Command Palette
Search for a command to run...
AutoFigure:生成与优化可供出版的科学插图
AutoFigure:生成与优化可供出版的科学插图
Minjun Zhu Zhen Lin Yixuan Weng Panzhong Lu Qiujie Xie Yifan Wei Sifan Liu Qiyao Sun Yue Zhang
摘要
高质量的科学插图对于有效传达复杂的科学与技术概念至关重要,然而其手动创作在学术界和工业界仍被公认为是一个显著的瓶颈。我们提出了 FigureBench,这是首个用于从长篇科学文本生成科学插图的大规模基准测试。FigureBench 包含 3,300 对高质量的科学文本-插图数据,涵盖了源自科学论文、综述文章、博客和技术教材的多样化文本到插图任务。此外,我们提出了 AUTOFIGURE,这是首个基于长篇科学文本自动生成高质量科学插图的 Agentic 框架。具体而言,在渲染最终结果之前,AUTOFIGURE 会进行广泛的思考、重组与验证,从而生成兼具结构严谨性与美学精炼性的布局,最终输出既结构完整又具视觉吸引力的科学插图。利用 FigureBench 的高质量数据,我们开展了广泛的实验,以评估 AUTOFIGURE 相对于多种 Baseline 方法的性能。实验结果表明,AUTOFIGURE 始终超越所有 Baseline 方法,能够生成可直接用于出版的科学插图。代码、数据集及 Huggingface Space 已发布在 https://github.com/ResearAI/AutoFigure。
一句话总结
作者提出了 AUTOFIGURE,这是首个能够通过广泛思考、重组和验证,从长篇科学文本生成出版就绪科学插图的 agent 框架,同时推出了 FigureBench,一个包含 3,300 对高质量科学文本 - 图像对的大规模基准,实验表明 AUTOFIGURE 始终优于所有基线方法,代码和资源已公开。
核心贡献
- 这项工作介绍了 FigureBench,这是首个用于从长篇文本生成科学插图的大规模基准,包含来自不同来源的 3,300 对高质量文本 - 图像对。该数据集支持各种文本到插图任务,并为训练和评估自动化科学可视化工具提供了基础。
- 本文提出了 AUTOFIGURE,这是一个 agent 框架,通过在渲染最终结果之前进行广泛的思考和验证,自动生成高质量科学插图。该过程确保输出既具备学术出版所需的结构完整性,又具备美学吸引力。
- 基于 VLM-as-a-judge 范式和人类专家评估的大量实验表明,该方法在生成出版就绪插图方面始终优于基线方法。相关代码、数据集和 Hugging Face space 已发布,以促进对 AI 驱动科学传播的进一步研究。
引言
高质量科学插图对于传达复杂概念至关重要,但其手动创建仍然是人类研究人员和新兴 AI 科学家的主要瓶颈。现有的自动化方法通常依赖于简短说明或重新排列现有内容,而主流的文本到图像模型在处理长篇科学文本时难以保持结构保真度。为了克服这些挑战,作者提出了 FigureBench,这是首个专为从长篇科学文档生成插图而设计的大规模基准。他们进一步开发了 AutoFigure,这是一个采用 Reasoned Rendering 范式的 agent 框架,将布局规划与美学渲染分离,确保最终输出在准确性和视觉吸引力方面均符合出版标准。
数据集
- 数据集构成与来源
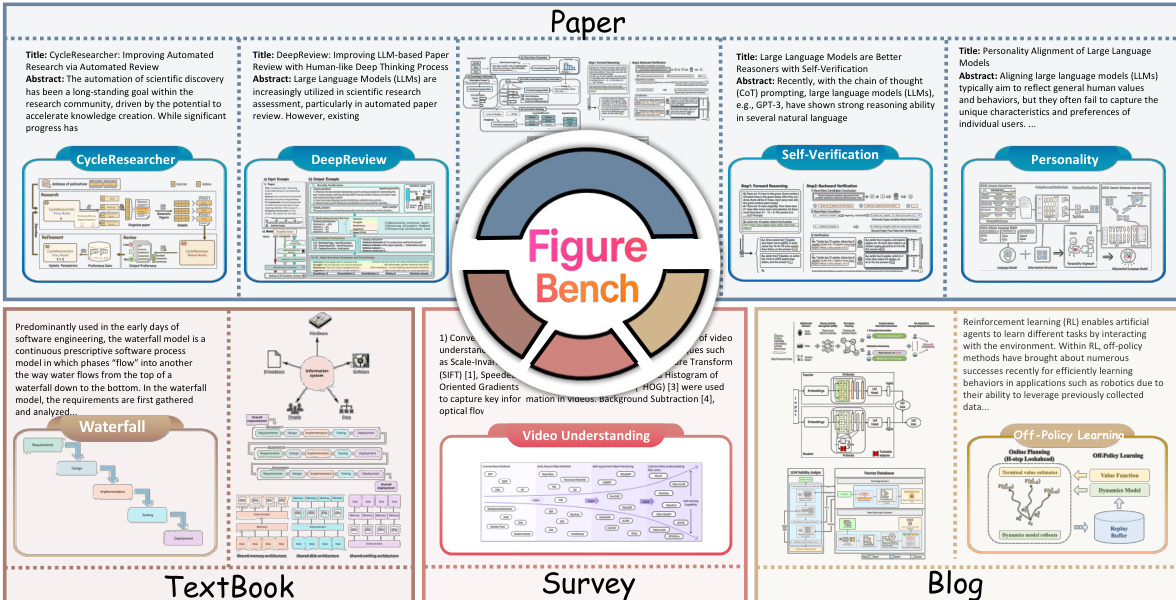
- 作者介绍了 FigureBench,这是一个由四个不同来源构建的基准:研究论文、综述、技术博客和教科书。
- 所有数据严格遵循开源许可证,论文来自 Research-14K 数据集,教科书来自 OpenStax 等平台。
- 每个子集的关键细节
- 测试集由 300 个高质量样本组成。
- 200 个样本来自 Research-14K 数据集。GPT-5 选择了代表核心方法的插图,两名独立标注员仅保留了获得一致批准的概念图。
- 另外 100 个样本是从 arXiv 上的 AI 综述、技术博客和教育教科书中手动整理的,以确保领域多样性。
- 开发集包含 3,000 个样本。作者在测试集上微调了一个视觉语言模型,用作更大 Research-14K 语料的自动过滤器。
- 数据使用与训练划分
- 测试集严格保留用于评估目的。
- 开发集旨在用于训练和开发,尽管提出的 AUTOFIGURE 流程作为仅推理系统运行。
- 作者提供开发集以促进社区对端到端或可训练方法的进一步探索。
- 处理与元数据构建
- 策展过程过滤掉数据驱动图表,专注于文本中明确描述视觉元素的概念插图。
- 统计元数据包括文本密度、颜色数量和结构组件,使用 InternVL 3.5 模型自动计算。
- 对 21 个随机样本的人工合理性检查验证了这些自动测量与人工标注的可靠性。
方法
作者介绍了 AutoFigure,这是一种解耦生成范式,旨在通过分离推理和渲染过程来生成高保真科学插图。该方法通过三阶段流程解决了创建语义准确且视觉连贯图表的挑战。
整体框架如下面的架构图所示,概述了从非结构化文本到最终出版就绪插图的转变。
阶段 I:概念锚定与布局生成 给定长篇科学文档 T,第一阶段生成机器可读的符号布局 S0(例如 SVG/HTML)和样式描述符 A0。Concept-Extraction agent 处理输入文本以提炼方法摘要 Tmethod,并识别要可视化为节点和有向边的实体和关系。该结构被序列化为基于标记的符号布局 S0,其中 S0 编码有向图 G0=(V0,E0)。
阶段 II:批评与优化 该方法的核心创新在于一个自优化循环,模拟 AI“设计师”和 AI“批评者”之间的对话,以优化蓝图的结构连贯性和逻辑一致性。初始布局 (S0,A0) 被评估以获得初始分数 q0,设定当前最佳版本 (Sbest,Abest)。在每次迭代 i 中,系统通过以下过程生成更优解决方案:
Fbest(i)=Feedback(Φcritic(Sbest,Abest))(Scand(i),Acand(i))=Φgen(Tmethod,Fbest(i)),批评者 Φcritic 评估表现最佳的布局的对齐、平衡和重叠避免情况,产生文本反馈 Fbest(i)。生成器 Φgen 随后利用此反馈重新解释 Tmethod 并生成候选布局 (Scand(i),Acand(i))。如果候选分数 qcand(i) 超过当前最佳值,则替换最佳版本。此循环持续直到收敛或预设迭代限制,产生逻辑一致且美学平衡的条件布局 (Sfinal,Afinal)。
阶段 III:渲染策略 最终阶段将优化的符号蓝图转换为高保真插图 Ifinal。转换函数 Φprompt 将布局和样式转换为详尽的文本到图像提示,输入到多模态生成模型中以渲染图像 Ipolished。为确保文本准确性,系统采用擦除与修正过程。非 LLM 擦除器 Φerase 从 Ipolished 中移除文本像素以创建干净背景 Ierased。OCR 引擎 Φocr 提取初步字符串,多模态验证器 Φverify 将这些字符串与从 Sfinal 解析的地面真实标签 Tgt 对齐。最后,修正后的文本映射 Tcorr 作为矢量文本叠加渲染在 Ierased 之上以获得最终插图。
该流程的有效性通过将生成输出与其他方法进行比较来证明。如下面的图所示,AutoFigure 生成具有高保真科学图表,细节清晰且配色悦目,优于 SVG 生成或直接 diagram agents 等替代方案。

实验
本研究通过 FigureBench 上的自动化基准、涉及论文作者的领域专家研究以及隔离关键模块的受控消融实验来评估 AUTOFIGURE。该框架通过有效平衡科学准确性与视觉美学,始终优于基线方法,生成的图表被专家认为是适合出版的。定性案例研究突出了与现有方法相比,对复杂科学结构的优越处理能力,而消融分析验证了符号布局和优化循环对于实现高质量输出的必要性。
该研究评估了系统在保持整体质量的同时适应不同视觉风格的能力。结果表明,虽然整体性能在不同风格中保持稳定,但视觉设计吸引力和沟通有效性等特定维度取决于所选的美学提示词。‘漫画’风格提示词实现了最高的视觉设计评级,但导致沟通清晰度和流畅性得分较低。‘极简’风格提示词在沟通有效性和内容复杂性方面优于其他风格,尽管视觉设计得分较低。整体质量得分在所有测试的风格变化中保持一致,证明了系统对美学变化的鲁棒性。

作者使用不同的开源推理骨干评估 AUTOFIGURE 框架,具体为 Qwen3-VL-235B、GLM-4.5V 和 ERNIE-4.5-VL。结果表明,GLM-4.5V 实现了最高的总体胜率,在沟通和内容保真度方面表现出优于其他模型的性能。相比之下,Qwen3-VL-235B 在视觉设计方面显示出强大的能力,如美学和润色,而 ERNIE-4.5-VL 在所有测量维度上表现明显不佳。GLM-4.5V 实现了最高的总体胜率,在盲选配对比较中优于 Qwen3-VL-235B 和 ERNIE-4.5-VL。Qwen3-VL-235B 表现出卓越的视觉设计质量,在美学、表现力和润色方面获得最高分。ERNIE-4.5-VL 在所有指标上表现最低,特别是在沟通清晰度和内容保真度方面。

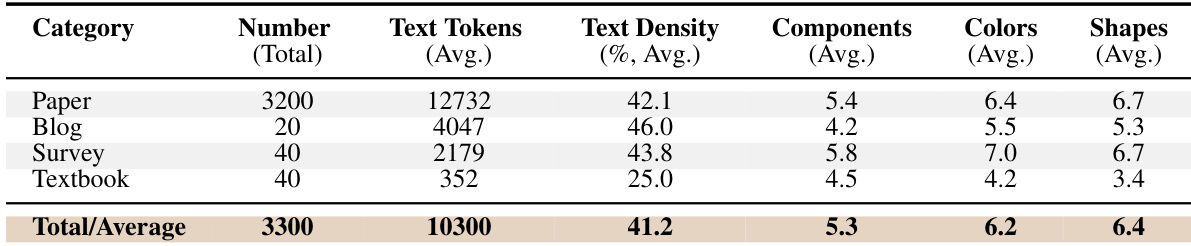
该表格详细说明了 FigureBench 数据集在四个不同文档类别中的统计构成。它根据样本量、文本量、文本密度以及视觉复杂性指标(如平均组件数量、颜色和形状)对类别进行比较。数据显示,学术论文是最普遍且文本最重的类别,而教科书代表文本密度最低且视觉上最简单的组。学术论文在样本数量和平均文本 token 量上占主导地位。教科书条目表现出最低的文本密度和最简单的视觉结构,组件和颜色较少。综述文档表现出最高的视觉复杂性,平均包含最多的组件和颜色。
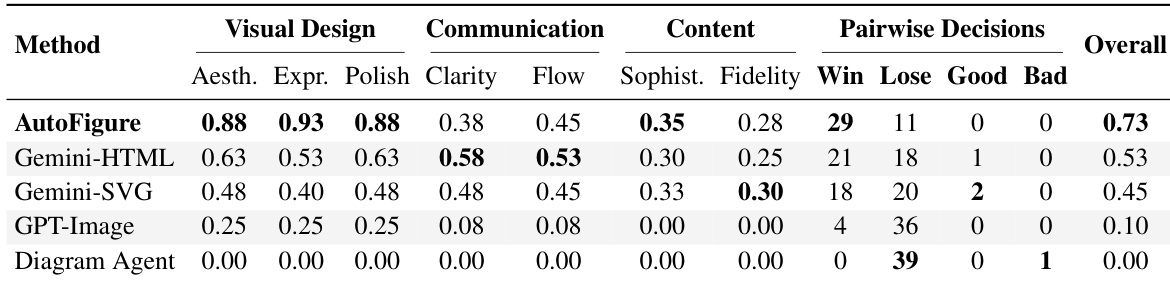
该研究将 AutoFigure 与多种基线方法进行了比较,包括代码生成和端到端模型,以评估图表生成质量。结果表明,AutoFigure 实现了最高的整体性能,特别是在视觉设计维度上,如美学和表现力。虽然基于代码的基线在沟通清晰度方面显示出中等强度,但 AutoFigure 在配对比较中占据主导地位,表明对其输出有强烈偏好。AutoFigure 实现了最高整体得分,并在与其他模型的配对比较中赢得大多数。视觉设计指标,包括美学和润色,对于 AutoFigure 而言显著高于基线。基于代码的基线如 Gemini-HTML 在沟通清晰度方面表现更好,但在视觉吸引力和整体质量方面明显落后。
作者进行了消融研究,以隔离文本优化模块对最终输出质量的影响。结果表明,完整模型优于没有优化的变体,特别是在视觉设计维度上,如美学和专业润色。这证实了优化阶段对于消除伪影和实现出版就绪标准至关重要。完整模型的整体得分高于缺少文本优化模块的版本。包括美学和表现力在内的视觉设计指标在优化步骤中显示出最显著的改进。优化过程有效地增强了专业润色,确保图表符合高质量标准。

该研究通过视觉风格适应性评估、骨干模型性能以及与基线方法的比较来评估 AUTOFIGURE 框架。结果表明,虽然整体质量在美学变化中保持一致,但特定风格在视觉设计吸引力和沟通清晰度之间存在权衡。完整框架显著优于基线和消融版本,证实 GLM-4.5V 骨干和文本优化模块对于实现高视觉保真度和专业润色至关重要。