Command Palette
Search for a command to run...
ECHO:终端代理免费学习世界模型
ECHO:终端代理免费学习世界模型
Vaishnavi Shrivastava Piero Kauffmann Ahmed Awadallah Dimitris Papailiopoulos
摘要
CLI Agent 是语言模型最接近具身智能(embodied setting)的场景:模型发出命令,终端执行这些命令,而返回的数据流——包括标准输入(stdin)、错误信息、文件内容、日志及追踪记录——则记录了执行后果。我们认为,这种返回流本质上是一种监督信号,但标准的 Agent 强化学习方法(RL)却丢弃了它:GRPO 风格的训练仅基于稀疏的结果级奖励更新动作 token,而忽略了 rollout 中已经存在的环境响应。尽管失败的经验回放(rollouts)包含了关于环境如何响应的丰富证据,但由于缺乏环境反馈,它们提供的策略梯度信号微乎其微。为此,我们引入了 ECHO(Environment Cross-entropy Hybrid Objective,环境交叉熵混合目标)。这是一种混合目标函数,它将动作 token 上的标准策略梯度损失与辅助损失相结合,辅助损失旨在训练策略模型预测由其自身动作引发的环境观测 token。ECHO 复用了 GRPO 的前向传播过程,无需额外的 rollout,并将终端反馈转化为针对所有 rollout 的密集监督信号。在 TerminalBench-2.0 上,ECHO 使 GRPO 的 pass@1 性能翻倍:Qwen3-8B 从 2.70% 提升至 5.17%,Qwen3-14B 从 5.17% 提升至 10.79%。此外,ECHO 生成的策略能更好地预测终端动态,即使是在其未生成的轨迹上也是如此:在未参与训练的 hold-out rollout 中,ECHO 显著降低了环境 token 的交叉熵,而仅使用 GRPO 时该指标几乎未发生变化。
一句话总结
ECHO(Environment Cross-entropy Hybrid Objective)使终端 Agent 能够通过结合标准策略梯度损失与预测环境观察 token 的辅助损失来学习世界模型,将终端反馈转化为密集监督而无需额外 rollout,使 Qwen3-8B 在 TerminalBench-2.0 上的 GRPO pass@1 从 2.70% 提升至 5.17%,Qwen3-14B 从 5.17% 提升至 10.79%,同时在保留 rollout 上降低了环境 token 交叉熵。
核心贡献
- 本研究提出了 ECHO,一种用于 CLI Agent 的混合目标,结合标准策略梯度损失与预测结果环境观察 token 的辅助损失。该方法重用与 GRPO 相同的前向传播,无需额外 rollout,有效地将终端反馈转化为所有轨迹的密集监督。
- 与依赖评估器或独立世界建模阶段的方法不同,所提出的方法直接将观察预测注入到 on-policy GRPO 中,使用原始环境观察 token。这种设计消除了对独立语料库或动力学模型的需求,同时利用现有的对话记录数据作为上下文。
- 在 TerminalBench-2.0 上的评估显示,ECHO 使 GRPO pass@1 分数翻倍,将 Qwen3-14B 从 5.17% 提升至 10.79%。训练后的策略也能更好地预测终端动力学,与单独使用 GRPO 相比,在保留 rollout 上显著降低了环境 token 交叉熵。
引言
在由大型语言模型驱动的终端 Agent 背景下,学习有效策略通常受到环境交互期间稀疏奖励信号的阻碍。先前的方法尝试通过辅助预测或世界模型来密集化学习,但它们通常依赖独立的训练阶段、外部评估器或复杂的动力学模型来生成必要的监督。作者利用 Agent 对话记录中已有的终端观察,将辅助交叉熵损失直接注入到 on-policy GRPO 中。该策略消除了对独立语料库或反馈生成器的需求,同时提供直接源自环境字面响应的密集监督。
数据集
-
数据集组成与来源
- 作者从 Endless Terminals 和 OpenThoughts-Agent-v1-RL 中构建了包含 2700 个精选终端任务的训练语料库。
- 他们通过修改后的 Endless Terminals 流程生成了 6170 个额外任务以扩展此池。
- 最终集合包含 8870 个专注于数据处理、系统操作和开发工具的任务。
-
过滤与选择标准
- 初始过滤排除了涉及分析、计算、专用应用、基础设施、网络化和复杂 bash 的领域。
- 仅当 GPT-5 在至少 16 次尝试中的某一次内解决任务时,才保留该任务。
-
数据划分与使用
- 训练集包含 8770 个用于模型优化的任务。
- 单独保留 100 个任务用于分布内验证,命名为 val100。
- 评估基准包括 TerminalBench-2.0 和 OpenThoughts-TBLite 以及内部集合。
-
环境与处理细节
- 回合在由 Harbor 框架编排的 Docker 容器中运行。
- 限制设置为每回合 16 轮,16k 上下文窗口。
- 验证使用单元测试,Agent 超时 10 分钟,验证器超时 2 分钟。
- 该流程处理任务规范、Dockerfile 生成和 Harbor 格式导出。
方法
ECHO 方法引入了一种混合目标,旨在利用环境反馈作为终端 Agent 强化学习期间的密集监督信号。标准训练流程通常仅对助手动作 token 应用损失函数,忽略了终端响应中包含的丰富信息。ECHO 通过添加环境观察 token 上的辅助交叉熵损失来增强此过程。
训练框架在交错系统提示、用户任务、助手动作和环境观察的多轮 rollout 序列上运行。策略根据先前对话记录生成动作,环境则响应输出,如 stdout、stderr 或文件内容。如下面的框架图所示:
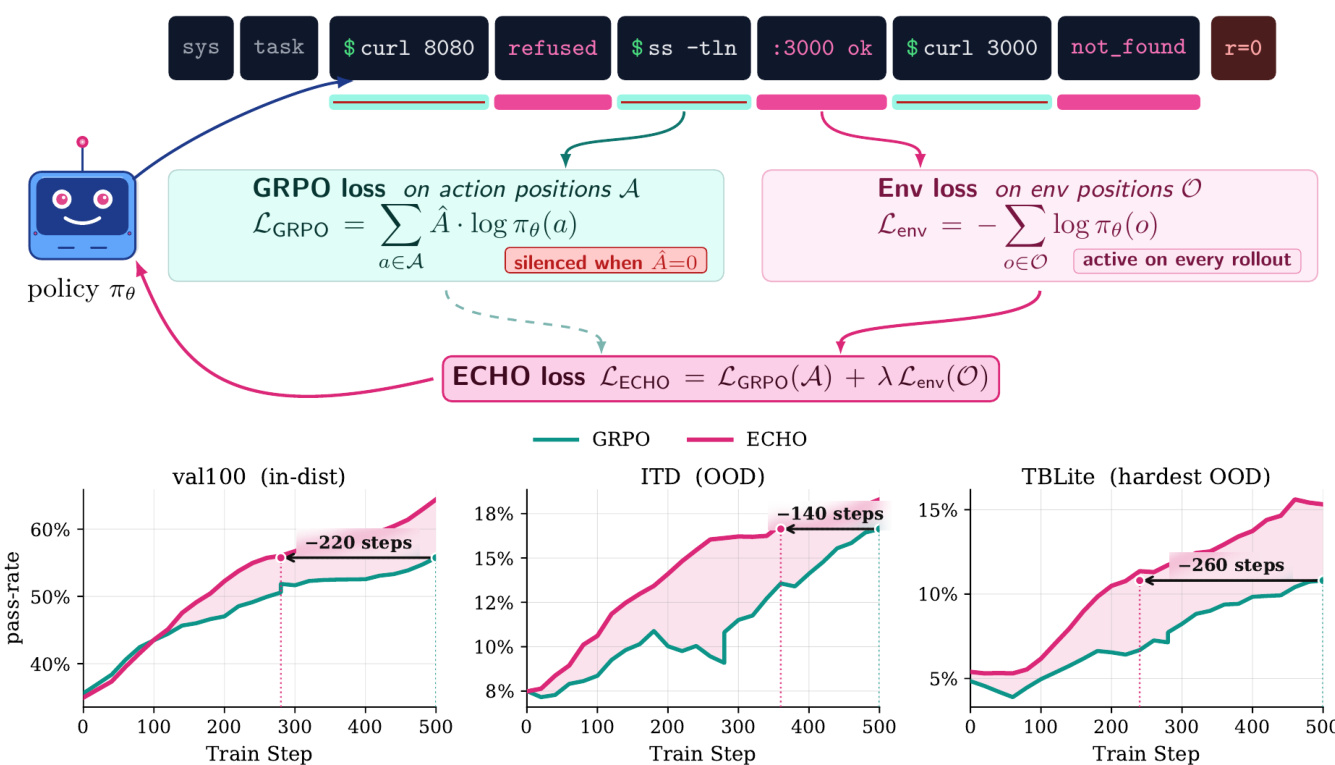
总损失函数结合了标准策略梯度项与环境预测项。GRPO 组件针对动作位置 A,并依赖源自稀疏结果奖励的组归一化优势。当优势为零时,该项被静音。同时,环境损失针对观察位置 O,并训练策略预测其动作导致的终端输出。该组件在每次 rollout 上保持活动。组合目标定义为:
LECHO=LGRPO(A)+λLenv(O)其中 λ 是混合系数。此公式确保失败的 rollout 仍有助于学习,通过教导模型终端如何响应特定命令。
从实现角度来看,该方法通过重用相同的前向传播来保持计算效率。模型一次计算整个序列的 logits。然后训练循环应用不同的掩码到这些 logits 以计算相应的损失项。这种方法避免了对额外 rollout 或独立教师模型的需求。关于目标选择,该方法特别排除了测试框架中的低熵警告 token,将环境损失集中在提供特定任务反馈的实际命令输出上。
实验
实验评估了 ECHO 与 GRPO 基线和专家 SFT 初始化在多个基准上的表现,以验证终端交互和学习效率的改进。结果表明,ECHO 通过学习可迁移的动力学,一致地提高了任务成功率和终端预测准确率,这减少了对专家演示的依赖,同时实现了更快的训练收敛。此外,无验证器适应测试证实,仅环境预测即可在具有信息丰富反馈的任务上推动策略改进,支持了 Agent 可以在没有显式奖励信号的情况下从终端后果中有效学习的结论。
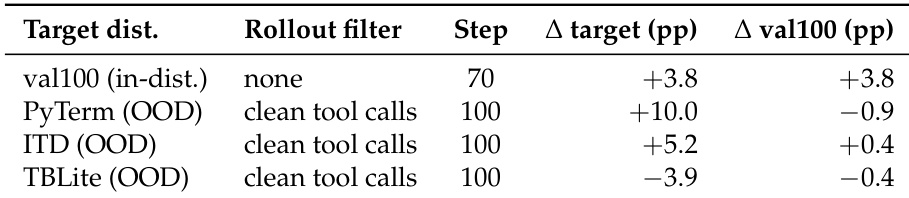
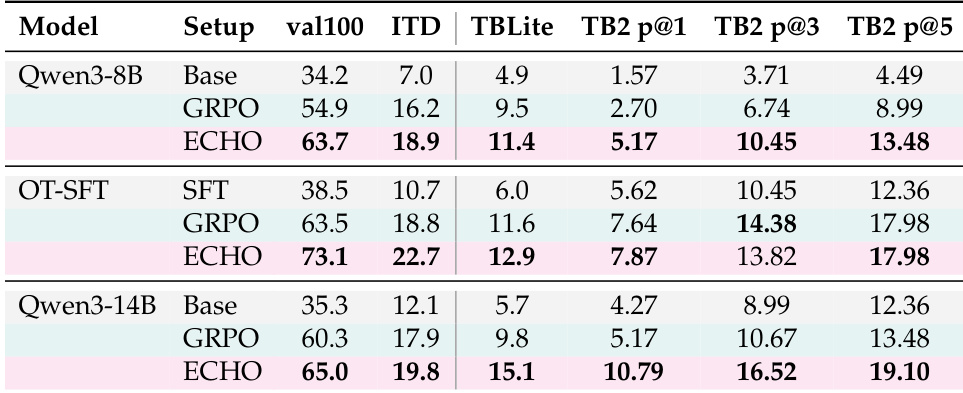
该表格通过比较 ECHO 和 GRPO 在不同模型配置下达到最佳内部分数所需的步数来评估训练效率。ECHO 在 Qwen3-8B 模型上显示出显著的速度优势,在聚合和困难的分布外任务上比 GRPO 基线收敛快得多。相比之下,较大的 Qwen3-14B 模型没有显示出基于步数的加速,两种方法在同一训练步数达到峰值性能。ECHO 显著加速了 Qwen3-8B 模型的训练,在比 GRPO 少得多的步数内达到峰值性能。虽然 OT-SFT 初始化在聚合指标上受益于 ECHO,但在特定的 TBLite 基准上比 GRPO 收敛慢。对于 Qwen3-14B 模型,ECHO 和 GRPO 在相同的步数计数下达到最佳内部分数,表明较大模型的收敛速度进入平台期。
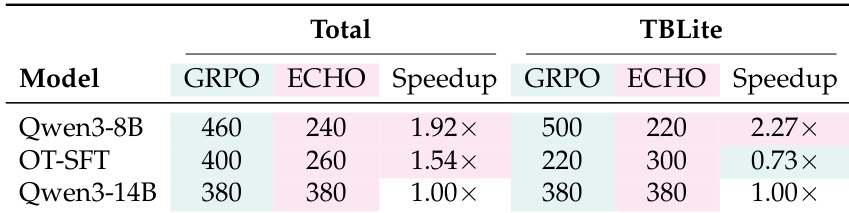
研究团队评估了无验证器适应,其中模型仅通过预测终端输出 token 进行学习,无需奖励信号。结果表明,当过滤干净的工具调用时,这种方法成功提高了分布内任务和特定分布外基准(如 PyTerm 和 ITD)的性能。然而,该方法未能提高 TBLite 基准的性能,表明有效性取决于环境反馈的密度和动作链接。无验证器适应仅使用环境预测提高了分布内性能。过滤干净的工具调用使得在 PyTerm 和 ITD 等分布外任务上获得显著提升,同时不降低基础性能。该方法在 TBLite 上降低了性能,可能是由于与其他基准相比,直接动作反馈链接较少。
该表格比较了使用标准 GRPO、提出的 ECHO 方法和专家 SFT 初始化的 Qwen3-8B 模型的性能。结果表明,ECHO 在所有内部和外部基准上一致地优于标准 GRPO 基线。此外,ECHO 显著缩小了相对于专家 SFT 模型的性能差距,在内部评估中恢复了大部分优势,在外部基准上恢复了约一半。ECHO 在所有内部和外部基准上一致地优于标准 GRPO 基线。该方法在内部评估中恢复了专家 SFT 初始化提供的几乎所有性能优势。ECHO 在 TerminalBench-2.0 指标上缩小了约一半的专家 SFT 性能差距。
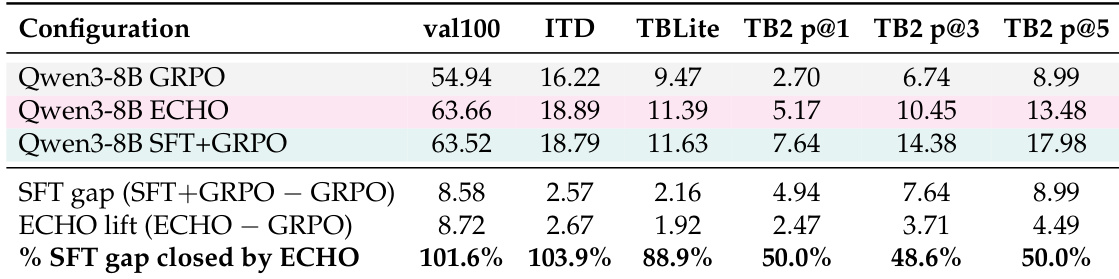
作者展示了结果显示,ECHO 方法在多种模型大小上始终优于基础策略和 GRPO 基线的任务成功率。ECHO 在 TerminalBench-2.0 和内部评估上取得了显著提升,在内部指标上匹配了专家 SFT 初始化的性能,而无需专家演示。ECHO 在所有内部评估和 TerminalBench-2.0 基准上始终优于 GRPO 和基础模型。与标准 GRPO 基线相比,该方法使 TerminalBench-2.0 pass@1 率几乎翻倍。ECHO 在内部评估中恢复了专家 SFT 初始化提供的几乎所有性能增益。
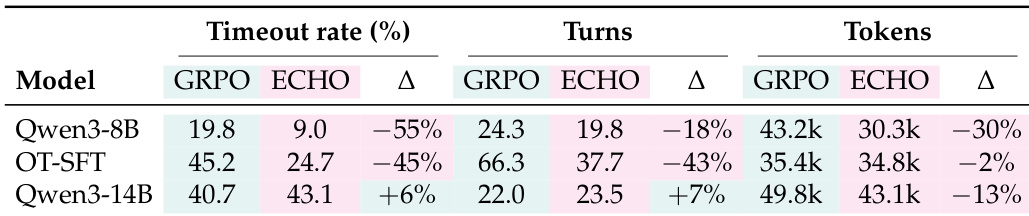
作者比较了 GRPO 基线和 ECHO 方法在不同模型配置下的推理效率指标,包括超时率、轮数和 token。结果表明,ECHO 通常通过减少超时和 token 使用来提高效率,特别是对于较小和 SFT 初始化的模型。与 GRPO 基线相比,ECHO 显著降低了 Qwen3-8B 和 OT-SFT 模型的超时率和平均轮数。所有模型变体的 token 消耗均减少,其中 Qwen3-8B 配置下降最明显。虽然 Qwen3-14B 模型经历了超时和轮数的轻微增加,但仍实现了总 token 使用量的减少。
实验评估了 ECHO 方法与 GRPO 基线和专家 SFT 初始化,以评估训练效率、任务性能和推理指标。ECHO 在所有内部和外部基准上一致地优于标准 GRPO,同时在内部评估中恢复了专家 SFT 提供的性能优势的大部分,而无需专家演示。虽然训练收敛在较小模型上加速,并且通过减少 token 使用提高了推理效率,但无验证器适应在特定分布外任务上显示出有效性,但在动作反馈链接较弱的情况下表现不佳。