Command Palette
Search for a command to run...
高效训练长上下文视觉语言模型:实现超越 128K 上下文的泛化能力
高效训练长上下文视觉语言模型:实现超越 128K 上下文的泛化能力
摘要
长上下文建模正成为现代大型视觉-语言模型(LVLMs)的核心能力,使其能够在长文档理解、视频分析以及智能体工作流中的多轮工具使用中实现持续的上下文管理。然而,实际的训练配方仍得到充分探索,特别是在设计和平衡长上下文数据混合方面。在本研究中,我们对 LVLMs 的长上下文持续预训练进行了系统研究,将 7B 模型的上下文从 32K 扩展至 128K,并对长文档数据进行了广泛的消融实验。我们首先表明,长文档视觉问答(VQA)比光学字符识别(OCR)转录有效得多。基于这一观察,我们的消融实验进一步得出三个关键发现:i) 对于序列长度分布,平衡数据优于以目标长度(例如 128K)为重点的数据,这表明长上下文能力需要在各种长度和位置上具备可泛化的关键信息检索能力;ii) 检索仍是主要瓶颈,因此倾向于使用检索密集型混合数据,并辅以适量的推理数据以增加任务多样性;iii) 纯长文档 VQA 在很大程度上保留了短上下文能力,这表明采用指令格式的长数据减少了对短数据混合的需求。基于这些发现,我们引入了 MMProLong,它是通过从 Qwen2.5-VL-7B 进行长上下文持续预训练获得的,仅使用了 5B token 的计算预算。MMProLong 将长文档 VQA 分数提高了 7.1%,并在超出其 128K 训练窗口的 256K 和 512K 上下文中保持了强大的性能,无需额外训练。此外,它在无需任务特定监督的情况下,泛化到了基于网页的多模态针检索、长上下文视觉-文本压缩以及长视频理解。总体而言,我们的研究建立了一套实用的 LongPT 配方,并为推进长上下文视觉-语言模型奠定了实证基础。
一句话总结
作者推出了 MMPROLONG,这是一款基于 Qwen2.5-VL-7B 衍生而来的 7B 视觉语言模型。该模型在 5B-token 的预算下通过长上下文持续预训练,将上下文窗口扩展至 128K。其训练策略优先采用序列长度分布均衡且侧重检索的长文档 VQA 任务,而非 OCR 转录,从而在扩展长上下文能力的同时保留了短上下文能力。
核心贡献
- 长文档视觉问答被确认为一种更优的训练任务,它能够在无需额外混合短上下文数据的情况下,提供可靠的证据检索与推理监督,同时保留短上下文能力。
- 大量消融实验表明,优先采用均衡的序列长度分布与侧重检索的数据混合策略,能够突破检索瓶颈,使上下文扩展在 5B-token 预算内从 32K 提升至 128K。
- MMProLong 训练配方通过长上下文持续预训练扩展了 Qwen2.5-VL-7B,在 MMLongBench 和 VTCBench 上取得优异表现,并能在多种多模态任务中泛化至 256K 和 512K 的上下文长度。
引言
作者利用长上下文持续预训练来解决现代视觉语言模型中的一项关键能力缺口。这些模型日益需要持续的上下文管理能力,以应对长文档分析、长视频理解以及多轮 agent 工作流等任务。尽管近期架构的上下文窗口扩展迅速,但实际的训练方法仍缺乏深入探索,导致实践者在如何构建最优数据混合比例、平衡序列长度分布或有效整合短上下文监督方面缺乏明确指导。为了解决这些挑战,作者针对长文档视觉问答与训练设计开展了系统的消融研究,最终提出了 MMProLong。该方法在仅使用 5B-token 预算的情况下,将 7B 模型的上下文能力从 32K 扩展至 128K tokens。研究证实,均衡的长度分布与侧重检索的数据混合策略优于以目标长度为核心的训练方式,且无需额外微调即可在 256K 和 512K 上下文中提供稳健的性能。
数据集
-
数据集构成与来源
- 作者构建了一个包含超过 150 万份 PDF 文档的基础池,涵盖工程、医学、社会科学和生物学领域的学术论文、书籍及技术手册。
- 为防止评估数据污染,他们通过将 PDF 内容哈希值与已知基准进行比对来过滤该数据集池。
- 使用 PyMuPDF 将每份 PDF 以 144 DPI 渲染为图像,并由基于 Seed 2.0 微调的 OCR 专家模型将页面解析为具有布局感知能力的文本块,并附带标题、章节、段落和表格等结构标签。
-
各子集关键细节
- 长文档 VQA: 来源于包含 32 至 50 页的文档,生成 32K 至 128K tokens 的多模态序列。该子集涵盖三种任务类型:单页信息提取、多页信息提取与跨页推理。
- OCR 转录: 分为全文档转录(要求输出每一页的文本)与针页转录(聚焦 1 至 3 个目标页面,将其余页面视为干扰项)。
- 短上下文数据: 使用 LLaVA-OneVision 公开提供的指令微调数据,用于补充微调与混合实验。
-
数据使用与训练混合比例
- 作者采用短到长(short-to-long)流水线合成长文档 VQA 数据,先生成基于 8 至 15 页片段的问答,随后将其放回完整文档上下文中。
- 研究对比了两种长度分布,最终选定池内原生分布,该分布在采样文档中保持自然的长度跨度,而非集中于接近最大长度的样本。
- 在最终训练中,VQA 任务被划分为信息提取与推理两类。作者优化了混合比例,采用 8:2 的提取与推理配比,该配置取得了最佳的长上下文性能。
- 短上下文数据以受控比例与长上下文数据混合,用于评估其对保留通用指令遵循能力的影响。
-
处理、元数据与裁剪策略
- 页面采样依赖 OCR 导出的结构标签,确保选取语义连贯的 8 至 15 页连续片段用于生成问题。
- 元数据构建在每个问题中明确包含片段锚点(例如指定具体章节或页码范围),以防止在完整文档上下文评估时出现歧义答案。
- 问答生成过程输出包含问题、答案、答案格式、证据页索引及证据来源的结构化 JSON,确保严格的追溯性与格式一致性。
- 渲染分辨率与 OCR 解析流水线在视觉保真度与计算效率之间取得平衡,支持长多模态序列的可扩展合成。
方法
作者利用一个三阶段流水线为 LongPT 构建长上下文训练数据集,旨在提升文档级推理任务的性能。流程始于片段采样,完整文档首先通过 OCR 专家模型提取文本,随后被划分为 8 至 15 页的连贯片段。该步骤确保输入被结构化为适合下游生成的可管理单元,同时保留文档固有的排版与内容流向。参见框架示意图。
第二阶段涉及问答(QA)生成。每个文档片段与任务指令配对以引导生成过程。随后,QA 生成模型基于片段与指令生成问答对。该阶段对于创建多样化且基于上下文理解的问题至关重要。如下图所示:
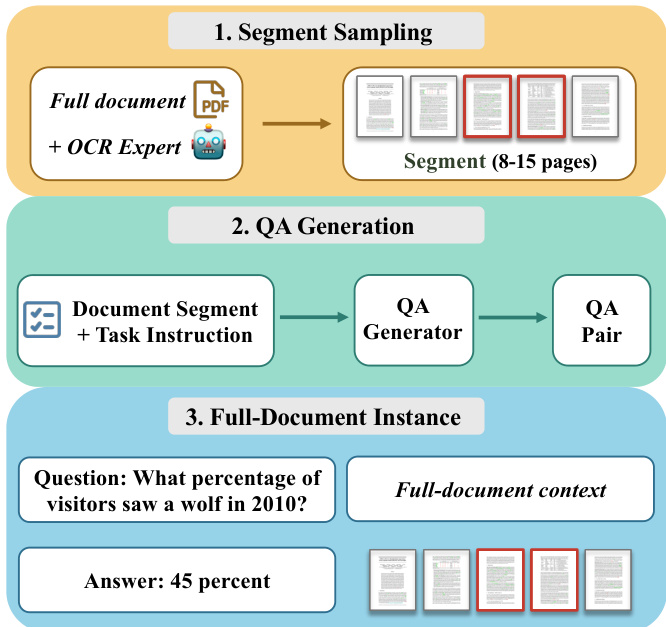
最终阶段将生成的问答对组装为完整文档实例,通过聚合全文上下文实现。该步骤确保模型在需要基于全文进行推理的问题上进行训练,而非孤立片段。每个实例包含问题、对应答案及完整文档上下文,使模型能够学习长距离依赖关系并执行跨页推理。该框架强调视觉与文本元素的融合,确保排版与内容在整个流程中得到保留。
实验
在固定计算预算下,实验对比了长文档 VQA 与 OCR 转录,并测试了多种短上下文数据混合比例,以验证扩展训练的最优监督来源与上下文保留策略。结果表明,长文档 VQA 提供了更优的指令对齐监督,在显著提升长文档性能的同时成功保留了短上下文能力。此外,优化后的训练配方能够稳健地外推至 512K 上下文,并有效迁移至多种下游任务,包括 needle-in-a-haystack 检索、视频理解以及视觉文本压缩。这些发现证明,所提方法培养了泛化的长上下文能力,在不同模型架构中均保持高度有效。
作者在长视频理解基准(包括 Video-MME、MLVU 和 LongVideoBench)上对比了 MMProLong 与 Qwen2.5-VL-7B 的性能。结果显示,MMProLong 在这三个基准上的得分均高于基础模型,表明其长视频理解能力得到提升。MMProLong 在 Video-MME、MLVU 和 LongVideoBench 上均优于 Qwen2.5-VL-7B。该模型在未进行视频特定训练的情况下,在长视频理解基准上实现了持续改进。结果表明,该训练配方提升了超越文档 VQA 的通用长上下文多模态能力。

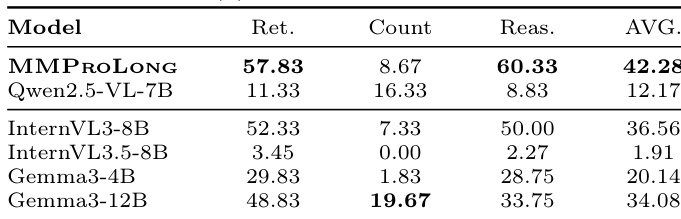
作者对比了 MMProLong 与多种开源及闭源 LVLM 在长文档 VQA 任务上的性能。结果显示,MMProLong 取得最高的总体平均分,在检索、计数和推理任务上显著优于 Qwen2.5-VL-7B 及其他模型。性能差距在推理和计数类别中尤为明显,MMProLong 在此展现出更优的能力。与其他模型相比,MMProLong 在长文档 VQA 任务上获得最高平均分。相较于 Qwen2.5-VL-7B,MMProLong 在推理与计数任务上实现显著改进。该模型在检索、计数与推理类别中均保持强劲表现,表明其能力均衡。
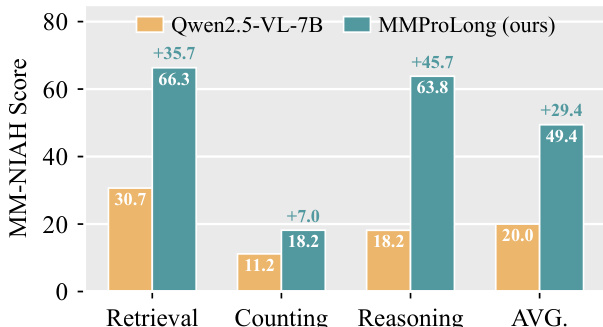
作者在 MM-NIAH 基准上对比了 MMProLong 与 Qwen2.5-VL-7B 的性能,该基准评估检索、计数与推理任务。结果显示,MMProLong 在这三项能力上均显著优于基线模型,其中检索任务的提升幅度最大。总体平均分也实现显著增长,表明训练配方提升了长上下文多模态理解的多方面性能。MMProLong 在 MM-NIAH 基准的检索、计数与推理任务上相比 Qwen2.5-VL-7B 取得实质性改进。检索任务的性能提升最为显著,分数大幅增加。总体平均分的显著提升凸显了该训练配方在不同能力维度上的有效性。
作者考察了在长上下文训练期间混合短上下文数据对模型在各基准上性能的影响。结果表明,加入短上下文数据会产生权衡效应:短上下文性能提升,但长文档 VQA 性能下降。纯长上下文训练在仅造成极小性能衰减的情况下保留了短上下文能力,同时实现了最佳的长文档 VQA 性能。混合短上下文数据虽能改善短上下文表现,但会降低长文档 VQA 表现。纯长上下文训练在保持高短上下文性能的同时仅造成微小衰减。训练过程中不混合短上下文数据时,长文档 VQA 性能达到最大化。
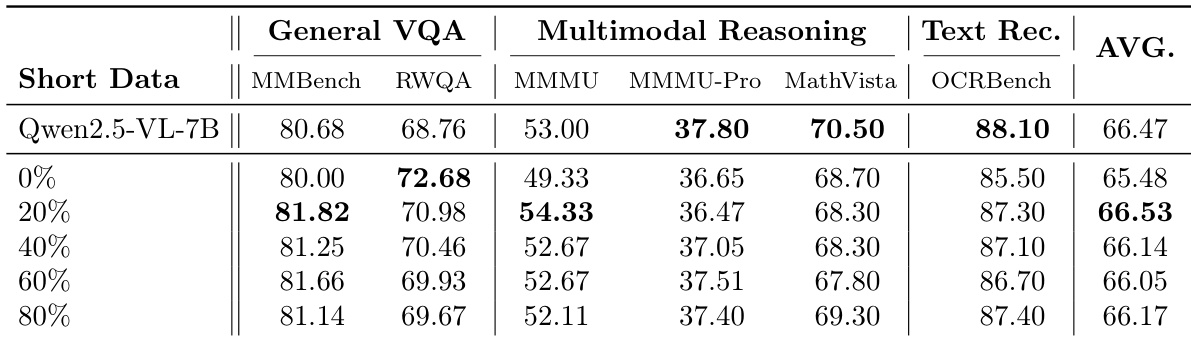
作者研究了不同数据混合比例对长文档 VQA 性能的影响,重点聚焦短上下文与长上下文能力之间的权衡。结果表明,训练期间短上下文数据比例的变化会影响短上下文与长文档 VQA 性能。纯长上下文训练在维持强劲短上下文性能的同时取得最佳的长文档结果。当短上下文与长上下文数据比例为 4:6 时,可在两项指标上实现最优平衡。纯长上下文训练实现最高的长文档 VQA 性能,仅轻微削弱短上下文能力。4:6 的短长数据混合比例提供了均衡的权衡,在长、短上下文任务中均保持强劲表现。8:2 的比例虽带来最佳的短上下文性能,但会显著降低长文档 VQA 分数,表明两者之间存在明确的权衡关系。
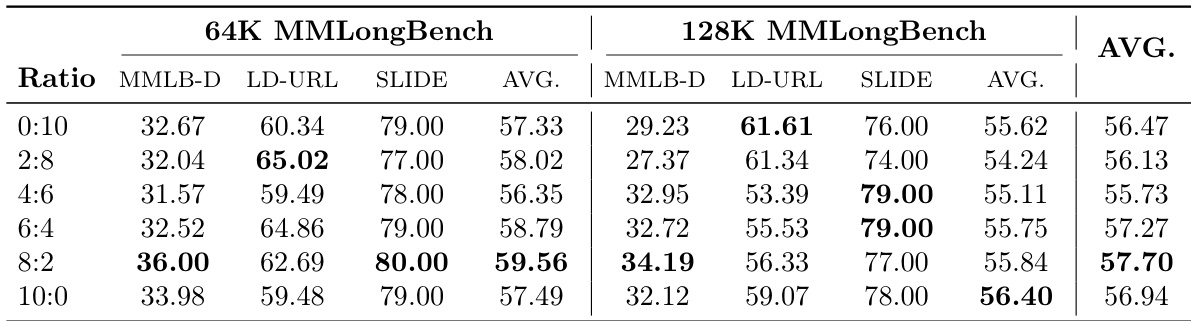
评估对比了 MMProLong 与基线视觉语言模型在长视频理解与长文档问答基准上的表现,同时考察了训练期间短上下文与长上下文数据混合的影响。结果证明,所提方法无需视频特定微调,即可在视频理解及基于文档的检索、计数与推理任务中持续超越基线模型。对训练数据组成的进一步分析表明,纯长上下文训练在最小化短上下文性能衰减的同时最大化长文档能力,而策略性数据混合则提供了一种可调的权衡机制,以实现短上下文与长上下文性能的均衡。