Command Palette
Search for a command to run...
将价值模型重新引入:大语言模型强化学习中的生成式批判家用于价值建模
将价值模型重新引入:大语言模型强化学习中的生成式批判家用于价值建模
Zikang Shan Han Zhong Liwei Wang Li Zhao
摘要
信用分配(Credit assignment)是强化学习(RL)中的一个核心挑战。经典的演员-评论家(Actor-Critic)方法通过基于学习的价值函数进行细粒度的优势估计(Advantage estimation)来解决这一挑战。然而,在现代大型语言模型(LLM)的强化学习中,通常避免使用学习的价值模型,因为传统的判别式评论家(Discriminative critics)难以可靠地训练。我们重新审视了价值建模,并认为这种困难部分源于表达能力(Expressiveness)的局限。具体而言,表示复杂性理论(Representation complexity theory)表明,在现有价值模型采用的单次预测(One-shot prediction)范式下,价值函数难以近似;我们的规模扩展实验也表明,此类评论家并未随规模扩大而实现可靠的性能提升。受此启发,我们提出了生成式演员-评论家(Generative Actor-Critic, GenAC),用生成式评论家替代单次标量价值预测,该评论家在生成价值估计之前会进行思维链(Chain-of-thought)推理。此外,我们引入了上下文 conditioning(In-Context Conditioning),帮助评论家在训练过程中持续保持对当前 Actor 的校准。GenAC 提升了价值近似、排名可靠性以及分布外泛化(Out-of-distribution generalization)能力,这些优势转化为比基于价值(Value-based)和去价值(Value-free)基线方法更强的下游强化学习任务性能。
一句话总结
为了解决大语言模型强化学习中传统判别式 critic 不可靠的问题,作者提出了生成式 Actor-Critic (GenAC),该方法用执行思维链推理的生成式 critic 取代了一次性标量值预测,并引入上下文条件化 (In-Context Conditioning) 以帮助 critic 保持与当前 actor 的校准,从而改善价值近似、排序可靠性和分布外泛化,使其在下游强化学习性能上优于基于价值和无价值的基线。
核心贡献
- 论文介绍了生成式 Actor-Critic (GenAC),该方法用执行思维链推理的生成式 critic 取代了一次性标量值预测,然后再产生价值估计。这种设计解决了通过表示复杂度理论和扩展实验确定的传统判别式 critic 表达能力有限的问题。
- 该框架引入了上下文条件化 (In-Context Conditioning),以帮助 critic 在整个训练过程中保持与当前 actor 的校准。该机制确保价值模型始终意识到所评估策略的能力,从而进行动态和准确的价值估计。
- 实验表明,GenAC 在价值近似、排序可靠性和分布外泛化方面优于基于价值和无价值的基线。这些改进转化为数学推理任务上更强的下游强化学习性能。
引言
强化学习推动大语言模型的后训练,但当监督仅限于最终结果时,有效的信用分配仍然困难。先前的工作通常避免使用判别式价值模型,因为训练不稳定和表达能力有限,导致从业者采用无价值方法,为整个序列分配均匀信用。作者提出了生成式 Actor-Critic,该方法用执行思维链推理的生成式 critic 取代了一次性标量预测,然后再产生价值估计。通过引入上下文条件化以保持与活跃策略的校准,该方法在价值近似和下游性能方面优于现有基线。
方法
作者提出了一种生成式 Actor-Critic (GenAC) 架构,旨在克服标准判别式 critic 的表示复杂度限制。与传统的用线性投影替换语言建模头以直接输出标量值的方法不同,生成式 critic 保留了原始的自回归结构。这允许模型在产生最终价值估计之前执行显式的思维链推理。为了使该输出对语言模型可行,critic 的任务是生成一个 0 到 10 之间的整数分数,代表成功的可能性,随后将其解析并归一化为 0 到 1 之间的价值预测。
参考框架图以可视化该方法与无价值方法以及带有判别式 critic 的标准 PPO 的对比。虽然无价值方法直接从奖励中推导优势,PPO 使用前向传递进行价值预测,但 GenAC 利用中间推理步骤来告知优势估计。
该架构的一个关键组件是上下文条件化 (ICC)。由于价值函数本质上是以策略为条件的,critic 必须意识到活跃 actor 的特定能力。判别式 critic 在其权重中编码此信息,但生成式 critic 利用上下文学习。作者设计了一个特定的提示模板,明确指示 critic 从部分响应中推断 actor 的能力,并提供模型大小和成功率平滑运行平均值等元数据。
如下图所示:

这种条件化奠定了 critic 推理的基础,确保其充当特定策略的函数近似器,而不是通用近似器。actor 和 critic 之间的交互是动态的。随着 actor 生成步骤,critic 实时评估进展和潜在错误。
参考交互图以查看 critic 如何在不同阶段提供反馈。例如,在正确的前缀之后,critic 可能会根据代数进展分配中等评级。相反,在错误步骤之后,critic 识别概念错误并分配较低的成功概率,有效地引导 actor 远离无效解决方案。
生成式 critic 的训练管道遵循三阶段过程以确保鲁棒性。首先,使用由 oracle 模型合成的高质量推理轨迹执行监督微调 (SFT),以灌输基础推理模式。其次,RL 预训练冻结 actor 并通过 REINFORCE 训练 critic,使用定义为 Rv(s,z)=1−(r−v^)2 的基于规则的奖励函数,其中 r 是观察到的奖励,v^ 是解析的价值预测。这将推理建立在经验回报之上。最后,在 RL 联合训练阶段,critic 被集成到 PPO 循环中。actor 使用从 critic 预测计算的优势进行更新,而 critic 不断调整其推理以跟踪演进 actor 的变动价值函数。
实验
实验在数学推理基准上评估生成式 Actor-Critic (GenAC) 与标准判别式 critic 和无价值基线。受控近似测试显示,判别式 critic 面临模型扩展无法克服的基本表达能力障碍,而生成式 critic 提供更准确和稳定的价值估计。因此,GenAC 在强化学习期间实现了卓越的样本效率和持续的性能提升,验证了显式生成推理改善了信用分配和对分布外数据的泛化。
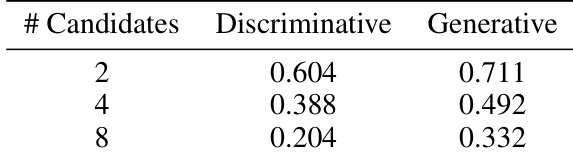
该表比较了判别式和生成式 critic 在从不同大小的池中选择最佳候选者时的 top-1 排名准确率。生成式 critic 在所有测试的池大小上始终优于判别式基线。虽然两种方法的准确率随着候选者数量的增加而降低,但判别式 critic 更快地退化到随机概率水平。生成式 critic 在每个候选者池大小上都实现了优于判别式 critic 的排名准确率。随着待评估候选者数量的增加,两种模型的性能均显示下降。随着决策空间的扩大,生成式方法保持了对基线更强的优势。
作者评估了生成式与判别式 critic 在具有不同程度分布偏移的数据集上的近似性能。结果显示,生成式 critic 始终实现更低的错误率,随着分布偏移从无增加到中等,性能差距扩大。生成式 critic 在所有测试数据集上的近似准确率始终优于判别式基线。随着分布偏移变得更加严重,生成式方法的相对改进变得更加显著。该方法展示了鲁棒的泛化能力,即使在具有高分布偏移的分布外数据集上也能保持显著的误差减少。

该表比较了提出的 GenAC 算法与三个基线在六个数学推理基准上的性能。GenAC 实现了最高的总体平均分数,并在大多数单独评估类别中优于所有其他方法。虽然基线在特定数据集上显示出竞争性结果,但 GenAC 在整个过程中展示了卓越的一致性和最终性能。GenAC 实现了最高的平均性能,并在大多数特定基准上领先。所提出的方法展示了清晰的性能层次结构,优于判别式和无价值基线。虽然基线在 MATH500 等特定数据集上显示出优势,但 GenAC 在整个评估套件中保持了卓越的稳定性。

作者分析了 GenAC 与 PPO 和 VinePPO 相比的计算成本,显示 GenAC 导致资源使用适度增加,而 VinePPO 的成本显著更高。这表明 GenAC 在计算开销和生成式价值建模的性能优势之间提供了有利的权衡。GenAC 需要大约标准 PPO 两倍的计算资源。VinePPO 是最昂贵的方法,成本是 PPO 基线的四倍以上。分析表明,为了实现细粒度反馈,GenAC 比 VinePPO 提供了更有效的平衡。

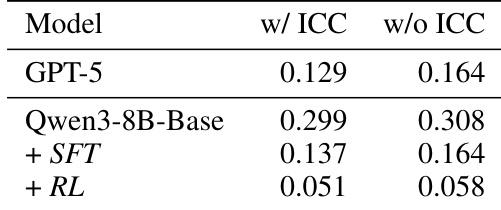
该表展示了关于价值函数近似性能的消融研究,比较了在不同训练阶段有和没有上下文条件化 (ICC) 的模型。结果表明,ICC 在所有配置中始终降低近似误差,而涉及 SFT 和 RL 的完整训练管道比基础模型或零样本提示产生显著更好的准确率。与没有 ICC 的配置相比,上下文条件化在所有模型变体中始终减少近似误差。RL 训练模型实现了最低误差,显著优于基础模型和零样本 GPT-5。零样本 GPT-5 的表现与 SFT 阶段相当,但未能匹配完全训练的 RL 模型的准确率。
实验评估了生成式 critic 与判别式基线在排名准确率、分布偏移下的近似性能以及数学推理基准上的表现。生成式方法始终优于判别式方法,随着候选者池扩大或分布偏移变得更加严重,保持卓越的准确率。所提出的 GenAC 算法展示了跨任务的鲁棒泛化和一致性,同时保持了有利的计算平衡,消融研究证实上下文条件化结合完整强化学习训练显著提高了价值函数近似准确率。