Command Palette
Search for a command to run...
SpatialBench:你的空间基础模型是全能选手吗?
SpatialBench:你的空间基础模型是全能选手吗?
摘要
尽管空间基础模型在标准数据集上已展现出卓越的性能,但一个关键问题仍未得到解答:它们是否真正具备全能选手的特质,能够在多样化的下游任务、任意视角、动态变化的场景域、不同的输入密度以及特定的硬件约束下实现稳健的泛化?解答这一宏观问题需要进行全面评估,然而现有模型主要在其专门设计或训练的特定领域上进行测试。此类评估本质上受限于范式覆盖范围狭窄、场景域有限以及帧采样具有任意性,这使得从根本上评估其真实的泛化能力变得极为困难。为弥补这一研究空白,我们提出了SpatialBench,这是一个面向空间基础模型的跨范式、多领域基准测试集,并采用确定性采样策略。SpatialBench具备前所未有的规模与严谨的确定性设计,涵盖5个多样化空间领域的19个数据集及546个场景。该基准在4种不同的输入密度设置下,针对5组任务套件,全面评估了涵盖6种范式的41个模型。我们的广泛评估表明,现有模型尚未达到全能选手的水平,并揭示了推动未来发展的关键洞见。具体而言,我们证实全上下文注意力机制能够最大化预测精度,而有界内存策略则能够释放长序列的可扩展性。此外,我们在具有挑战性的具身智能与第一人称视角任务中的实证评估表明,严格的领域对齐与高质量数据对模型性能的影响远大于单纯的数据集规模扩展。此外,为弥补分析中所识别出的最大数据缺口,我们超越了单纯的评估工作,引入了大规模数据集DA-Next-5M及强基线模型DA-Next,从而进一步拓展了空间表示学习的边界。
一句话总结
SpatialBench 引入了一项综合性基准测试,用于在多样化的下游任务、任意视角、变化的场景域、不同的输入密度以及特定硬件约束下评估空间基础模型,从而检验其超越标准数据集的鲁棒泛化能力。
核心贡献
- SpatialBench 提供了一个确定性的、标签感知的评估框架,支持在不同输入密度、视角类型和场景动态下进行系统的跨范式比较。这一独立基准测试建立了一套统一协议,用于评估空间基础模型,而此前针对特定模型的评估套件缺乏受控的评估标准。
- 针对 41 个模型和六种范式的广泛实验表明,当前的空间基础模型在域变化和输入密度变化下缺乏鲁棒的泛化能力。这些结果指出了领域适应性和输入密度弹性方面的关键性能差距,限制了模型在真实视频流中的一致性表现。
- 为解决在挑战性视角下识别出的数据稀缺问题,本研究引入了 DA-Next-5M,这是一个专为第一人称视角和手腕视角序列定制的大规模数据集。基于该数据集训练的对应基线模型为未来可扩展内存管理和长距离几何对齐的改进提供了重要的参考基准。
引言
空间基础模型已成为机器人、自动驾驶和 AR/VR 应用的关键基础架构,其能够从标准 2D 图像中实现精确的 3D 场景重建。尽管已被广泛采用,但实际部署要求在不可预测的域偏移、高度变化的输入密度以及严格的硬件约束下均保持鲁棒性能。以往的评估工作存在不足,因为它们通常将特定模型范式孤立出来,依赖不一致的采样协议,且极少测试系统在密集视觉流或内存限制下的扩展能力。为弥补这一差距,本文提出 SpatialBench,这是一个标准化的跨范式基准测试,系统性地评估了六个架构家族中的四十一款模型、十九个数据集以及四种确定性密度配置。通过建立统一的评估协议,本研究揭示了精度与可扩展性之间的根本权衡,同时引入 DA-Next-5M 数据集和 DA-Next 基线模型以解决关键的第一人称感知缺口,最终推动该领域向更具泛化能力的空间智能发展。
数据集
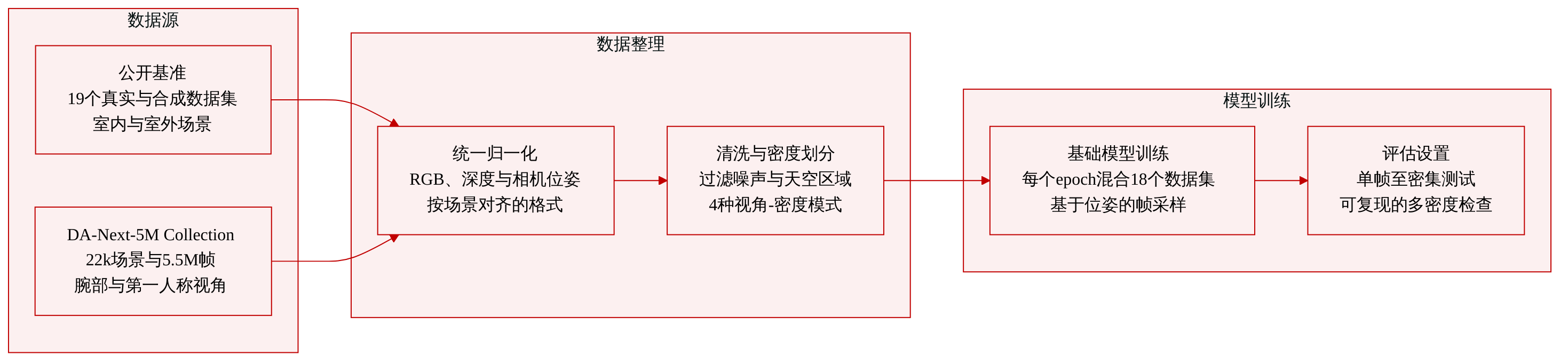
-
数据集构成与来源
- 本文整合了 19 个公开的实采与合成数据集至 SpatialBench,涵盖室内外环境中的 546 个场景和 72,540 帧评估图像。
- 该集合包含静态与动态内容,采集视角涵盖常规视角、第一人称视角以及手腕佩戴视角。
- 专用的单帧混合数据集(Single-frame Mixture)将 Lingbot-Depth 与所有基准数据集结合,以支持单目深度评估。
- 配套数据集 DA-Next-5M 包含 22,000 个场景和 550 万帧图像,专注于第一人称与手腕视角,数据来源于实采视频及 RLbench、Robo Colosseum、RoboTwin 和 Robolab 等机器人模拟器。
-
各子集关键细节
- 静态实采子集包括 7-Scenes、DTU、NRGBD、Scannet++、Tanks & Temples 和 ETH3D,用于提供高质量的真实几何参考。
- 动态实采子集包含 TUM-Dynamic、DROID、Xperience、Waymo 和 KITTI-Odometry,覆盖室内活动与街道级驾驶场景。
- 动态合成子集包括 ADT、RLBench with Colosseum、RoboTwin、Robolab、Virtual KITTI 2 和 OmniWorld-Game,利用域随机化技术调整背景、物体属性与相机位姿。
- DROID 子集经过严格筛选,采用立体深度估计(S²M²)、置信度阈值处理、初始位姿估计(MapAnything)、动态物体掩码(SAM3)及光束法平差,以确保时间维度上的深度一致性。
- Xperience 子集采用基于 VIPE 的 SLAM 获取位姿,并使用 FoundationStereo 进行度量深度估计;仿真数据集被调整至 1280x720 或 512x512 分辨率,并调整相机外参以捕捉机械臂交互过程。
-
数据使用与训练配置
- 在评估阶段,本文为每个场景构建四种确定性的视图密度配置:SINGLE(固定单帧)、SPARSE(基于体素集覆盖以保证视角多样性)、MEDIUM(偏向重叠的集覆盖)以及 DENSE(长视野时间连续性,并设置最大帧数预算)。
- 在训练 DA-Next 基础模型时,本文合并了 18 个数据集,包括 DA-Next-5M、HyperSim、Infinigen、Spring、MapFree、Matterport 3D、MVS-Synth、ScanNet++、TartanAir、Unreal 4K、Virtual KITTI 和 Waymo。
- 训练采用固定的混合比例,每个 epoch 独立采样,且每个批次严格包含 18 帧,分别从 2 到 18 个随机场景中抽取。
- 帧选择基于相机位姿的欧氏距离,围绕随机选取的锚点帧进行排序,并从其最近的有效范围内采样,以维持空间一致性。
-
处理流程与元数据构建
- 所有原始数据集均被归一化为统一的结构化表示,包含 RGB 帧、度量深度图、相机内参以及相机到世界坐标系的位姿。
- 评估输入通过 JSON 记录与数据读取解耦,明确指定每个场景及各密度配置下的精确帧索引,从而保证可复现的多密度采样。
- 统一的五阶段深度清洗流程依次执行范围裁剪、离群点去除、边缘感知双边滤波、小孤立区域移除以及语义天空掩码,以过滤不可靠像素。
- 仿真数据包含广泛的域随机化设置;手腕视角序列则通过计算逐像素重投影深度误差进行筛选,剔除时间一致性较差的序列。
方法
本文的模型 DA-Next 采用基于 Transformer 的架构,该架构基于 Depth-Anything-3 的 Giant 变体构建。该框架处理输入图像序列,记为 I={Ii}i=1N,并可选择性地引入相机参数 C={Ci}i=1N={Ki,Gi}i=1N,其中 Ki 为内参矩阵,Gi 为外参位姿。模型架构旨在联合预测深度图、射线图与全局缩放因子,从而实现度量级 3D 点云的重建。
整体流程首先将输入帧划分为 patch tokens,记为 ef。随后将其与 camera tokens ec 和 scale tokens es 拼接,形成统一的 tokens 序列,并由 Transformer 编码器 E 进行处理。camera tokens 在可用时直接由真实相机信息生成,否则作为可学习参数。该 Transformer 编码器包含 L 层,交替使用帧级自注意力与全局自注意力模块,使模型能够捕捉场景内的局部与全局依赖关系。如下图所示,编码器的输出 (e^c,e^s,e^f) 将用于生成最终预测结果。patch tokens e^f 与 camera tokens e^c 被输入至 Dual-DPT 预测头,以生成深度图 D^ 与射线图 R^ 的预测值。同时,scale tokens e^s 经过轻量级多层感知机(MLP)处理,回归出标量缩放因子 S^。预测得到的深度图、射线图与缩放因子随后被用于重建场景点云。
实验
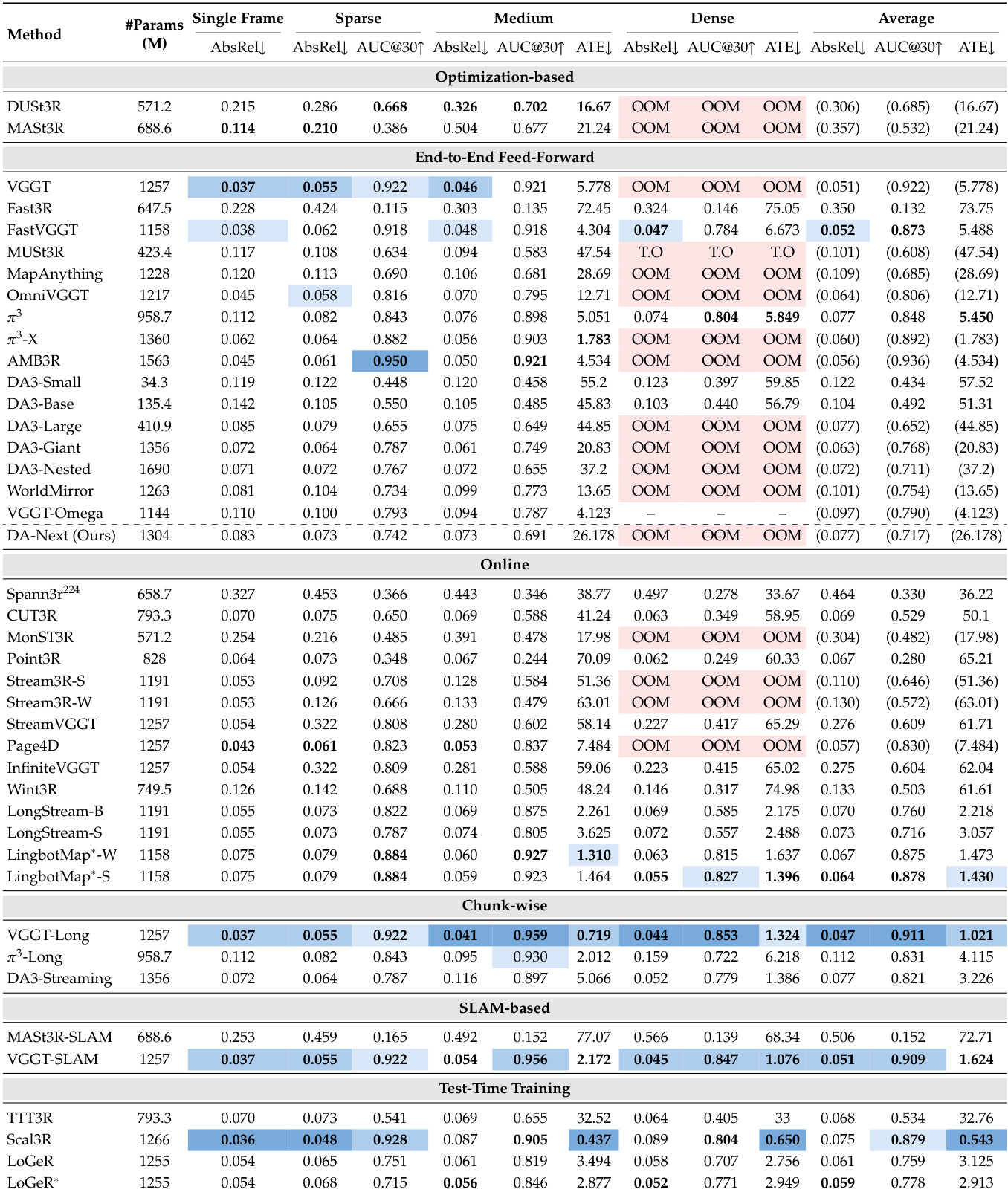
该评估在空间重建任务上对六种架构范式的 41 款模型变体进行基准测试,验证了其在不同输入密度、硬件约束及辅助先验注入下的性能表现。定性分析表明,全上下文注意力模型能够实现最高的几何精度,但受限于内存容量;而有限内存与测试时训练方法则成功在长视野场景中实现了精度与可扩展性的权衡。实验进一步证明,训练数据的质量与域多样性对泛化能力起决定性作用,针对代表性不足视角的定向数据筛选能显著缩小性能差距。最终结果表明,最优的空间基础模型需在架构效率与精心筛选的域特定数据之间取得平衡,而非单纯依赖增加数据集规模或输入密度。
实验在 SpatialBench 上对六种范式的 41 款模型变体进行评估,考察其在单帧、稀疏、中等与密集输入设置下的表现。全上下文前馈模型在内存受限条件下实现最高精度,而流式与在线方法支持在有限内存下进行长序列重建,但深度估计精度有所降低。训练数据质量,尤其是域内数据覆盖率,对不同域下的模型性能具有强烈影响。全上下文前馈模型在内存约束下精度最高,在重建质量上优于流式与在线方法。流式与在线方法支持有限内存下的长序列重建,但其深度估计精度仍低于全上下文模型。模型性能高度依赖训练数据质量与域覆盖率,域内数据能在各类任务与设置中带来更优结果。
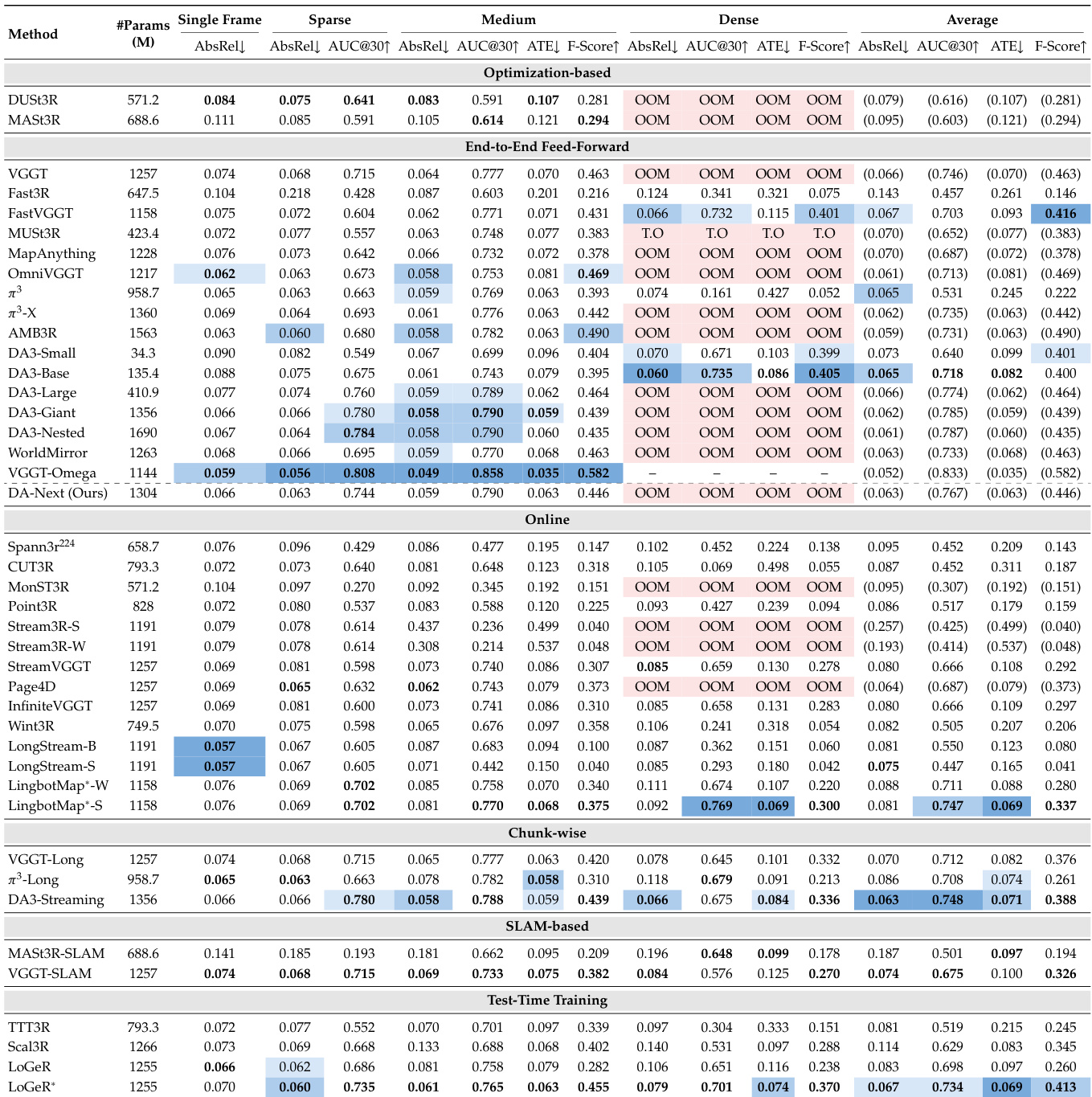
实验在 SpatialBench 上对六种重建范式的 41 款模型变体进行评估,考察其在单帧、稀疏、中等与密集输入设置下的表现。结果表明,全上下文前馈模型精度最高,尤其在深度与相机位姿估计方面,而有限内存模型则以精度换取可扩展性。表现最优的方法因输入配置与域而异,训练数据覆盖率是预测各域性能的关键指标。全上下文前馈模型在多数指标上精度最高,尤其在深度与相机位姿估计方面,但常因内存限制在密集输入下失效。有限内存模型(如流式与分块方法)在长序列下保持可扩展性,但重建精度低于全上下文模型。训练数据的域覆盖率比模型架构或数据集规模更能预测性能,在域内数据上训练的模型在其对应域中表现优于其他模型。
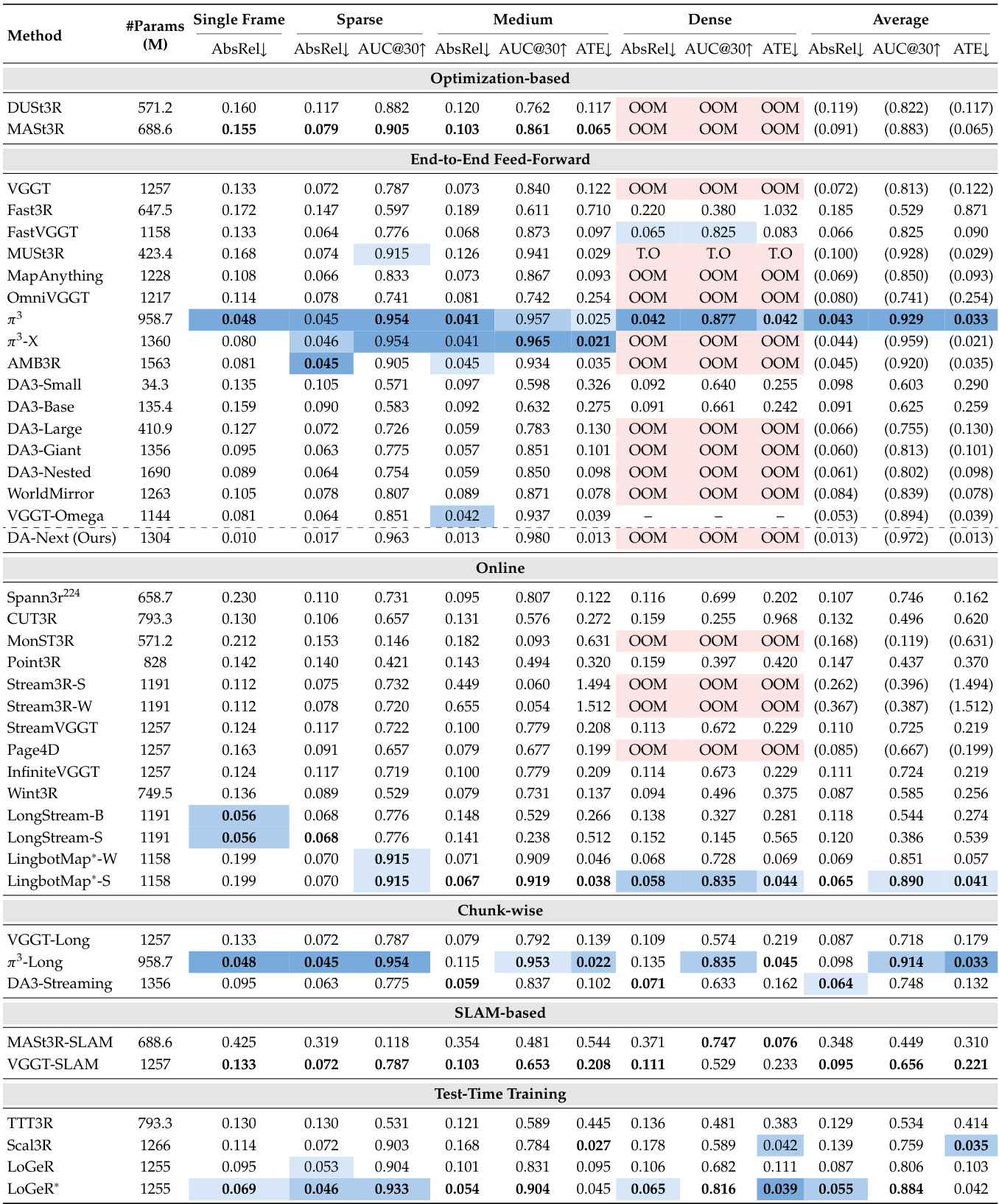
该表格展示了按域分组的多数据集上各类空间基础模型的对比,评估其重建质量。模型按架构范式分类,包括前馈、基于分块、在线及测试时训练等。结果表明不同模型在不同域与输入设置下表现各异。评估强调,在域内数据上训练的模型通常表现更佳,模型选择取决于具体应用需求与输入密度。不同模型在不同域中表现最优,域内训练数据是性能的关键因素。前馈模型通常精度较高,但在长序列上受内存限制。模型性能在不同输入设置下差异显著,由于冗余问题,密集输入并不总能带来更优结果。
实验在 SpatialBench 上对六种范式的 41 款模型变体进行评估,考察其在单帧、稀疏、中等与密集输入设置下的表现。结果表明,全上下文前馈模型精度最高,尤其在深度与相机位姿估计方面,而流式与分块方法在有限硬件上提供更高的可扩展性,尽管精度略低。表现最优的模型因输入配置与域而异,训练数据覆盖率是域内性能的关键因素。全上下文前馈模型在多数指标上精度最高,尤其在深度与相机位姿估计方面,但受限于高内存占用。流式与分块模型以精度换取可扩展性,支持在有限硬件上进行长序列重建。模型性能在不同输入配置与域中差异显著,对于域内成功而言,训练数据覆盖率比数据集规模更具决定性。
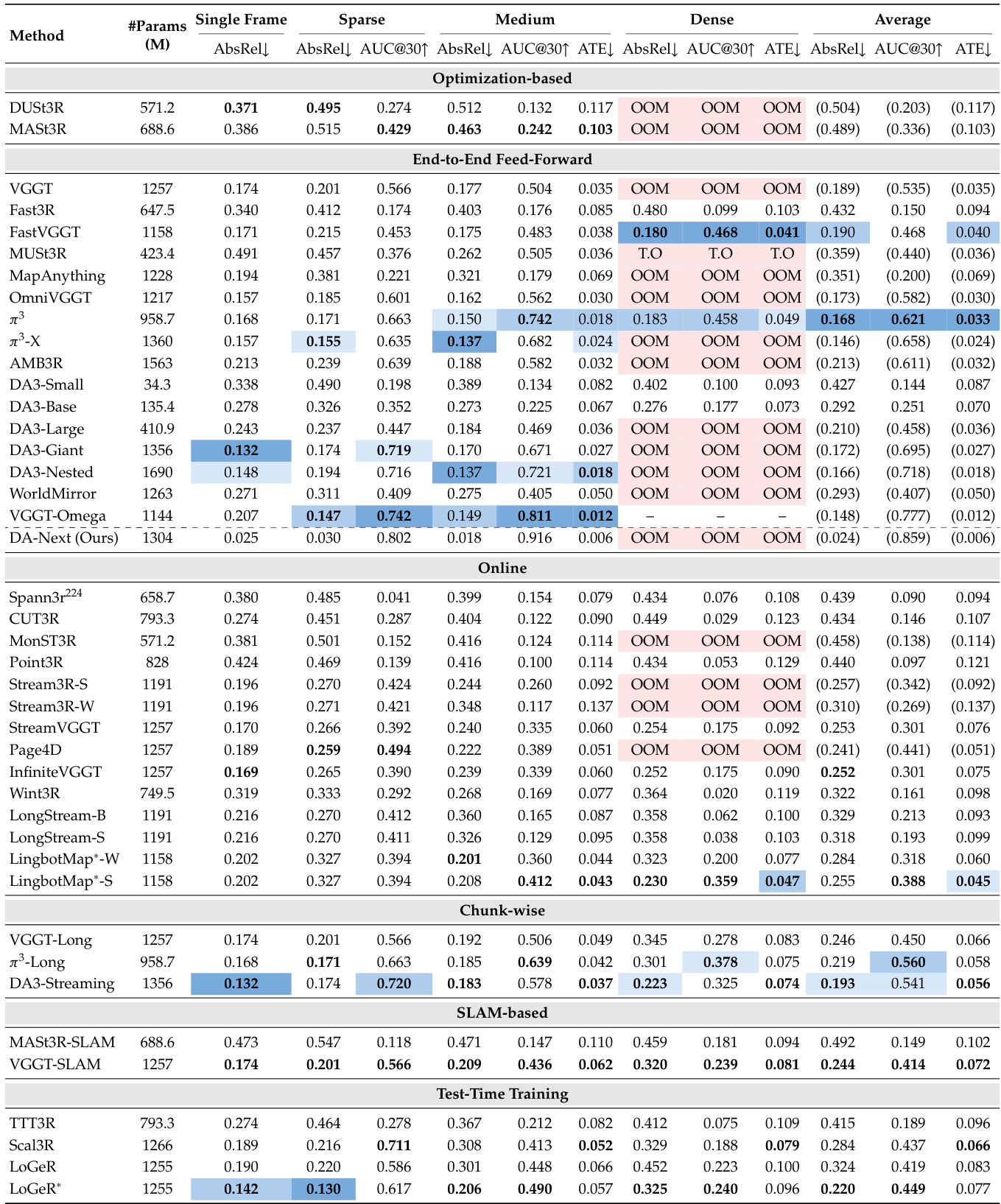
实验在 SpatialBench 上对六种范式的 41 款模型变体进行评估,考察其在单帧、稀疏、中等与密集输入设置下的表现。结果表明,全上下文前馈模型在受限输入下精度最高,而流式与在线方法支持在内存约束下进行长序列重建,但深度精度较低。模型性能在不同域中差异显著,训练数据覆盖率是特定环境成功的关键预测指标。全上下文前馈模型在受限输入下精度最高,在重建质量上优于流式与在线方法。流式与在线模型支持内存约束下的长序列重建,但需以深度精度换取可扩展性。跨域模型性能高度依赖训练数据覆盖率,域内数据比数据集规模更能预测成功概率。
该评估在 SpatialBench 上对六种重建范式的四十一款模型变体进行测试,验证不同架构方法在不同输入密度下如何平衡重建精度与内存约束。结果表明,全上下文前馈模型精度更优,但在长序列上表现吃力;而流式与基于分块的方法牺牲部分精度以实现可扩展的有限内存处理。在所有设置下,性能主要由域内训练数据覆盖率决定,而非模型架构或数据集规模,这凸显了域对齐训练对获取最优结果的重要性。