Command Palette
Search for a command to run...
MemEye:面向多模态 Agent 记忆的以视觉为中心的评价框架
MemEye:面向多模态 Agent 记忆的以视觉为中心的评价框架
摘要
长期智能体记忆日益呈现多模态特征,然而现有评估很少测试智能体是否保留了后续推理所需的视觉证据。在先前的研究中,许多基于视觉的问题仅利用图像描述或文本痕迹即可回答,使得答案可以在不保留细粒度视觉证据的情况下被推断出来。同时,需要针对动态变化的视觉状态进行推理的复杂案例在很大程度上仍然缺失。因此,我们提出了 MemEye,这是一个从两个维度评估记忆能力的框架:一个维度衡量决定性视觉证据的粒度(从场景级到像素级证据),另一个维度衡量检索到的证据必须如何被使用(从单一证据到演化式综合)。在此框架下,我们构建了涵盖 8 个生活场景任务的新基准,并采用消融驱动的验证门控来评估可答性、捷径抵抗能力、视觉必要性以及推理结构。通过对 4 种视觉语言模型(VLM)骨干网络上的 13 种记忆方法进行评估,我们表明当前架构在保留细粒度视觉细节以及随时间推移对状态变化进行推理方面仍存在困难。我们的研究结果表明,长期多模态记忆依赖于证据路由、时间追踪和细节提取。
一句话总结
MemEye 引入了一种以视觉为中心的评价框架,通过测量证据粒度与检索合成能力,在八个生活场景任务中对多模态 agent 记忆进行基准测试。通过对四种 VLM 骨干网络上的十三种记忆方法的评估,该框架揭示出当前架构在保留细粒度视觉细节或推理时序状态变化方面存在困难,从而凸显了构建稳健证据路由与追踪机制的必要性。
核心贡献
- 提出 MemEye,一种二维评价框架,通过测量视觉证据粒度与合成推理的复杂度来评估长期多模态 agent 记忆。
- 构建涵盖八个生活场景任务的基准测试,通过消融驱动门控与字幕替换诊断进行验证,以强制要求视觉必要性并防止文本捷径利用。
- 在四种 VLM 骨干网络上评估十三种记忆方法,证明现有架构难以随时间推移保留细粒度视觉细节,并确立有效长期记忆依赖于证据路由与时序追踪。
引言
随着对视觉-语言模型在长期 agent 记忆中依赖程度的不断加深,AI 系统得以处理需要同时保留对话历史与视觉上下文的复杂现实任务。然而,先前的评价框架大多忽视了这一视觉维度,它们依赖文本密集型基准测试,或允许模型使用字幕而非原始图像来回答问题。这一设计缺陷掩盖了保留细粒度视觉细节及跨会话追踪时序状态变化方面的关键失败。为弥补这些不足,研究提出 MemEye,一种新颖的评价框架与基准测试,沿两个正交轴测量多模态记忆:视觉证据粒度与记忆推理深度。通过构建涵盖八个生活场景任务、经过严格验证的 371 道题目数据集,该研究揭示了当前架构的根本性权衡,并证明可靠的长期视觉记忆需要精确的证据路由、时序追踪与细节提取。
数据集
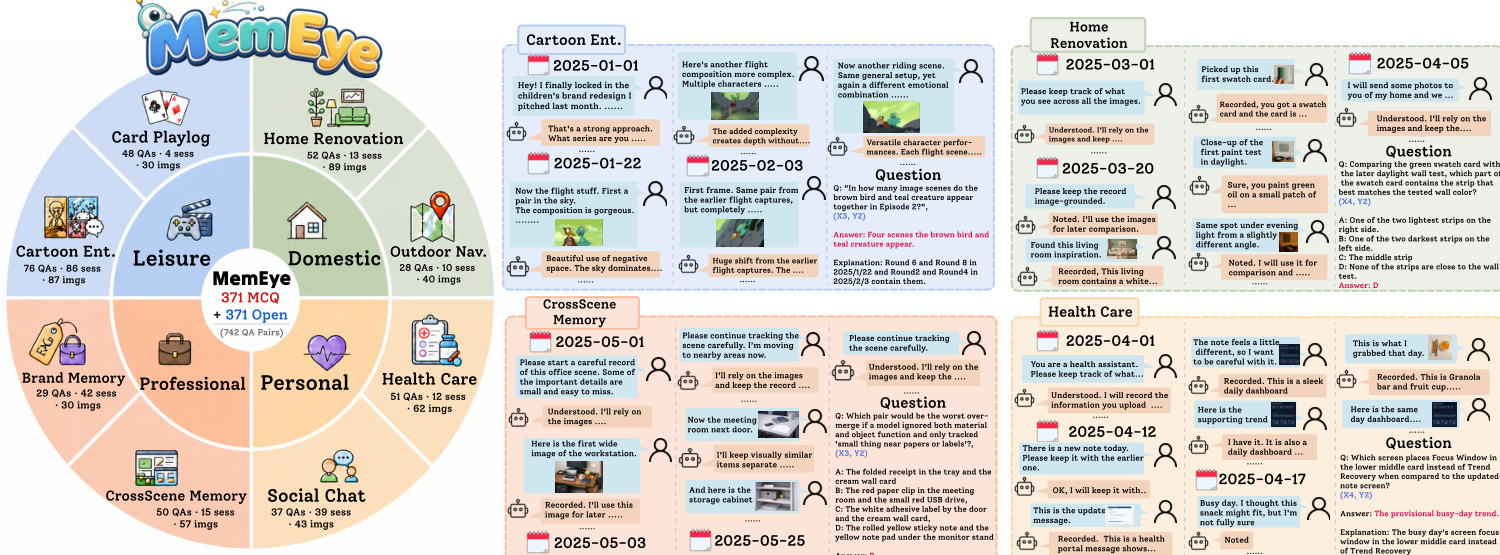
数据集概览 研究提出 MemEye,一个以视觉为中心的基准测试,旨在评估长周期多模态 agent 记忆。该数据集包含 371 道题目,分布在 221 个会话、848 轮对话和 438 张图像中。每道题目均提供镜像版选择题与开放式格式,以支持多样化的评估配置。
构成与来源 该基准测试涵盖八个任务,划分为四个生活场景领域:休闲、家庭、职业与个人。图像来源因任务而异,包括档案资料、公开内容与生成媒体。具体来源包括:用于品牌记忆的 Pitt Image Ads 数据集,用于卡通娱乐的公有领域漫画与 Seed-Story,用于家居改造的室内摄影图库,基于 Cardiverse 的 HTML 渲染截图用于卡牌日志,结合 PIL 渲染界面的 StyleGAN 人脸用于社交聊天,来自日本开放驾驶数据集的行车记录仪画面用于户外导航,以及通过 DALL-E 生成的 AI 图像用于跨场景记忆与健康管理。该集合涵盖照片、截图、漫画面板与界面渲染等多种图像类型。
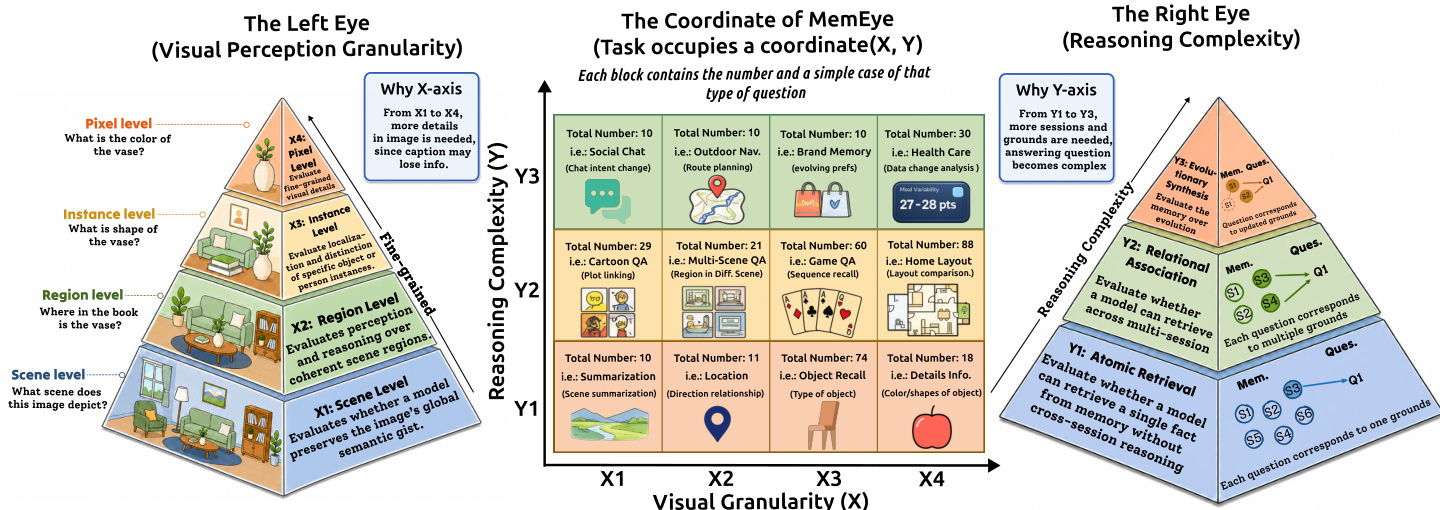
分类体系与元数据 每道题目均通过最高瓶颈规则分配 (X, Y) 坐标,以捕捉所需最细粒度视觉证据与最深记忆操作。X 轴测量视觉证据粒度,包含四个层级:X1 用于场景级主旨,X2 用于区域级空间细节,X3 用于实例级识别,X4 用于像素级属性(如精确颜色、文本或纹理)。Y 轴评估记忆推理深度,包含三个层级:Y1 用于单一事实的原子检索,Y2 用于非冲突分布式线索的关系关联,Y3 用于涉及更新、冲突或状态覆盖的演化合成。数据集包含分类体系分布的元数据,并标记每项任务的视觉证据属于档案资料还是生成内容。
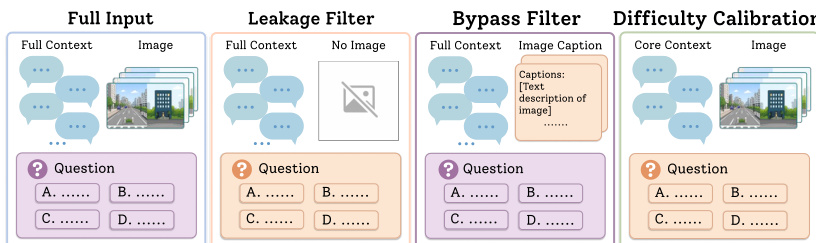
处理与过滤 为确保基准测试检验视觉记忆而非文本可解性或基础模型识别能力,研究应用三种严格的过滤机制。首先,通过仅使用对话文本测试题目并移除无需视觉证据即可解答的项目,消除答案泄露。其次,通过用极简字幕替换图像来测试视觉可绕过性,并丢弃仅凭文本描述仍可解答的题目。第三,通过提供包含答案相关上下文的图像来控制固有难度,将可解性与记忆约束隔离,移除因基础模型局限而失败的项目。此外,通过为每道题目创建四个旋转变体(正确答案在所有选项中循环)来缓解多选题偏差。
使用与评估 该数据集专为评估设计,包含用于多模态多选题作答、文本加字幕作答、题目生成与分类标注的提示词模板。评估采用大语言模型即裁判框架,并配备详细评分标准,根据语义等价性、否定词处理、身份匹配与幻觉规避,对回答进行 0 至 1 的评分。研究提供用于题目生成与标注的 JSON 输出格式,以标准化元数据构建并确保视觉与推理要求标签的一致性。
方法
研究利用二维评价框架构建 MemEye,沿由视觉感知粒度与推理深度定义的坐标系组织任务。X 轴称为视觉粒度,涵盖从粗到细的四个层级:场景级(X1)、区域级(X2)、实例级(X3)与像素级(X4)。这些层级对应处理视觉证据的尺度,范围从全局场景语义到颜色与纹理等细粒度像素细节。Y 轴代表推理复杂度,捕捉检索与合成证据所需的认知处理深度。其分为三个层级:Y1(原子检索),仅需单一证据单元;Y2(关系关联),需组合多个非冗余证据单元;Y3(演化合成),需跨线索的时序排序与状态更新以得出结论。
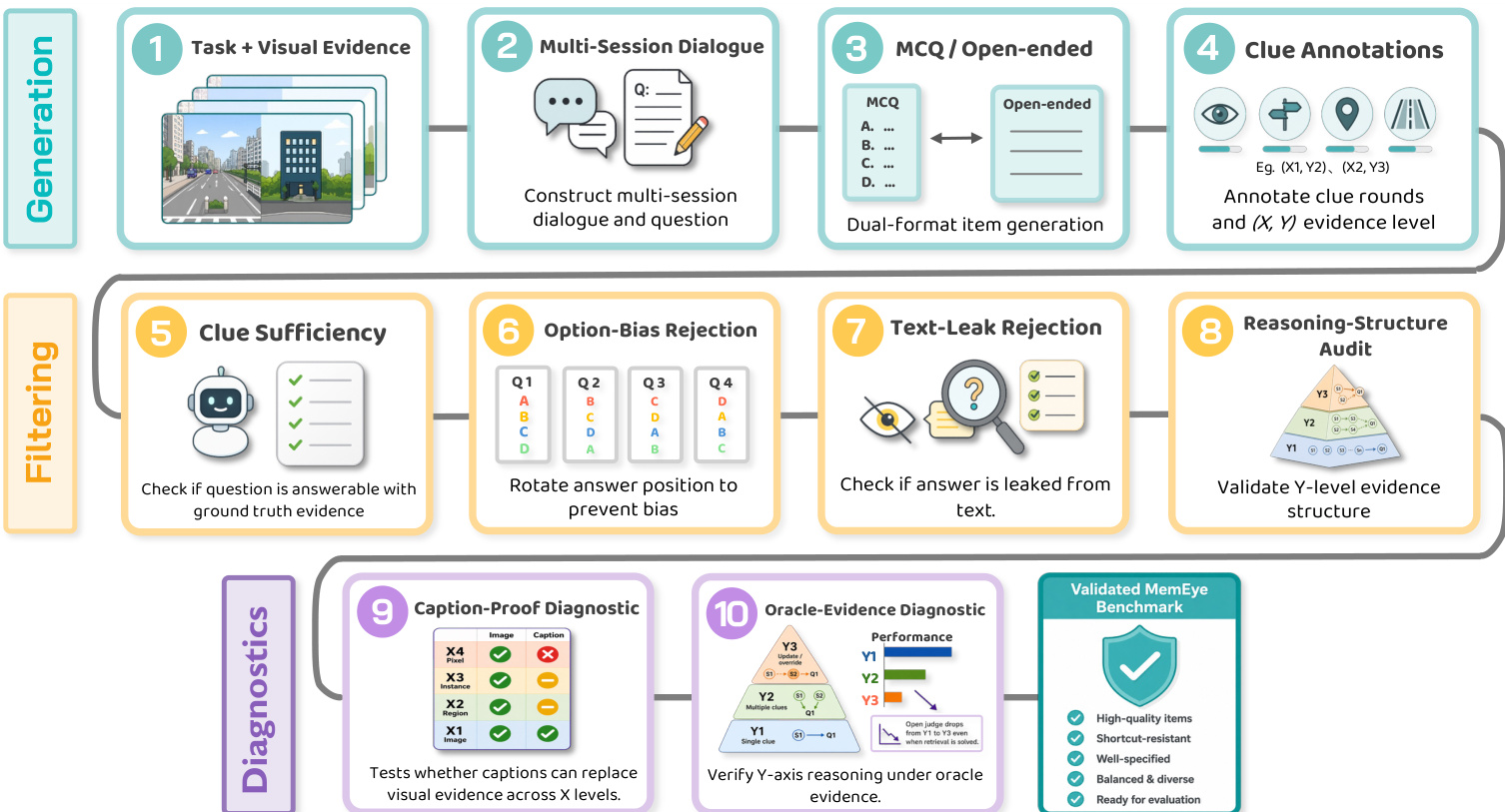
该框架通过多阶段流水线实现,始于任务与视觉证据生成,随后构建多会话对话并生成选择题或开放式题目。每道题目均标注对应的 (X,Y) 粒度与复杂度层级。流程随后进入严格过滤阶段,首先进行线索充分性检查,确保题目可使用真实证据解答。接着进行选项偏差剔除,通过旋转答案位置防止回答偏差。文本泄露过滤器检查答案是否仅凭文本即可推断,绕过过滤器评估短字幕能否在不妨碍题目有效性的前提下替换完整图像。难度校准阶段确保题目在整个分类体系中维持适当的挑战水平。
推理结构审计验证题目是否符合预期的 Y 层级证据结构,确保 Y1 项目仅需原子检索,Y2 项目涉及跨多线索的关系关联,Y3 项目需要跨时间的演化合成。流水线以诊断评估收尾:字幕验证测试字幕能否在 X 层级替代视觉证据,真实证据诊断通过在 oracle 条件下测试性能,验证 Y 轴推理是否依赖多模态证据。最终输出为经过验证的 MemEye 基准测试,其特点是高质量、抗捷径、定义明确且多样化的题目,可直接用于评估。
实验
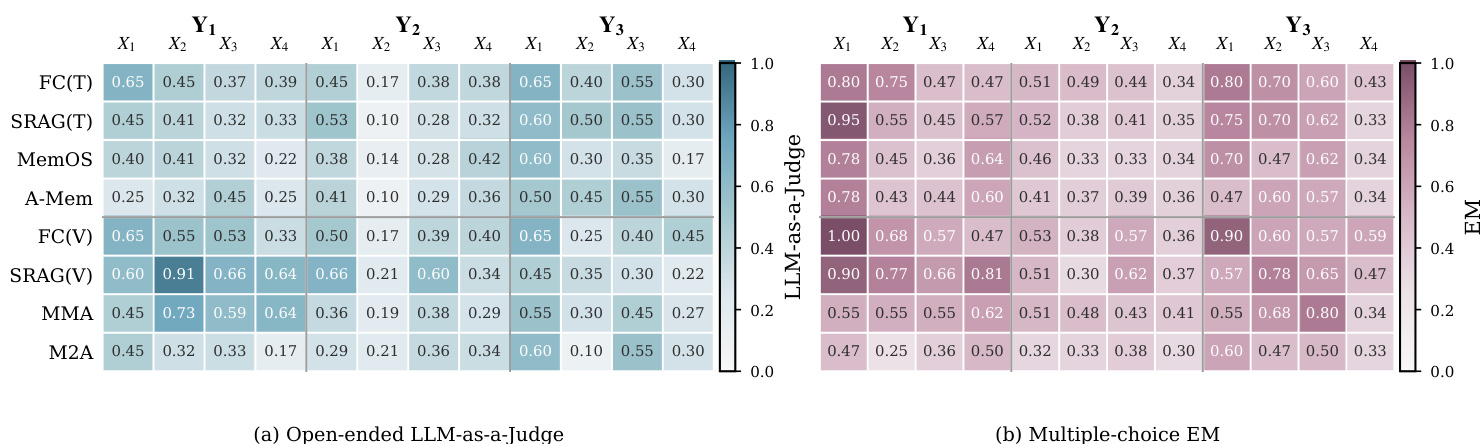
研究使用 MemEye 基准测试,沿视觉粒度轴与推理深度轴组织任务,并通过字幕验证与真实证据诊断进行验证,评估了四种视觉-语言模型上的十三种记忆架构。结果表明,当前系统面临两大主要瓶颈:图像转文本导致细粒度视觉细节大量丢失,而基于检索的方法在追踪演化视觉状态时经常选择过时的时序证据。因此,有效的长期多模态记忆需要混合方法,在保留结构化文本状态记录的同时维持原生视觉证据,并辅以过滤机制,优先选择时序有效的信息而非仅依赖语义相似度。
{"summary": "研究分析了各类记忆系统在评估推理深度与视觉粒度的基准测试上的表现。结果表明,系统在两个维度上的表现存在差异,多模态方法在细粒度视觉任务中普遍优于基于文本的方法,而基于文本的方法在推理演化状态方面展现出优势。分析凸显了在动态记忆环境中保留视觉证据与选择有效状态之间的权衡。", "highlights": ["多模态方法在细粒度视觉任务中优于基于文本的方法,但在演化状态选择方面存在困难。", "基于文本的方法在推理演化状态方面更具竞争力,因为追踪更新与冲突的能力至关重要。", "该基准测试揭示了视觉证据保留与状态选择之间的权衡,表明没有任何单一方法在两个维度上均表现卓越。"]}
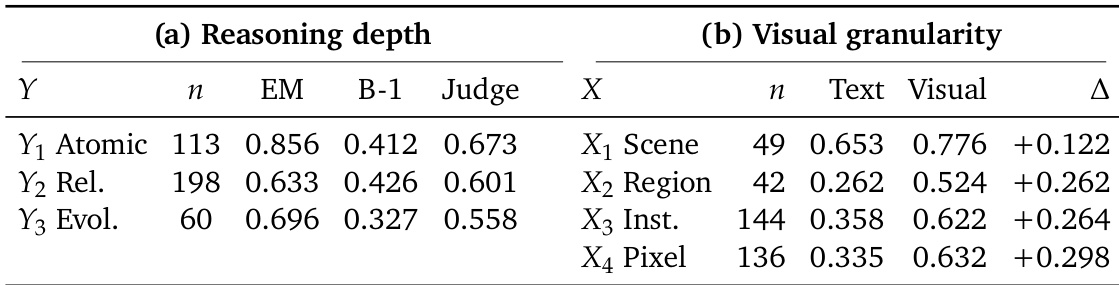
研究分析了记忆系统在不同视觉证据粒度与推理深度层级下的性能,指出当前系统在细粒度视觉信息与演化视觉状态方面存在困难。多模态方法在保留视觉细节方面普遍优于基于文本的方法,但基于检索的系统在证据随时间变化时,往往无法选择最新的有效状态。多模态记忆系统在保留细粒度视觉证据方面优于基于文本的系统,尤其在较高视觉粒度层级下表现明显。基于检索的方法即使检索到相关证据,也常无法选择最新的视觉状态。基于文本的记忆系统通过维护结构化状态记录能更好地处理演化视觉状态,但会丢失细粒度视觉细节。
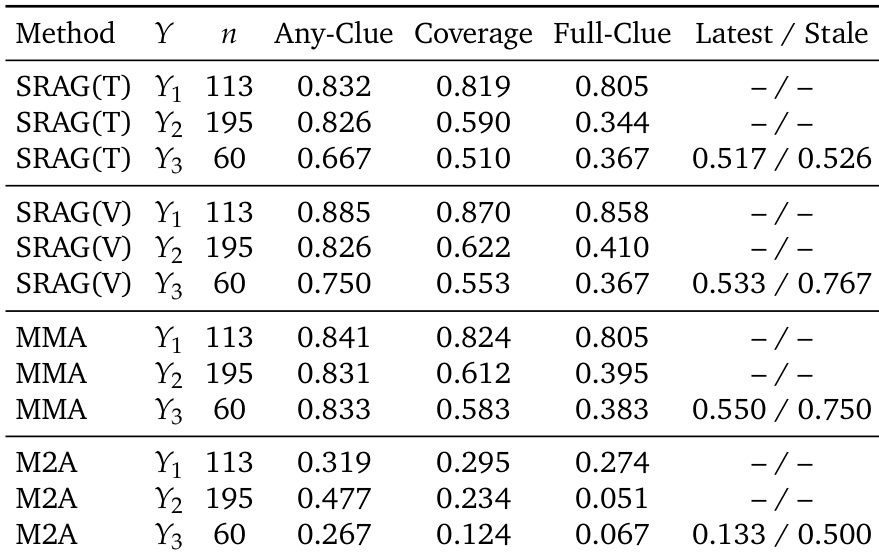
研究分析了各类记忆系统在评估视觉证据粒度与推理深度的基准测试上的性能。结果表明,多模态方法普遍优于基于文本的方法,尤其在需要细粒度视觉细节的任务中。然而,所有系统在需要跨时间追踪演化视觉状态的任务中性能均出现下降,表明从动态记忆历史中选择有效证据存在瓶颈。多模态记忆方法在需要细粒度视觉证据的任务中优于基于文本的方法。所有系统在需要跨时间追踪演化视觉状态的任务中性能均下降。没有任何方法能同时完全解决视觉证据保留与演化状态选择问题。
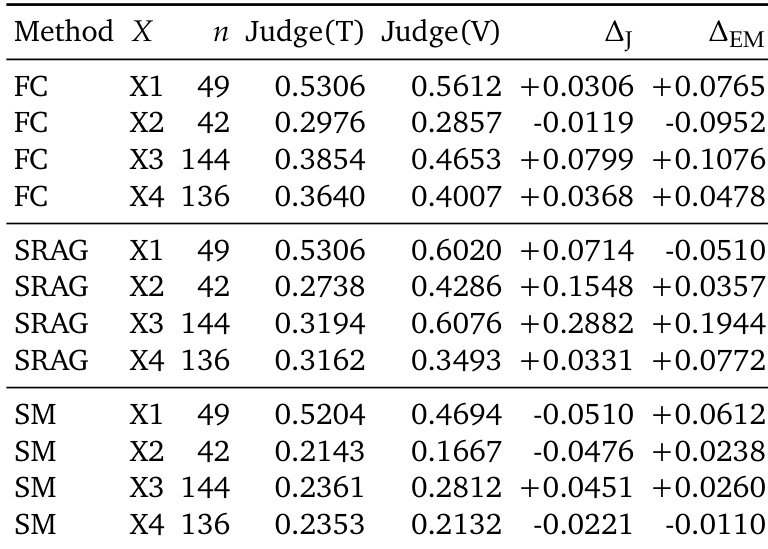
实验在测量视觉证据粒度与记忆推理深度的双轴框架下评估多种记忆系统。结果表明,当前系统难以同时处理细粒度视觉细节与演化视觉状态,性能在基于文本与多模态方法之间因任务复杂度不同而产生显著差异。分析揭示了与视觉信息丢失及状态选择相关的不同故障模式,表明有效记忆系统必须结合视觉与文本证据,并配备随时间筛选有效证据的机制。当前记忆系统无法同时处理细粒度视觉证据与演化视觉状态,在评估矩阵的不同区域表现出明显的故障模式。多模态方法在细粒度视觉任务上优于基于文本的方法,而基于文本的方法在演化状态推理上表现更好,表明视觉保真度与状态追踪之间存在权衡。结果表明,未来的记忆系统需要结合图像与文本记忆,并配备从漫长且多样化的历史中过滤与选择有效证据的机制。
研究在评估视觉证据粒度与记忆推理深度的二维基准测试上评估了多种记忆系统。结果表明,没有任何单一方法在所有条件下表现优异,多模态方法在细粒度视觉任务中表现出色,而基于文本的方法在演化状态推理中表现更佳。分析指出,当前系统既难以保留详细视觉信息,也无法从漫长历史中选择最相关的更新证据。多模态方法在细粒度视觉任务中优于基于文本的方法,但在演化状态推理方面存在困难。基于文本的方法在推理演化视觉状态时更为有效,但会丢失细粒度视觉细节。当前记忆系统无法同时处理视觉证据保留与时序状态选择,表明需要结合型记忆架构。
实验使用二维基准测试评估了多种记忆系统,该测试验证了系统在动态记忆的视觉证据粒度与推理深度上的性能。分析揭示了明显的定性权衡:多模态架构在保留细粒度视觉细节方面表现出色,而基于文本的方法在追踪演化状态方面更为有效。最终,没有任何单一方法能成功平衡这两项需求,表明未来系统必须整合视觉与文本记忆,并配备专门机制以跨时序历史过滤有效证据。