Command Palette
Search for a command to run...
通过对比的视角:视觉语言模型(VLMs)中自我改进的视觉推理
通过对比的视角:视觉语言模型(VLMs)中自我改进的视觉推理
Zhiyu Pan Yizheng Wu Jiashen Hua Junyi Feng Shaotian Yan Bing Deng Zhiguo Cao Jieping Ye
摘要
推理已成为大语言模型的一项关键能力。在语言任务中,可以通过自我提升技术来增强这种能力,即优化推理路径,以便用于后续的微调。然而,将这些基于语言自我提升方法扩展到视觉-语言模型(VLMs)时面临着一个独特的挑战:推理路径中的视觉幻觉难以被有效验证或纠正。我们的解决方案基于对视觉对比现象的一个关键观察:当面对对比性的视觉问答(VQA)对(即两个视觉上相似、问题含义相同的样本)时,VLMs 能够更精准地识别相关的视觉线索。受此启发,我们提出了视觉对比式自教学推理器(Visual Contrastive Self-Taught Reasoner, VC-STaR),这是一种利用视觉对比来缓解模型生成推理过程中幻觉的新型自我提升框架。我们收集了多样化的 VQA 数据集,根据多模态相似度构建对比对,并使用 VC-STaR 生成相应的推理过程。由此,我们构建了一个新的视觉推理数据集 VisCoR-55K,并通过监督微调进一步提升了多种 VLMs 的推理能力。
一句话总结
作者提出了视觉对比自学习推理器(VC-STaR),这是一个自我改进框架,通过利用对比 VQA 对来优化推理路径并构建 VisCoR-55K 数据集,从而减轻视觉语言模型中的视觉幻觉。该数据集随后用于通过监督微调提升各种 VLM 的推理能力。
核心贡献
- 提出了视觉对比自学习推理器(VC-STaR),作为一个自我改进框架,利用视觉对比来减轻模型生成推理依据中的幻觉。这种方法利用了这样一个观察结果:当呈现对比性视觉问答对时,视觉语言模型能更精确地识别相关视觉线索。
- 构建了一个名为 VisCoR-55K 的新视觉推理数据集,通过从多样化的 VQA 数据集中策划对比对,并使用所提出的框架生成推理依据。该数据集作为资源,用于通过监督微调训练模型。
- 使用此数据集进行监督微调被证明能提升各种视觉语言模型的推理能力。这些结果证实,视觉对比能有效减轻推理路径中的幻觉。
引言
推理能力对于大型模型至关重要,然而将自我改进技术应用于视觉语言模型(VLMs)仍然困难,因为视觉幻觉难以轻易验证。现有方法侧重于文本连贯性,往往无法纠正模型优先考虑文本先验而非实际视觉证据的错误。作者通过引入视觉对比自学习推理器(VC-STaR)来解决这一问题,该框架使用对比 VQA 对来优化推理路径并减轻幻觉。该方法生成了 VisCoR-55K 数据集,与现有基线相比,该数据集显著提升了各种基准测试中的推理能力。
数据集
-
数据集组成与来源
- 作者聚合了 21 个 VQA 数据集,涵盖五个类别:推理、图表、数学、通用和 OCR。
- 这种多样化的集合确保了微调模型在广泛任务谱系中的泛化能力。
-
子集细节与过滤
- 使用贪婪的首次匹配退出搜索算法策划了 24 万原始对比 VQA 对的初始池。
- 基于难度的采样仅保留中位数样本,即模型最初失败但在对比提示下成功的样本。
- 最终的 VisCoR-55K 数据集包含经过质量控制推理依据生成后的高保真样本。
- 每个对比对包含同义问题和视觉上相似但需要细粒度区分的图像。
-
模型使用与处理
- 数据支持监督微调以增强视觉推理能力。
- 训练输入包括目标图像、问题、答案、粗略推理依据和对比分析。
- 视觉嵌入依赖于基于 ID 的视觉度量学习,而文本使用 GTE 嵌入。
- 基于文本匹配的后期处理步骤过滤掉具有错误推理模式的推理依据。
方法
作者提出了视觉对比自学习推理器(VC-STaR),这是一个旨在通过对比分析减轻视觉语言模型(VLMs)中视觉幻觉的框架。核心洞察在于,当对比相似场景时,VLMs 比单独分析图像能更准确地感知视觉细节。参考朴素回答与对比之间的比较。

如图所示,朴素方法可能导致幻觉细节,而对比两张相似图像(例如不同的滑板技巧)允许模型区分细粒度特征并生成更忠实的推理依据。
构建训练数据的整体流程涉及三个阶段:数据收集、对比对搜索和基于难度的采样。如下图所示:
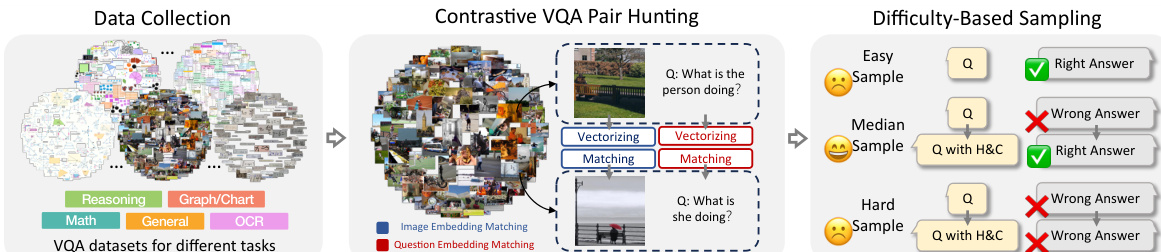
该过程首先聚合各种任务中的多样化 VQA 数据集。系统随后通过向量化图像和问题来执行对比对搜索,以识别具有同义问题和相似视觉上下文的对。最后,应用基于难度的采样来策划不同复杂度的样本,确保模型从简单和具有挑战性的案例中学习,同时过滤掉错误的推理模式。
为了优化推理依据,该方法采用三步对比和重思考过程。如下图所示:

首先,在思考步骤中,VLM 使用思考提示为目标样本 (vi,qi,ai) 生成粗略推理依据 ri。其次,在对比步骤中,VLM 将目标样本与对比对应样本 (v^i,q^i,a^i) 进行比较,以生成对比分析 ci,识别差异或共同模式。第三,在重思考步骤中,大型语言模型(LLM)ψ 利用对比分析 ci 来修正粗略推理依据 ri,生成更合乎逻辑且视觉准确的优化推理依据 r~i。
该过程产生了视觉对比推理数据集 VisCoR-55K。该数据集的分布和示例如下所示。

该数据集包含 5.5 万个样本,涵盖五个类别:通用、推理、数学、图表和 OCR。这些高质量样本用于微调 VLM,增强其在多个基准测试中的推理能力。
实验
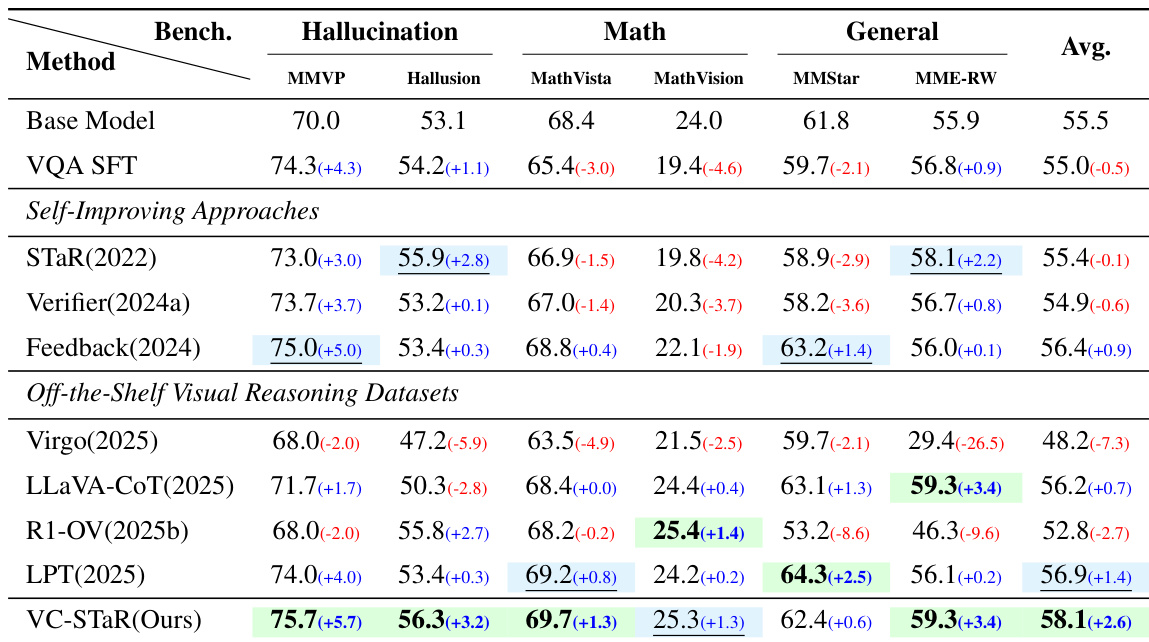
实验评估利用六个基准测试来评估幻觉、数学推理和通用能力,将所提出的方法与自我改进基线以及在外部视觉推理数据集上训练的模型进行比较。结果表明,VC-STaR 通过有效地将文本推理依据扎根于视觉证据中,在所有类别中实现了持续的性能提升,而现有方法经常在减少幻觉的同时牺牲数学和通用能力。额外分析证实该方法在不同基础模型上具有泛化性,并从负对比对中获得最佳性能,同时表明包含简单样本或仅依赖文本推理依据对推理质量有害。
下表展示了消融研究,比较了正负对比 VQA 对对模型性能的影响。虽然两种类型的对都带来了相对于基础模型的改进,但仅使用负对应样本会产生显著更高的收益。当正负对结合时达到最佳性能,证实了它们在视觉推理任务中的互补作用。仅使用负对比对比仅使用正对产生显著更高的性能提升。结合正负对应样本导致在评估基准测试中的最高总体得分。涉及属性比较和对象选择的任务在使用负对比对时显示出最实质性的改进。

作者在幻觉、数学和通用基准测试上评估了所提出的方法 VC-STaR,与基础模型、自我改进基线以及在现成视觉推理数据集上训练的模型进行比较。结果表明,VC-STaR 在所有类别中实现了持续的性能提升,特别是在减轻幻觉和增强数学推理方面优于其他方法。与其他经常为了减少幻觉而牺牲数学或通用能力的自我改进方法不同,VC-STaR 保持了平衡的收益,而没有在其他领域出现显著退化。VC-STaR 通过避免常见的权衡(即幻觉抵抗力的提升以牺牲数学或通用推理能力为代价)优于现有的自我改进基线。在现成数据集上训练的模型显示出混合结果,与 VC-STaR 采用的视觉原生策略相比,纯文本推理依据方法被证明无效。所提出的方法表现出更优的平均性能,并且与基础模型和其他竞争技术相比,在幻觉基准测试中显示出显著改进。
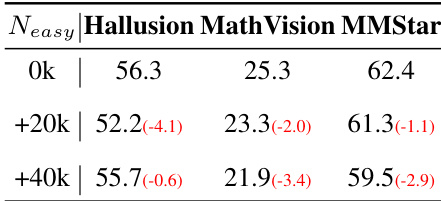
作者研究了将简单样本纳入训练数据集对模型视觉推理性能的影响。结果表明,添加这些样本通常是有害的,与基线相比导致幻觉、数学和通用基准测试中的性能下降。因此,该方法排除了简单样本以避免潜在的过度思考并保持最佳能力。包含简单样本导致与基线相比在幻觉、数学和通用基准测试中性能下降。随着简单样本数量的增加,数学推理和通用感知能力显示出一致的退化。作者确定简单样本对模型的推理能力有害,并从最终设置中排除它们。
作者通过将 VC-STaR 方法应用于不同的基础模型(具体为 Qwen2.5VL-3B 和 InternVL2.5-8B)来评估其泛化能力。结果表明,启用该方法持续地提升了两种架构在幻觉、数学推理和通用能力基准测试中的性能。将方法应用于 Qwen2.5VL-3B 模型导致在所有测试基准测试中可衡量的改进。当利用该方法时,InternVL2.5-8B 模型也表现出一致的性能提升。这些发现验证了该技术的不依赖于模型的特性,表明它在不同视觉语言模型大小和系列中都能有效工作。

实验通过消融研究和与各种基线的比较验证了 VC-STaR 方法,以评估其对视觉推理任务的影响。消融研究揭示,结合正负对比对可实现最佳性能,而添加简单样本被发现对模型能力有害。总体而言,VC-STaR 通过平衡幻觉减少与数学和通用推理收益,优于现有的自我改进技术,证明了在不同模型架构中的一致改进。