Command Palette
Search for a command to run...
MMSkills:迈向通用视觉 Agent 的多模态技能
MMSkills:迈向通用视觉 Agent 的多模态技能
摘要
可复用技能已成为提升智能体(agent)能力的核心基础,然而大多数现有的技能包主要将可复用行为编码为文本提示、可执行代码或学习到的例程。然而,对于视觉智能体而言,程序性知识本质上是多模态的:其复用不仅取决于执行何种操作,还涉及识别相关状态、解释进展或失败的视觉证据,以及决定下一步行动。我们将这一需求形式化为多模态程序性知识,并解决三个实际挑战:(I)多模态技能包应包含哪些内容;(II)此类技能包可从公共交互经验中的何处获取;以及(III)智能体如何在推理时查阅多模态证据,同时避免过多的图像上下文或对参考截图的过度锚定。我们引入了 MMSkills,这是一个用于表示、生成和使用可复用多模态程序以支持运行时视觉决策的框架。每个 MMSkill 都是一个紧凑的、以状态为条件的包,它将文本程序与运行时状态卡片和多视角关键帧相结合。为了构建这些技能包,我们开发了一种基于智能体的轨迹到技能生成器(agentic trajectory-to-skill Generator),通过工作流分组、程序归纳、视觉定位和元技能引导的审计,将公共非评估轨迹转化为可复用的多模态技能。为了使用这些技能包,我们引入了一种分支加载的多模态技能智能体:在临时分支中检查选定的状态卡片和关键帧,将其与实时环境对齐,并提炼为结构化指导以辅助主智能体。在 GUI 和基于游戏的视觉智能体基准测试中的实验表明,MMSkills 持续提升了前沿模型和较小规模的多模态智能体的性能,这表明外部多模态程序性知识能够补充模型内部先验。
一句话总结
MMSkills 通过将文本流程与运行时状态卡片及多视角关键帧相结合,为视觉 agent 提供可复用的多模态程序性知识。该框架利用基于 agent 的轨迹到技能 Generator 进行包构建,并采用分支加载的多模态技能 agent 进行实时环境对齐,从而在 GUI 和基于游戏的视觉 agent 基准测试中持续提升前沿模型与小型 multimodal agent 的性能。
核心贡献
- 提出 MMSkills 框架,通过将可复用行为编码为结合文本流程、运行时状态卡片与多视角关键帧的紧凑包,实现多模态程序性知识的规范化。
- 基于 agent 的轨迹到技能 Generator 通过工作流分组、流程归纳、视觉定位及元技能引导的审计,自动从公开交互日志中构建这些包。
- 分支加载推理机制在临时分支中检查选定证据以提炼结构化指导,在缓解长上下文性能衰退的同时,持续改善 GUI 和基于游戏基准中前沿与小型 multimodal agent 的表现。
引言
针对桌面自动化与交互式游戏等复杂视觉环境中运行 multimodal AI agent 对可复用程序性知识日益增长的需求,相关工作致力于提升其能力。尽管先前的技能表示能有效将行为编码为文本或代码,但当 agent 必须解读实时屏幕证据时,难以捕捉所需的视觉状态线索与条件决策。现有方法要么生成冗长的纯文本指令,要么依赖僵化的原始演示,要么通过直接注入完整技能库使上下文窗口过载,这通常导致 agent 锚定于参考截图而非当前观测。为弥补这一差距,MMSkills 框架将可复用知识构建为结合文本流程、运行时状态卡片与多视角关键帧的紧凑多模态包。进一步地,自动化流水线从公开交互轨迹中提炼这些包,并提出分支加载机制,作为一种运行时机制,选择性地将技能证据与实时观测对齐,从而在不造成上下文饱和的情况下提供精确的状态感知指导。
数据集
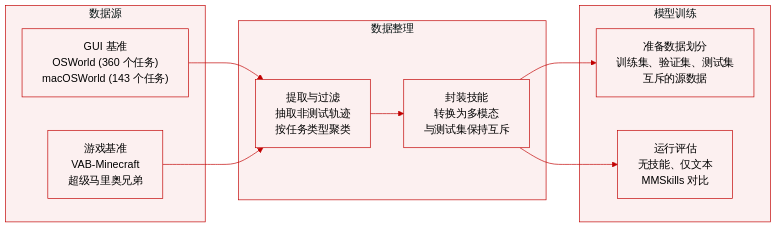
- 数据集构成与来源: 研究采用涵盖真实图形用户界面与开放游戏环境的四项视觉 agent 基准测试。技能数据来源于 OpenCUA 轨迹数据集、官方训练划分集以及多次游戏运行记录,所有源材料均与评估集严格隔离。
- 子集详情: OSWorld 包含 360 个 Ubuntu 桌面测试用例,涵盖浏览器、办公软件、媒体应用及系统工作流。macOSWorld 提供 143 个跨平台 GUI 用例,聚焦文件管理、生产力工具与界面任务。VAB-Minecraft 评估需要视觉定位、库存跟踪与工具操作的项目获取任务。Super Mario Bros 选自 LMGaME-Bench,因其重复出现的视觉场景天然支持可复用技能提取。
- 数据使用与划分: 所有多模态技能均严格从非测试轨迹中提取。在三种条件下评估前沿与小型模型:无技能、纯文本技能以及 MMSkills。源轨迹与最终测试用例完全独立,以确保评估无偏并防止数据泄露。
- 处理与元数据构建: Agent 直接根据捕获为桌面或游戏截图的视觉观测进行规划。针对 macOS 技能提取,原始 OpenCUA 轨迹经过额外的聚类与相关性过滤,以对齐基准类别。生成的技能包被结构化为多模态格式,以指导 agent 决策。
方法
MMSkills 框架基于模块化架构构建,通过技能表示、生成与推理机制的组合,使视觉 agent 能够利用可复用的多模态程序性知识。其核心由三个主要组件构成:多模态技能包、技能生成流水线以及分支加载的多模态技能 agent。整体系统首先从公开交互轨迹中构建可复用技能库,随后在任务执行期间利用分支加载推理机制查询这些技能,而无需将完整的技能上下文直接嵌入主 agent 的推理过程。
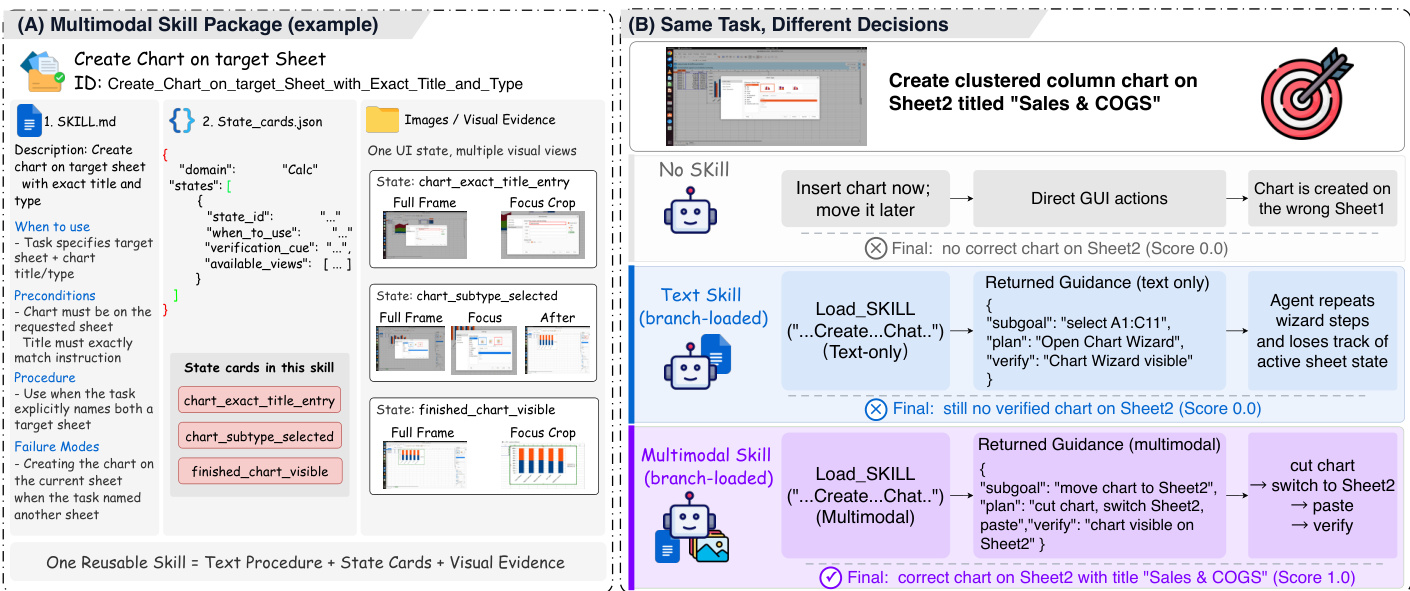
多模态技能包将程序性知识封装为状态条件化流程,表示为 M=(D,P,S,K),其中 D 为紧凑描述符,P 为文本流程,S 为运行时状态卡片集合,K 为关键帧包集合。每张状态卡片 Sj 定义流程的应用或跳过时机,并包含可见线索、验证线索与可用视图,使 agent 能够做出关于技能使用的合理决策。关键帧包 Kj 提供多视角视觉证据(例如全帧、聚焦裁剪、操作前与操作后视图),将技能与环境绑定。该表示法支持技能的文本与视觉双重使用,视觉组件作为诊断参考而非直接动作模板。技能包设计为紧凑且可复用,纯文本变体为不包含任何视觉证据的退化情况。
技能生成流水线将公开的非测试轨迹转化为领域特定的技能库。该流程首先对任务指令与轨迹元数据进行嵌入与聚类,形成语义聚焦的簇。针对每个簇,基于大语言模型 (LLM) 的 agent 提出原子技能,定义工作流边界、完成条件与任务覆盖范围。随后将这些提议合并并泛化为统一的技能规范,同时拒绝过于宽泛的技能。下一阶段负责起草技能的文本组件(描述符、流程与状态卡片),且不引用图像。最后,通过选择关键帧、构建多视角包以及审计包内容来确保一致性与相关性,完成技能的视觉定位。该流水线受元技能控制,提供可复用脚本与质量检查点,确保生成的技能连贯且实用。
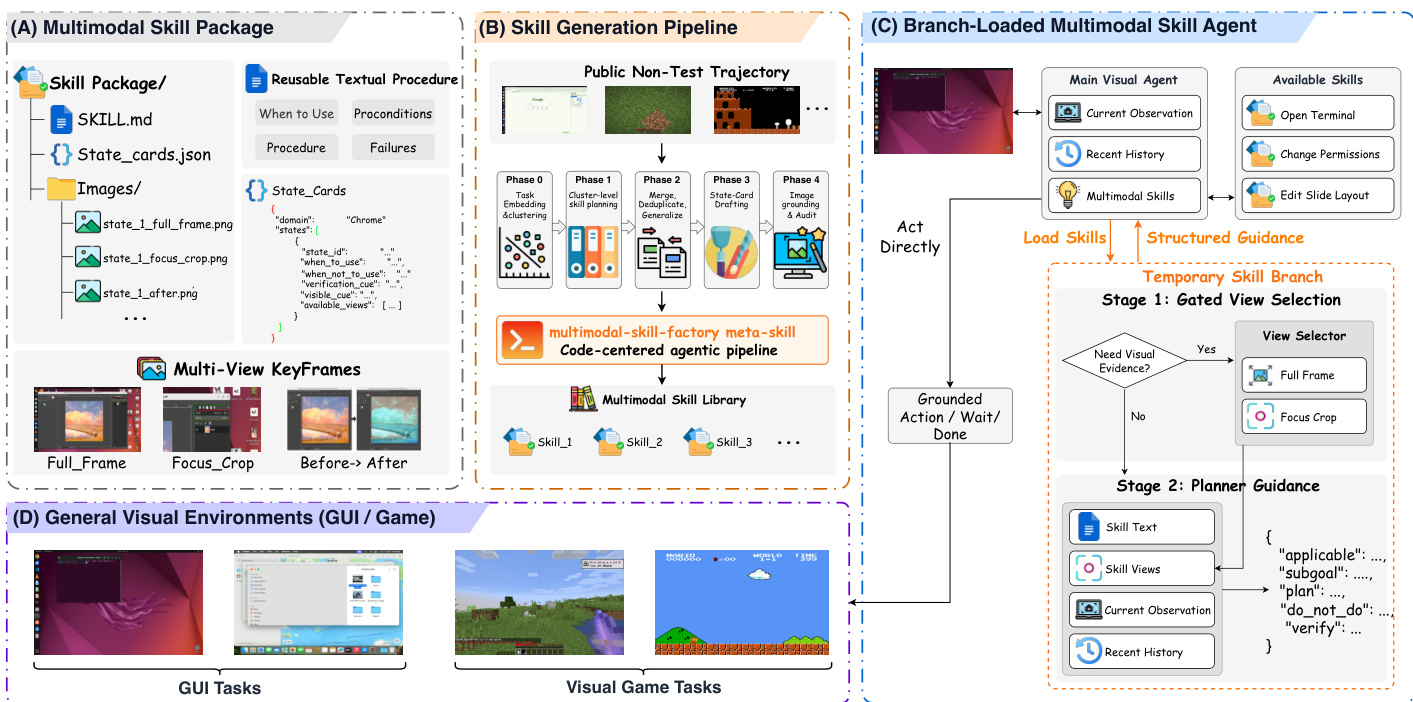
推理期间,主视觉 agent 采用分支加载方式运行,以避免直接加载完整技能包所导致的上下文过载。agent 维护短期历史记录并观测当前视觉状态,在每一步决定直接执行动作或查询选定技能。当查询技能时,激活临时分支,将技能与环境绑定过程与主轨迹隔离。该分支分两个阶段运行。第一阶段,门控视图选择器评估当前观测与近期历史,判断是否需要视觉证据,并在需要时确定加载哪些状态卡片与视图类型。该决策基于证据目标,例如定位控件、识别变更前状态或验证变更后结果。第二阶段为规划器指导模块,利用选定证据生成结构化指导元组 Gt=(applicablet,subgoalt,plant,do_not_dot,verifyt),包含适用性判断、局部子目标、技能条件化计划、负向约束与验证检查。该指导返回至主 agent,作为决策支持使用,同时保持动作基于实时观测。

主 agent 查询技能的决策由策略控制,该策略评估技能提示的相关性与任务当前状态。agent 查询技能的次数受到严格限制,已耗尽的技能将从可用列表中移除。分支加载设计确保 agent 接收紧凑的结构化指导,而不受无关视觉参考的干扰,从而保持实时环境观测的完整性。该架构通过针对特定领域调整技能表示与生成流程,使框架能够应用于图形用户界面与视频游戏等多种视觉环境。
实验
评估在桌面 GUI 与开放式游戏环境中将多模态程序性知识与无技能及纯文本基线进行对比,以验证其对 agent 性能与决策动态的影响。组件消融实验证实,在过滤后的分支加载架构中将运行时状态判别卡片与视觉关键帧相结合,是实现准确技能检索与上下文保持的必要条件。使用分析表明,多模态指导提高了技能调用频率,同时通过减少冗余探索有效缩短任务轨迹。行为追踪最终证明,这些技能将 agent 执行从试错点击根本性地转化为具备更强完成意识的结构化、状态感知规划。
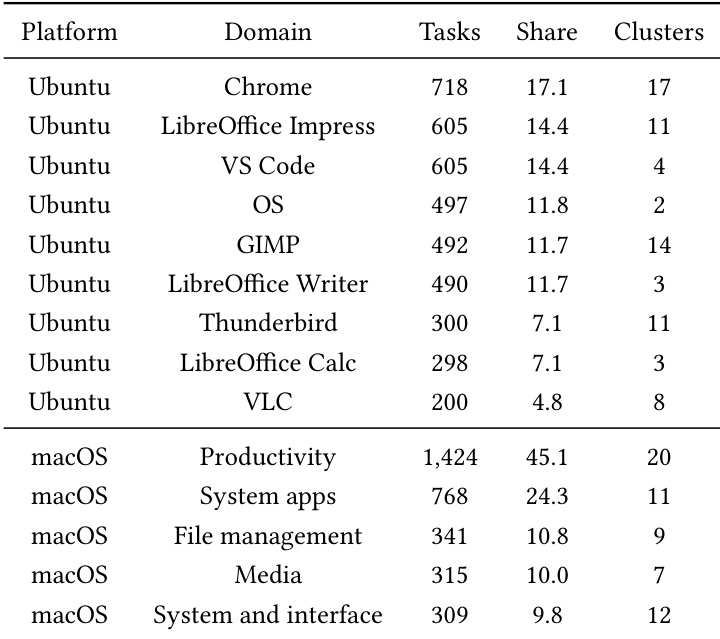
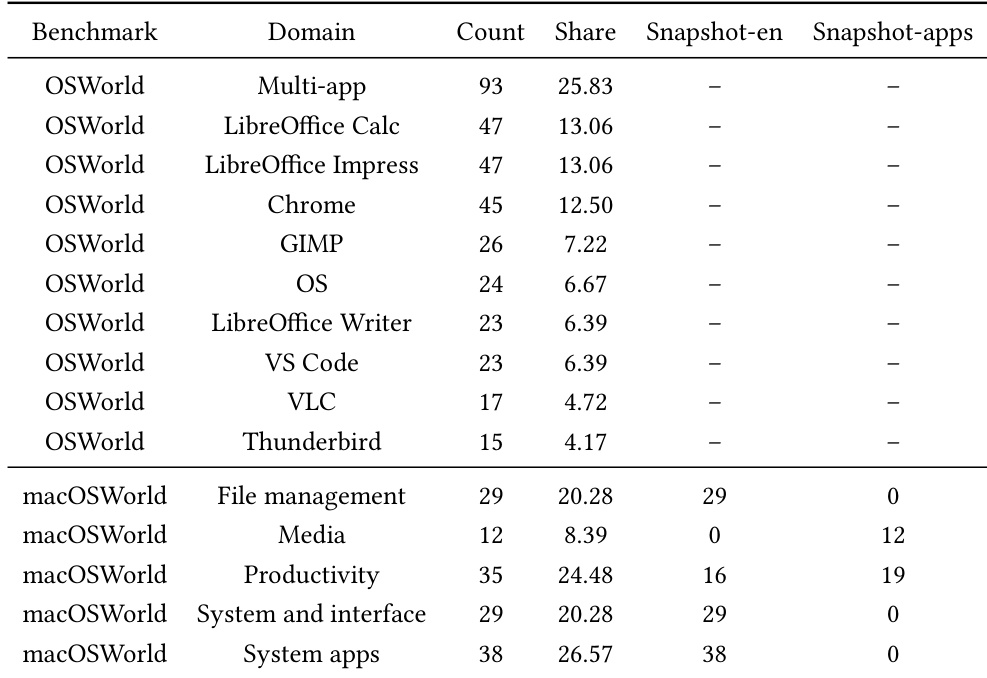
研究分析了不同平台与领域内任务及轨迹簇的分布情况,结果显示大部分任务与簇集中于 macOS 平台,尤其在生产力与系统应用中。数据表明,相较于 Ubuntu,macOS 的任务量更高且聚类更多样,反映出 macOS 环境中评估场景的范围更广。大部分任务与轨迹簇集中于 macOS 平台。macOS 上的生产力与系统应用拥有最多的任务与簇。Ubuntu 显示的任务与簇较少,跨领域分布相对有限。
MMSkills 在多种模型与任务上对视觉 agent 的影响得到评估,结果表明多模态程序性知识的整合提升了成功率并改变了 agent 行为。结果显示,在不同模型家族与任务领域中均取得一致的性能提升,MMSkills 带来更短的轨迹、减少的重复动作以及更高效的决策。MMSkills 在所有评估的模型与任务中均提高成功率,其中较弱模型与基于视觉定位的游戏设置提升最为显著。使用 MMSkills 缩短交互长度并减少重复动作,表明行为更高效且更具目标导向性。MMSkills 使 agent 行为转向结构化输入与更好的完成意识,减少探索性动作并增加任务完成验证。
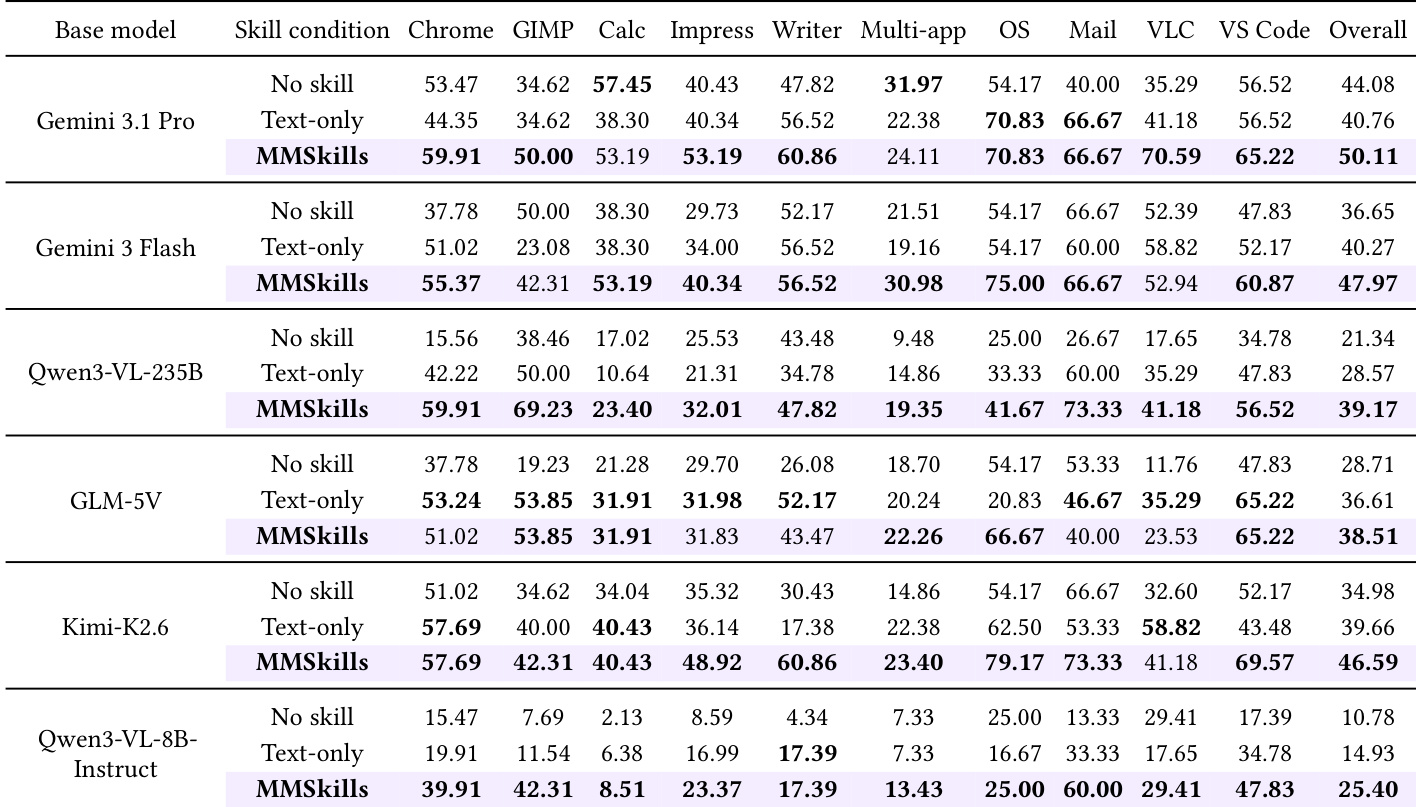
针对多个基准测试,MMSkills 对视觉 agent 的影响分析表明,多模态程序性知识的整合提高了任务成功率并改变了 agent 行为。结果显示,MMSkills 减少低级动作数量,降低重复行为,并将动作模式转向更结构化与目标导向的交互,尤其在点击使用率较高的模型中表现明显。MMSkills 降低低级动作与重复行为数量,从而实现更高效的执行。使用 MMSkills 的 agent 从重度点击行为转向更结构化输入与完成判定。多模态技能的整合缩短交互轨迹,并在多款模型中降低重复动作频率。
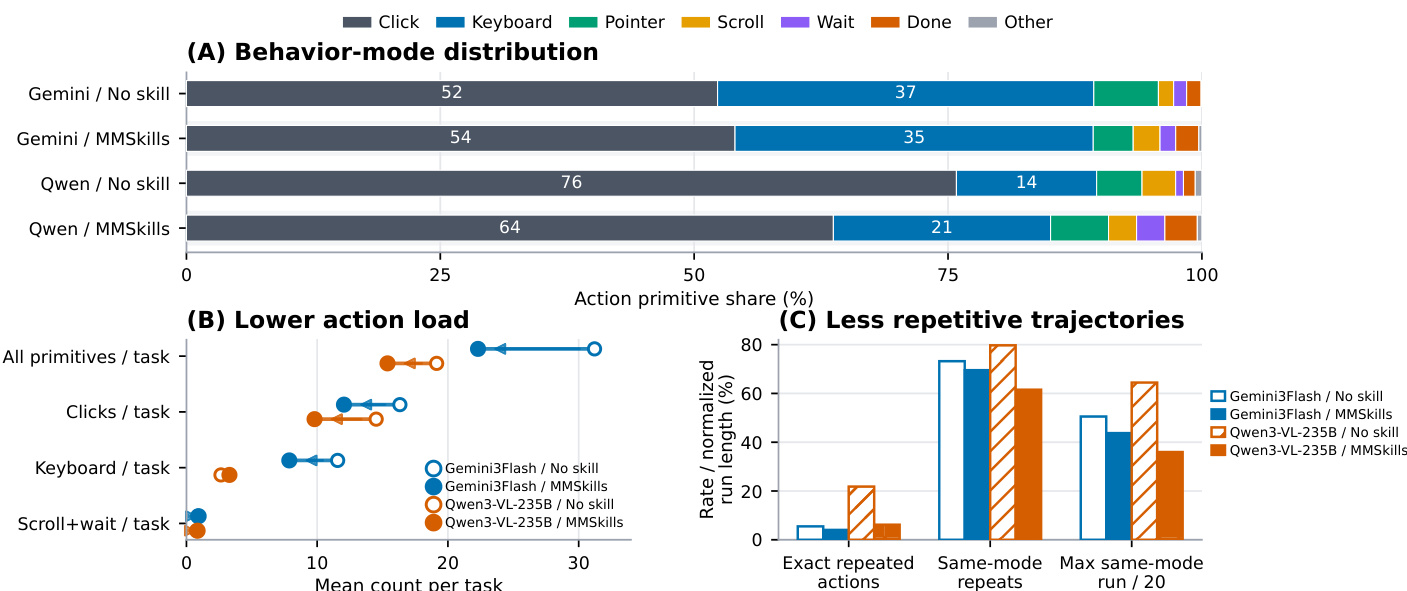
针对桌面环境与视频游戏等多个基准测试,多模态程序性技能对视觉 agent 的影响评估表明,引入这些技能持续改善成功率与行为效率,尤其对内部视觉推理能力有限的模型效果显著,同时减少求解步骤与重复动作。MMSkills 在所有评估模型与基准中提高成功率,较弱视觉 agent 提升幅度最大。MMSkills 降低低级动作与重复行为数量,促成更高效的结构化任务执行。使用 MMSkills 缩短轨迹并提升状态识别效果,尤其在结合分支加载与视觉证据过滤时更为明显。
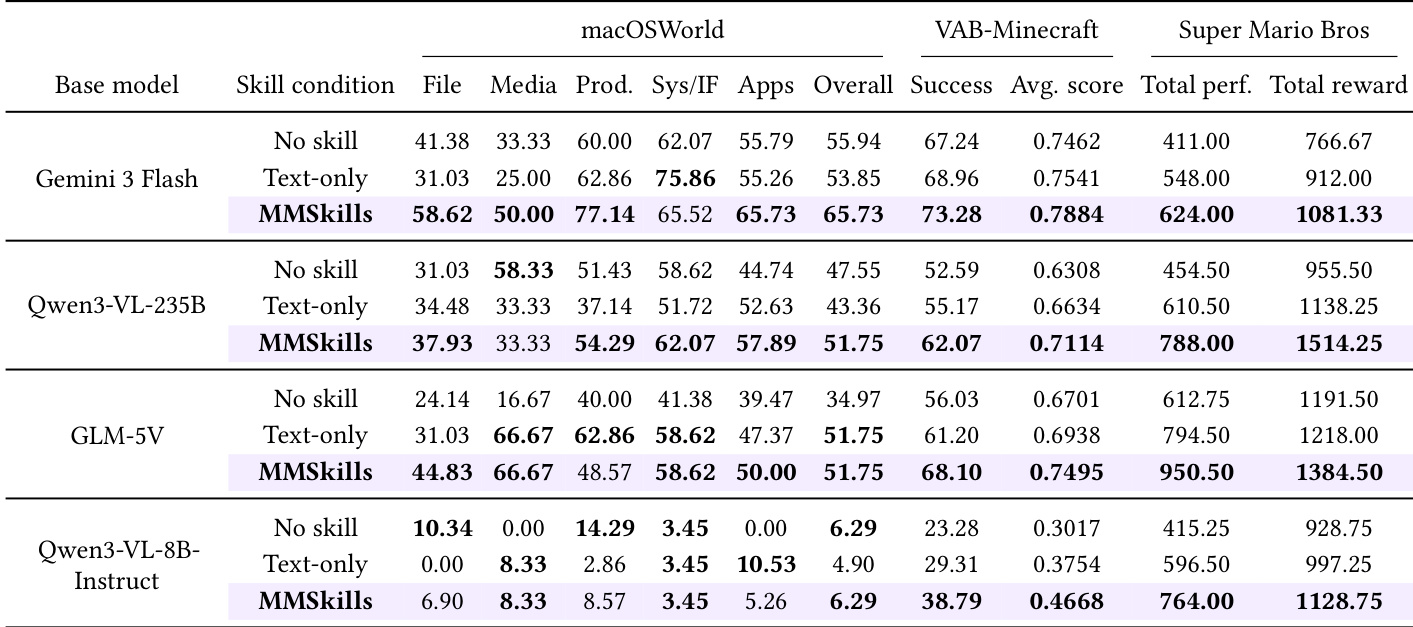
MMSkills 在桌面应用与游戏环境等多个基准测试中对视觉 agent 的影响评估显示,该框架在不同模型与领域持续改善性能,成功率与行为效率均有所提升。MMSkills 的有效性归因于其多模态特性,该特性支持更优的状态识别与更结构化的任务执行。MMSkills 在桌面应用与游戏环境等多样领域与模型中提升性能。其多模态特性促使 agent 行为更高效且更具目标导向性,减少冗余动作与重复模式。MMSkills 使 agent 更好地识别相关状态并针对性使用外部知识,从而提升任务求解效率。
实验套件针对多种桌面平台、应用领域与模型架构,评估多模态程序性技能整合至视觉 agent 的效果,以验证其对任务执行与行为效率的影响。结果一致表明,引入这些技能提升整体成功率,同时通过消除冗余动作与缩短交互轨迹从根本上重塑 agent 交互。最终,该方法促成更结构化与目标导向的工作流,并改善状态识别能力,为内在视觉推理能力较弱的模型带来最显著的行为改进。