Command Palette
Search for a command to run...
D^2-Monitor:基于犹豫感知路由的扩散语言模型动态安全监控
D^2-Monitor:基于犹豫感知路由的扩散语言模型动态安全监控
Aoxi Liu Yupeng Chen James Oldfield Guanzhe Hong Junchi Yu Baoyuan Wu Philip Torr Adel Bibi
摘要
尽管扩散大型语言模型(D-LLMs)作为自回归大型语言模型(AR-LLMs)的替代方案已应运而生,但针对D-LLMs的安全监控在很大程度上仍属空白。与AR-LLMs不同,D-LLMs通过多步去噪过程生成文本,会暴露出中间隐藏表示,其中可能包含标准单步监控设置中无法获取的安全相关信息。鉴于轻量级探针适用于持续监控,我们分析了哪些轨迹级信号最能指示此类探针何时可能面临困难。我们发现信息量最丰富的信号是安全犹豫:即中间隐藏状态反复落入探针决策边界的微小容差范围内。D-LLM轨迹中此类犹豫步骤的数量能够有效预测探针失效情况,从而作为样本难度的代理指标。基于上述分析,我们提出了D^2-Monitor,这是一种面向D-LLMs的双层安全监控器。D^2-Monitor采用轻量级探针作为持续运行的监控器,以联合估计犹豫程度并执行基础分类。当犹豫程度超过设定阈值时,系统将激活一个表达能力更强但计算开销更大的探针。该动态路由机制能够在测试阶段高效地分配监控资源。在涵盖4个D-LLMs的3个数据集(WildguardMix、ToxicChat、OpenAI-Moderation)上的评估结果表明,D^2-Monitor以紧凑的参数规模(leq 0.85M parameters)实现了最先进的性能,相较于8种基线方法,在有效性与效率之间取得了最佳平衡。
一句话总结
D2-Monitor 通过追踪中间轨迹状态来动态监控扩散大语言模型的安全性。当状态反复接近轻量级探针的决策边界且犹豫程度超过阈值时,系统会将其路由至计算开销更大的探针。该方法在三个数据集和四个模型上均达到最先进性能,参数量紧凑(≤ 0.85 million),并在与八种基线方法的对比中实现了最佳的效能与效率权衡。
核心贡献
- 分析将安全犹豫识别为一种轨迹级现象,即中间隐藏状态反复落在探针决策边界附近。研究表明,犹豫严重程度与监控失败高度相关,并可作为样本难度的可靠代理指标。
- 基于上述分析,本文提出 D2-Monitor,这是一种双层安全框架。该框架持续使用轻量级探针,并动态将高犹豫样本路由至计算开销更大的二级分类器。系统还利用犹豫轨迹来筛选针对性训练数据,以优化高级监控阶段。
- 在四个扩散语言模型上对 WildguardMix、ToxicChat 和 OpenAI-Moderation 数据集的评估表明,该方法在数据集内和数据集间设置下均实现了最先进的检测精度。该框架参数量紧凑(低于 0.85 million),在与八种现有基线方法的对比中,实现了安全性效能与计算效率的最佳平衡。
引言
扩散大语言模型(D-LLMs)凭借并行解码能力,正迅速成为自回归架构的高效替代方案,但其安全部署仍是关键的应用挑战。此前的安全监控研究主要面向自回归模型,依赖计算开销庞大的外部 LLM 或静态轻量级探针,未能充分考虑扩散生成固有的多步去噪轨迹。为弥补这一差距,研究团队将安全犹豫识别为一种稳健的轨迹级信号,可可靠地预测轻量级探针在复杂或对抗性输入下的失效时机。基于这一机制洞察,本文提出 D2-Monitor,这是一种动态双层安全系统。该系统持续追踪中间隐藏状态,仅在必要时将不确定样本路由至表达能力更强的分类器。该设计在保持最小参数规模的同时实现了最先进的检测性能,并在监控精度与计算效率之间取得了最优平衡。
数据集

-
数据集构成与来源: 研究团队使用三个公开基准评估其安全监控方法:WildGuardMix、ToxicChat 和 OpenAI-Moderation。这些来源涵盖了对抗性输入、真实世界对话交互以及标准化的内容审核类别。
-
各子集关键细节:
- WildGuardMix:包含 86.8k 条标注为有害或无用的训练提示词与 1.7k 条测试提示词。采用 ODC-BY 许可证发布。
- ToxicChat:包含 5.08k 条训练提示词与 5.08k 条测试提示词,来源于真实用户与 AI 的交互,并标注了二元毒性标签(1 表示有毒,0 表示无毒)。仅在 CC-BY-NC-4.0 许可证下用于非商业研究。
- OpenAI-Moderation:包含 1.68k 条提示词,涵盖八个风险类别的标注。若任一类别被标记,则提示词视为不安全,否则视为安全。采用 MIT 许可证发布。
-
使用方式与训练划分: 研究团队采用两种评估协议应用这些数据。在数据集内测试中,分别在 WildGuardMix 和 ToxicChat 上独立训练和评估探针。在跨数据集泛化测试中,仅在 WildGuardMix 上进行训练,并在 ToxicChat 与 OpenAI-Moderation 上测试所得探针。数据集直接用于训练轻量级安全探针,未指定混合比例或采样策略。
-
处理与元数据构建: 研究团队直接使用原始数据集,依赖原始提示词文本与预分配的安全标签。未进行裁剪、文本截断或自定义元数据生成。现有标签直接映射至二元或多分类目标,用于训练时序隐藏状态监控器。
方法
研究团队提出 D2-Monitor,这是一种面向扩散大语言模型(D-LLMs)的动态安全监控框架,利用多步去噪轨迹实现高效且有效的安全分类。该框架基于以下洞察:D-LLM 去噪过程中的犹豫步数可作为线性探针判断样本难度的可靠指标。核心机制在于识别高犹豫严重程度的轨迹,即探针决策边界符号间隔低于阈值 τ 的步数统计,并利用该信息指导两阶段分类流程。
D2-Monitor 的整体架构由三个核心组件构成:低复杂度基础探针、路由模块和复杂度高的高级探针。基础探针采用线性实现,设计为轻量级且持续运行的监控模块。它将每个输入提示词输入 D-LLM 的去噪过程,生成隐藏表示的多步轨迹。基础探针随后计算逐时间步间隔,识别犹豫步数,并计算整体犹豫严重程度 nτ。路由模块使用该严重程度分数决定是否需要将样本升级至第二阶段分类。对于低犹豫严重程度的样本(nτ≤λ),基础探针直接输出最终预测。对于高犹豫严重程度的样本(nτ>λ),路由模块将激活高级探针。
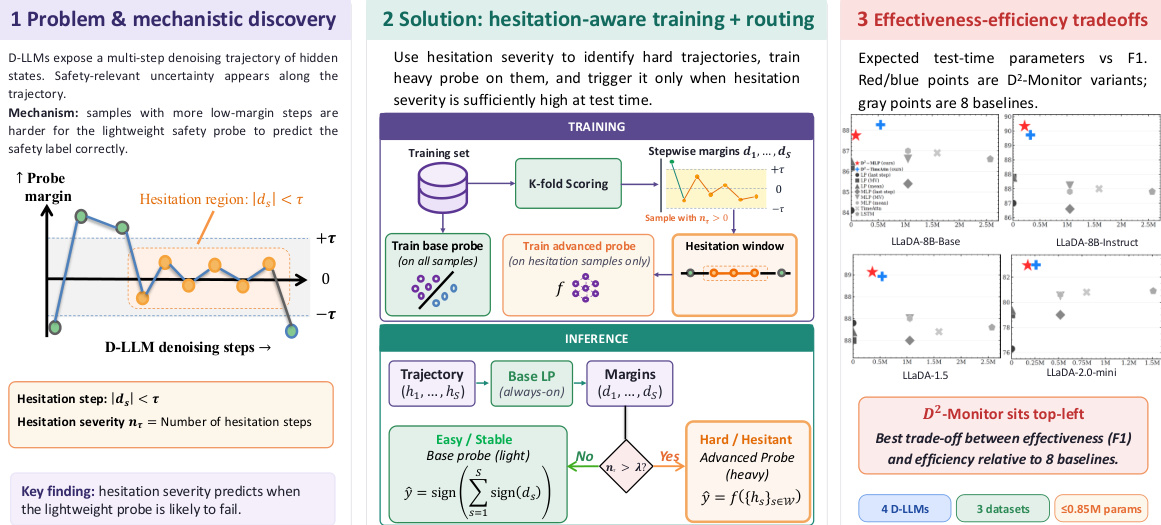
D2-Monitor 的训练过程分为三个阶段。首先,采用折外评分机制收集用于训练高级探针的犹豫轨迹。训练集被划分为 k 折,在 k−1 折上训练的线性探针用于对剩余折进行评分,从而获得无偏的间隔估计。利用间隔阈值 τ 识别犹豫步数,并筛选出 nτ>0 的轨迹。其次,在完整训练集上训练基础探针,使其作为初始分类器并计算犹豫分数。高级探针仅在收集的犹豫轨迹上进行训练。该高级探针在全轨迹 H 上运行,不进行时间步级池化,而是采用时序注意力机制聚合犹豫窗口内的信息。犹豫窗口定义为包含所有犹豫步数的最小连续跨度。随后将该窗口输入双层 MLP 进行分类。最后,在推理阶段应用级联检测策略:基础探针首先计算间隔与 nτ。若 nτ≤λ,则返回基础探针的多数投票预测结果。否则,提取犹豫窗口并传递给高级探针进行第二级预测。该设计实现了计算资源的动态分配,确保仅由计算成本更高的高级模型处理最具难度的样本。
实验
该评估在扩散 LLM 的数据集内与跨数据集设置下测试 D2-Monitor,以验证其感知犹豫的级联架构相对于标准基线的表现。综合实验验证了模型对解码配置变化、重掩码策略及分布偏移的鲁棒性,消融实验则证实基于间隔的路由能有效隔离内在不确定的样本。通过仅在模型真实出现犹豫时条件性激活专用探针,该框架在保障检测精度的同时大幅降低了计算开销。总体而言,研究结果表明,针对局部犹豫动态进行优化能够产出高效且可靠的安全监控方案。
研究团队在不同 LLaDA 模型上评估了所提方法 D2-Monitor 的性能,并与基线方法进行对比。结果表明,D2-Monitor 在所有模型上的性能均优于基线,且其有效性不受具体模型或数据集配置的影响。在评估的所有模型中,D2-Monitor 均表现优于基线。相较于 LLaDA-1.5,该方法在 LLaDA-8B-Base 和 LLaDA-8B-Instruct 上取得了更高的性能。该方法性能始终优于基线,表明其在不同模型配置下均具备稳健的有效性。

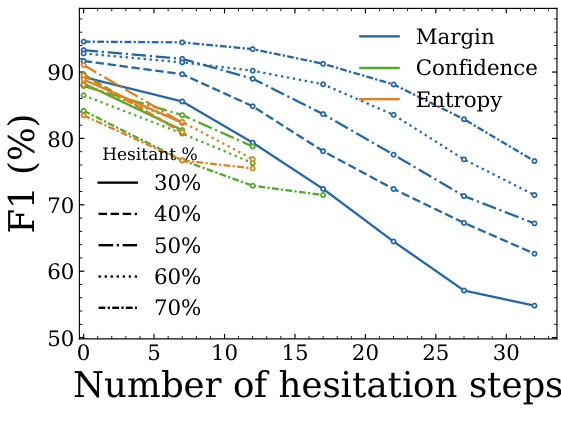
研究团队分析了所提方法中不同路由信号的性能,重点考察犹豫步数如何影响识别犹豫的不同阈值下的 F1 分数。结果表明,基于间隔的路由始终优于基于置信度和熵的信号,且在各类犹豫比例下表现稳定。随着犹豫步数增加,性能有所下降,但基于间隔的路由相比其他方法仍能保持更高的 F1 分数。在所有犹豫比例下,基于间隔的路由均取得更高的 F1 分数。F1 分数随犹豫步数增加而下降,基于间隔的路由展现出更稳定的性能。该方法对识别犹豫的不同阈值表现出良好的鲁棒性,在 30% 至 70% 的犹豫水平下均能维持高性能。
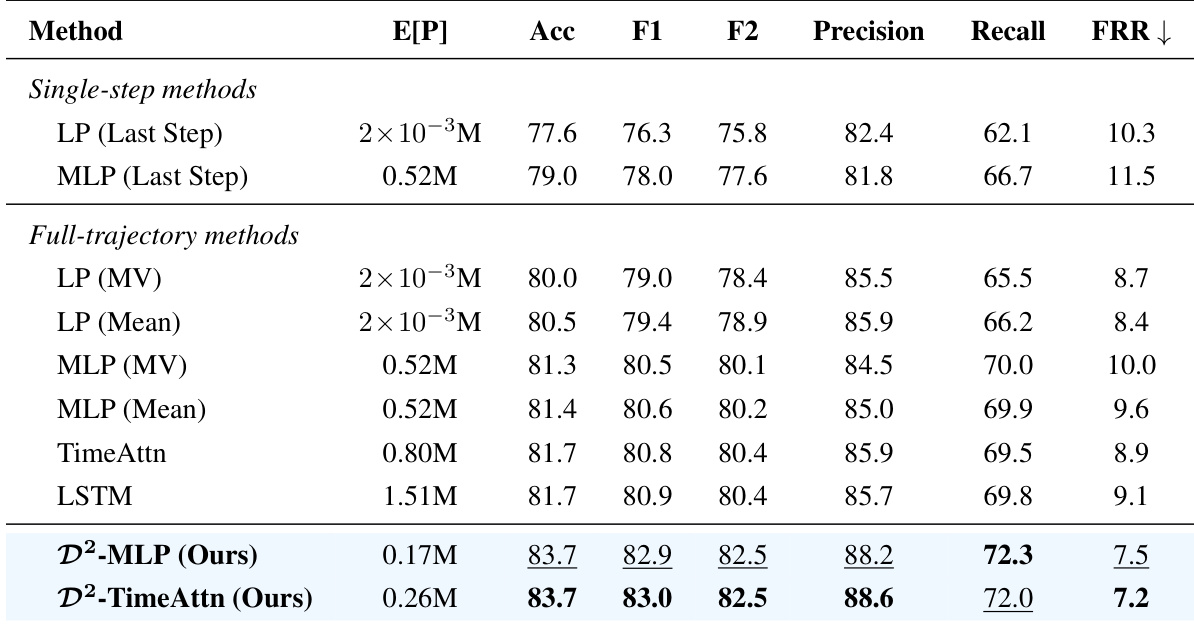
研究团队将所提方法 D2-Monitor 与多种单步及全轨迹基线进行对比,证明该方法在多项指标上实现更优性能的同时,保持了显著更低的计算成本。结果表明,D2-Monitor 在准确率、F1、F2 和精确率方面均优于所有基线,召回率具有竞争力且误拒率较低,尤其在与全轨迹方法对比时更为明显。该方法的效率归功于其条件计算机制,仅处理部分输入并聚焦局部犹豫窗口,从而降低了每个样本的预期浮点运算次数(FLOPs)。D2-Monitor 在所有方法中实现了最高的准确率与 F1 分数,同时使用的计算资源远少于全轨迹基线。该方法在精确率与 F2 分数等多项指标上保持强劲表现,误拒率低于其他方案。通过仅在犹豫样本上选择性激活高级探针,D2-Monitor 实现了更优的效能与效率权衡,其计算成本与单步方法相当。
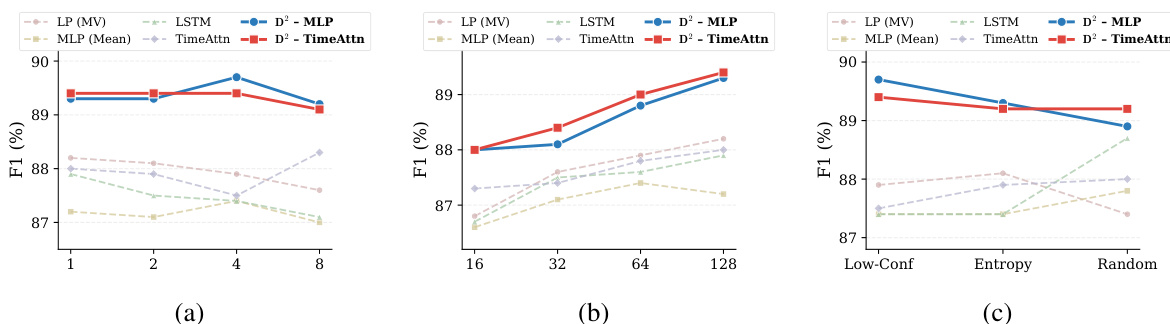
研究团队在不同实验设置下将所提 D2-Monitor 方法与多种基线进行性能对比。结果表明,D2-Monitor 始终取得比其他方法更高的 F1 分数,展现出更优的有效性。该方法还保持了良好的效能与效率权衡,通过仅在表现出犹豫的样本上选择性激活高级探针来降低计算成本,同时性能仍可与全轨迹模型持平。在所有实验设置中,D2-Monitor 相较于所有基线方法均取得了最高的 F1 分数。该方法通过感知犹豫的路由机制降低计算成本,实现了与全轨迹模型相当的性能,同时资源消耗更低。D2-Monitor 的性能在不同生成长度、步长及重掩码策略下均表现稳健,表明其可泛化至多样化的部署条件。
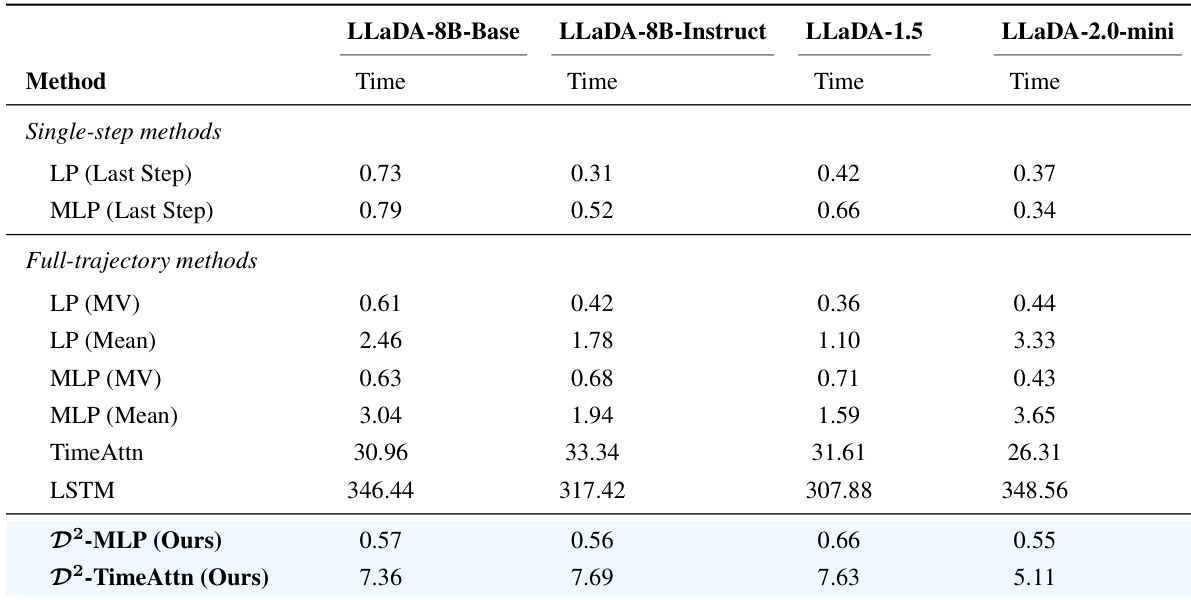
该表格对比了不同 LLaDA 模型在各方法下的推理时间,显示所提出的 D2-Monitor 方法在保持竞争力性能的同时,推理时间显著低于全轨迹基线。结果表明,D2-MLP 与 D2-TimeAttn 属于速度最快的方法,其推理时间与单步方法相当,且大幅低于基于序列的模型。研究团队将这些效率提升归因于感知犹豫的路由机制,该机制仅在部分样本上选择性激活更复杂的探针,在不牺牲有效性的前提下降低计算开销。所提出的 D2-Monitor 方法实现了与单步方法相当的推理时间,同时在有效性方面优于全轨迹基线。相较于 TimeAttn 与 LSTM 等传统全轨迹模型,D2-MLP 与 D2-TimeAttn 显著缩短了推理时间。效率提升归功于条件计算机制,即高级探针仅在被识别为犹豫的少数样本上激活,从而最大限度减少冗余处理。
所提方法在多个 LLaDA 模型与实验配置下进行评估,并与单步及全轨迹基线进行基准对比。实验验证了该方法始终实现更优的检测精度,且基于间隔的路由信号被证明比基于置信度或熵的替代方案更稳定有效。效率评估确认,仅在犹豫输入上选择性激活高级探针可产生极佳的权衡效果,在匹配全轨迹性能的同时大幅降低计算开销与推理延迟。总体而言,研究结果证明该方法在不同生成长度、犹豫阈值及重掩码策略下均具备稳健的泛化能力。