Command Palette
Search for a command to run...
MOSS-TTS 技术报告
MOSS-TTS 技术报告
SII-OpenMOSS Team
摘要
本报告介绍了 MOSS-TTS,一种基于可扩展技术路径(离散音频 Token + 自回归建模 + 大规模预训练)构建的语音生成基础模型。该模型建立在 MOSS-Audio-Tokenizer 之上,这是一种因果 Transformer 分词器,能够利用可变比特率残差向量量化(RVQ)和统一的语义-声学表示,将 24kHz 音频压缩至 12.5fps。我们发布了两种互补的生成器:MOSS-TTS 强调结构简洁性、可扩展性以及在长上下文和控制导向场景下的部署能力;MOSS-TTS-Local-Transformer 则引入了帧局部自回归模块,以实现更高的建模效率、更强的说话人特征保留能力以及更短的音频首帧生成时间。在多语言及开放域设置下,MOSS-TTS 支持零样本声音克隆、Token 级时长控制、音素/Pinyin 级发音控制、流畅的语码转换以及稳定的长文本生成。本报告总结了所发布模型的设计、训练配方及实证特性。
一句话总结
SII-OpenMOSS 团队推出了 MOSS-TTS,这是一个基于离散音频 tokens、自回归建模和大规模预训练构建的语音生成基础模型。该模型使用 MOSS-Audio-Tokenizer 将 24kHz 音频压缩至 12.5fps,并采用可变比特率 RVQ,发布两个互补的生成器。其中 MOSS-TTS 强调结构简化和可扩展性,而 MOSS-TTS-Local-Transformer 优先考虑效率和说话人保留,以实现零样本语音克隆、token 级时长控制、音素/拼音级发音控制,以及在多语言开放域设置下的流畅语码转换。
核心贡献
- 本工作提出了 MOSS-TTS,这是一个基于结合离散音频 tokens、自回归建模和大规模预训练的可扩展方案构建的语音生成基础模型。该方法利用 MOSS-Audio-Tokenizer,一种因果 Transformer tokenizer,将 24kHz 音频压缩至 12.5fps,并采用可变比特率 RVQ 和统一的语义 - 声学表示。
- 该报告发布了两个互补的生成器,其中 MOSS-TTS 强调结构简化,而 MOSS-TTS-Local-Transformer 引入了帧局部自回归模块。后者在相同的 tokenizer 和大规模预训练方案下,实现了更高的建模效率、更强的说话人保留和更短的首音时间。
- 在多语言和开放域设置中,该模型支持零样本语音克隆、token 级时长控制和音素级发音控制。该设计实现了稳定的长文本生成和流畅的语码转换能力,无需依赖外部预训练音频教师。
引言
现代语音生成越来越依赖离散音频 tokenization 和自回归建模来实现可扩展的基础模型。然而,现有方法往往难以在确保长上下文合成稳定性的同时平衡压缩效率与语义对齐。作者通过提出 MOSS-TTS 解决了这些挑战,这是一个基于离散 tokens、自回归建模和大规模预训练的可扩展方案构建的基础模型。他们整合了一种统一语义和声学表示的因果 Transformer tokenizer,并引入了两种互补的生成器架构,以在简化与效率之间进行权衡。该框架实现了零样本语音克隆,并在多语言设置下支持对时长和发音的细粒度控制。
数据集

数据集组成与来源
- 作者从自然发生的开放域录音中获取音频,包括播客、有声读物、广播新闻、电影和网络内容。
- 原始网络音频经过三阶段流程处理,以确保音频清洁度和对 TTS 监督的真实转录对齐。
预处理与过滤流程
- 音频预处理: 作者将原始文件重采样至 48 kHz,并使用 MossFormer2-SE-48K 进行降噪。音量归一化应用基于 RMS 的增益钳位和峰值归一化,以标准化不同来源的幅度。
- 说话人分割: DiariZen 执行说话人分离以创建说话人标记的间隔。短于 0.1 秒的片段被移除,连续的同说话人片段被合并。录音限制为一小时。
- 转录生成: MOSS-Transcribe-Diarize 生成多语言转录。基于规则的检查丢弃空文本或过度重复。LLM 通过修复截断和移除非语音标签来优化内容。
- 质量验证: 最终配对必须通过音频质量检查(DNSMOS 大于 2.8,Meta AudioBox PQ 大于 6.5),匹配音频和文本语言标签,并保持语言特定的字符率一致性。
合成与增强
- 音色转移: 作者使用 WavLM-Large 嵌入相似度选择的随机 30 秒剪辑,从同一说话人构建提示 - 目标配对。
- 鲁棒性与覆盖范围: 对现有配对应用文本噪声变换。添加音素脚本和单字符话语以处理发音控制和短文本输入。
- 时长格式化: 资产被序列化为时长条件化和自由时长变体,以支持训练期间的显式和隐式时长监督。
训练应用
- 语料库支持涵盖数百万小时语音数据的四阶段预训练计划。
- 关于领域份额、语言分布和话语时长的统计详细信息见论文中的图 4。
方法
作者提出了一个建立在三个核心组件之上的语音生成框架:高质量音频 tokenizer、大规模数据流程和自回归生成模型。
音频 Tokenizer 架构 系统的基础是 MOSS-Audio-Tokenizer,它将连续音频转换为适合自回归建模的离散 tokens。如框架图所示,该模型采用 RVQ-GAN 框架,包括因果编码器、残差向量量化器 (RVQ)、因果解码器、语义头和对抗判别器。编码器和解码器均基于因果 Transformer 构建,每个包含 68 个块,利用 10 秒滑动窗口注意力机制以促进流式推理。编码器使用 patchify 操作和线性投影,在四个阶段中将 24 kHz 波形逐步下采样至 12.5 fps 的帧率。
离散 tokenization 使用 32 层残差向量量化器执行。每层采用大小为 1024 的码本,具有因子化向量量化和 L2 归一化码。为了鼓励语义结构化表示,附加了一个 0.5B 仅解码器因果语言模型作为语义头。该头通过自回归预测基于量化器输出的文本,提供音频到文本监督,涵盖自动语音识别和音频描述等任务。
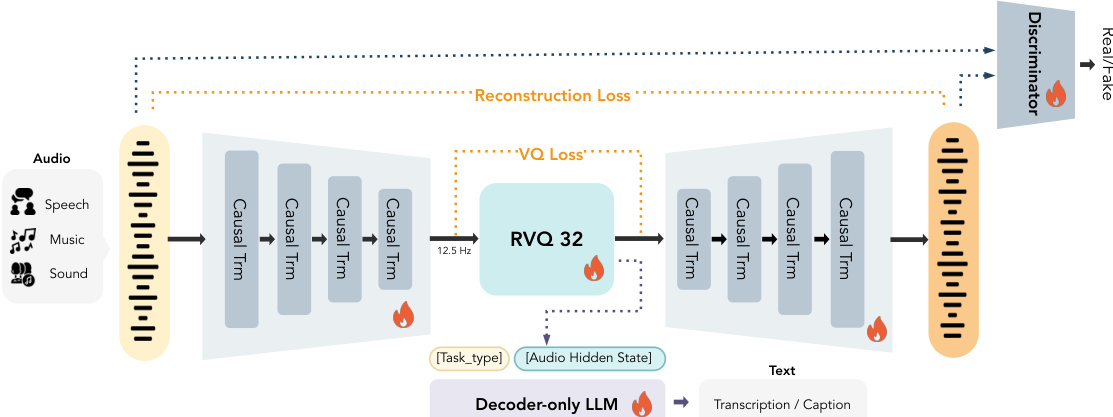
训练 tokenizer 涉及多任务学习框架。语义目标使用标准交叉熵损失优化:
Lsem=−t=1∑∣s∣logpθLLM(st∣T,q,s<t),其中 s 表示目标文本 token 序列,q 表示量化音频表示。量化器优化利用带有承诺损失和码本损失的因子化向量量化。为了确保高保真重建,采用多尺度梅尔频谱损失:
Lrec=i=5∑11∥S2i(x)−S2i(x^)∥1,此外,使用多判别器的对抗训练来提高感知质量,对判别器损失采用最小二乘 GAN 公式,并为生成器结合特征匹配损失。
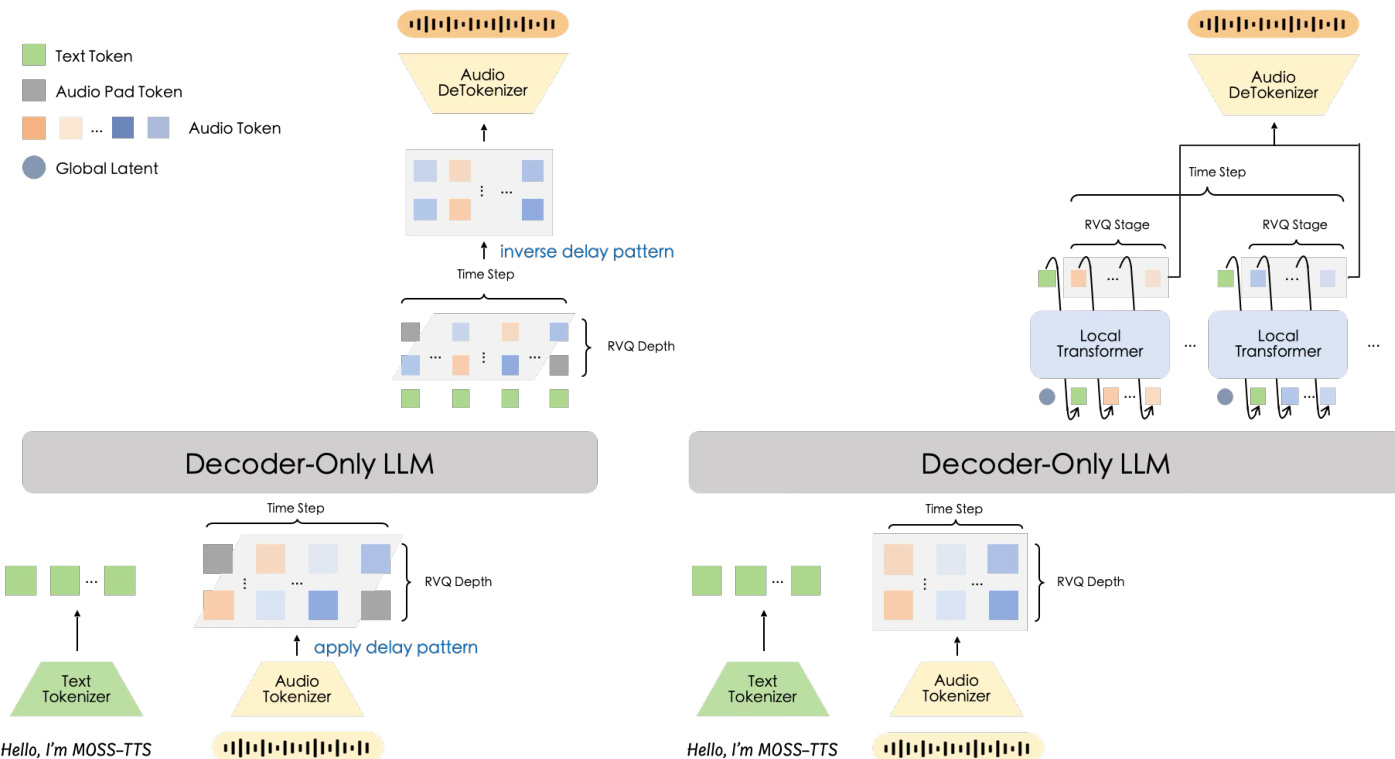
生成模型架构 MOSS-TTS 探索了两种不同的架构来对离散音频 tokens 进行建模。如架构比较图所示,作者评估了 Delay-Pattern 模型和 Global-Latent + Local Transformer 模型。
Delay-Pattern 模型利用带有多个预测头的单一 Transformer 骨干。它对 RVQ 层应用时间延迟偏移,使得 j 层向前偏移 j−1 帧。这允许模型从单一骨干隐藏状态预测所有通道,而不过度增加序列长度。输入音频表示向量是所有层嵌入的总和,输出头预测文本或填充通道以及 32 个音频通道。
Global-Latent + Local Transformer 模型引入了分层设计。骨干在每个对齐步产生一个全局潜在变量,轻量级自回归模块将该潜在变量扩展为步内 token 块。该方法对 token 块进行建模而不引入时间偏移,在每个帧内插入一个长度为 Nq+1 的额外自回归循环。虽然在稳态解码中计算量更大,但该设计为帧级 token 建模提供了更强的归纳偏置,并表现出更高的建模效率。
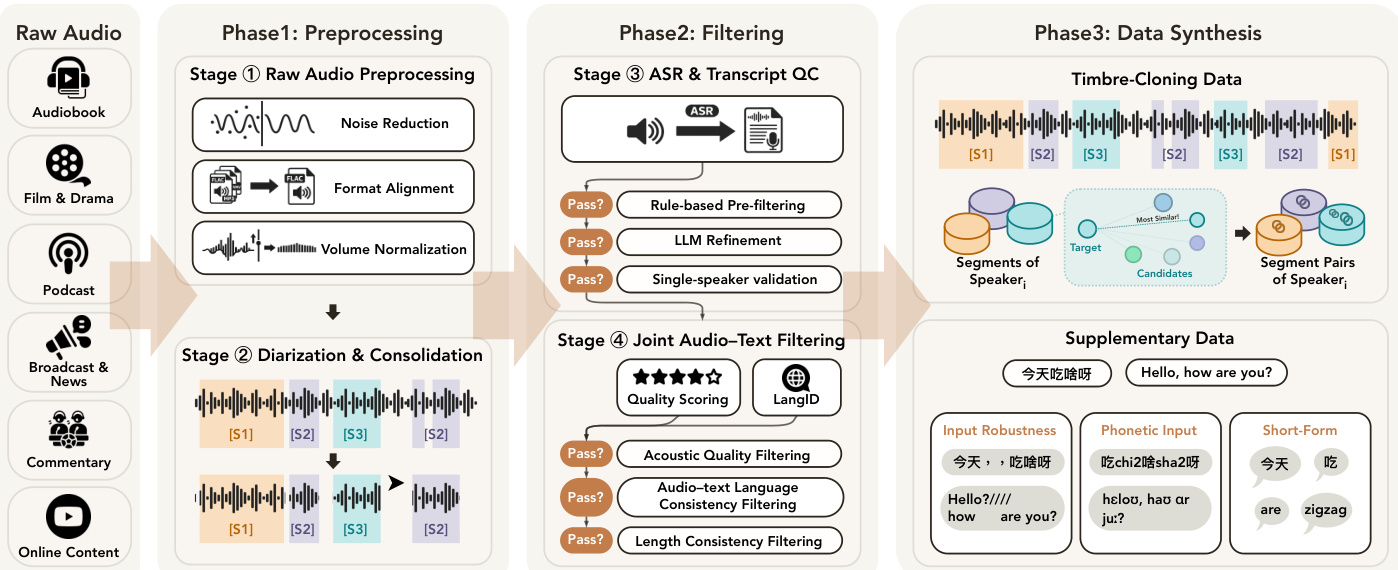
数据流程与预训练 为了支持大规模预训练,作者构建了一个高质量数据流程,将原始开放域录音转换为可训练资产。如概述图所示,该过程分为三个主要阶段。
第一阶段涉及预处理,包括降噪、格式对齐、音量归一化和说话人分离,以将原始音频整合为单说话人片段。第二阶段专注于过滤,利用 ASR 和转录质量控制、基于规则的预过滤以及联合音频 - 文本过滤,以确保音频质量和语言一致性。第三阶段涵盖数据合成,通过配对同一说话人的片段生成音色克隆数据,并为输入鲁棒性、音素输入和短文本任务创建补充数据。
预训练遵循具有四个阶段的课程学习策略。第一阶段专注于使用主要过滤语料库获取基本对齐。第二阶段在稳定高学习率下扩展能力,引入音色克隆和面向控制的数据。第三阶段执行线性衰减混合重平衡和质量巩固。最后,第四阶段扩展上下文窗口以进行长文本生成。这种分阶段的方法确保模型在解决更复杂的控制任务和长上下文依赖之前学习核心文本 - 语音映射。
实验
该评估通过保真度、语音克隆、多语言鲁棒性和可控性的基准测试来评估 MOSS-Audio-Tokenizer 和语音生成模型。研究结果表明,tokenizer 在比特率区间方面优于开源基线,而生成架构揭示了权衡,其中 Local-Transformer 变体在说话人相似度方面表现出色,而标准模型更好地支持时长控制和超长生成。尽管扩展输出中存在累积说话人漂移,但该系统展示了在音素级编辑和零样本克隆方面的实际可用性,无需专门微调。
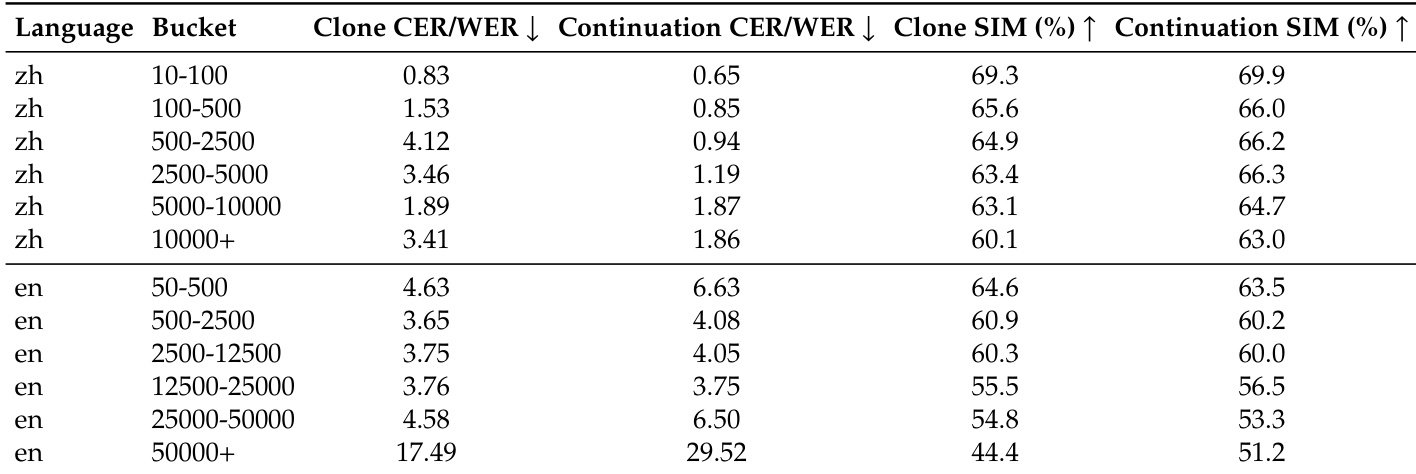
该表评估超长语音生成性能,跟踪中文和英文在不同递增时长桶中的内容保真度和说话人相似度。结果表明,中文的内容准确性保持稳定,但在最长时间范围内英文显著下降。说话人相似度通常随着时长增加而下降,与克隆模式相比,延续模式在扩展长度下表现出更好的说话人身份保留。中文生成在所有时长桶中保持低错误率和高说话人相似度。英文内容保真度在最长时间处急剧下降,显示词错误率大幅增加。在最长生成长度下,延续模式比克隆模式更好地保留说话人相似度。
该评估评估九种语言的多语言语音克隆能力,将 MOSS-TTS 架构与各种开源基线进行比较。结果表明,该模型在欧洲语言中实现了具有竞争力的性能,无需特定任务微调,但在日语和韩语方面性能明显较低。推理模式之间的比较显示,延续模式通常产生与克隆模式不同的错误概况,特别是影响非英语语言。MOSS-TTS 在几种欧洲语言中优于较小的基线模型,包括德语、法语和俄语。与中文和英文相比,零样本克隆性能在日语和韩语中持续较弱。延续模式在两种 MOSS-TTS 架构中均降低了日语相对于克隆模式的错误率。
作者评估 MOSS-Audio-Tokenizer 与最先进的开源模型在低、中、高比特率区间,以评估重建保真度。结果表明,所提出的 tokenizer 在语音重建质量方面始终优于基线,同时在通用音频和音乐任务上保持有竞争力的性能。MOSS-Audio-Tokenizer 在所有比特率类别的语音指标(如说话人相似度和可懂度)中得分最高。随着比特率增加,重建质量稳步提高,表明有效利用模型容量。与像 Encodec 和 Mimi 这样的专用 tokenizer 相比,该模型在通用音频和音乐基准测试中保持竞争力。
作者通过测试中文和英文中的短跨度部分替换和整个句子完全替换来评估音素级发音控制。结果表明,该模型在所有条件下实现了低错误率,展示了细粒度发音编辑的实际可用性。对于两种语言,部分替换设置始终比完整句子替换产生更低的错误率。在两种实验设置中,中文发音控制的错误率低于英文。该模型保持低仅跨度错误率,表明对音素级生成的有效控制。

提供的表评估语音生成模型在中文和英文语言上的 token 级时长控制。它报告了各种时间桶中的相对时长误差,表明该模型有效地匹配从几秒到半小时的话语的目标时长。结果表明,即使生成语音的时长增加,该模型也表现出强大的可控性。该模型在中文和英文语言上表现出一致的时长控制性能。准确性在 10 秒到 10 分钟的 utterances 中最高,其中误差指标最小化。即使对于延长至 30 分钟的更长片段,该模型也保持稳定的时长预测,误差仅边际增加。
该评估套件评估超长语音生成、多语言克隆、tokenizer 保真度,以及在多种语言上对发音和时长的细粒度控制。结果表明,虽然中文性能在长时间内保持稳定,但英文以及日语和韩语等语言显示内容保真度下降,延续模式表现出比克隆模式更好的说话人身份保留。此外,提出的音频 tokenizer 实现了卓越的语音重建质量,而生成模型展示了音素级编辑和长达 30 分钟时长匹配的鲁棒可控性。