Command Palette
Search for a command to run...
DVAO:用于多奖励强化学习的动态方差自适应优势优化
DVAO:用于多奖励强化学习的动态方差自适应优势优化
Guochao Jiang Jingyi Song Guofeng Quan Chuzhan Hao Guohua Liu Yuewei Zhang
摘要
强化学习已成为将大型语言模型与人类意图及任务需求对齐的标准范式。尽管组相对策略优化(Group Relative Policy Optimization)提供了比近端策略优化(Proximal Policy Optimization)更高效、无需价值模型的替代方案,但将其适应于现实世界中的多奖励设置仍面临挑战。标准的标量化实践,如奖励组合(Reward Combination)和优势组合(Advantage Combination),存在显著缺陷:奖励组合经常生成平方幅度过大的优势,导致训练不稳定;而优势组合则依赖于静态超参数,并忽略了跨目标的相关性。为了解决这些局限性,我们提出了动态方差自适应优势优化(Dynamic Variance-adaptive Advantage Optimization, DVAO),该方法根据滚动组(rollout group)中每个目标的经验奖励方差动态调整组合权重,从而有效增强具有更强学习信号的目标的权重,同时抑制噪声目标。我们从数学上证明了 DVAO 能够保持有界的优势幅值以确保训练稳定,并引入了一种自适应性跨目标正则化机制。在 Qwen3 和 Qwen2.5 模型上的数学推理和工具使用基准测试中的大量实验表明,DVAO 显著优于基线方法,实现了更优的多目标帕累托前沿和稳健的训练稳定性。
一句话总结
动态方差自适应优势优化(DVAO)是一种多奖励强化学习方法,该方法利用经验奖励方差动态调整优势组合权重以稳定训练过程,引入自适应性跨目标正则化机制,并保证优势幅度有界,从而在使用 Qwen3 和 Qwen2.5 模型的数学推理与工具使用基准测试中,实现了更优的多目标帕累托前沿与鲁棒稳定性。
核心贡献
- 本文提出了动态方差自适应优势优化(DVAO),这是一种多奖励 GRPO 框架,能够基于 rollout 组内的经验奖励方差动态调整组合权重,从而优先强化具有更强学习信号的目标。
- 该方法在数学上保证了优势幅度有界,以防止训练不稳定,并使用自适应性跨目标正则化机制替代了静态标量化方法,从而消除了对手动超参数调整的依赖。
- 在数学推理与工具使用基准测试中,基于 Qwen3 和 Qwen2.5 模型的大量实验表明,该框架显著优于标准基线方法,同时实现了更优的多目标帕累托前沿与鲁棒的训练稳定性。
引言
强化学习已成为使大语言模型符合实际需求的标准化方法,然而实际部署要求同时优化多个相互竞争的目标,例如准确率、响应长度与工具使用格式。尽管组相对策略优化提供了一种高效且无需价值模型的训练流水线,但将其适配至多奖励场景仍具挑战性。现有的标量化方法要么因优势幅度爆炸而引发训练不稳定,要么依赖固定超参数,无法捕捉不同目标之间的交互关系。本文利用动态方差自适应加权机制来解决这些瓶颈,具体做法是根据每个 rollout 组内的经验奖励方差对组合权重进行缩放。该方法能够自动放大高信号目标并抑制噪声,在数学上保证优势幅度有界以实现稳定收敛,同时引入隐式跨目标正则化机制,彻底摆脱对手动超参数调整的依赖。
方法
本文基于多奖励强化学习的策略优化框架,聚焦现有标量化方法(奖励组合与优势组合)的局限性,并提出一种名为动态方差自适应优势优化(DVAO)的新方法。该方法通过根据每个 rollout 组内个体奖励的经验方差动态调整其权重,有效解决了奖励组合中的幅度爆炸问题以及优势组合中目标相互孤立的问题。
在奖励组合方法中,总奖励被计算为个体奖励的加权和,优势值则通过对 rollout 组内的累积奖励进行归一化得到。该方法会导致优势值幅度过大,进而可能引发策略更新不稳定。相比之下,优势组合方法计算归一化优势的凸组合,虽能降低优势信号的幅度,却未能考虑目标间的相关性,且依赖固定权重,限制了训练过程中的适应性。
为克服上述局限,DVAO 方法引入了动态且方差自适应的权重,以数据驱动的方式进行调整。具体而言,权重定义为 w~k=∑lwlσliwkσki,其中 σki 表示针对给定查询 xi 的 rollout 组中第 k 个奖励的标准差。该公式提高了高方差目标的权重,这类目标通常对应信息量更大或更具挑战性的任务;同时降低低方差目标的权重,此类目标可能代表稳定或易受噪声干扰的信号。计算得到的 DVAO 优势值公式如下:
ADVAO(i,j)=k∑w~kAk(i,j)=∑lwlσli∑kwkσkiAk(i,j).
如图下方所示,DVAO 框架将该自适应加权机制融入策略梯度计算中,使用方差感知机制替代了标准优势组合方法中的固定凸组合,从而动态调节每个目标的贡献度。
DVAO 的核心理论优势在于其能够在保留跨目标交互关系的同时,平衡优势信号的幅度。命题 2 证明,DVAO 优势幅度严格受限于奖励组合优势,从而确保策略更新保持稳定,且不会受到梯度过大的影响。该效果通过利用每个奖励的方差来缩放其影响力来实现,从而有效正则化学习过程。
此外,组合优势对个体奖励的敏感性揭示了 DVAO 与标准优势组合方法之间的根本差异。对于优势组合方法,组合优势关于第 k 个原始奖励的偏导数仅依赖于独立优势 Ak(i,j),即将各目标视为相互独立。相比之下,DVAO 的敏感性包含交叉项 ADVAO(i,j)Ak(i,j),该交叉项将第 k 个目标的梯度贡献与整体多目标性能耦合在一起。这种依赖关系使 DVAO 能够根据模型的全局性能自适应调节学习信号,促进跨目标的协同对齐,并防止对单一奖励的过度优化。个体性能与整体性能之间的动态交互确保了策略能够以上下文感知的方式学习如何平衡多个目标。
实验
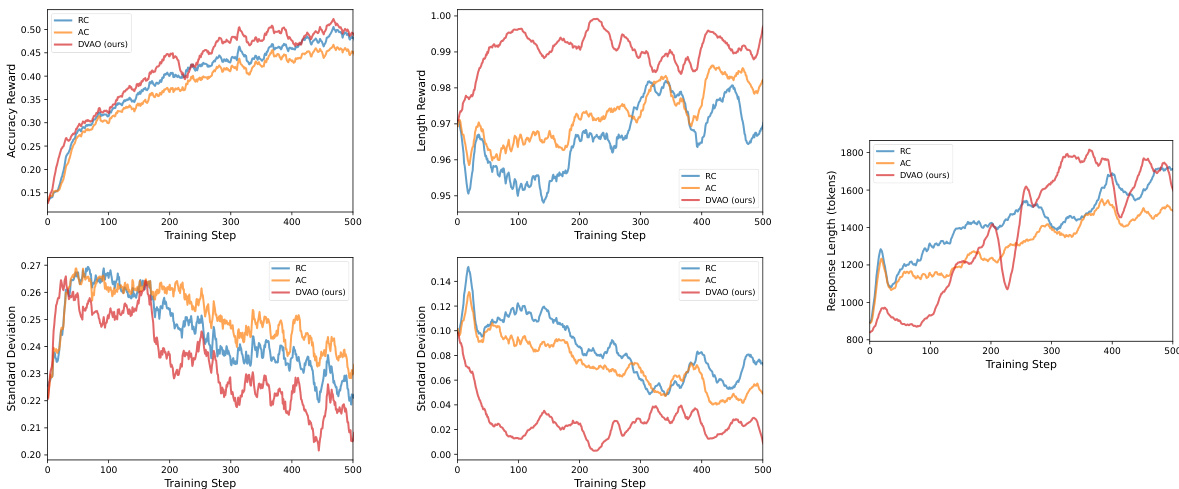
该评估在数学推理与工具使用基准上检验 DVAO,验证其在多种模型规模下同步优化准确率以及输出长度、格式合规性等次要约束的能力。主要结果表明,DVAO 通过在两个目标上均保持高性能,持续优于固定权重基线方法,而竞争方法则不可避免地需要在某一维度上做出牺牲。训练动态与帕累托前沿分析进一步验证,DVAO 的自适应方差归一化机制能够稳定奖励信号,防止简单任务主导梯度,并在无需手动调整超参数的情况下,实现对准确率与合规性权衡的稳健导航。最终,该算法通过在各类推理与执行任务中提供均衡且稳定的收敛效果,为多奖励优化建立了一个可靠的框架。
{"summary": "The authors evaluate their proposed DVAO method on tool-use tasks using the BFCL-v4 benchmark, comparing it against several baselines across different model scales. Results show that DVAO achieves the highest performance in both accuracy and format compliance simultaneously, outperforming all other methods which typically sacrifice one objective for the other. The training dynamics reveal that DVAO stabilizes rewards and response lengths more effectively, leading to better convergence and consistent improvement.", "highlights": ["DVAO achieves the highest accuracy and format compliance across all tasks and model scales, outperforming all baselines that trade one objective for the other.", "DVAO demonstrates superior training stability with lower variance in accuracy and length rewards compared to baselines, leading to more consistent optimization.", "DVAO's adaptive mechanism enables it to dominate the Pareto frontier, maintaining high compliance across different accuracy-weight settings while other methods show instability or saturation."]
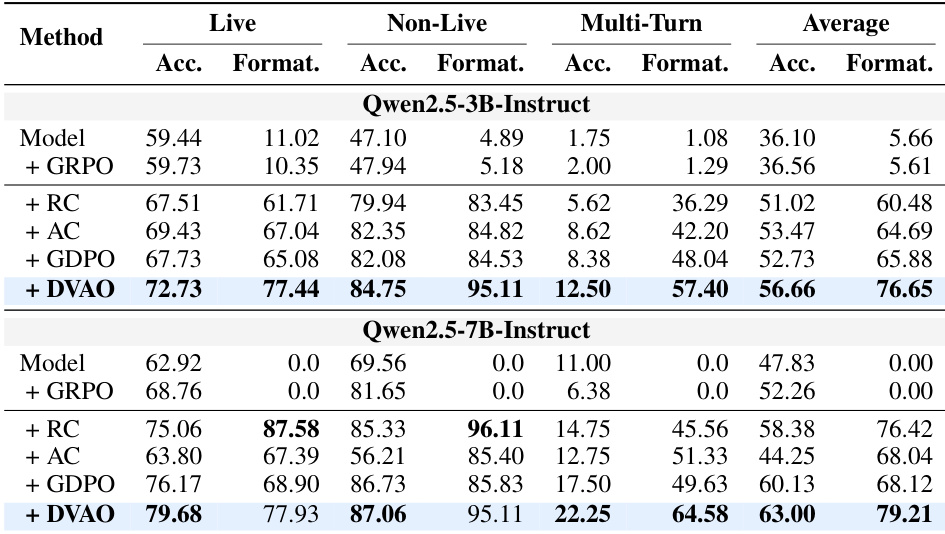
本文在数学推理与工具使用任务上评估了 DVAO 算法,并将其与 GRPO、RC、AC 和 GDPO 等多种基线方法进行对比。结果表明,DVAO 在两项任务与多种模型规模下均取得了最高的平均性能,在保持高准确率的同时,也确保了长度与格式约束的强合规性。其他方法通常需要在某一目标上做出牺牲,而 DVAO 则能同时在两个维度上保持领先。DVAO 在数学推理与工具使用任务中同时取得了最高的准确率与合规性得分。在不同模型规模下,DVAO 均保持卓越性能,而基线方法则需在准确率与合规性之间进行权衡。DVAO 展现出更稳定的训练动态,其奖励信号方差更低,并能有效收敛至目标长度与格式要求。
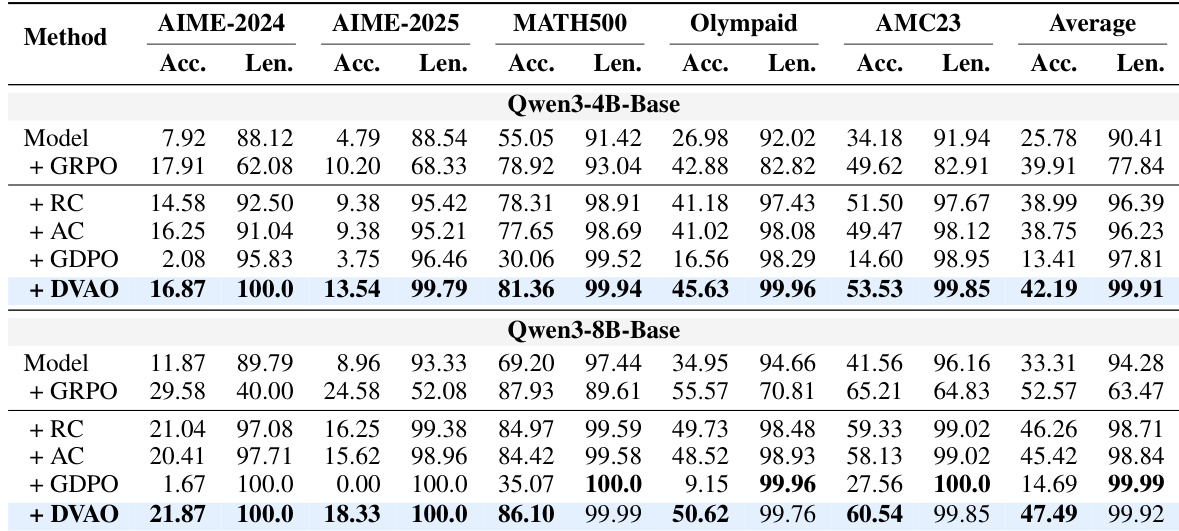
本文在多种模型规模下的数学推理与工具使用任务中评估了 DVAO 方法,并通过与多种基线方法的对比,验证了其同步优化准确率与合规性的能力。结果表明,DVAO 成功消除了性能与约束遵循之间常见的权衡问题,在竞争方法被迫牺牲某一目标时,仍能持续输出优异结果。定性分析表明,该方法具备更优的训练稳定性与可靠的收敛性,在不同配置下均能保持稳健性能,进一步证实了其作为平衡优化框架的地位。