Command Palette
Search for a command to run...
VibeServe:AI代理能否构建定制化的大型语言模型服务系统?
VibeServe:AI代理能否构建定制化的大型语言模型服务系统?
Keisuke Kamahori Shihang Li Simon Peter Baris Kasikci
摘要
多年来,我们一直像构建其他关键基础设施一样,建立大语言模型(LLM)推理服务系统:采用单一的通用技术栈,经过工程师数年的人工微调,旨在支持所有模型和工作负载。在本文中,我们采取了相反的策略:利用多智能体循环(multi-agent loop),自动为不同的使用场景合成定制化的推理服务系统。我们提出了 VibeServe,这是首个能够端到端生成完整 LLM 推理技术栈的智能体循环(agentic loop)。VibeServe 利用外层循环来规划和追踪系统设计的搜索过程,并利用内层循环来实现候选方案、验证正确性,并在目标基准测试(benchmark)上评估性能。在标准部署环境中,现有系统已高度优化,VibeServe 的表现与 vLLM 相当,这表明运行时(generation-time)专用化并不以牺牲性能为代价。更有趣的是,在非标准场景中,VibeServe 通过挖掘通用系统所忽略的机会,在涉及非标准模型架构、工作负载知识以及特定硬件优化等六个场景中,均优于现有系统。综上所述,这些结果揭示了基础设施软件在设计空间中的一个不同方向:运行时专用化,而非通用性。
一句话总结
VibeServe 是首个 agent 循环,它通过采用外部循环进行设计规划、内部循环进行实施和评估,端到端地生成整个定制的 LLM 服务堆栈。它优先考虑生成时的专用性而非运行时的通用性,以便在标准部署中与 vLLM 保持竞争力,同时在涉及非标准模型架构、工作负载知识和硬件特定优化的六种场景中超越现有系统。
核心贡献
- 本文介绍了 VibeServe,这是首个为不同使用场景端到端生成整个 LLM 服务堆栈的 agent 循环。它使用外部循环规划系统设计,使用内部循环实施候选方案,同时检查正确性并衡量性能。
- 该架构采用基于角色的 agents,它们利用服务系统知识库的技能库和直接分析器访问权限在共享工作空间上协作。这些 agents 将性能分析融入到每一次实施更改中,以便在合成过程中针对高性能代码。
- 实验表明,该方法在标准部署设置中与 vLLM 保持竞争力,同时在六种非标准场景中超越现有系统。其中两个涉及非标准模型架构和硬件的具体场景无法在任何通用堆栈上运行。
引言
大型语言模型服务基础设施通常依赖于为主流工作负载手动优化的通用堆栈。这种一刀切的方法会对新兴模型架构和专用硬件产生性能开销,其中标准抽象失效。现有的 agent 系统解决了细粒度的优化问题,但由于上下文窗口限制和状态漂移,难以协调端到端系统合成。作者提出了 VibeServe,这是一个多 agent 框架,可自动生成针对特定部署目标的定制服务系统。其设计采用外部规划循环和内部实施循环来管理长视野任务而不丢失上下文。这种方法在标准部署上实现了与手动调整基线的同等水平,同时在涉及复杂模型或非常规硬件的非标准场景中提供了显著的速度提升。
方法
作者提出了 VibeServe,这是一个生成针对用户指定模型、硬件平台和工作负载的定制服务系统的框架。该系统不依赖通用运行时来覆盖每种情况,而是从一组用户提供的小规模工件中迭代生成端到端服务系统。
如框架图所示,这种方法与当前的通用服务形成对比,后者试图用一个运行时覆盖各种工作负载和硬件的常见情况。VibeServe 改为为每个目标创建一个定制服务系统,针对工作负载、模型和硬件的特定交集进行优化。
下图所示的详细架构将生成过程分解为外部规划循环和内部实施循环。系统接受用户输入,包括模型权重、参考代码、准确性检查脚本和基准指标。这些输入定义了参数化框架的每个目标合同。
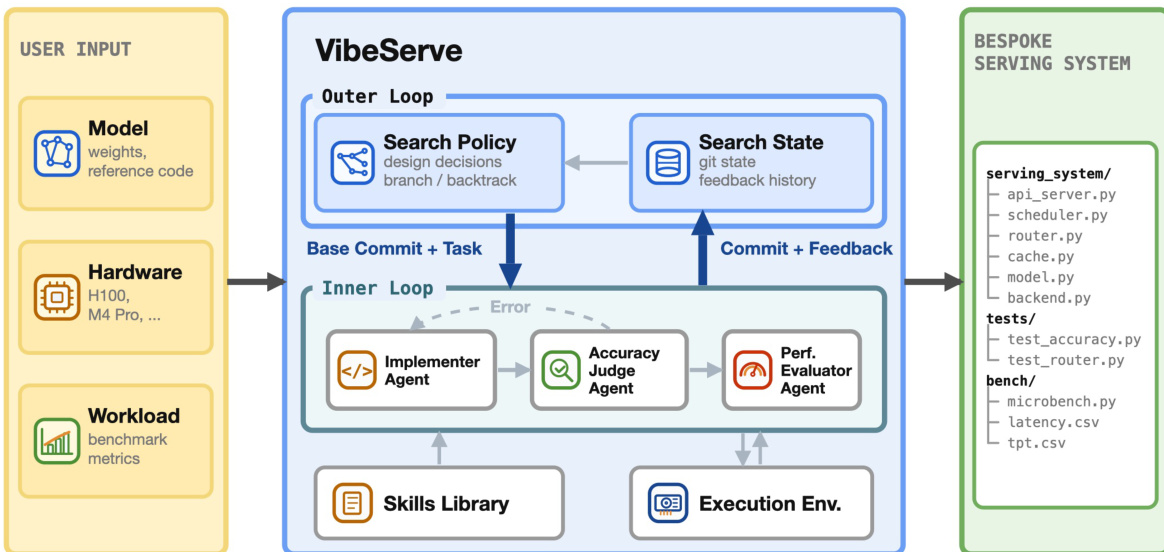
外部循环管理搜索策略和搜索状态。它从 git 仓库读取先前状态,每轮向内部循环分发一个任务,并接收带有性能指标的结果提交。此循环支持协调机制,例如如果后续轮次通过正确性但在主要指标上出现回归,则回滚到较早的检查点。实施的策略包括进化搜索和问题追踪器方法,后者维护结构化的优化任务待办队列。
在每一轮中,内部循环采用多个 agents 将代码编辑提议与验证分离。Implementer agent 在隔离的工作空间中生成和修订候选服务系统。此工作空间以只读方式挂载用户工件,并暴露目标执行环境。一旦 Implementer 生成构建,Accuracy Judge agent 就会把关整体正确性。它根据参考实现验证端到端模型准确性,并检查奖励黑客模式,例如仅模式合成或绕过模型推理。
如果实施通过正确性检查,Performance Evaluator 会对系统进行性能分析。它从用户提供基准上的端到端性能开始,并在需要更精细测量时使用特定于平台的分析器进行深入分析。Evaluator 为后续轮次生成性能提示,这些提示反馈给外部循环。
为了支持这些 agents,VibeServe 提供了一个可扩展的技能库。该库包含按抽象层组织操作知识,例如模型架构、服务算法和硬件平台。agents 从此库中检索聚焦指导,使它们能够应用连续批处理等技术或利用 FlashInfer 等特定库,而无需重新实现内核。
实验
评估在六种涵盖不同工作负载模式、模型架构和硬件配置的场景中评估 VibeServe,以确定生成的系统是否匹配人工工程系统的性能或解决特定限制。在标准服务环境中,该系统与现有框架保持同等水平,同时自主优化吞吐量和延迟。对于混合架构和本地约束解码等特殊情况,VibeServe 通过实施通用系统缺乏的优化,提供了显著的性能提升,验证了定制系统可以有效处理现有基础设施不足的复杂用例。
该表详细说明了 VibeServe agent 在六种不同服务场景中的资源消耗,突出了 Orchestrator、Implementer、Judge 和 Performance Evaluator 角色之间的工作分布。Implementer 角色始终消耗总时长的最大部分,而 Orchestrator 所需时间最少。总 agent 执行时间因场景而异,标准 Llama-3.1 服务任务需要最多资源,而 JSON 约束解码效率最高。Implementer 角色主导执行时间,通常占所有场景中时长的最大份额。场景 A 需要最高数量的调用和总时长,反映了优化成熟设置的难度。Orchestrator 角色在所有实验中始终保持最低的时间份额和调用量。

评估评估了 VibeServe agent 在六种不同服务场景中的资源消耗,以确定 Orchestrator、Implementer、Judge 和 Performance Evaluator 角色之间的工作负载分布。结果表明,Implementer 角色始终消耗最大部分的执行时间和调用量,而 Orchestrator 在所有场景中保持最低份额。总体而言,实验强调总 agent 效率因任务复杂度而异,标准 Llama-3.1 服务需要最多资源,而 JSON 约束解码证明效率最高。