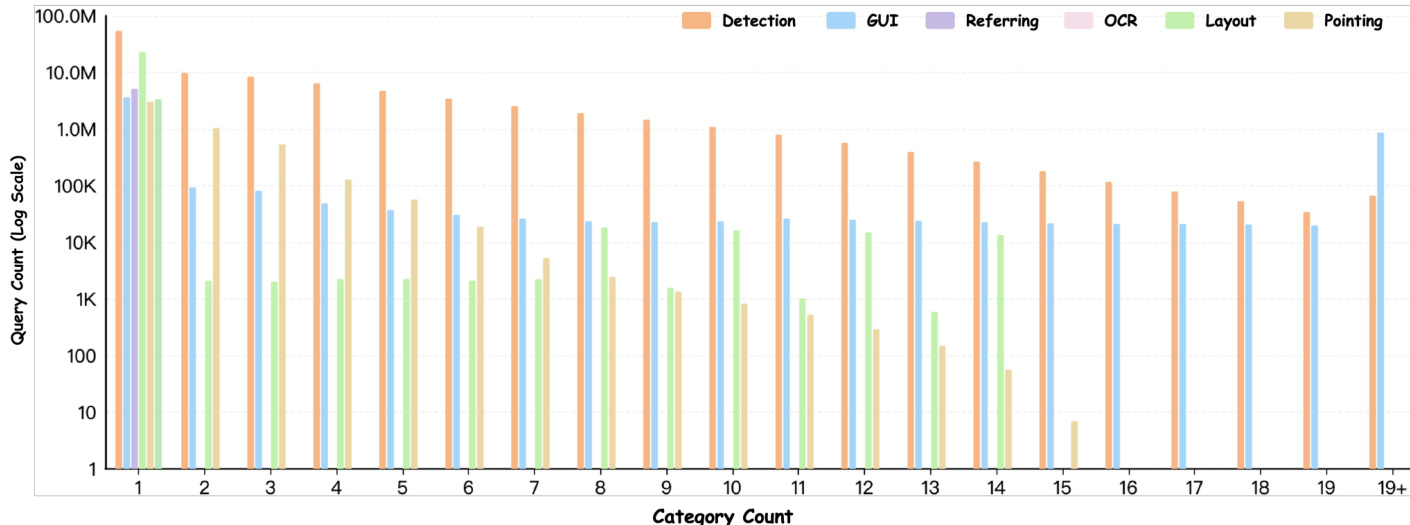
作者分析了不同任务类别与物体实例数量下的查询量分布,结果表明检测任务在查询总量与单图物体实例数上均占据主导地位。数据呈现出一致的模式:与检测相关的查询频率显著高于其他任务,且随着单图物体数量的增加,查询量总体呈下降趋势,其中单实例物体的查询量最高。在所有物体实例数量区间内,检测任务均占据查询量的绝大多数。随着单图物体数量增加,查询量下降,单实例物体出现频率最高。GUI、指代表达、OCR、布局和指点等其他任务的查询量均显著低于检测任务。
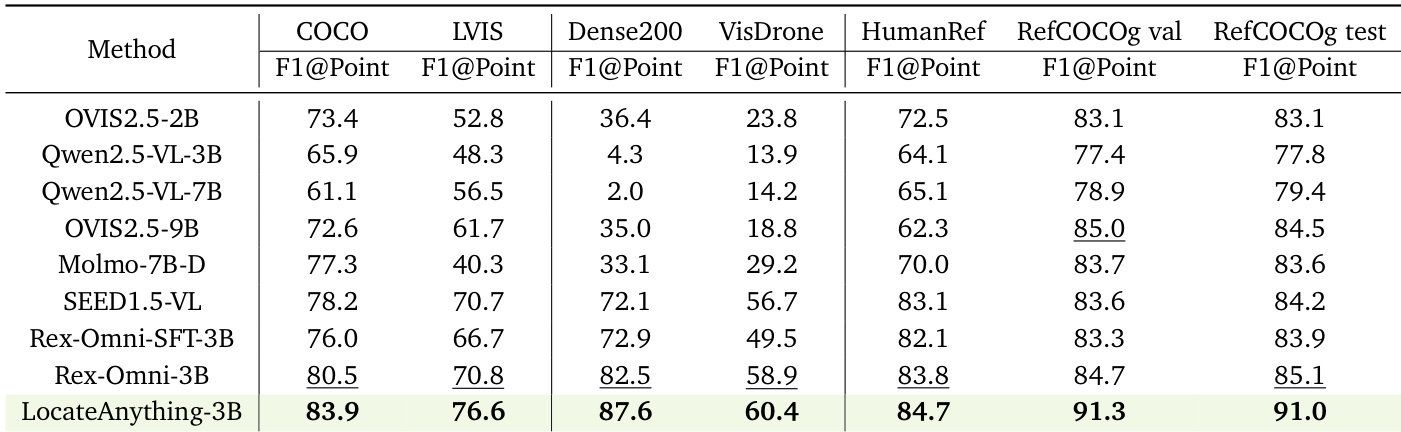
作者在对多个基准测试(包括密集目标检测、语言感知定位及基于点的定位任务)上评估了 LocateAnything-3B。该模型在多种场景下均展现出强劲性能,尤其在密集与复杂环境中表现突出,同时实现了较高的解码速度。结果表明,LocateAnything 在精度与效率方面优于多项最先进模型。与现有模型相比,LocateAnything 在密集检测与语言感知定位基准上取得更优表现。该模型展现出极高的解码速度,在吞吐量方面显著超越基于文本的方法。在面对密集目标检测与复杂指代表达等挑战性场景时,LocateAnything 表现出稳健的定位精度。
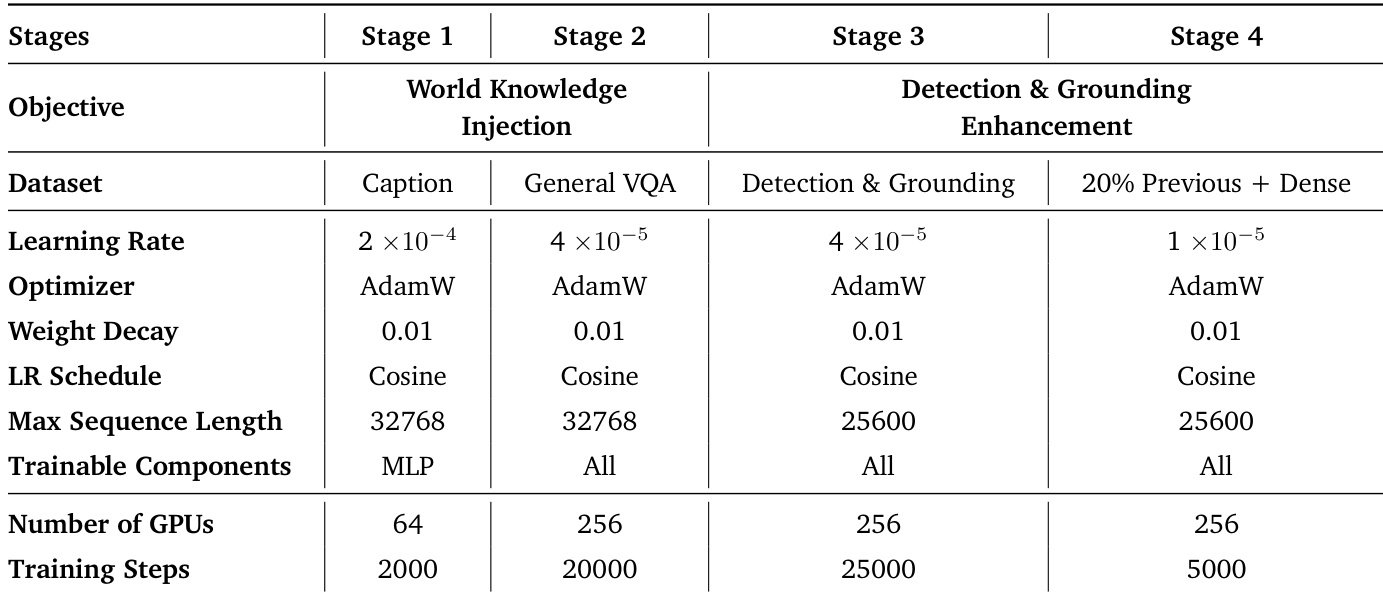
{"summary": "该表格概述了视觉语言模型的多阶段训练流程,从世界知识对齐开始,逐步推进至专注于检测与定位增强的阶段。每个阶段使用不同的数据集与配置,在训练步骤与计算资源方面呈现出复杂度与规模的递增。", "highlights": ["训练流程包含四个阶段,从世界知识对齐开始,随后转向检测与定位增强。", "学习率与优化器等训练参数在各阶段保持一致,而序列长度与训练步骤在后期阶段显著增加。", "各阶段使用的 GPU 数量有所不同,在检测与定位增强阶段使用的数量最多。"]}
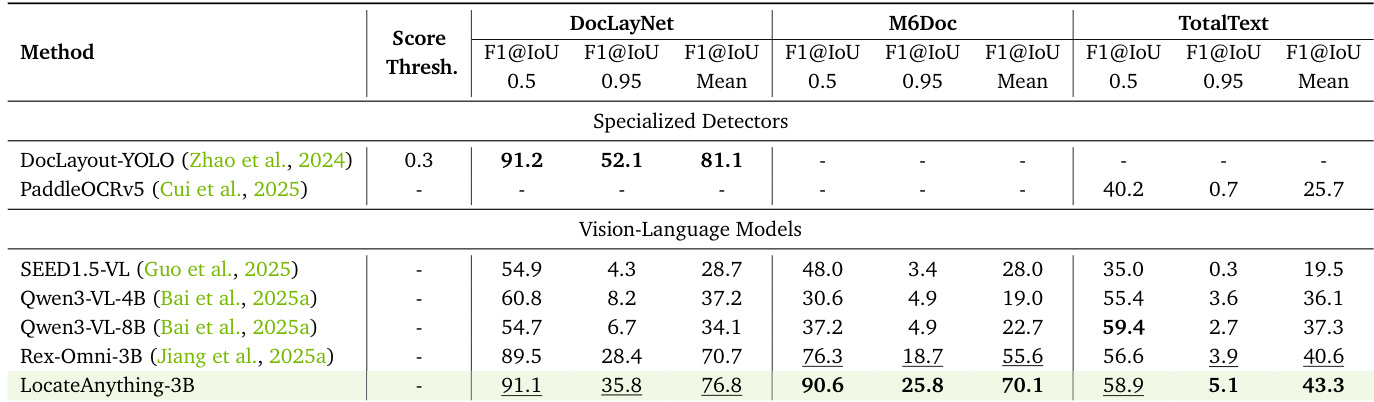
该表格展示了多种模型在多个基准测试上文档布局定位与 OCR 任务的对比结果。LocateAnything-3B 在大多数指标上取得最高分数,尤其在 DocLayNet 和 M6Doc 数据集的 F1@IoU 0.5 与 F1@IoU 0.95 指标上表现卓越,彰显了其在精确空间定位方面的强大能力。结果表明,LocateAnything 在密集且结构化的文档场景中,性能优于专用检测器与视觉语言模型。LocateAnything-3B 在 DocLayNet 和 M6Doc 上取得最高 F1 分数,超越了专用检测器及其他视觉语言模型。该模型在高 IoU 与低 IoU 阈值下均表现强劲,印证了其定位的精确性与鲁棒性。在 OCR 任务中,LocateAnything-3B 超越了 Rex-Omni 及其他 VLM,展现出在文档理解方面更优的边界界定与实例分离能力。
实验评估考察了架构选择、真实世界查询分布及标准化基准测试,以验证 LocateAnything-3B 的设计与性能。对内部组件的初步测试证实,优化的框排序与并行解码显著提升了预测精度与计算吞吐量。使用模式分析揭示了对检测任务的主导依赖,这直接指导了模型以定位与空间推理为核心的渐进式训练流水线。在密集检测、语言感知定位及文档理解方面的最终基准测试表明,该架构持续优于现有模型,提供了更优越的定位精度与应对复杂场景的稳健处理能力。