Command Palette
Search for a command to run...
RepoZero:大语言模型能否从零开始生成代码仓库?
RepoZero:大语言模型能否从零开始生成代码仓库?
Zhaoxi Zhang Yiming Xu Jiahui Liang Weikang Li Yunfang Wu
摘要
尽管大型语言模型(LLMs)在代码生成方面近期取得了显著进展,但其在从零开始构建完整软件仓库方面的能力仍缺乏深入理解。根本性的瓶颈在于缺乏可验证且可扩展的评估手段:现有基准测试要么侧重于基于补丁的编辑,要么依赖人工或基于 LLM 的判断,这引入了偏差并限制了可复现性。在本工作中,我们提出了 RepoZero,这是首个支持从零开始、基于执行进行的仓库级生成完全自动化验证的基准测试。我们的核心思想是将生成问题重新定义为仓库复现:仅给定 API 规范,一个 Agent 必须重新实现整个仓库,使其行为与原始实现相匹配。这种设计允许通过输出等价性进行严格的黑盒验证,并通过复用现有的开源仓库自然支持大规模构建。为了进一步缓解数据泄露和捷径解(shortcut solutions)问题,我们引入了跨语言约束和沙盒化评估协议。基于该基准测试,我们提出了一种代理代码-测试迭代进化(Agentic Code-Test Evolution, ACE)框架,该框架执行迭代测试生成和基于错误的细化,从而为仓库级合成提供有效的测试时扩展(test-time scaling)能力。
一句话总结
这项工作介绍了 RepoZero,这是首个能够完全自动化、基于执行验证从零开始进行仓库级生成的基准测试,它将任务重构为仅根据 API 规范进行仓库复现,并提出了一个代理代码测试进化(ACE)框架,该框架采用迭代测试生成和错误驱动的细化,以实现仓库级合成的有效测试时扩展。
核心贡献
- 这项工作介绍了 RepoZero,这是首个基于 API 规范将任务重构为仓库复现,从而实现从零开始进行仓库级生成的完全自动化、基于执行验证的基准测试。
- 引入了跨语言约束和沙箱评估协议,以减轻评估过程中的数据泄露并防止捷径解决方案。
- 提出了一个代理代码测试进化(ACE)框架,用于执行迭代测试生成和错误驱动的细化,从而实现仓库级合成的有效测试时扩展。
引言
大型语言模型在代码生成方面取得了进展,但从零开始构建完整的软件仓库缺乏可靠的评估方法。现有基准测试通常依赖于基于补丁的编辑或主观判断,这会引入偏见并增加数据泄露的风险。为了克服这些挑战,作者提出了 RepoZero,这是首个实现完全自动化和基于执行验证的仓库级生成基准测试。该方法将生成重构为仓库复现,其中 agent 根据 API 规范重新实现功能以匹配原始行为。此外,他们引入了一个代理代码测试进化框架,利用迭代测试生成和错误驱动的细化来提高合成能力。
数据集

-
数据集组成与来源
- 作者介绍了 RepoZero,这是一个旨在评估端到端仓库生成能力的基准测试。
- 该数据集包含两个跨语言子集,源自 GitHub 上手动策划的开源仓库。
- 来源的选择基于严格的标准,包括确定性、开源完整性和架构复杂性,以确保多文件结构。
-
子集详情与统计
- RepoZero-Py2JS:包含 400 个样本,要求用 JavaScript 重新实现 Python 仓库。
- RepoZero-C2Rust:包含 200 个样本,要求用 Rust 重新实现 C/C++ 仓库。
- 难度等级:样本根据三个 LLM 的多数投票划分为简单、中等和困难类别,以估算代码行数、API 数量和输入/输出复杂性。
-
数据处理与过滤
- 测试文件生成:LLM agent 根据严格提示生成测试文件,每个文件调用 1 到 20 个 API。
- 测试用例验证:每个候选测试用例执行 20 次以确保稳定性。
- 过滤规则:如果样本触发运行时异常或产生非确定性输出(如内存地址或时间依赖变量),则予以丢弃。
- 最低阈值:仅当样本包含至少 10 个有效测试用例时才予以保留。
-
使用与维护
- 该基准测试作为评估框架而非训练数据,以减轻数据泄露。
- 初始仓库选择后,流程保持自动化,以允许持续更新和扩展。
- 通过执行测试用例的稳定输出验证建立真实值。
方法
提出的框架通过包含数据集构建和模型评估的两阶段管道运行。作者利用基于 agent 的自动化工作流生成高质量基准测试,随后评估迁移任务上的模型性能。
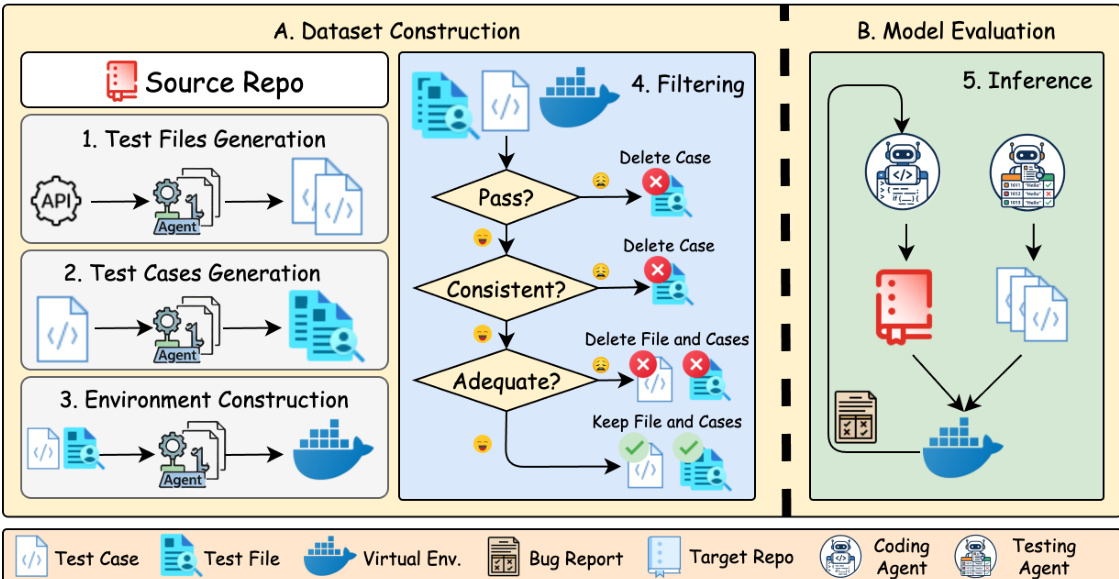
过程始于数据集构建,如左图所示。从源仓库开始,系统利用 agent 执行三个顺序生成任务。首先,生成测试文件以建立必要的结构。其次,合成特定测试用例以验证功能。第三,构建虚拟环境以确保代码可在隔离上下文中执行。生成后,应用严格的过滤机制。此阶段根据三个标准评估生成的工件:测试是否通过、行为是否与源一致以及覆盖范围是否充分。未通过任何检查的项目将被丢弃,确保只有高质量数据继续。
在模型评估阶段,如右图所示,系统进入推理循环。此阶段利用两个专用 agents:一个 Coding Agent 和一个 Testing Agent。Coding Agent 负责根据错误报告和 target repository 生成目标实现,而 Testing Agent 验证输出。agents 在严格的提示指南下运行,旨在确保跨语言迁移期间的保真度。例如,在 Python 到 Node.js 迁移任务中,提示强制使用纯 JavaScript 和 ES 模块,要求所有库和入口文件使用 .mjs 后缀。
此外,生成过程要求命令行参数使用 process.argv 与源语言相同的方式解析,确保 node test.mjs --arg val 的行为与 python test.py --arg val 完全相同。逻辑、数值精度和字符串格式必须完全匹配,console.log 输出要求与 Python print 语句逐字节相同。agents 还被限制仅使用 Node.js 内置模块,禁止外部 npm 包以维持零依赖环境。最后,强制执行项目结构将代码拆分为具有显式导出的模块,agents 必须作为黑盒实现逻辑,从接口推断行为而不是直接读取源代码。
实验
本研究使用 OpenHands-bash 和 Mini-SWE-Agent 在隔离的 Docker 容器中评估 coding agents,以实施严格的黑盒测试并防止评估作弊。实验结果表明,虽然整体性能未达最优,但 Mini-SWE-Agent 由于更好的上下文工程优于 OpenHands-bash,Claude-4.6-Sonnet 在基准测试中实现了最高的通过率。此外,ACE 框架表明,在推理期间集成动态测试生成通过解决边缘案例和优先考虑语义正确性而非简单的代码可运行性,显著提高了成功率。
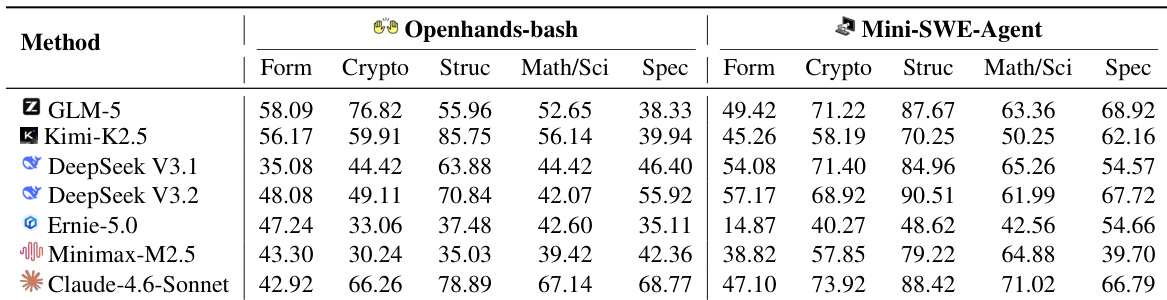
作者使用 OpenHands-bash 和 Mini-SWE-Agent 脚手架评估了多个大型语言模型,涵盖包括密码学和数据结构在内的五个功能领域。评估显示 Mini-SWE-Agent 通常优于 OpenHands-bash,而 Claude-4.6-Sonnet 在大多数类别中取得了顶级结果。Mini-SWE-Agent 在测试模型中通常产生比 OpenHands-bash 更高的性能分数。Claude-4.6-Sonnet 在数学和专业领域表现出优于其他模型的能力。较新的模型迭代(如 DeepSeek V3.2)在多个类别中显示出比早期版本(如 V3.1)的性能提升。
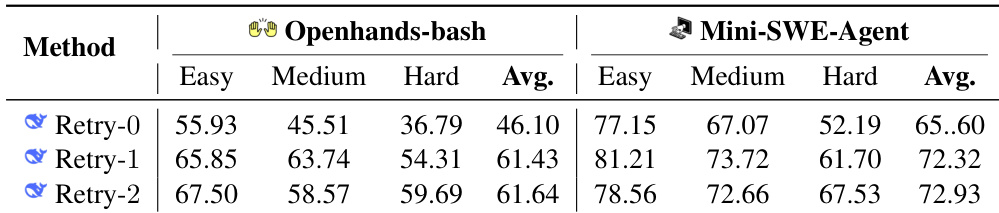
实验使用 OpenHands-bash 和 Mini-SWE-Agent 脚手架评估了 DeepSeek V3.1 骨干模型在 Py2JS 基准测试上的表现。它评估了不同任务难度和由重试迭代次数定义的测试时扩展策略下的性能。Mini-SWE-Agent 在所有难度级别和重试配置中始终优于 OpenHands-bash。从零次重试移动到一次重试时性能显著提高,第二次重试的收益递减。任务难度与成功率呈负相关,性能从简单类别下降到困难类别。
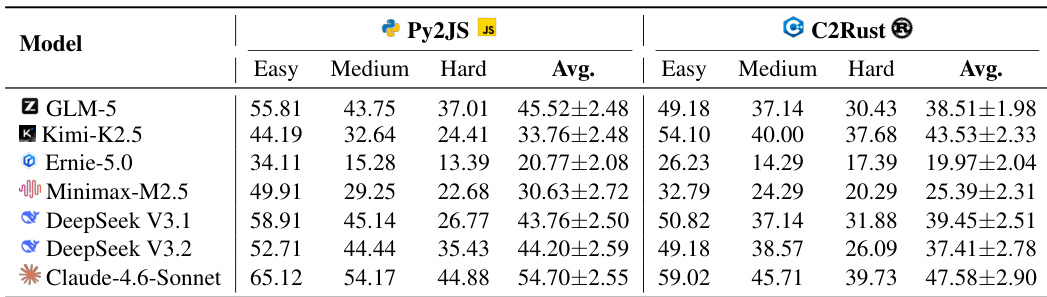
作者使用 Mini-SWE-Agent 脚手架在 RepoZero 基准测试上评估了各种大型语言模型,侧重于 Python 到 JavaScript 和 C 到 Rust 翻译任务。结果按难度等级分类,表明虽然较新模型通常实现更高的通过率,但随着任务复杂性增加,性能一致下降。Claude-4.6-Sonnet 在两个翻译基准测试中相比其他模型实现了最高的通过率。对于所有评估模型,随着任务难度从简单移动到困难类别,性能通常会下降。模型家族的较新迭代(如 DeepSeek V4 和 Kimi-K2.6)显示出比其先前版本的性能提升。
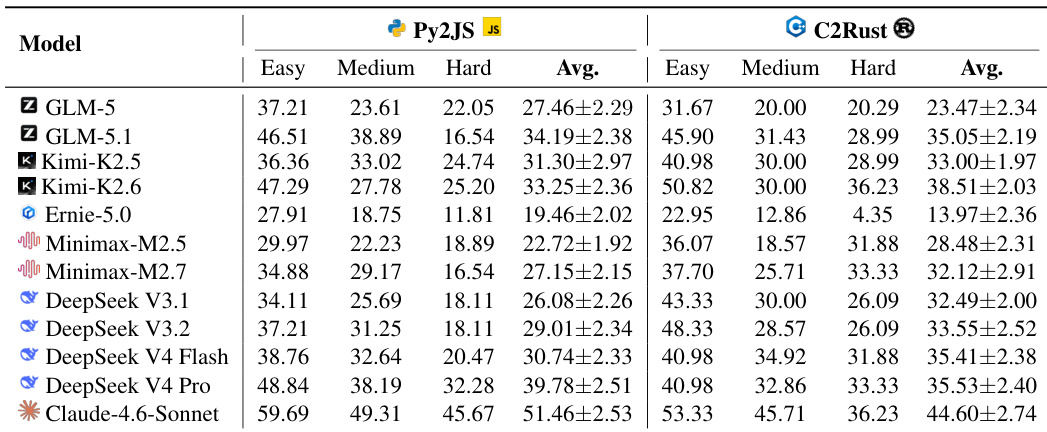
作者使用 Mini-SWE-Agent 脚手架在 RepoZero 基准测试上评估了各种大型语言模型,以评估它们在 Python 和 JavaScript 以及 C 和 Rust 之间移植代码的能力。结果表明,Claude-4.6-Sonnet 在所有难度级别和翻译任务中始终实现最高的通过率,而 Ernie-5.0 记录最低性能。通常,模型在 Python 到 JavaScript 任务上表现出比 C 到 Rust 任务更高的成功率,并且随着任务难度增加性能下降。Claude-4.6-Sonnet 在 Py2JS 和 C2Rust 任务中相比其他模型实现了最高的平均通过率。对于所有模型,随着任务难度从简单增加到困难,性能一致下降。对于大多数评估模型,Python 到 JavaScript 移植任务产生的成功率高于 C 到 Rust 移植。
实验评估了迭代细化对使用 DeepSeek V3.1 骨干模型的 coding agents 的影响,比较了 OpenHands-bash 和 Mini-SWE-Agent。结果表明,增加重试循环次数显著提高了两个框架的性能。此外,Mini-SWE-Agent 在所有难度级别中始终实现比 OpenHands-bash 更高的成功率。将重试迭代次数从 0 增加到 2 导致两个 agents 的性能一致提升。Mini-SWE-Agent 在简单、中等和困难难度级别中始终优于 OpenHands-bash。随着任务难度增加,性能下降,困难任务产生的成功率最低。

作者使用 OpenHands-bash 和 Mini-SWE-Agent 脚手架评估了多个大型语言模型,涵盖代码翻译和功能基准测试。Mini-SWE-Agent 始终优于 OpenHands-bash,Claude-4.6-Sonnet 在不同难度级别中表现出优于其他模型的能力。性能趋势显示,成功率随任务难度增加而下降,但随额外重试循环而提高,而较新的模型迭代通常超越早期版本。