Command Palette
Search for a command to run...
EvalVerse:面向专业电影级视频生成的流水线感知与专家校准基准测试
EvalVerse:面向专业电影级视频生成的流水线感知与专家校准基准测试
摘要
生成式视频基础模型的快速发展正推动该领域迈向专业级电影合成。为实现如此严苛的质量要求,学界正转向强化学习(RL)与agent工作流。然而,可靠的评估已成为关键瓶颈。现有基准测试主要评估“是否正确”(基本提示词遵循),却从根本上忽视了“是否优秀”(电影质感、表演与美学)。此外,当前的自动化指标缺乏提供可信信号所需的领域特异性严谨性,导致人类审美感知与机器评分之间出现严重的可信度鸿沟。为弥合这一鸿沟,我们提出了EvalVerse,一个全面、流程感知且经专家校准的评估框架。我们将视频生成评估不仅视为一项工程任务,更视为一个核心科学问题:主观电影专业知识的系统化数字化。首先,我们将领域知识组织为与专业电影制作流程(前期制作、拍摄制作与后期制作)相一致的评估分类体系。其次,我们将人类专家的判断提炼为带有大规模人工标注的精选数据集。第三,我们通过专家校准的微调策略将这一知识注入视觉-语言模型(VLMs),使VLM能够执行显式的思维链推理。与以往工作相比,EvalVerse不仅保留了对基础“正确性”指标的兼容性,还将评估标准显著扩展至“优秀性”,并将任务覆盖范围拓宽至复杂的多镜头序列与视听融合。因此,通过提供细粒度的诊断信号,EvalVerse超越了静态排行榜,并为奖励模型和evaluator agent等未来工作奠定了基础性基础设施。
一句话总结
EvalVerse 是一款流水线感知且经专家校准的基准测试框架。它通过系统性地数字化主观专业知识(利用与工作流程对齐的分类法以及精心策划的人工标注数据集),将电影级视频评估从基础的提示词遵循能力提升至更高阶段,从而弥合了自动化指标与人类审美感知在专业电影视频生成之间的可信度差距。
核心贡献
- EvalVerse 引入了一种流水线感知的评估框架,将专业电影制作经验结构化为一套涵盖前期制作、拍摄制作和后期制作阶段的综合分类法。该框架利用 Real-to-Gen 数据引擎,通过对真实专业视频分布进行比例采样,构建高保真测试对。
- 一套系统化的人机校准机制将大规模专家标注提炼为精心策划的数据集,并将该领域知识注入视觉-语言模型中。此过程将主观的电影标准转化为可扩展的、与专家对齐的链式思维推理,用于自动化评估。
- 综合评估表明,在复杂的多镜头序列和音视频融合维度上,人机对齐程度显著。所得指标提供了可靠的诊断信号和密集奖励向量,以支持生成式视频合成中的强化学习优化与自主 Agent 工作流。
引言
生成式视频模型的快速演进正推动该领域向专业电影级合成迈进,使得细粒度评估对于使用强化学习和自主 Agent 训练下一代系统至关重要。然而,现有基准测试主要衡量基础的提示词遵循能力,无法评估细腻的电影质感,导致人类审美判断与自动化评分之间存在显著的可信度差距。为弥合这一鸿沟,作者提出了 EvalVerse,一种流水线感知的评估框架,将专业电影制作工作流程映射为结构化的诊断分类法。通过将专家判断提炼为大规模标注数据集,并利用结构化推理过程对视觉-语言模型进行微调,研究团队成功将主观的电影专业知识转化为可扩展、可解释的机器指标。该方法论支持对复杂多镜头序列和音视频生成的严格评估,同时提供推进未来生成式流水线所需的可靠奖励信号。
数据集

-
构成与来源: 作者精心策划了一个基准数据集,源自多样化的专业电影与动画合集。该数据库的结构旨在跨九个核心电影维度评估视频生成模型,重点强调技术保真度、艺术渲染和叙事连贯性。
-
子集详情与分布: 作者未将数据划分为训练集。相反,他们使用完整合集作为评估集,并在九个维度上应用比例采样策略以建立精确的混合比例。关键子集包括涵盖视觉质量、色彩度、材质感和光照的美学(Aesthetics)维度,以及评估序列逻辑与剪辑节奏的多镜头(Multi-Shot)维度。
-
数据用途与工作流: 该数据集仅作为测试基准,而非训练资源。作者构建了 Real to Gen 测试对以驱动下游生成任务并衡量模型能力。这些测试对作为结构化的真实标签参考和提示词目标,用于跨不同视频生成架构的对比评估。
-
处理与元数据构建: 流水线始于多模态感知套件,该套件提取结构化的 JSON 元数据,涵盖相机参数、角色属性与环境细节。经过工业级处理与严格的人工校验后,作者使用 Gemini 3.1 Pro 从元数据和原始字幕中合成专业的电影提示词。针对基于参考的任务,他们提取关键帧并通过 Nano Banana Pro 进行处理,以生成高保真参考图像,同时利用经过 ControlNet 微调的模型生成对应的深度序列。
方法
EvalVerse 的框架围绕一套全面且流水线感知的分类法构建,该分类法映射了传统的电影制作工作流程,将视频评估划分为三个独立阶段:前期制作、拍摄制作与后期制作。该层级结构组织了 18 个主维度和 45 个子维度,每个维度均旨在从专业电影制作视角评估视频质量的具体方面。该分类法构成了系统化评估流水线的基础,指导人类与机器的评估流程。请参阅框架示意图,以了解核心维度如何分布在这三个阶段中,以及它们与整体评估流程的关联。
评估流水线通过五个步骤实现。第一步涉及分类法的建立,定义概念框架及其组成维度。第二步专注于数据集策划,组装大规模、高质量的影视内容数据库,并辅以工业级算子与人工标注。该步骤包含全面的采样策略与测试对构建,确保评估数据的多样性与代表性。第三步涉及专家人工评估,由 14 名视频 AIGC 研究科学家与工程师,以及 20 名专业艺术家共同执行基于排名与深思熟虑的评分,其工作流设计旨在确保交叉检查与验证。第四步构成机器评估套件,包含专业算子开发与链式思维评估。第五步通过基准测试与训练模型的部署实现应用落地。
机器评估的核心是一个两阶段的 VLM 微调过程。第一阶段涉及分数校准,模型在点级数据集上进行训练,以生成详细的 CoT 推理依据与最终绝对分数。模型学习自回归地生成推理依据,随后输出分数,最优参数通过最小化交叉熵损失获得。第二阶段采用渐进式三层校准机制,使模型对齐人类专家标准。这包括提示词级校准(将抽象的评估维度替换为更具感知基础的维度)、融合级校准(使用轻量级 MLP 优化不同证据源与推理组件的权重)以及参数级校准(通过微调将电影领域知识直接注入模型参数)。
机器评估流水线分两步运行。首先,一套专用算子从输入视频、音频、文本提示词与参考素材中提取确定性的客观证据。这些算子包括用于跨帧身份追踪的 DINO、用于语义锚定的 YOLO、用于音视频同步的 SyncNet,以及用于语音情感识别的 Whisper。它们提供感知先验,以减轻幻觉现象并确保可靠的上下文关联。如下图所示,这些证据随后被输入微调后的 VLM 中,由模型执行专家引导的链式思维推理。

记为 Mθ∗ 的 VLM 处理多模态上下文,其中包括提取的证据、文本提示词、参考素材,以及针对特定电影维度设计的一组专家多问题。模型不直接输出分数,而是生成详细的 CoT,其中包含自我反思机制,用于重新检查自身推理是否存在潜在幻觉。上下文感知门控机制会在叙事上下文不支持时动态跳过某些指标。维度的最终分数通过结合 VLM 的输出与该门控指示器计算得出。该方法不仅确保评估的准确性,还保证其透明性与可解释性,为最终判断提供清晰的推理依据。
实验
该评估框架结合严格的人工专家三阶段流水线与自动化基准测试,跨前期制作资产逻辑、后期制作多镜头序列与情感叙事对视频生成模型进行评估。此项综合测试验证了模型在不同生成设置下保留视觉概念、维持电影美学以及同步音视频元素的有效性。定性分析揭示出清晰的性能层级:领先模型在摄影构图、情感递进与多模态连贯性方面表现持续优异,而其他模型则在复杂叙事与声音设计方面展现出特定优势或明显短板。对齐实验进一步证实,自动化评估系统与专业人类判断高度吻合,表明参数级校准对于准确评估抽象且时间交织的电影标准至关重要。
作者针对多种视频生成模型与评估维度,评估了自动化指标与人类专家判断之间的对齐程度。结果显示,自动化预测与人类偏好之间存在强相关性,尤其是在基于视觉与电影标准的维度上;经过任务特定校准后,抽象与时间复杂维度的吻合度进一步提升。自动化指标在多个视频生成维度上均与人类专家评估展现出强对齐性。经过任务特定校准后,抽象与时间交织维度的相关性显著提高。基于像素的维度与人类判断实现强对齐,表明提示词级推理表现可靠。
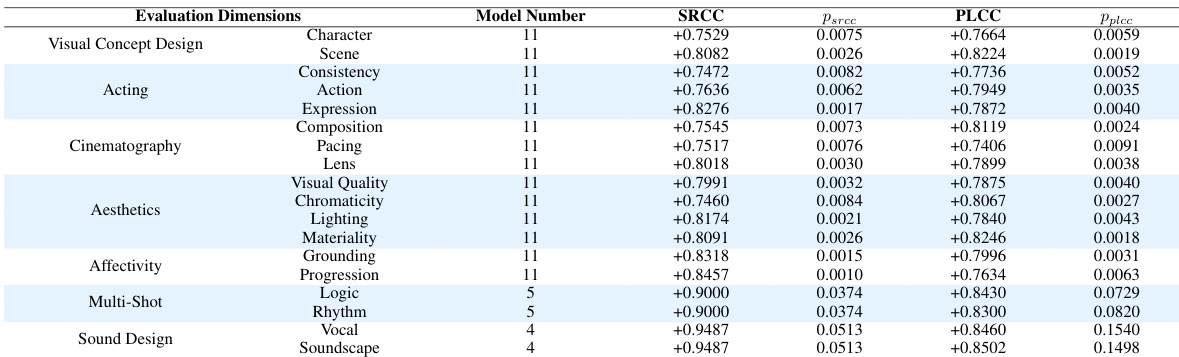
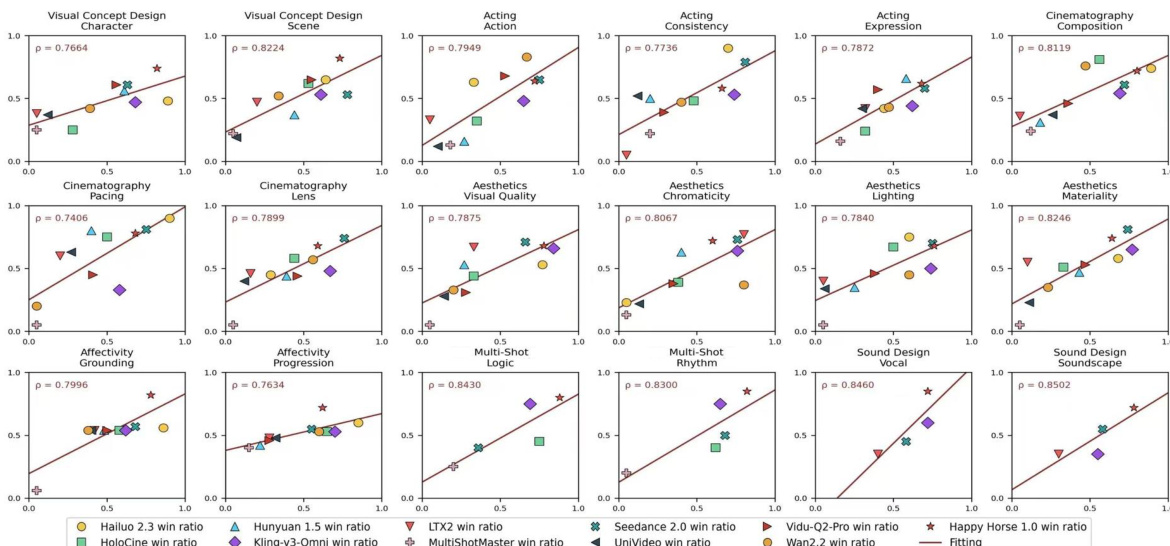
作者使用一套全面的基准测试框架评估了多种视频生成模型,该框架涵盖视频质量的多项维度,包括视觉设计、情感共鸣与后期制作连贯性。EvalVerse 框架旨在通过校准流水线与人类专家评估保持一致,在不同模态与评估标准下均与专业判断保持高度一致。EvalVerse 在多种视频生成模型与评估维度上展现出与人类专家评估的高度对齐。该基准测试框架覆盖多样化的任务模态,包括文生视频、参考图生视频、带音效视频及多镜头序列。EvalVerse 实现了高可解释性与专家引导的评估,在基于像素的维度以及抽象、时间交织的维度上均表现强劲。
作者针对多种视频生成维度,评估了自动化模型预测与人类专家判断之间的对齐程度。结果表明,自动化评估与人类评估之间存在强相关性,尤其是基于视觉内容的维度以及经过任务特定校准优化的维度。这表明评估框架有效捕捉了人类偏好,校准后基于像素与抽象、时间复杂属性的吻合度均显著提升。自动化预测在所有评估维度上均与人类专家判断高度一致。基于视觉内容的维度展现出强对齐性,表明提示词级推理表现可靠。抽象与时间复杂属性在任务特定校准后达到最高吻合度。
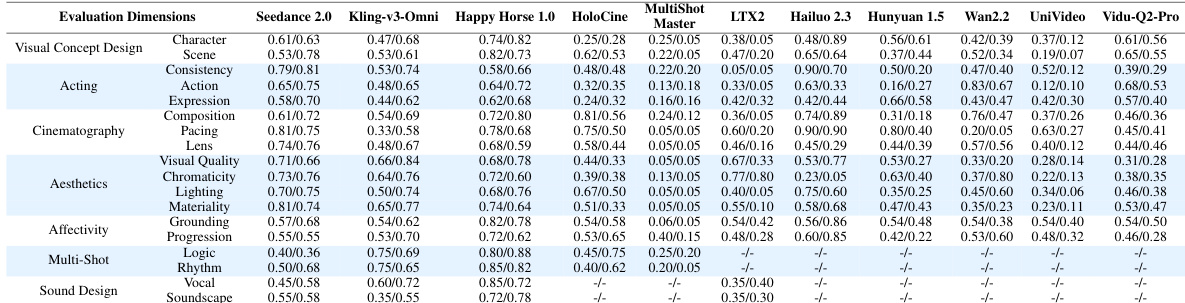
作者采用多阶段人工评估协议与自动化评估框架,跨涵盖前期制作、拍摄制作与后期制作阶段的多个维度,评估了一系列视频生成模型。结果表明,领先模型在视觉与电影质感方面表现强劲,而在情感表达与声音相关维度上则显现出差异,评估框架整体与人类专家判断保持高度一致。Seedance 2.0 在大多数评估维度上取得最高综合性能,尤其在美学、摄影构图与声音相关标准方面表现突出。各模型在不同方面展现出差异化优势,部分模型在视觉与镜头控制方面表现出色,但在情感表达与音视频同步方面存在短板。自动化评估框架与人类专家偏好高度一致,尤其针对基于视觉与电影属性的维度,并通过任务特定校准进一步优化了抽象与时间复杂方面的评估效果。

作者利用多阶段人工评估协议,针对多种电影维度(包括视觉设计、情感表达与声音设计)评估了多款视频生成模型。结果显示模型间存在清晰的性能层级,部分模型整体表现强劲,而其他模型则在特定领域展现出专业优势或明显短板。Seedance 2.0 在大多数评估维度上取得最高综合性能。Kling-v3-Omni 与 Happy Horse 1.0 在视觉与电影质感方面表现稳定且强劲,在声音相关与情感维度上则各具优势。各模型性能分布不均,部分模型在视觉一致性或摄影构图等特定领域表现优异,但在情感表达或音视频同步等方面相对滞后。
该评估采用综合基准测试框架结合多阶段人工评估协议,跨多种模态与电影维度对比前沿视频生成模型。此项实验设置验证了自动化评分系统与专业人类判断之间的对齐程度,同时确立了竞争模型间的性能层级。定性结果表明,自动化指标能够可靠地捕捉人类偏好,尤其在视觉与电影属性方面,任务特定校准进一步强化了针对抽象与时间复杂标准的共识。总体而言,模型能力呈现出明显的专业化特征,领先系统在美学与摄影构图方面表现卓越,但在情感共鸣与音视频同步方面则展现出强弱不均的特点。