Command Palette
Search for a command to run...
SkillsVote:从收集、推荐到演进的 Agent 技能生命周期治理
SkillsVote:从收集、推荐到演进的 Agent 技能生命周期治理
Hongyi Liu Haoyan Yang Tao Jiang Bo Tang Feiyu Xiong Zhiyu Li
摘要
长周期大语言模型(LLM)智能体留下的痕迹可能转化为可复用的经验,但原始轨迹噪声较大且难以管理。我们将“智能体技能”(Agent Skills)视为一种经验模式,该模式将可执行脚本与不可执行的程序性指导相结合。然而,开放的技能生态系统中存在冗余、分布不均且对环境敏感的元素,不加区分的更新可能会污染未来的上下文。我们提出了 SkillsVote,这是一个针对智能体技能生命周期的治理框架,涵盖从收集、推荐到演化的全过程。SkillsVote 对百万级规模的开源语料库进行画像分析,评估其环境需求、质量和可验证性,并合成用于可验证技能的任务。在执行前,SkillsVote 在结构化的技能库中进行智能体库搜索,以揭示指令性技能上下文。在执行后,它将轨迹分解为与技能关联的子任务,将结果归因于技能使用、智能体探索、环境因素及结果信号,并仅允许成功的可复用发现通过证据门控更新。在我们的评估中,离线演化使 GPT-5.2 在 Terminal-Bench 2.0 上的表现最高提升了 7.9 个百分点,而在线演化使 SWE-Bench Pro 的表现最高提升了 2.6 个百分点。总体而言,当系统能够控制暴露、归因和保留机制时,受治理的外部技能库可以在不更新模型的情况下提升冻结智能体的性能。
一句话总结
SKILLSVOTE 管理 agent 技能的生命周期,通过将可执行脚本与流程化指导相结合,在分解执行轨迹并归因结果后应用基于证据的更新机制,并通过百万级语料库画像与执行前的库搜索过滤可复用经验。最终,在不进行模型参数更新的情况下,SKILLSVOTE 使 GPT-5.2 驱动的冻结 LLM agent 在 Terminal-Bench 2.0 上的性能提升最高达 7.9 个百分点,在 SWE-Bench Pro 上提升 2.6 个百分点。
核心贡献
- SKILLSVOTE 是一个生命周期治理框架,通过将可执行脚本与流程化指导相结合来构建可复用的 Agent Skills 体系。该系统对百万级开源语料库进行画像分析以评估环境需求与质量,随后采用任务条件化的 agent 库搜索机制,在执行前仅暴露相关技能及使用说明。
- 执行后的轨迹被分解为与技能关联的子任务,以便将结果归因于特定技能应用、agent 探索或环境因素。基于证据的更新策略会过滤噪声轨迹,仅将成功且可复用的发现纳入持久化技能库。
- 在 Terminal-Bench 2.0 和 SWE-Bench Pro 上的评估表明,离线进化使 GPT-5.2 性能提升最高达 7.9 个百分点,而在线进化使 SWE-Bench Pro 分数提升最高达 2.6 个百分点。这些结果证实,受控的外部技能库能够在无需模型参数更新的情况下增强冻结 agent 的性能。
引言
大语言模型 agent 的最新进展已将研究重心转向需要与代码库和 Web 应用等复杂环境交互的长周期任务。此类场景会生成丰富的轨迹,在此过程中复用过往经验对提升效率至关重要。然而,原始执行轨迹通常噪声过多且高度依赖上下文,难以作为可靠的知识库。尽管前期研究引入了 agent 技能来结构化这些经验,但扩展此类库仍面临重大挑战。现有生态系统存在冗余、质量不一致及安全风险等问题。此外,现有的检索方法通常依赖静态元数据,容易遗漏关键细节;而进化机制经常错误归因结果,导致虚假或环境依赖型失败污染技能仓库。
本文提出 SKILLSVOTE,这是一种生命周期框架,将 agent 技能视为受控且可版本化的工件,通过推荐、归因与进化的闭环进行管理。该系统对百万级开源技能语料库进行画像,并在执行前采用 agent 搜索动态推荐一组精简的相关技能,而非依赖浅层的元数据匹配。任务完成后,SKILLSVOTE 通过将轨迹分解为与技能关联的子任务来进行细粒度的结果归因,以判断成功或失败源于技能本身、agent 的探索还是外部因素。该归因层作为库更新的门控机制,确保仅纳入经验证且可复用的发现,同时过滤噪声。实验表明,这种受控进化能够在无需模型参数更新的情况下,提升 agent 在 Terminal-Bench 2.0 和 SWE-Bench Pro 等基准测试上的性能。
数据集

-
数据集构成与来源 研究团队构建了 SKILLSVOTE 数据集,这是一个从 GitHub 通过 SkillsMP 和 skills.sh 等生态系统聚合的百万级开源 agent 技能语料库。每个技能被视为一个目录级包,包含定义能力与使用条件的必需文件 SKILL.md,以及用于可执行脚本、参考文献和资源的可选目录。
-
子集详情与过滤规则 原始语料库从三个维度进行画像分析:运行时需求、质量指标与可验证性。通过可验证性画像的技能被合成符合 Harbor 任务格式的基准任务,包含清晰指令、可复现环境及可执行验证器。被识别为偏好驱动、开放世界或硬件密集型任务的技能则保留为画像语料库条目,不强制转换为基准任务。
-
数据使用与处理 研究团队使用源自 Harbor 数据集镜像的预构建实验镜像,在合成任务上运行 agent 与模型组合。该预构建过程固定了 agent CLI 版本(具体为 nv0.40.4、Node.js 22 与 Codex CLI 0.125.0),以消除运行时安装延迟并确保版本一致性。系统记录执行轨迹、成功率、成本及验证器结果,从而将静态技能描述与观测到的 agent 行为相连接。
-
元数据构建与工件 数据集包含结构化的归因与进化工件。轨迹被分割为具有独立目标、事实摘要与可复用探索的子任务。每个子任务均标注有判断信号类型(如环境或人工)以及归因标签,用于对结果进行分类(例如 success_skill_used_with_extra_exploration 或 fail_skill_issue)。元数据通过关联的技能名称及由文件路径和行号定义的精确知识范围来追踪技能影响。进化工件记录了包含理由与操作摘要的编辑与创建请求,确保修改基于探索结果,并遵循局部替换等约束条件。
方法
SKILLSVOTE 框架作为 Agent Skills 的生命周期治理系统,整合了收集、推荐、执行与进化阶段以管理开放技能生态。整体架构围绕三阶段流水线构建:任务前推荐、任务中执行以及任务后归因与进化。系统核心维护一个结构化技能库,作为推荐与进化的基础。执行前,推荐阶段从精选集合中选取与任务相关的技能,确保 solver agent 在受限且有意义的环境中运行。执行后,系统将 agent 轨迹分解为语义连贯的子任务,将结果归因于技能使用、探索与环境因素,随后基于经验证的可复用发现对技能库应用受控更新。这种生命周期方法确保外部技能库能够在无需模型更新的情况下安全进化,前提是暴露范围、责任归属与保存机制得到妥善管理。
任务前推荐阶段首先根据环境需求、质量与可验证性过滤大规模开源技能语料库。该画像技能库支持在执行前进行针对性搜索。如框架图所示,agent 接收一组技能与使用指导,这些内容源自结构化技能库。推荐流程包括解析任务指令、拆解为核心能力,并使用 grep 与 glob 等文件系统工具搜索候选技能。系统优先选择在其 SKILL.md 文件中包含直接能力证据的技能,避免仅依赖目录名或描述。识别相关技能后,系统生成精简的使用指导,说明所选技能如何覆盖特定任务阶段、如何组合以及存在哪些覆盖缺口,且不执行任务或复制技能内容。该指导将追加至任务指令末尾,确保 solver agent 仅接收必要上下文。推荐阶段在 solver agent 启动前运行,因为它控制哪些技能被安装至 agent 的可见目录,并据此修改任务指令。
推荐完成后,solver agent 在受控环境中执行任务。agent 的轨迹(包含所有操作、观测与反馈)被记录为步骤序列。试验结束后,归因阶段处理该完整轨迹,将其提炼为结构化子任务。该阶段并非简单将会话压缩为文本,而是恢复原始 agent 会话以保留上下文细节,这对维持思维链完整性至关重要。系统基于结果证据变化、责任分配或可复用增量来识别子任务。每个子任务是语义完整的单元,具备独立目标、主要评估信号以及最多一个关联技能上下文。归因过程评估子任务结果是否可通过客观环境反馈判定、是否依赖人工偏好,或缺乏明确信号。责任被分配至技能引导执行、独立探索或观测到无关技能后的探索。对于与技能相关的子任务,系统定位实际影响执行过程的技能知识部分,仅提取可复用发现(如缺失流程或恢复模式),同时剔除试错过程与任务特定常量。
生成的可进化单元随后由受控进化阶段处理。该阶段首先应用准入过滤器,仅允许具有可复用探索的成功子任务进入下一环节。失败或不确定的子任务保留用于诊断,但不直接授权更新。符合条件的单元基于共享的可复用流程、前置条件或修正措施聚合为组,确保重复观测强化单一变更,而非产生碎片化编辑。每个聚合组随后被路由至更新操作。若证据表明扩展了影响执行的技能,系统通过最小必要变更编辑该技能(修复错误指导、补充缺失知识或收紧前置条件)。若证据反映当前技能边界外的新独立能力,系统则创建新技能。当证据薄弱或语义不匹配时,系统跳过进化。这种保守设计确保每项库更新均得到归因执行证据的支持,限定于相关技能边界内,并以可复用流程知识的形式表达。进化过程由结构化模式引导,定义错误修复、知识补充、前置条件添加、技能创建或跳过等操作,并对读写操作施加严格约束以隔离进化范围。


该框架确保进化过程基于证据且保持保守。系统使用统一的本地 agent 主目录管理凭证与会话,而每个进化请求拥有独立工作目录以隔离读写范围。任何编辑操作前,系统会备份技能的当前版本。针对编辑请求的进化提示词同时提供旧技能的 editable 副本与新技能创建目录,使 agent 能够在必要时进行局部编辑或创建新技能。针对创建请求,系统确保新技能遵循标准技能文件夹布局,保持连贯、独立且可复用。编辑或创建新技能的决策取决于探索内容是否属于同一工具、工作流家族或问题类型,抑或引入了不同的工具、工作流或领域。遇到不确定情况时,系统优先选择创建新技能,避免将语义无关的知识强行合并至现有技能中。该方法确保技能库以受控且有意义的方式进化,维护 agent 知识库的完整性。
实验
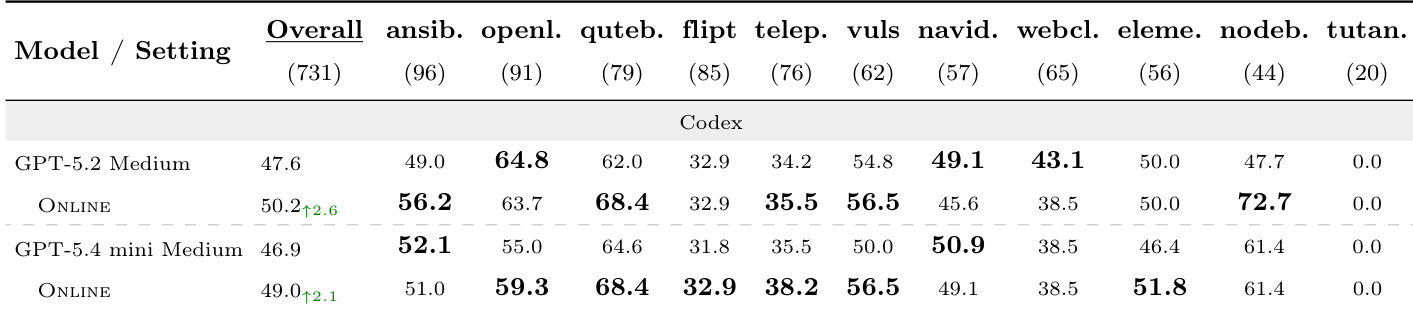
评估在 Terminal-Bench 2.0 与 SWE-Bench Pro 上验证 SKILLSVOTE,采用基于 GPT 的骨干网络检验三个核心生命周期阶段:离线进化、在线进化与任务条件化推荐。离线进化成功将历史轨迹提炼为冻结库,将可复用流程知识迁移至未见任务;在线进化则展示系统在连续工作流中持续积累经验的能力。任务条件化推荐作为关键过滤器,仅暴露相关技能以防止负迁移,从而补充进化流程。最终实验证实,将流程化技能积累与智能暴露机制相结合,能显著提升 agent 在多样化软件工程与终端环境中的性能。
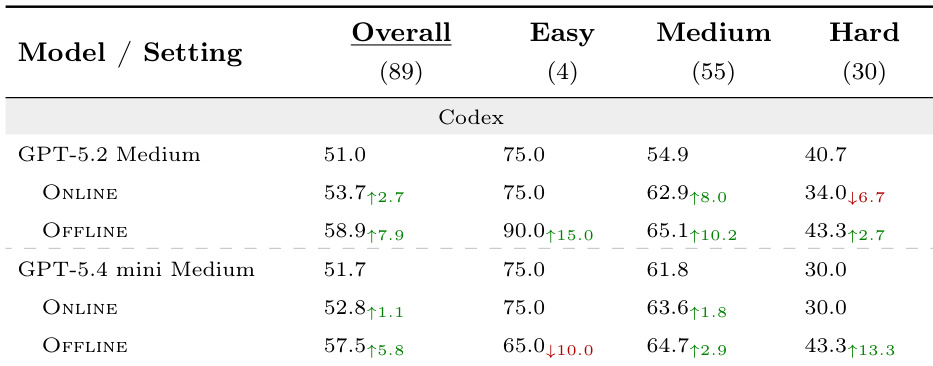
研究团队在 Terminal-Bench 2.0 上评估 SKILLSVOTE,将离线与在线进化设置与无技能基线进行对比。结果表明,离线进化在所有难度级别上均带来显著提升,而在线进化提供较小但正向的收益,尤其在中等与困难任务上表现明显。任务条件化推荐通过减轻无关技能带来的负迁移来提升性能。与基线相比,离线进化在所有难度级别上持续改善性能。在线进化提供较小但正向的收益,其中中等与困难任务的提升幅度最大。任务条件化推荐降低了负迁移,并增强了技能暴露的整体有效性。
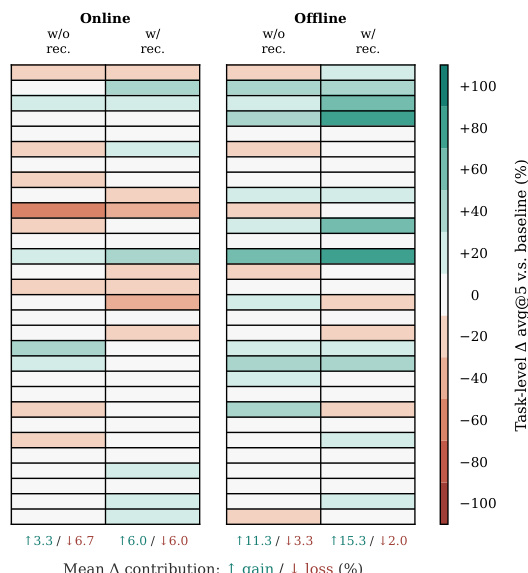
研究团队在两项基准测试上评估 SKILLSVOTE,表明离线与在线进化均能提升不同任务类型的性能。结果表明,技能推荐通过过滤有害或无关技能增强了库的实用性,带来更稳定的收益。离线进化将历史轨迹中的技能迁移至未见任务,提升两项基准的性能。在线进化产生较小但正向的收益,推荐机制有助于缓解匹配不佳技能带来的负迁移。任务条件化推荐改善了技能暴露的平衡性,减少有害影响并提升整体性能。
研究团队分析了推荐机制在在线与离线设置中对技能库性能的影响,表明推荐通过过滤有害技能暴露来减轻负迁移。结果表明,离线进化生成的技能库比在线进化更有效,且推荐机制通过改善正负任务级贡献的平衡,提升了两类库的实用性。推荐机制在在线与离线设置中均通过过滤有害技能暴露降低负迁移。离线进化生成的技能库优于在线进化,离线设置下的更强收益印证了这一点。推荐机制改善了正负任务级贡献的平衡,从而提升整体库的实用性。
研究团队在多项基准测试上评估 SKILLSVOTE,将离线与在线进化策略与无技能基线进行对比。结果表明,离线进化通过将历史技能有效迁移至未见任务,在所有难度级别上持续产生更强的性能收益;而在线进化提供更温和但可靠的改进,尤其在复杂任务上。任务条件化推荐的集成进一步验证了其过滤无关或有害技能的能力,有效缓解负迁移并平衡两种设置下的任务级贡献。总体而言,实验表明进化技能暴露与定向推荐相结合,能显著提升模型性能与库的实用性。