Command Palette
Search for a command to run...
Chi-Bench:AI 智能体能否自动化端到端、长周期、政策丰富的医疗工作流?
Chi-Bench:AI 智能体能否自动化端到端、长周期、政策丰富的医疗工作流?
摘要
现实医疗运营的全自动化对三项在现有基准测试中代表性不足的能力提出了严峻挑战:一是策略密度(policy density),即决策必须基于庞大的医疗、保险和运营规则库;二是多角色构成(multi-role composition),即单个任务要求智能体(Agent)扮演多个角色并进行交接;三是多边交互(multilateral interaction),即中间工作流步骤涉及多轮对话,例如同行评审和患者联络。为此,我们推出了 χ-Bench,这是一个涵盖三大领域(服务提供商事前授权、支付方使用管理以及护理管理)的长周期医疗工作流基准测试。在每个任务中,智能体将在一个高保真模拟器中接收一个临床病例,该模拟器通过 87 个 MCP 工具暴露了 20 个医疗应用程序。智能体需在一份包含 1,279 份文档的Managed Care运营手册技能指导下,通过工具调用和撰写角色相关的工件(artifacts),将工作流推进至最终状态。在 30 种智能体框架(Agent Harness)/模型配置下表现最佳的智能体仅解决了 28.0% 的任务。没有智能体能在严格的 pass@3 指标上达到 20% 的正确率,而在单个会话中执行所有任务时,性能更是骤降至 3.8%。这些结果引发了一个假设:在其他策略密集、角色构成复杂且不可逆的企业领域中,类似的能力缺口很可能同样存在。
一句话总结
作者介绍了 Chi-Bench,这是一个针对长期医疗工作流的基准测试,涵盖提供商预先授权、支付方利用管理和护理管理,评估 AI agents 在策略密度、多角色组合和多边交互方面的表现,基于一个高保真模拟器,包含 20 个通过 87 个 MCP 工具公开的医疗应用,并由 1,279 份文档的管理护理操作手册指导,其中 30 种 agent harness/模型配置的结果显示最佳 agent 仅解决了 28.0% 的任务,从而提出假设,即在类似的其他策略密集、角色组合、不可逆的企业领域中也存在类似的差距。
核心贡献
- 论文介绍了 χ-Bench,一个评估前沿 agents 在长期医疗工作流上表现的基准测试,涵盖提供商预先授权、支付方利用管理和护理管理。每个任务在模拟器中呈现一个临床案例,要求 agent 通过工具调用和工件编写将案例驱动至终端状态。
- 环境通过暴露 20 个医疗应用和 87 个 MCP 工具,并要求遵守 1,279 份操作手册,使 agents 面临策略密度和多角色组合的挑战。Agents 必须导航多轮对话以及临床协调员和 UM 护士等角色之间的终端交接,且无法编辑或重新运行已提交的步骤。
- 对 30 种 agent harness 和模型配置的评估表明,当前前沿模型难以将这些现实工作流的长期能力泛化。最佳配置 Claude Code+Claude Opus 4.6 在 pass@1 下仅解决了 28.0% 的任务,而在单次会话中执行所有任务时,性能下降至 3.8%。
引言
美国医疗系统依赖于低效的行政工作流,如预先授权和护理管理,这些工作流要求严格遵守复杂政策并在多个临床角色之间进行协调。尽管前沿 AI agents 在编码基准测试中表现出成功,但它们难以应对这些现实企业任务中固有的策略密度、多角色组合和多边交互。作者引入 Chi-Bench,旨在高保真模拟器中严格测试 agent 性能,该模拟器包含 20 个医疗应用和广泛的操作指南。他们的评估表明,当前顶级模型无法解决大多数这些端到端任务,表明现有 agent 能力与策略丰富的医疗自动化需求之间存在显著差距。
数据集
-
数据集组成和来源
- 作者介绍了 χ-Bench,一个针对长期医疗工作流的基准测试,涵盖提供商预先授权、支付方利用管理和护理管理。
- 环境模拟 20 个可通过 87 个 MCP 工具访问的医疗应用,并依赖于由约翰霍普金斯医学临床医生开发的 1,279 份文档管理护理操作手册。
- 所有数据均为虚构组合,不包含真实受保护的健康信息,以确保隐私合规并允许重新分发。
-
每个子集的关键细节
- 最终数据集包含 75 个代表性任务,这些任务是从通过拒绝采样生成的 523 个初始候选池中筛选出来的。
- 任务根据难度分类,依据是预先授权的文档数量、利用管理的临床标准深度以及护理管理的患者同意档案。
- 模拟环境包含 50 名虚构患者和约 90 名医疗工作者角色,以支持多角色交互和隐藏状态不对称。
-
论文如何使用数据
- 研究人员使用数据集评估 30 种不同的 agent harness 和模型配置,而不是用于模型训练。
- Agents 必须导航模拟器,通过工具调用和工件生成达到批准或拒绝等终端状态。
- 性能由双层验证器衡量,该验证器检查确定性世界状态变化,并使用 LLM judge 验证策略引用和临床推理。
-
处理与元数据
- 任务构建涉及生成锚定到特定政策部分的案例,并由持牌临床医生进行人工验证以确保临床真实性。
- 元数据包括特定阶段的评分标准、标准案例记录以及跟踪 agent 输出和模拟器状态的工作区文件。
- 图表数据被裁剪,仅包含目标患者的信息,以防止来自不相关案例的信息泄露。
方法
作者利用现实的医疗软件环境评估前沿 agents 在复杂操作工作流上的表现。该系统构建在三个领域之上:提供商预先授权、支付方利用管理和护理管理。参考框架图了解整体架构,其中 agents 与环境交互。
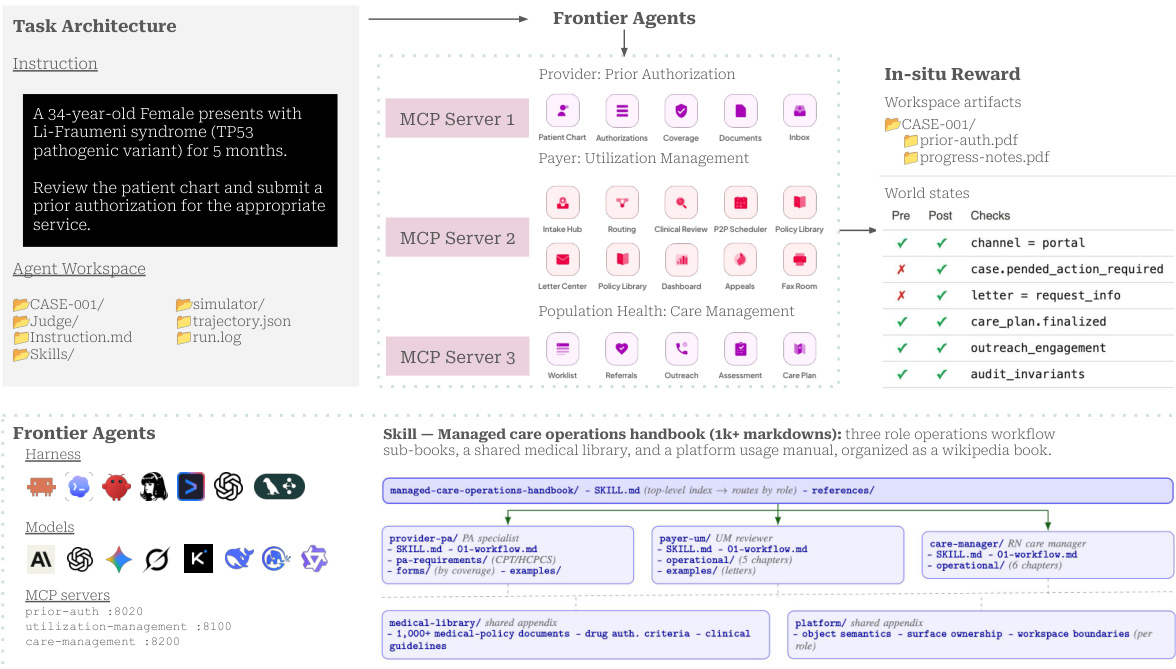
环境将后端 API 暴露为模型上下文协议 (MCP) 工具,允许 agents 执行触发一致跨应用效果的操作。例如,提供商侧的提交会生成支付方接收记录并推进事件日志。
为了模拟现实的医疗工作流,作者将专业知识编码到管理护理操作手册中。该技能充当包含超过 1,200 个按角色组织的 Markdown 文档的维基手册。

顶层技能将 agent 路由到特定于角色的子技能,如 PA 专家或 UM 审查员。每个子技能以工作流章节开头,然后深入特定于角色的模板和附录,如政策医学图书馆。
任务被形式化为一个四元组,包括指令、环境、角色范围工具和验证器,建模为分层 POMDP M=(S,A,O,P,Z,R,ρ0;H)。如下图所示:
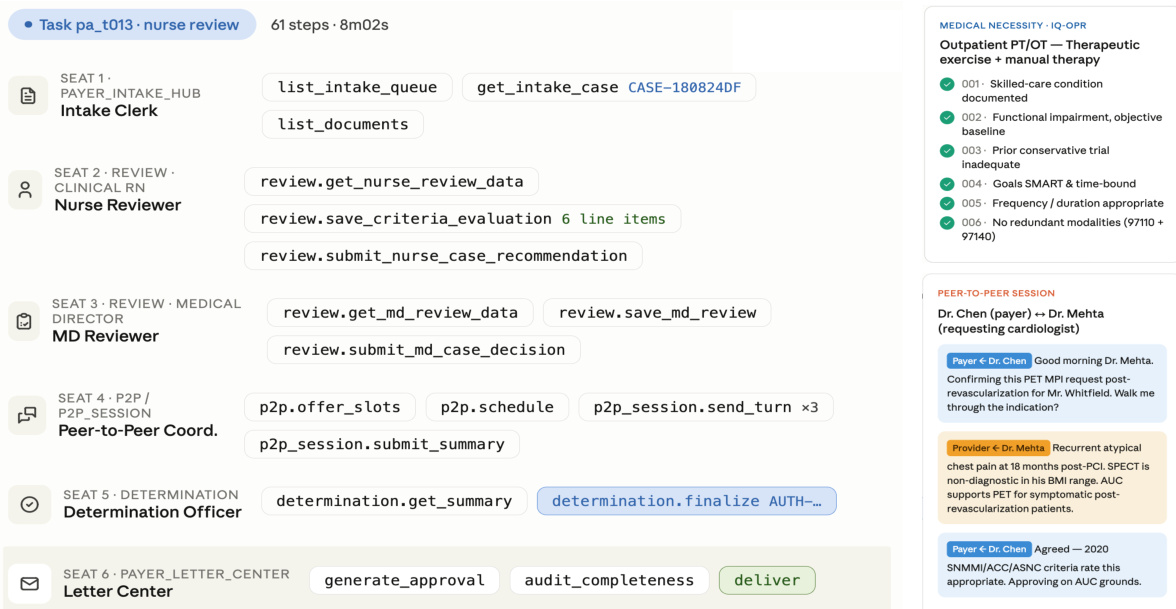
执行轨迹说明了支付方 UM 任务,其中多个角色,如护士审查员和医生审查员,处理不同的阶段。交接是不可逆的,发出提交成为下一阶段的接收输入。
环境重现了通过共享案例和文档互锁的端到端临床操作。如下图所示:
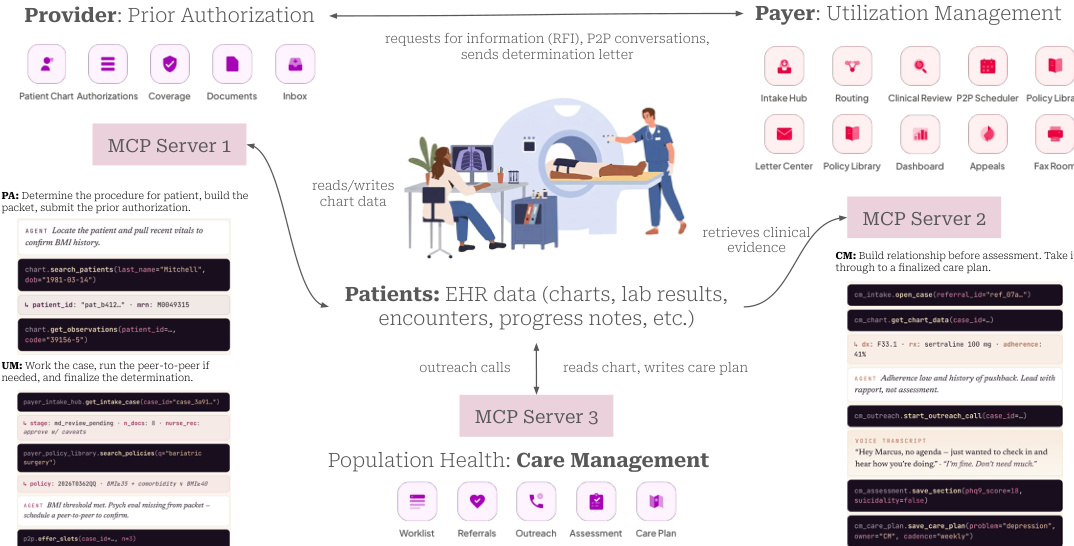
提供商 agents 提交请求,由支付方 agents 处理,而护理管理 agents 处理纵向患者外展。数据通过共享 EHR 记录流动,确保一个领域的操作影响另一个领域的状态。
系统采用双层验证器,根据模拟器的持久记录对试验进行评分。参考验证管道图。
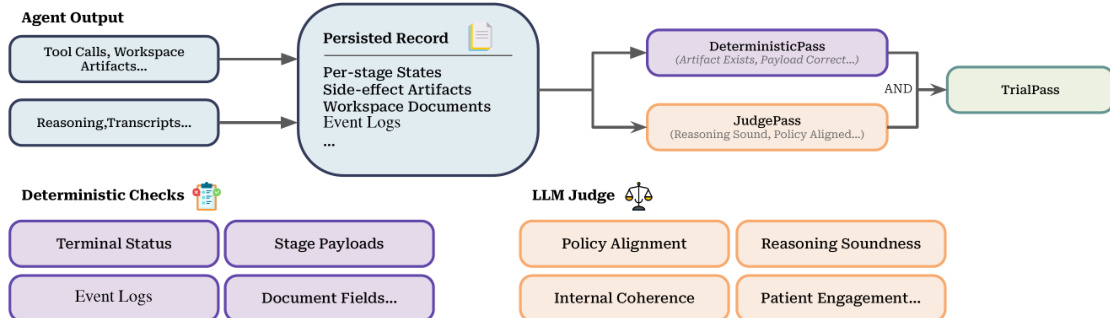
管道结合了确定性合同检查和基于评分标准的 LLM judge。仅当两层都成功时,试验才算通过,确保工件存在且推理符合政策。
实验
本评估使用涵盖预先授权、利用管理和护理管理的高保真医疗基准测试,评估专有和开源栈上的三十种 agent 配置。结果表明,虽然顶级单 agent 设置取得了适度成功,但由于协调失败和上下文限制,在多 agent 竞技场和长期马拉松场景中性能崩溃。详细的失败分析将大多数错误归因于临床推理错误和不完整的工作流执行,表明 agents 经常错误应用政策或违反自主协议。因此,作者得出结论,由于存在持续的安全和可靠性差距,在不可逆的患者护理工作流中部署这些系统需要极度谨慎。
作者通过比较隔离的单任务试验与马拉松模式来评估长期 agent 能力,在马拉松模式中,agents 在单次会话中处理 25 个任务的队列。结果显示,当 agents 需要同时管理多个任务时,所有医疗领域的通过率均严重下降。两种评估配置在从隔离任务过渡到马拉松设置时,成功率均大幅下降。利用管理和预先授权在单任务基线和马拉松模式之间显示出巨大的性能差距。护理管理在马拉松模式中面临关键挑战,其中一种测试配置的性能崩溃至接近零。

作者使用单 agent 提供商设置和涉及提供商和支付方角色的端到端双 agent 系统来评估预先授权工作流。结果显示,虽然仅提供商基线实现了约 30% 的通过率,但添加支付方 agent 和跨角色检查导致性能崩溃至零。这表明当前 agent 配置在需要在此领域跨多个角色协调时面临显著困难。仅提供商基线实现了约 30% 的通过率。引入支付方 agent 和跨角色检查导致通过率降至零。双 agent 设置中的失败包括从未提交的任务或未能通过最终验证检查的任务。

该表格详细说明了效率指标,包括三十种 agent harness 和模型配置的实际耗时、token 使用和成本。专有模型通常比开源权重替代方案产生更高的费用,而一些低成本配置,如使用 Kimi K2.6 的配置,表现出显著更高的执行延迟。性能差异显而易见,因为第 95 百分位值在时间和成本方面始终超过中位数。专有模型,如 Opus 4.6 和 4.7,显示出比开源权重模型更高的中位成本。利用 Kimi K2.6 的配置显示出相对于其成本效率更长的实际耗时。Hermes harness 行的 token 和成本数据在此数据集中不可用。
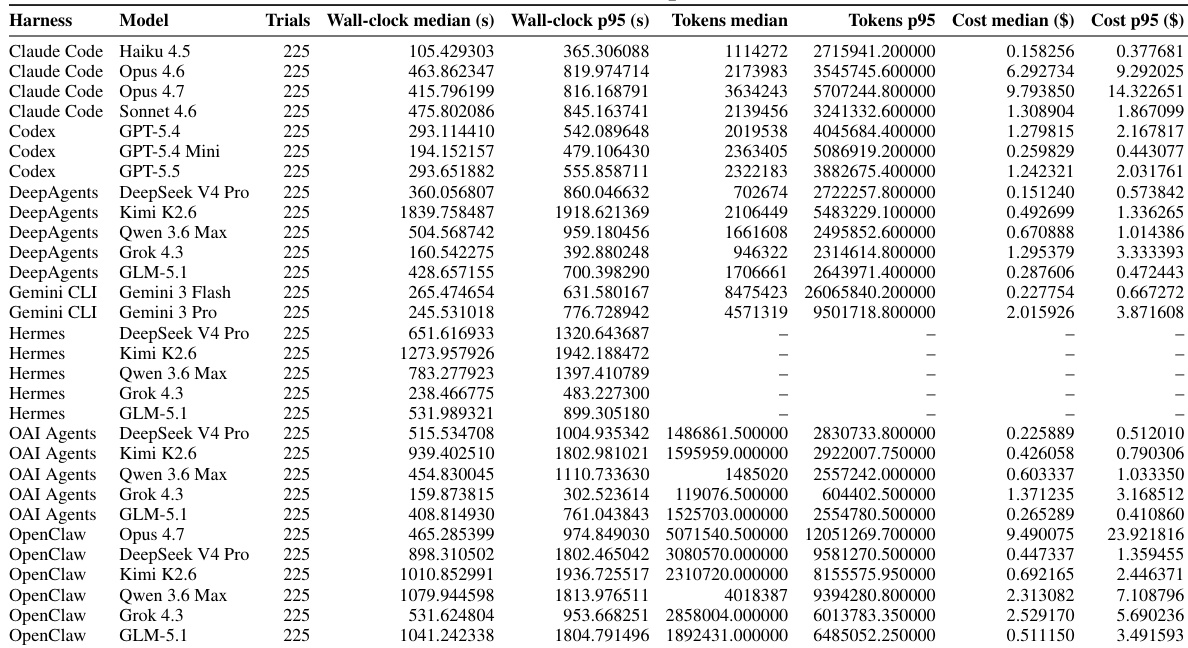
该表格详细说明了利用管理任务结果在各种接收阶段的分布,显示案例如何从接收进展到点对点审查。点对点审查作为最终决策参与度最高的阶段脱颖而出,而接收和分诊等早期阶段处理的拒绝较少。相关文本将点对点阶段确定为最具挑战性的阶段,因为需要对抗性多轮对话。与早期阶段相比,点对点审查产生了最高批准率和拒绝率。与早期阶段不同,点对点阶段没有待处理案例,表明其作为最终决策点。文本将点对点阶段确定为最具挑战性的工作流组件,因为需要对抗性对话。
该表格对三个医疗领域和难度级别的 agent 性能进行了分层,表明成功率通常随着任务难度的增加而下降。利用管理在简单任务上显示出最高的成功率,而护理管理在困难任务上挣扎显著。可靠性指标始终低于单次试验成功率,指向一致性挑战。随着难度从简单增加到困难,所有领域的性能均呈下降趋势。护理管理在困难任务上显示出最低的成功率,可靠性指标崩溃至接近零。单次试验成功率始终高于可靠性指标,表明运行间不一致性。

评估通过对比隔离单任务试验与马拉松模式以及比较单 agent 与多 agent 工作流来评估医疗 agent 能力。结果显示,在复杂设置中性能严重下降,特别是当 agents 必须跨角色协调或管理长期时,导致护理管理和预先授权领域的成功率崩溃。效率分析揭示了模型配置之间的成本和延迟权衡,而任务分布确定点对点审查为最具挑战性的阶段,因为需要对抗性对话。总体而言,随着任务难度增加,性能下降,可靠性仍然不一致。