Command Palette
Search for a command to run...
SMOL:115种代表性不足语言的专业级平行翻译数据
SMOL:115种代表性不足语言的专业级平行翻译数据
摘要
我们开源了 SMOL(Set of Maximal Overall Leverage,最大整体杠杆数据集合),这是一套旨在赋能低资源语言机器翻译的训练数据套件。SMOL 目前已翻译至 124 种(且数量仍在增加)资源匮乏的语言中(涵盖 125 个语言对),其中包括许多此前没有任何公开资源支持的语言,共计生成 610 万个翻译 token。SMOL 包含两个子数据集,均是根据其规模经过精心筛选,以确保产生最大影响:SMOLSENT 是一组旨在实现广泛且独特 token 覆盖率的句子集合;SMOLDOC 则是一个文档级资源,侧重于广泛的主题覆盖。它们与之前发布的 GATITOS 数据集相结合,构成了涵盖段落、句子和 token 级内容的“三剑客”。我们证明了,利用 SMOL 对 Large Language Models(大语言模型)进行 prompt 或 fine-tune,能带来显著且稳健的 CHRF 指标提升。此外,除了翻译内容外,我们还为 SMOLDOC 中的所有文档提供了事实性评级及依据,从而为大多数这些语言构建了首个事实性数据集。
一句话总结
作者开源了 SMOL,这是一套专业翻译的平行数据套件,旨在为 124 种资源匮乏的语言解锁机器翻译,总计 6.1M tokens,涵盖句子级别的 SMOLSENT 和文档级别的 SMOLDOC 子数据集。在提示或微调大型语言模型时,该套件能带来稳健的 CHRF 提升,并为大多数包含的语言提供首个事实性评级和依据。
核心贡献
- 这项工作介绍了 SMOL,一个开源的训练数据套件,旨在为低资源语言解锁机器翻译。SMOL 包含 SMOLSENT 和 SMOLDOC 子数据集,涵盖 124 种资源匮乏的语言,拥有 6.1M 翻译 tokens。
- 实验表明,利用 SMOL 提示或微调大型语言模型,能在翻译任务中带来稳健的 CHRF 提升。
- SMOLDOC 内的所有文档均提供了事实性评级和依据。这一补充为大多数涵盖的语言提供了首个事实性数据集。
引言
机器翻译模型通常缺乏对低资源语言的支持,此处定义为 2020 年之前 Google Translate 支持的 104 种语言之外的语言。现有数据集通常依赖网络爬虫或旧版机器翻译输出,缺乏有效训练所需的质量和数量。为此,作者提出了 SMOL,这是一个针对 115 种代表性不足语言的专业翻译平行数据集。他们利用志愿者贡献和专业翻译,为以往被主要系统排除的语言创建了高质量资源。
数据集
作者介绍了 SMOL,这是一个专业翻译的数据集套件,旨在为 124 种低资源语言解锁机器翻译。该集合总计 6.1M 翻译 tokens,跨越两个互补的子集。
-
数据集构成与来源
- 该套件针对 125 种语言对,源文本选自或生成自英语,以简化质量控制。
- 它通过添加句子和文档级别的内容,补充了现有的 GATITOS token 级别资源。
- 翻译由签订合同的职业翻译人员支付公平工资完成,同时针对特定语言(如粤语)包含志愿者贡献。
-
子集详情
- SMOLSENT: 包含 863 个选自 CommonCrawl 的英语句子,以最大化唯一 token 覆盖(5.5k tokens)。这些句子被翻译成 88 种语言。
- SMOLDOC: 由 LLM 使用涵盖各种主题、语调和领域的多样化模板生成的 584 个英语文档组成。这些文档被翻译成 106 种语言。
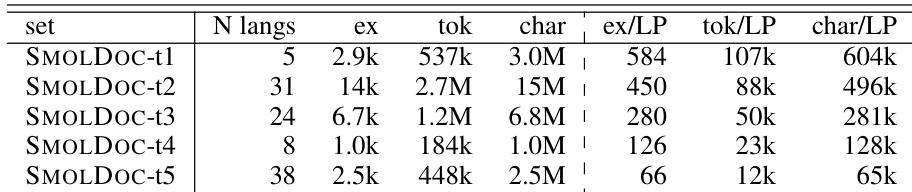
- Language Tiers: SMOLDOC 数据根据使用者人口规模分布在五个层级,使用者语言较多的语言拥有更大的子集。
-
模型使用
- 作者利用该数据对大型语言模型进行微调和提示,在 Gemini 2.0 Flash 上展示了稳健的 CHRF 提升。
- SMOLDOC 包含所有文档的事实性评级和依据,为大多数涵盖的语言创建了首个事实性数据集。
-
处理与验证
- Selection Strategy: SMOLSENT 采用贪心 token 集覆盖算法,并通过 Researcher-in-the-Loop 过程进行优化,以消除蜜罐和短句子偏差。
- Diversity Filtering: SMOLDOC 文档按字符 9-gram 逆文档频率排名以去除冗余,减去 BREAD 分数以降低内部重复的权重。
- Quality Control: 交付物检查重复项、异常长度比率以及与 Google Translate 输出的相似度。
- Validation: FUNLANGID 验证语言身份,而人工检查修正了西非语言和桑塔利语等语言的拼写和脚本问题。
- Factuality Audit: 每份 SMOLDOC 文档由三名人类评估员评级,分配轻微问题、明显问题或正常状态的代码。
方法
作者通过研究人员在环机制扩展了贪心集覆盖方法。系统并非总是选择得分最高的句子,而是迭代地向研究人员展示根据多种得分排名的前 20 个最高分句子批次。研究人员然后在每次迭代中选择并可选择性地编辑每个句子。在每次迭代中,研究人员还可以从储备库中移除该批次的任意数量句子。允许研究人员查看和编辑句子确保了句子的高质量。为了解决长度偏差问题,系统不仅显示最大化覆盖百分比的句子,还显示最大化覆盖与新 token 命中数加权启发式的句子,如 log(coverage_percent)∗n_hits。这种方法旨在解决诸如蜜罐句子之类的问题。示例蜜罐句子如下所示:

CommonCrawl 包含许多内容词密集但无清晰语义或语法的句子。
为了获得 N-shot 结果的强基线,作者采用了一种类似于贪心集覆盖算法的基于 RAG 的方法。对于评估集中的每个句子,目标是尽可能最好地覆盖源句子 n-grams,同时使范例之间的冗余最小。因此,系统迭代地选择源侧与评估源具有最小 ChRF 的范例。然而,在计算 ChRF 计算中的真阳性时,每个 ngram ni 的计数被 (1+ci)−α 加权。这里 ci∈[0,∞] 是 ni 在迄今为止选择的范例中出现的次数,α 是控制该算法接近 ngram 集覆盖程度的参数。作者使用 α=2。选择的范例集是 SMOLSENT 和 SMOLDOCSPLIT 的拼接。
对于 0-shot 提示,作者使用了一个相当冗长的提示,其中 SL 和 TL 分别代表源语言和目标语言名称。提示指示模型充当专家翻译员,并提供文本片段示例对。在示例对之后,模型接收另一个 SL 中的句子,并被要求将其翻译成 TL。指令指定仅给出翻译,不要额外评论。对于微调模型,不需要如此冗长的提示,因为它存在过拟合风险。因此,改用极简提示,仅说明 Translate from SLto {TL}:。
实验
该研究通过在 Gemini 2.0 Flash 上进行微调和上下文学习实验来评估 SMOL 数据集,利用 CHRF 指标跨越 FLORES-200 和 NTREX 基准来验证数据效用。发现表明,组合数据集子集能产生最强的性能提升,特别是对于低资源语言,而在未调整模型上进行上下文学习能达到与微调零样本解码相似的结果。此外,选择过程实验证实了集覆盖方法的有效性,尽管反向翻译任务揭示了严重的过拟合,需要将重点限制在英语到其它语言的方向上。
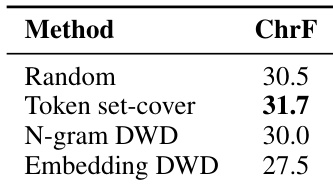
作者评估了不同的数据选择策略,以验证 SMOLSENT 数据集的有效性,用于微调机器翻译模型。他们比较了 Token set-cover 与 N-gram DWD、Embedding DWD 以及随机基线,以确定最佳选择方法。结果表明,Token set-cover 是最有效的方法,相比其他技术实现了更优的性能。Token set-cover 在所有测试的选择方法中实现了最高性能。Embedding DWD 相比其他方法导致最低性能。随机选择表现优于 N-gram DWD 和 Embedding DWD,但仍不及集覆盖方法。
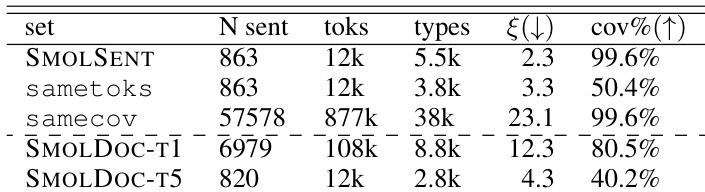
作者通过比较受 token 计数或覆盖约束的基线来评估 SMOLSENT 数据选择过程的效率。SMOLSENT 集以最少句子数量和低指标值实现了近乎完全的覆盖,而使用其他方法匹配此覆盖需要大得多的数据集。相反,将基线限制为相同的 token 计数会导致与 SMOLSENT 集相比显著较低的覆盖。SMOLSENT 集使用非常少量的句子实现了近乎完美的覆盖。匹配 SMOLSENT 集的覆盖需要基线使用数量级更大的数据集。当限制为相同的 token 计数时,SMOLSENT 集保持比基线更低的指标值。
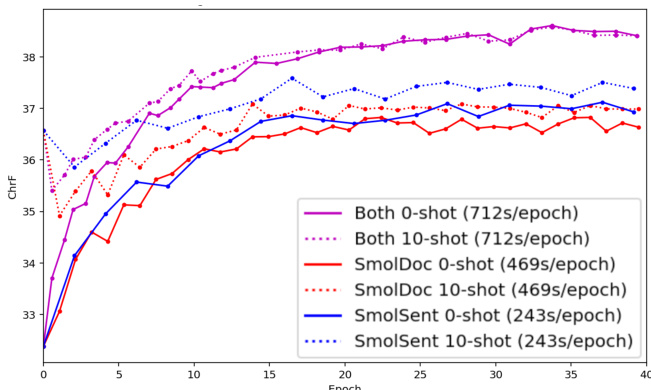
作者评估了在 SMOL 数据集上微调 Gemini 2.0 Flash 对众多语言对的影响。结果表明,微调通常能带来翻译质量的积极提升,特别是对于资源不足或未被主要翻译服务覆盖的语言。组合数据集子集并包含额外数据源进一步增强这些改进,通常优于标准基线。在 SMOL 数据上微调导致训练集中包含的语言性能一致提升,而集合外的语言显示出可忽略或负面的提升。对于未被 Google Translate 等主要翻译服务支持的低资源语言,性能提升最为显著。组合句子和文档级别数据子集以及像 GATITOS 这样的额外来源,相比单独使用子集能产生最强的整体性能提升。
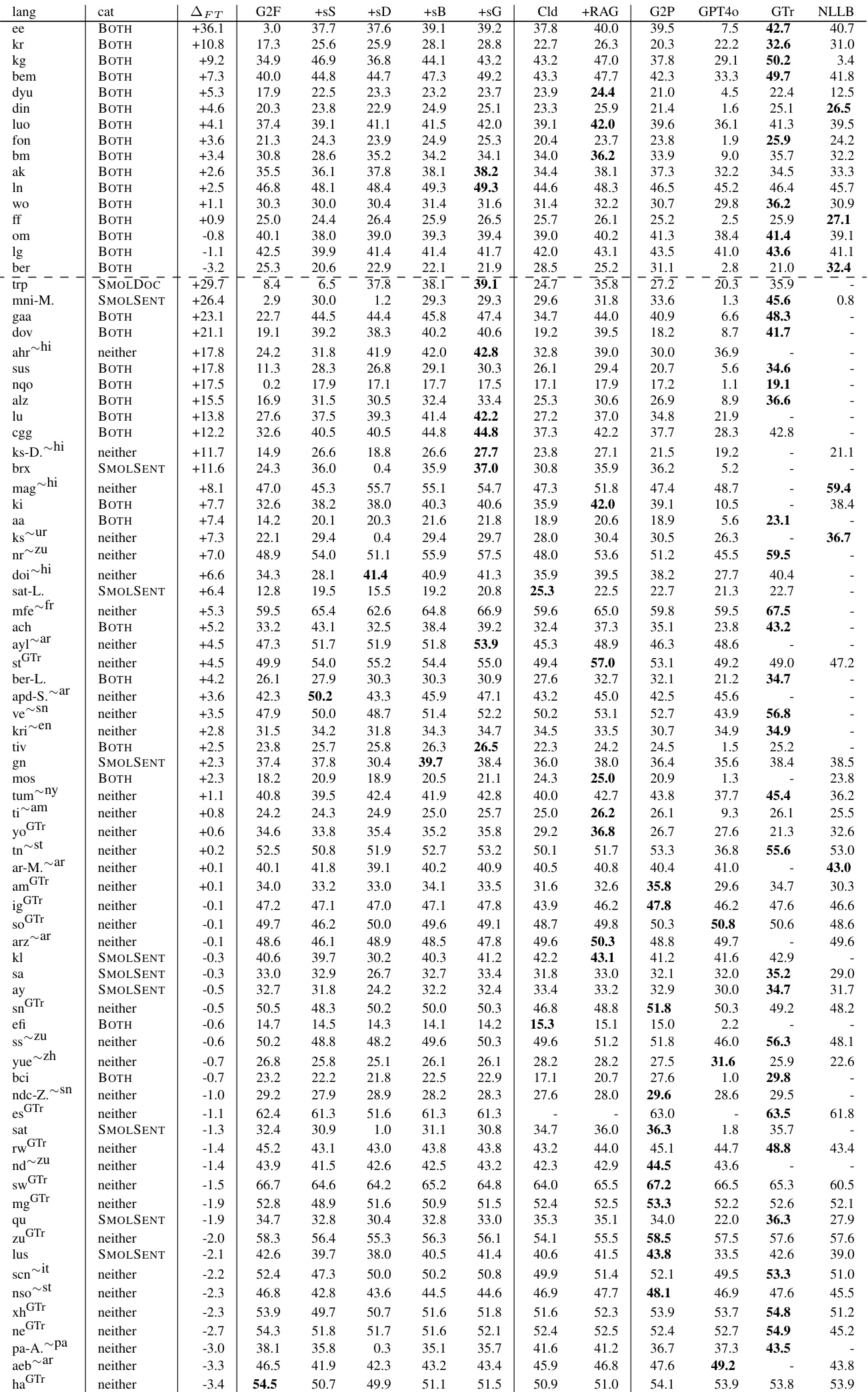
该表详细说明了 SMOLDOC 子集的构成,表明随着语言数量增加,每个语言对的数据量减少。相关实验显示,在这些数据集上微调可改善翻译质量,最佳结果通过组合多个数据源并针对未被主要翻译服务覆盖的语言实现。组合 SMOLDOC 和 SMOLSENT 数据集比单独使用任一数据集带来更高的性能提升。包含更多语言的子集中,每个语言对的数据量显著下降。微调为被排除在 Google Translate 之外的低资源语言提供了最显著的改进,而高资源语言显示最小增益。
作者展示了按语言划分的评估结果,表明在 SMOL 数据集上微调在不同语言对之间产生不同的性能变化。数据显示特定对存在负增益,表明微调并未改善这些语言相对于基础模型的性能。像 Google Translate 这样的强基线在这些场景中经常优于微调模型。微调导致所列语言对的性能出现负向变化,表明与基础模型相比质量下降。Google Translate 在大多数语言对上一致获得最高分数,经常优于微调模型。检索增强生成 (+RAG) 在特定语言对上表现出更优越的性能,在这些实例中优于微调基线。
作者评估了数据选择策略,发现 Token set-cover 优于替代方法,允许 SMOLSENT 数据集以最少句子实现近乎完全的覆盖。在此数据上微调通常能改善翻译质量,特别是对于被主要服务排除的低资源语言,组合数据集能产生最强的性能提升。然而,按语言的结果表明结果各异,某些对显示负向提升,而像 Google Translate 或检索增强生成这样的强基线仍然更优。