Command Palette
Search for a command to run...
通过简单且统一的缩放实现金牌级奥林匹克推理
通过简单且统一的缩放实现金牌级奥林匹克推理
摘要
标题:摘要:近期推理模型的发展显著推动了长周期数学与科学问题的求解能力,多个系统在国际数学奥林匹克(IMO)和国际物理奥林匹克(IPhO)题目上已达到金牌水平表现。在本文中,我们提出了一种简单且统一的方案,用于将经过后训练的推理主干模型转化为严格的奥林匹克级别求解器。该方案首先采用反向困惑度课程进行监督微调(SFT),以植入严格的证明搜索和自我检查行为;随后通过两阶段强化学习(RL)流程扩展这些行为,从具有可验证奖励的RL逐步过渡到更精细的证明级RL;最后通过测试时扩展(test-time scaling)进一步提升求解性能。应用该方案,我们使用约340K条长度低于8K token的轨迹对30B-A3B主干模型进行SFT训练,随后执行200步RL训练。所得模型SU-01能够在复杂问题上支持稳定的推理,其轨迹长度超过100K token,同时在数学和物理奥林匹克竞赛中达到金牌水平表现,包括IMO 2025/USAMO 2026以及IPhO 2024/2025。此外,该模型还展现出将科学推理能力泛化至数学与物理以外领域的强大能力。
一句话总结
本文介绍 SU-01,一款参数量为 30B-A3B 的推理模型。该模型通过统一的扩展训练方案进行训练,该方案结合了逆困惑度监督微调、两阶段强化学习流水线以及测试时扩展(test-time scaling),旨在培养严谨的证明搜索与自我检查行为。最终,该模型在国际数学与物理奥林匹克竞赛中达到金牌水平表现,并在数学与物理之外的领域展现出强大的泛化能力。
核心贡献
- 提出统一的训练方案,通过逆困惑度课程进行监督微调,并结合从可验证奖励扩展至证明级优化的两阶段强化学习流水线,将经过后训练的推理骨干网络转化为奥林匹克级别的解题模型。
- 推出 SU-01 模型(30B-A3B 架构),该模型基于约 34 万条长度低于 8K token 的轨迹进行训练,并经过 200 步强化学习。该模型能够在复杂问题上维持稳定推理,即使轨迹长度超过 100K token 亦能保持连贯。
- 在国际数学奥林匹克(IMO 2025)、美国数学奥林匹克(USAMO 2026)及国际物理奥林匹克(IPhO 2024/2025)等赛事中达到金牌水平表现,同时在数学与物理之外的科学领域展现出强大的推理泛化能力。
引言
本文针对国际数学与物理奥林匹克竞赛中对于严谨且达金牌水平推理的需求展开研究。在此类任务中,模型必须生成完整的证明过程,并在极长的推理跨度内保持逻辑连贯。先前的方法通常依赖复杂的神经符号系统、庞大的模型规模或相互割裂的训练策略,这些限制因素影响了模型的普及性与泛化能力。研究团队采用精简且统一的训练后方案,将紧凑的 30B-A3B 骨干网络转化为 SU-01,并通过一系列针对性干预实现金牌水平的性能。该方法在监督微调阶段采用逆困惑度课程,以培养证明搜索与自我检查行为;随后接入两阶段强化学习流水线,将优化目标从粗粒度的可验证奖励推进至精细的证明级奖励;最后通过自我验证实现测试时扩展。最终得到的模型能够维持超过 100K token 的稳定推理轨迹,并在其主训练分布之外的科学领域展现出强大的迁移能力。
数据集
-
数据集构成与来源: 研究团队精心构建了一个涵盖数学、科学、编程及指令遵循的广泛数据混合集。数学提示词来源于 Evan Chen 的奥林匹克竞赛资料、Shuzhimi 论坛、Art of Problem Solving、在线竞赛训练教材以及评分至少为六级的 DeepMath 问题。科学推理数据取自 NaturalReasoning,指令遵循与编程数据则来自 Nemotron-Instruction-Following-Chat-v1、Eurus-2-RL-Data 与 OpenCodeReasoning-2。强化学习池额外引入了 OPC,这是一份经过人工评估的高级数学证明语料库。
-
各子集关键细节: 监督微调数据集包含 33.8 万条过滤后的轨迹,划分为直接生成组(数学、STEM、编程与指令遵循)与自我提升组(自我验证与自我优化)。针对数学子集,研究团队生成额外的验证与优化轨迹,用于教导模型如何校验证明并修复逻辑漏洞。强化学习数据集由 25,254 条提示词构成,划分为 8,967 条可验证样本与 16,287 条不可验证样本,专门针对面向证明或开放式的推理任务进行定制。
-
数据使用方式: 研究团队在直接解决方案与自我修正行为上共同训练监督微调模型,以构建严谨的推理能力。强化学习池被划分为可验证与不可验证两部分,以引导不同的优化目标。可验证集合支持基于答案校验的优化,而不可验证集合则利用生成奖励等较柔和的评判信号对模型进行训练,以应对复杂证明任务。
-
处理与裁剪策略: 训练前,团队从两个数据池中剔除受污染的问题,并对剩余提示词进行去重。研究团队使用 DeepSeek-V3.2-Speciale 为 SFT 数据生成推理轨迹,随后丢弃噪声输出。为保持监督信号聚焦并防止训练不稳定,研究团队将任何超过 8,192 token 的轨迹进行裁剪或直接移除。针对强化学习池,团队采用拒绝采样过滤掉对当前策略而言过易或过难的样本,并移除格式不佳或不可靠的提示词。
方法
SU-01 模型采用模块化训练流水线,旨在将具备广泛能力的后训练语言模型转化为用于严谨数学与科学推理的高性能系统。整体框架依次经过四个独立阶段:监督微调(SFT)、粗粒度强化学习(RL)、精细强化学习(RL)以及测试时扩展(TTS)。每个阶段针对推理能力的特定方面进行优化,并以前一阶段为基础,最终在奥林匹克级别问题上实现专家级表现。
第一阶段 SFT 旨在为模型灌输规范的证明搜索模式。该阶段以经过后训练的模型 P1-30B-A3B 为起点,该模型已具备较强的科学推理能力,但缺乏结构化处理长篇幅证明的方法。SFT 过程混合使用了来自数学、科学、编程及指令遵循等多个来源的长篇幅解决方案、自我验证与自我优化轨迹。训练数据按逆困惑度排序,即首先呈现与初始模型策略偏差最大的样本。该课程安排帮助模型适应新的推理风格,同时保留其既有能力,有效避免了长链推理(Long-CoT)训练中常见的性能退化现象。
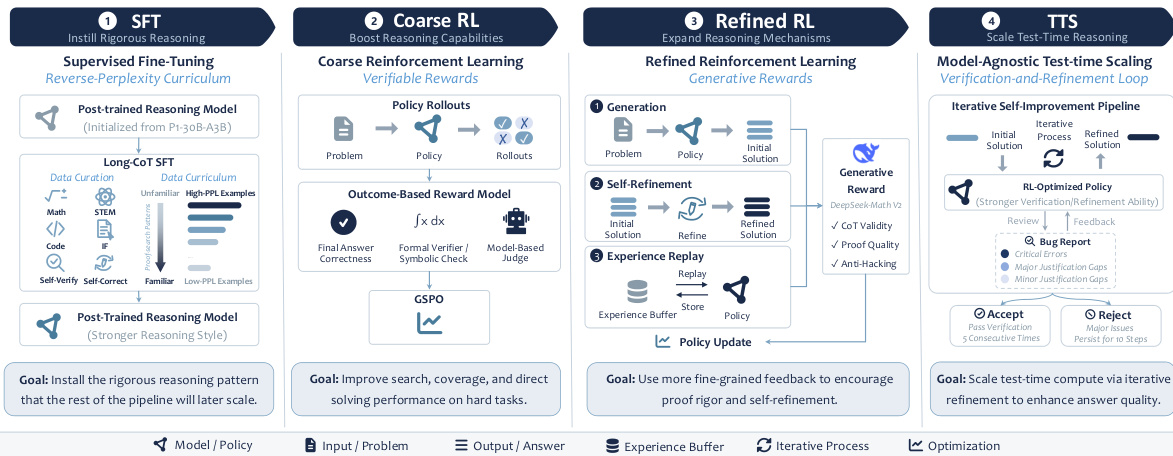
第二阶段粗粒度 RL 通过提升模型在难题中寻找正确答案的能力,来扩展其推理行为。该阶段遵循可验证奖励强化学习(RLVR)范式,利用可验证提示词与高效的结果检查机制提供可靠的二元奖励。策略更新采用组序列策略优化(GSPO),该算法作用于完整响应级别,非常契合结果奖励训练。奖励系统采用分层架构:首先应用规范化文本匹配,其次使用基于规则的数学表达式求值器(Math-Verify),最后对未决案例调用生成式模型(gpt-oss-120b),从而确保奖励信号保守且高精度。
第三阶段精细 RL 使策略专注于生成完整且可审计的证明。优化目标从单纯的正确答案转向证明质量。该阶段通过评分完整推理路径的生成式奖励模型(DeepSeekMath-V2)实现这一目标。为鼓励自我优化,流水线集成了自我优化机制,将失败的解决方案转换为提示词,用于批判与修复论证过程。此外,经验回放缓冲区存储罕见的成功证明轨迹,确保策略即使在样本稀少的情况下也能从高价值示例中学习。回放机制具有针对性,通过控制比例并选择熵值最低的轨迹,以保障训练的稳定与安全。
最终阶段 TTS 利用测试时算力提升模型性能。该阶段应用自我验证与优化循环,模型首先生成初始解决方案,检查其中的逻辑错误与漏洞,并基于结构化错误报告进行迭代优化。该过程使模型能够在长轨迹(超过 100K token)上维持连贯推理,并将额外的推理算力有效分配至最具挑战性的问题,从而将解题能力扩展至单次推理无法达到的水平。
实验
评估框架在可验证答案任务、不可验证的证明导向挑战以及官方奥林匹克竞赛中全面测试模型,以验证训练流水线是否成功将推理模式从浅层的答案检索转向严谨的自我修正证明构建。实验表明,分阶段的后训练逐步提升了证明可靠性,并使模型在仅使用数学与物理信号训练的情况下,依然能够实现稳健的跨学科 STEM 迁移。定性分析进一步揭示,测试时扩展有效将推理算力分配至验证与迭代优化环节,使模型能够修复复杂论证并达到顶尖竞赛水平。最终结果证实,精简统一的训练方案能够在不依赖海量算力或多领域监督的前提下,从紧凑架构中激发出人类水平的奥林匹克推理能力。
研究团队分析了模型在不同训练阶段的推理演进过程,重点关注其生成严谨证明与恢复正确答案的能力。随着训练推进,模型在处理不可验证证明任务方面表现显著提升,尤其在高级问题上。结果表明,模型在复杂推理任务上的性能得益于自我验证与优化机制的双重作用,性能提升主要集中在需要完整证明构建的高难度问题上。在训练过程中,模型生成严谨证明的能力在高级不可验证任务上获得大幅改善。自我验证与优化机制在提升复杂证明导向问题表现方面尤为有效。模型在未训练领域展现出强大的迁移能力,表明其具备超越训练信号的通用科学推理能力。

研究团队分析了模型性能在各训练阶段的演进情况,显示其在可验证与不可验证推理任务上均取得进步。随着训练从初始监督微调转向配备精细奖励的强化学习及测试时扩展,模型在证明导向基准测试中展现出强劲提升,尤其在高级问题上。结果表明,该训练方案增强了严谨推理与自我修正能力,最终模型在竞赛风格问题上达到顶级表现。模型在不可验证证明任务上的性能随每个训练阶段显著提升,高级问题上的进步尤为明显。测试时扩展大幅增强了模型生成正确证明的能力,在基础与高级证明基准上效果显著。训练流水线成功引导模型从答案检索过渡至严谨证明构建与自我优化。
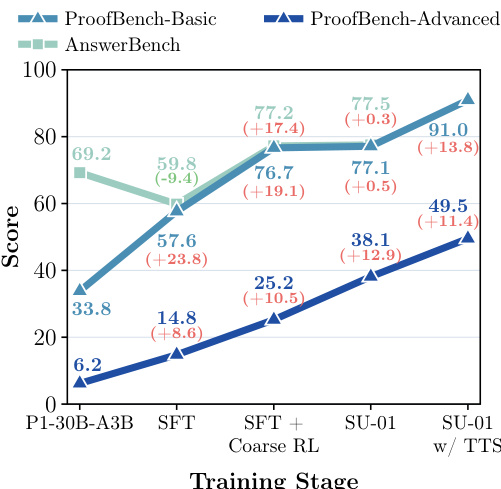
研究团队评估了模型在不可验证推理任务上的表现,重点聚焦证明导向基准。结果表明,模型在基于证明的评估中取得优异成绩,且在测试时扩展后获得显著提升。在同等规模模型中,该模型性能具备强竞争力。尽管主要基于数学与物理信号进行训练,其推理行为仍展现出跨领域的迁移性。模型在不可验证证明基准上表现强劲,测试时扩展大幅优化了其结果。尽管仅接受数学与物理训练,模型仍展现出可迁移至化学与生物学等未训练科学领域的推理能力。分阶段训练有效改善了模型的推理行为,其中优化与自我验证机制在提升证明质量方面发挥关键作用。
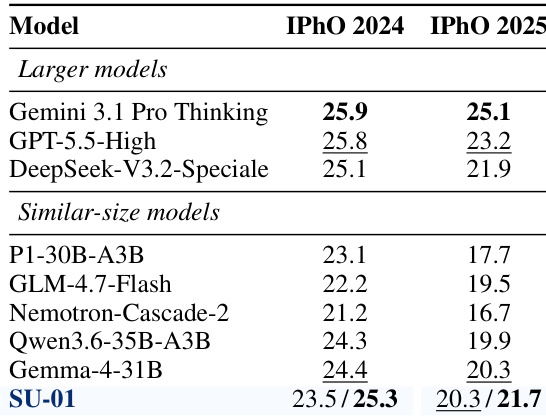
研究团队评估了 SU-01 在物理奥林匹克竞赛问题上的表现,并将其与更大规模及同规模模型进行对比。结果显示,SU-01 在 IPhO 2024 与 2025 中均取得优异分数,连续两年突破金牌阈值,并超越其他同规模模型。测试时扩展使模型性能显著提升,表明其具备有效的自我优化能力。SU-01 在 IPhO 2024 与 2025 中均超越金牌标准,展现出强大的奥林匹克级别推理能力。在两项赛事中,SU-01 均优于其他同规模模型,凸显其高效性与实力。测试时扩展大幅拉升 SU-01 的性能,印证了其稳健的自我优化行为。
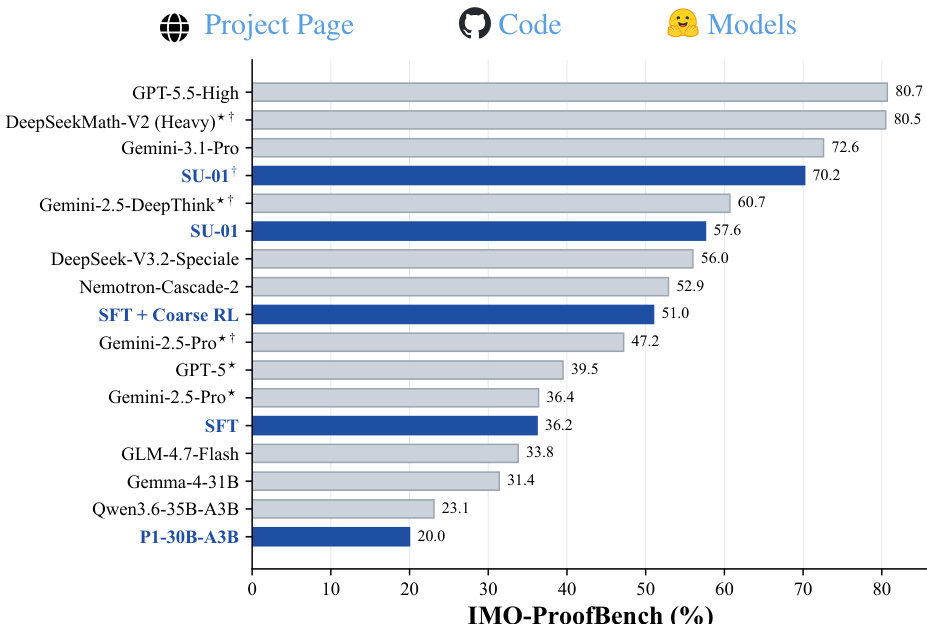
研究团队展示了数学奥林匹克竞赛问题的实验结果,表明该模型在 IMO 2025 与 USAMO 2026 中均达到顶级表现,两项赛事成绩均触及金牌阈值。结果表明,测试时扩展显著提升了性能,使模型能够解决单次推理无法攻克的难题。模型展现出强劲的推理能力,尤其在将问题转化为形式化框架方面表现突出,但在部分复杂问题上仍存在失效模式。模型在 IMO 2025 与 USAMO 2026 中均获得金牌水平分数,达到或超越官方金牌标准。测试时扩展使模型成功解决单次推理失败的题目,整体性能大幅改善。模型展现出卓越的推理能力,特别是在利用数学框架形式化问题方面,但在某些复杂题型上仍存在局限。
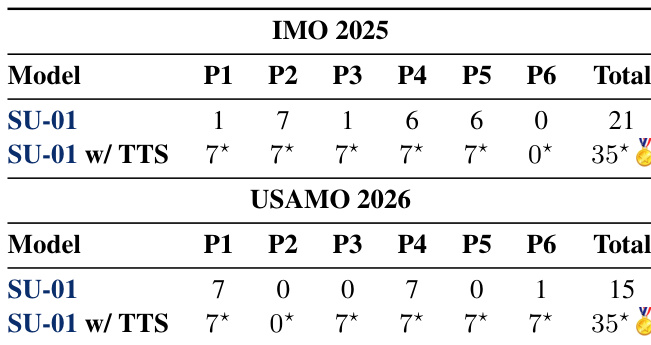
实验在分阶段训练周期与多样化基准上对模型进行全面评估,涵盖数学与物理奥林匹克问题、不可验证证明任务以及未训练科学领域。评估结果验证了渐进式训练流水线结合测试时扩展与自我优化机制,能够大幅增强严谨证明构建与自我修正能力。模型在主要赛事中持续保持金牌水平表现,并展现出强劲的跨领域迁移能力,尽管在部分高度复杂的推理任务上仍面临局限。