Command Palette
Search for a command to run...
Macaron-A2UI:个人 Agent 中生成式 UI 的模型
Macaron-A2UI:个人 Agent 中生成式 UI 的模型
摘要
随着个人智能体(personal agents)不断演进以处理复杂、以用户为中心的任务,静态纯文本聊天正迅速成为瓶颈。生成式用户界面(Generative UI)作为一种必要的新接口层应运而生,它能够根据交互上下文实时动态合成合适的控件、选项和状态。我们提出了 Macaron-A2UI,这是一种面向个人智能体的生成式用户界面模型。我们的目标是通过使智能体能够同时生成自然语言与轻量级、可执行的用户界面操作,从而超越仅基于文本的交互方式,这些操作涵盖信息收集、偏好细化、确认以及多目标组织。我们从异构对话源构建了一个大规模的生成式用户界面语料库,引入了 A2UI-Bench 用于受控评估,并采用基于参数高效 LoRA 的监督微调,随后进行基于奖励的强化学习,训练了 30B、235B 和 754B 参数的模型。在无需显式模式提示的情况下,最佳 Macaron-A2UI 模型在 A2UI-Bench 上取得了 75.6 的整体得分,超越了最强的全模式前沿基线模型。我们发布了这些模型、基准测试及评估协议,以支持未来关于个人智能体生成式用户界面的研究工作。
一句话总结
作者提出了 Macaron-A2UI,这是一种面向个人 Agent 的生成式 UI 模型,它将自然语言与可执行界面操作相结合。该模型基于大规模异构对话语料库,采用参数高效的基于 LoRA 的监督微调(SFT)进行训练,随后进行基于奖励的强化学习。在无需显式模式提示的情况下,该模型在 A2UI-Bench 上取得了 75.6 的整体得分,超越了最强的全模式前沿基线模型。
核心贡献
- 本文介绍了 Macaron-A2UI,该模型在固定的声明式协议下同时生成自然语言和可执行的 UI 操作,以支持个人 Agent 的动态界面。模型采用两阶段训练流程,结合了参数高效的基于 LoRA 的监督微调与基于奖励的强化学习。
- 本研究从异构对话来源构建了大规模生成式 UI 语料库,并发布了 A2UI-Bench,这是一个用于评估动态生成界面协议合规性与交互质量的受控评估框架。
- 实验表明,该训练方法提升了协议正确性与交互质量,其中最佳的 235B 模型在无需显式模式提示的情况下,于 A2UI-Bench 上取得了 75.6 的整体得分。这些结果表明,生成式界面能力可以在训练过程中内化,而无需在推理阶段依赖繁重的模式提示。
引言
随着个人 AI Agent 处理日益复杂且以用户为中心的任务,静态纯文本界面正逐渐成为瓶颈。生成式 UI 通过动态合成轻量级、可执行的控制组件来解决这一问题,直接在交互循环中简化信息收集、偏好优化和多目标组织。既往研究主要集中在纯文本对话、代码生成或导航现有界面,导致在大规模 UI grounded 训练数据、严格的评估基准以及模型内化界面生成(无需冗长模式提示)的成熟方法方面存在关键空白。作者利用统一框架,在生成自然语言的同时输出可执行的 A2UI 操作序列。他们构建了大规模生成式 UI 语料库,引入了 A2UI-Bench 评估套件,并使用参数高效的监督微调与基于奖励的强化学习两阶段流程训练模型。该方法证明 Agent 能够内化结构化界面生成能力,在极简提示设置下无需显式模式提示即可实现顶尖性能。
数据集
-
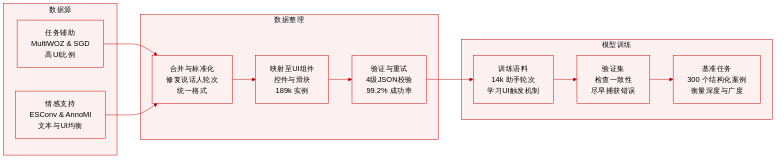
数据集构成与来源: 作者通过整合四个异构来源数据集构建了基于 A2UI 的对话语料库:用于任务导向辅助的 MultiWOZ 2.2 和 Schema-Guided Dialogue (SGD),用于情感支持的 ESCONv,以及用于动机访谈的 AnnoMI。
-
子集详情与采样策略: 最终训练语料库包含从 4,306 个基础对话中提取的 14,245 个助手轮次样本,分为 10,210 个 UI 轮次和 4,035 个纯文本轮次。AnnoMI 经过过滤仅保留高质量子集,并通过针对组件的增强进行扩展。SGD 采用单轮次采样策略,每个对话仅提取一个信息量极高的助手轮次,以优先考虑服务覆盖范围而非对话深度。
-
处理与验证流程: 同一说话者的连续话语被合并,以强制执行严格的用户与助手交替格式并消除分割伪影。随后,作者将异构注释标准化为统一的中间表示形式,将对话行为和指导行为映射到特定的 A2UI 组件族,如选择控件、滑块、复选框和日期选择器。四级代码检查流程用于验证 JSON 格式、结构类型、数据绑定和语义一致性。未通过的样本最多经历三次错误反馈重试,最终渲染率达到 99.2%。
-
训练用途与数据集特征: 作者使用该语料库进行大规模模型监督训练,有意保留源领域的自然 UI 与文本比例。任务导向来源保持约 80% 的高 UI 比例,而支持性对话来源保持平衡,以避免扭曲共情交互。该数据集提供了约 189,000 个组件级实例,通过原始样本与针对性增强的结合,教导模型何时触发 UI、选择何种组件,以及如何生成符合协议的输出。
方法
作者利用参数高效的两阶段训练流程开发具备 A2UI 能力的助手,该流程包含监督微调(SFT)与组相对策略优化(GRPO)。两个阶段均采用 LoRA 适配来更新少量低秩参数,避免对骨干模型进行全量微调。该流程在 Qwen3-30B-A3B-Instruct-2507 和 Qwen3-235B-A22B-Instruct-2507 上实现,并将 GLM-5.1 作为额外骨干模型纳入,同时在所有训练阶段保持固定的输出协议。训练目标是生成统一的助手响应,整合自然语言文本与结构化 A2UI 操作。
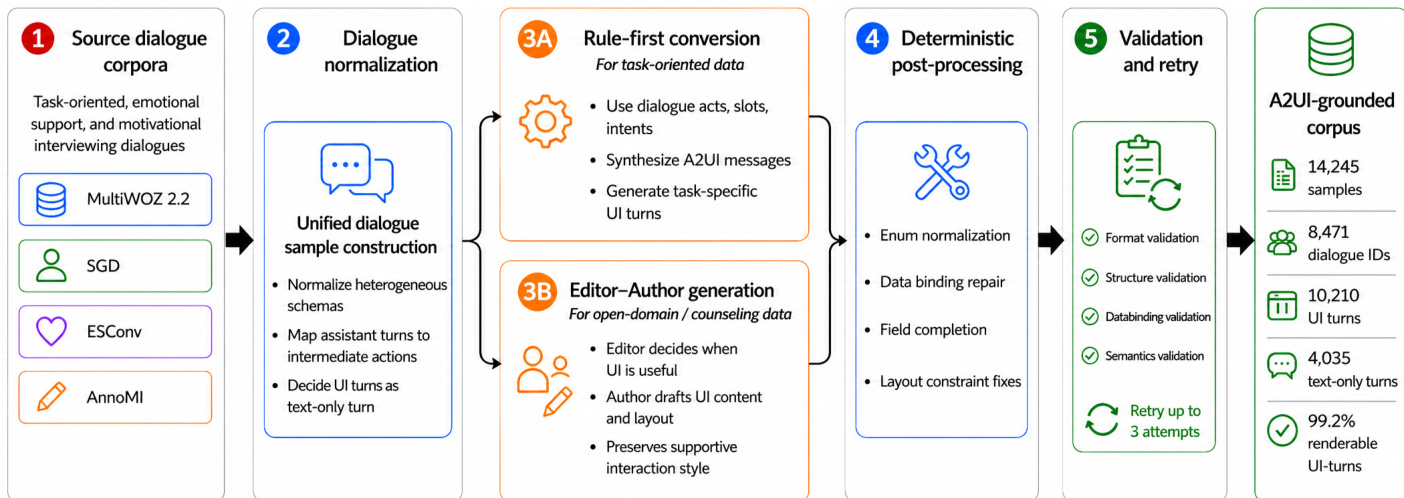
SFT 阶段通过在聊天风格的提示与响应对上进行训练,教导模型基本响应格式。每个样本包含系统指令和对话历史,目标响应被结构化为一个 JSON 对象,其中包含自然语言 text_response 和 A2UI 操作列表。训练目标为标准自回归负对数似然,仅计算对话中最终助手轮次的损失。该方法直接指导模型联合生成流畅文本与可执行 UI 操作,将界面生成视为响应的内在组成部分,而非后处理步骤。
SFT 之后,GRPO 阶段在面向交互的奖励下优化模型行为。从 SFT 模型出发,策略通过组相对优势进行优化。对于每个提示,采样一组候选响应,并使用评估结构质量、任务构建质量和用户级效用的奖励函数对每个响应进行打分。优势值计算为候选响应奖励与组平均奖励的差值,随后用于计算优化目标。该阶段对于难以通过单一黄金标准进行监督的属性尤为有效,例如 UI 触发、操作完整性以及跨不同结构有效响应的交互质量。
GRPO 奖励函数围绕可执行的 A2UI 质量设计,针对格式错误的 JSON、缺失的 A2UI 输出、协议级验证失败和渲染关键错误设置了硬性结构门限,这些情况均导致零奖励。对于有效响应,奖励是底层正确性(SL1)、任务构建质量(SL2)和用户级效用(SL3)的加权组合。该设计确保强化学习与核心目标保持一致,即同时生成可执行、恰当且在实际交互中真正有用的响应。
实验
评估通过互补的语言侧协议检查与视觉侧渲染评估来检验 A2UI 生成能力,在仅使用轻量提示的条件下测试模型以验证内化能力,并使用重度模式提示建立性能上限。这些实验验证了监督微调与强化学习流程,表明训练后的模型在无需显式模式指令的情况下,性能显著优于未调优的前沿模型。定性分析表明,强化学习首先稳定基础的协议与结构技能,随后逐步优化高层交互设计与跨领域适应性。最终,该方法使模型能够可靠地将对话意图转化为简洁、视觉连贯且可直接用于交互的用户界面。
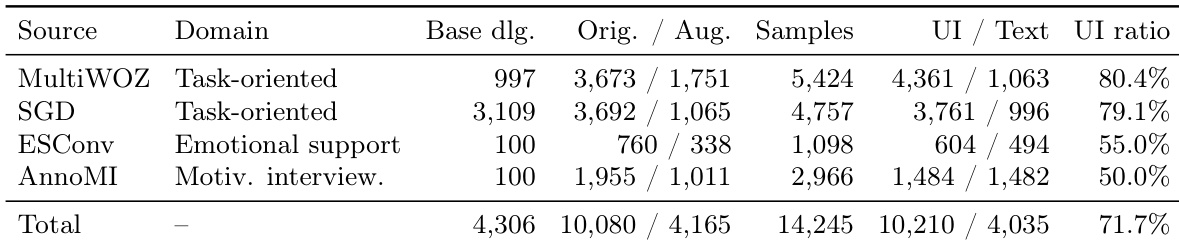
下表按来源、领域和数据类型展示了评估数据集的细分情况,显示了对话样本数量及其在文本与 UI 组件间的分布。数据表明不同领域和来源数据集的分布均衡,所有类别的 UI 与文本比例保持一致。数据集涵盖多个领域,包括任务导向、情感支持和动机访谈,且所有来源的 UI 与文本比例一致。评估集在四个来源数据集和三种任务格式上保持平衡,确保结果不受单一来源影响。样本总数在原始数据与增强数据之间分配,大多数类别中增强数据的比例较高。
作者使用语言侧与视觉侧指标评估 A2UI 生成能力,在轻模式与重模式设置下比较模型。结果表明,监督微调与强化学习显著提升了各规模模型的性能,训练后的模型即使在没有完整模式提示的情况下也能取得优异结果,而前沿模型需要模式提示才能达到竞争水平。监督微调与强化学习在语言和视觉评估指标上均带来显著提升。训练后的模型在无模式提示下表现强劲,优于需要模式提示才能达到竞争水平的未调优前沿模型。最大规模的训练模型取得了最高整体得分,并展现出强大的跨领域鲁棒性,在任务构建和交互质量方面获得显著提升。
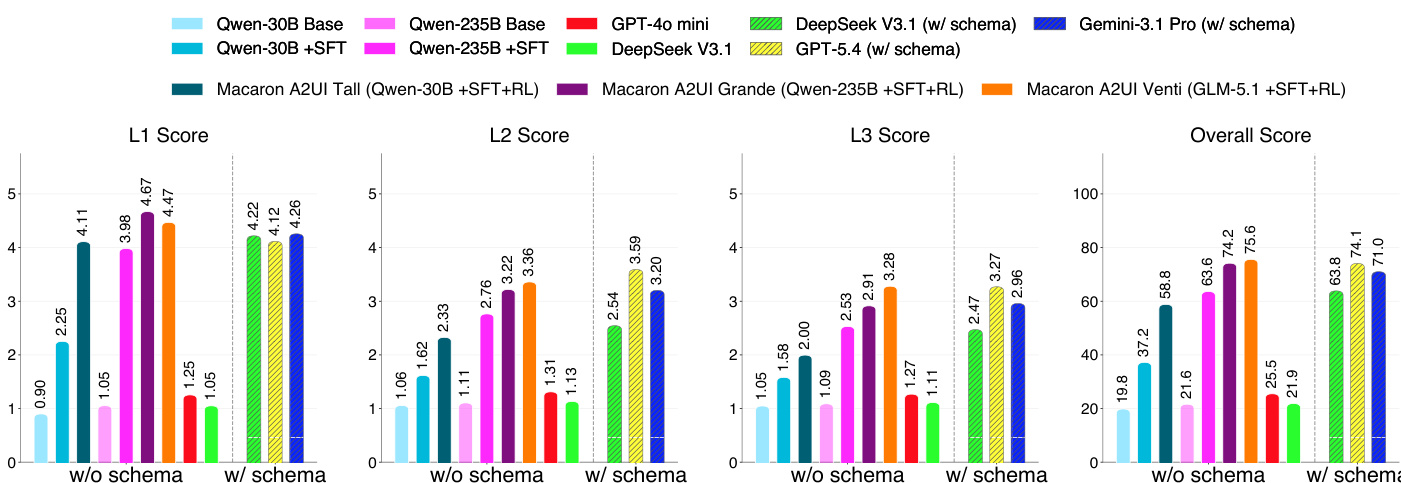
作者使用语言侧与视觉侧指标评估模型在 A2UI 生成上的表现,在包含模式与轻模式提示下比较模型。结果表明,微调模型的得分高于未微调模型,性能在不同评估维度(如协议正确性和交互质量)上有所差异。在轻模式提示下,微调模型的整体得分高于未微调模型。性能因评估维度而异,部分模型在协议正确性上表现突出,而其他模型在交互质量上表现更好。与仅使用监督微调相比,采用强化学习训练的模型在多项指标上均有所提升。
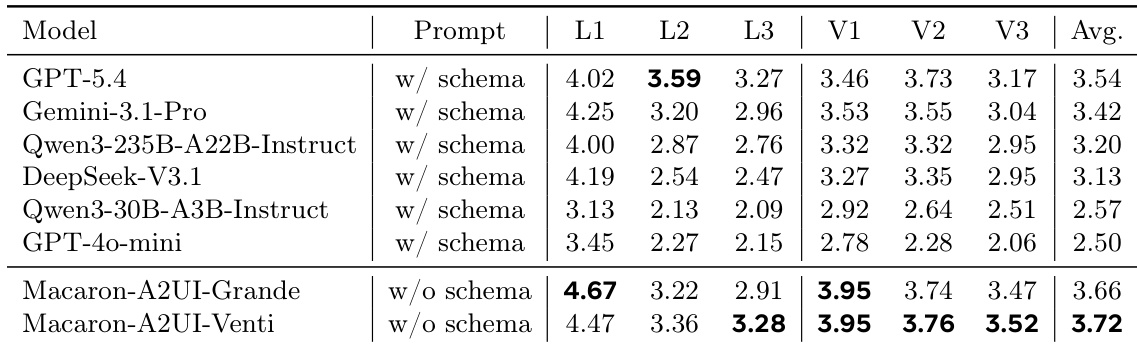
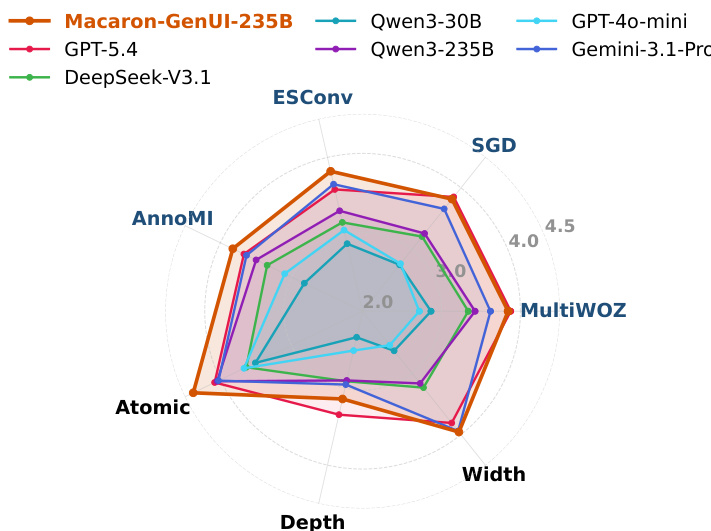
作者使用语言侧与视觉侧指标评估 A2UI 生成,重点关注协议正确性、任务构建和交互质量。结果表明,监督微调与强化学习显著提升了各规模模型的性能,训练后的模型即使在没有模式提示的情况下也优于未调优的前沿模型,且最强模型在多个数据集和任务类型上均取得高分。训练后的模型展现出鲁棒性,并在结构与交互质量上保持稳定提升,尤其在原子任务和宽度任务中表现突出,而在深度任务中性能有所波动。监督微调与强化学习显著提升了各规模模型的 A2UI 生成性能。训练后的模型在无模式提示下优于未调优的前沿模型,证明 A2UI 能力得到了有效内化。最强模型在数据集和任务类型上取得高且稳定的分数,在原子任务和宽度任务中改善显著。
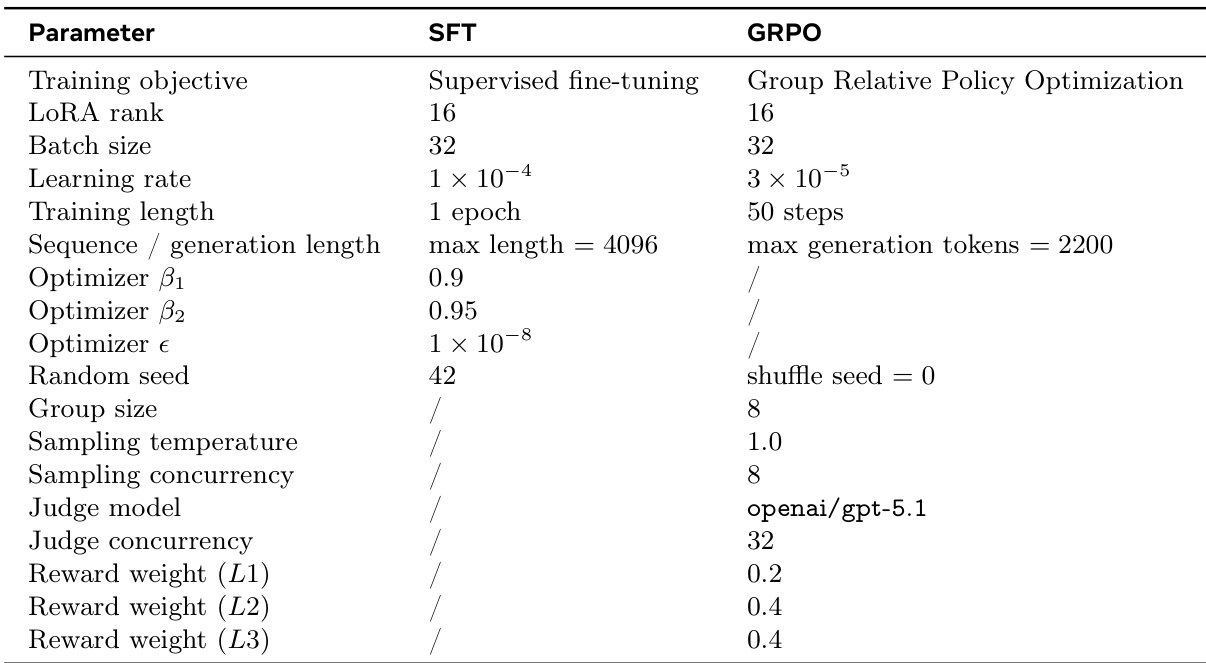
作者采用包含监督微调与组相对策略优化的两阶段训练流程,下表详细列出了两个阶段的关键超参数。两个阶段的训练目标与优化设置有所不同,SFT 侧重于结构正确性,而 GRPO 通过加权奖励强调交互质量。SFT 使用 1e-4 的学习率并训练一个 epoch,而 GRPO 使用较小的 3e-5 学习率并运行 50 个步骤。GRPO 引入了基于评判的奖励,并为 L1、L2 和 L3 组件分配了不同权重,表明其重点在于提升交互质量。两个阶段均使用 LoRA rank 16 和 batch size 32,表明训练阶段间保持一致的适配与数据处理策略。
评估在平衡的多领域数据集上,使用语言和视觉指标在不同提示条件下检验 A2UI 生成能力。这些实验通过将训练模型与未调优的前沿基线进行比较,验证了监督微调与强化学习的影响。定性来看,联合训练方法显著提升了结构准确性与交互质量,使模型在无需显式模式提示的情况下仍能保持竞争力,并展现出强大的跨领域泛化能力。