Command Palette
Search for a command to run...
因果强制++:用于实时交互式视频生成的可扩展少步自回归扩散蒸馏
因果强制++:用于实时交互式视频生成的可扩展少步自回归扩散蒸馏
Min Zhao Hongzhou Zhu Kaiwen Zheng Zihan Zhou Bokai Yan Xinyuan Li Xiao Yang Chongxuan Li Jun Zhu
摘要
实时交互式视频生成需要低延迟、流式传输以及可控的 rollout。现有的自回归(AR)扩散蒸馏方法通过将双向基础模型蒸馏为少步 AR 学生模型,在分块(chunk-wise)4 步模式下取得了显著成果,但其仍受限于粗糙的响应粒度和不可忽略的采样延迟。在本文中,我们研究了一种更为激进的设置:仅使用 1--2 个采样步的帧级自回归。在此模式下,我们确定少步 AR 学生模型的初始化是关键瓶颈:现有策略要么与目标不对齐,无法实现少步生成,要么扩展成本过高。我们提出了 Causal Forcing++,这是一种原则性强且可扩展的流水线,利用因果一致性蒸馏(causal CD)进行少步 AR 初始化。其核心思想是,因果 CD 学习与因果 ODE 蒸馏相同的 AR 条件流映射,但通过在相邻时间步之间使用单个在线教师 ODE 步获取监督信号,从而避免了预计算和存储完整 PF-ODE 轨迹的需求。这使得初始化过程更加高效且易于优化。由此产生的流水线(即我们的方法)在帧级 2 步设置下,超越了 SOTA 分块式 Causal Forcing 方法,在 VBench Total 上提升 0.1,在 VBench Quality 上提升 0.3,在 VisionReward 上提升 0.335,同时将首帧延迟降低 50%,并将第二阶段训练成本降低约 4 倍。受 Genie3 的启发,我们进一步将该流水线扩展至动作条件世界模型生成。项目页面:https://github.com/thu-ml/Causal-Forcing 和 https://github.com/shengshu-ai/minWM 。
一句话总结
Causal Forcing++ 通过在相邻时间步之间采用单次在线教师 ODE 步长,利用因果一致性蒸馏初始化少步长学生模型,从而实现仅用一到两个采样步长的逐帧自回归合成,支持实时交互式视频生成。该方法在消除完整轨迹存储的同时,在逐帧 2 步长设置下,VBench Total 指标提升 0.1,VBench Quality 指标提升 0.3,性能优于 4 步长分块式 Causal Forcing 基线。
核心贡献
- 本文提出 Causal Forcing++,这是一种仅依赖一到两个采样步长的逐帧自回归视频生成的可扩展初始化流程。该方法利用相邻时间步之间的单次在线教师 ODE 步长作为监督信号,学习自回归条件流映射,从而无需预计算和存储完整的多步轨迹。
- 在 Wan2.1-1.3B 模型上的评估表明,该方法在逐帧 2 步长设置下优于以往的分块式方法,提升了 VBench Total 和 Quality 分数,同时将首帧延迟降低 50%。该流程还将第二阶段训练成本降低约 4 倍,并在 1、2 和 4 步长配置中保持一致的性能。
- 该框架通过将相机位姿条件生成器蒸馏为自回归模型,扩展至交互式世界模型生成,展现出与动作条件视频展开的直接兼容性。
引言
实时交互式视频生成要求低延迟、流式输出并能即时响应用户输入,这使得自回归扩散模型成为序列帧合成的极具吸引力的架构。然而,以往的蒸馏方法通常依赖四个采样步长的分块式生成,为交互式应用引入了不可接受的延迟和粗糙的粒度。尝试将这些模型推向仅含一到两个步长的逐帧生成会暴露出关键的初始化瓶颈,因为现有策略要么泄露未来帧信息,要么在自展开过程中遭受严重的近似误差,或要求计算成本高昂的离线轨迹存储。为解决这一问题,作者利用因果一致性蒸馏来高效初始化少步长自回归学生模型。通过在相邻时间步之间通过单次在线教师步长学习条件流映射,该流程消除了昂贵的预计算轨迹,同时在逐帧两步长模式下实现最先进的视频质量,将首帧延迟减半,并将训练成本降低约四倍。
方法
作者利用自回归扩散模型实现低延迟的交互式视频生成,以解决传统双向扩散模型单次生成完整视频的限制。该方法在更小的生成单元(通常为帧或分块)上运行,允许在生成过程中进行增量输出和用户反馈。该框架将扩散建模与自回归推理相结合,其中每一帧均基于先前生成的帧进行条件生成,并在自展开过程中借助因果注意力机制和键值(KV)缓存实现。
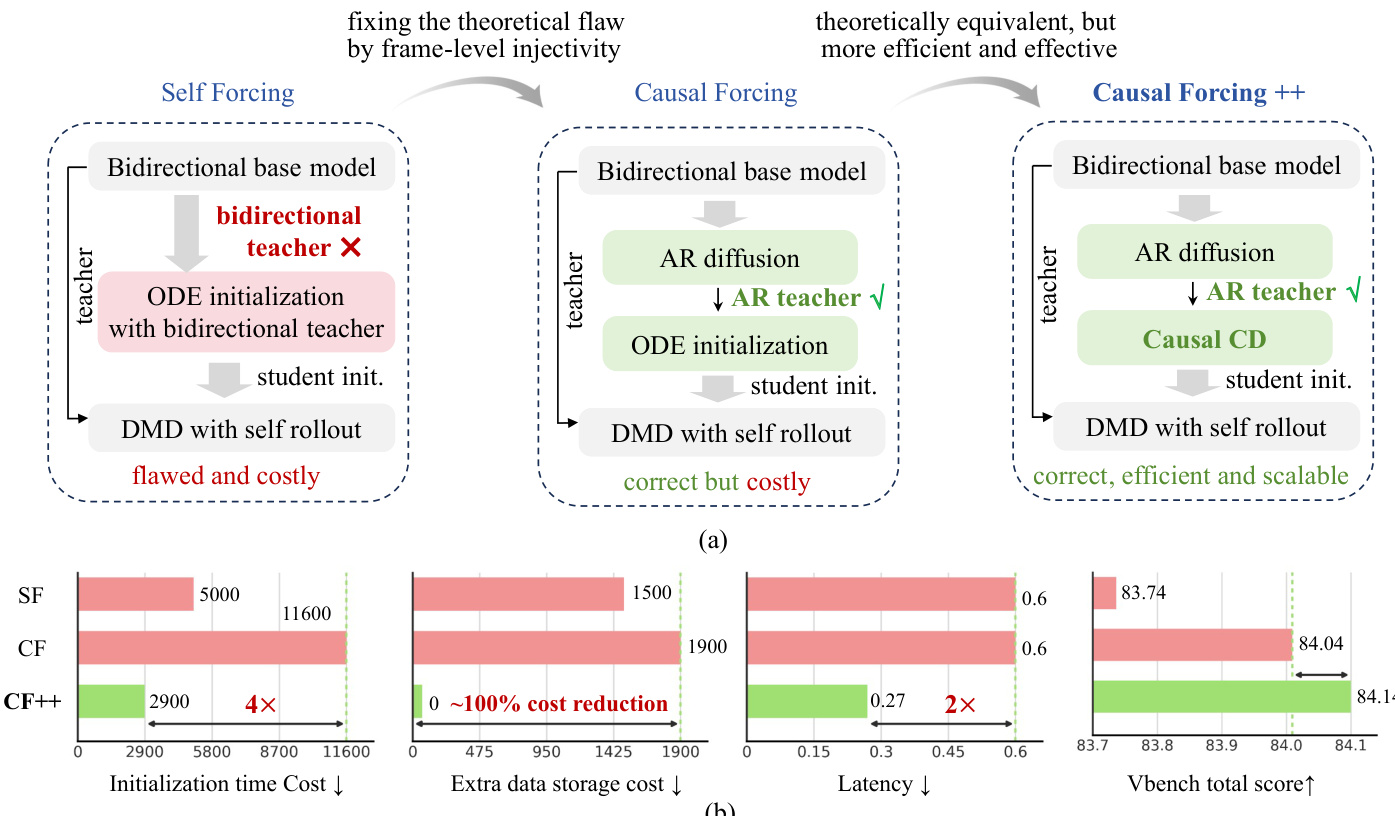
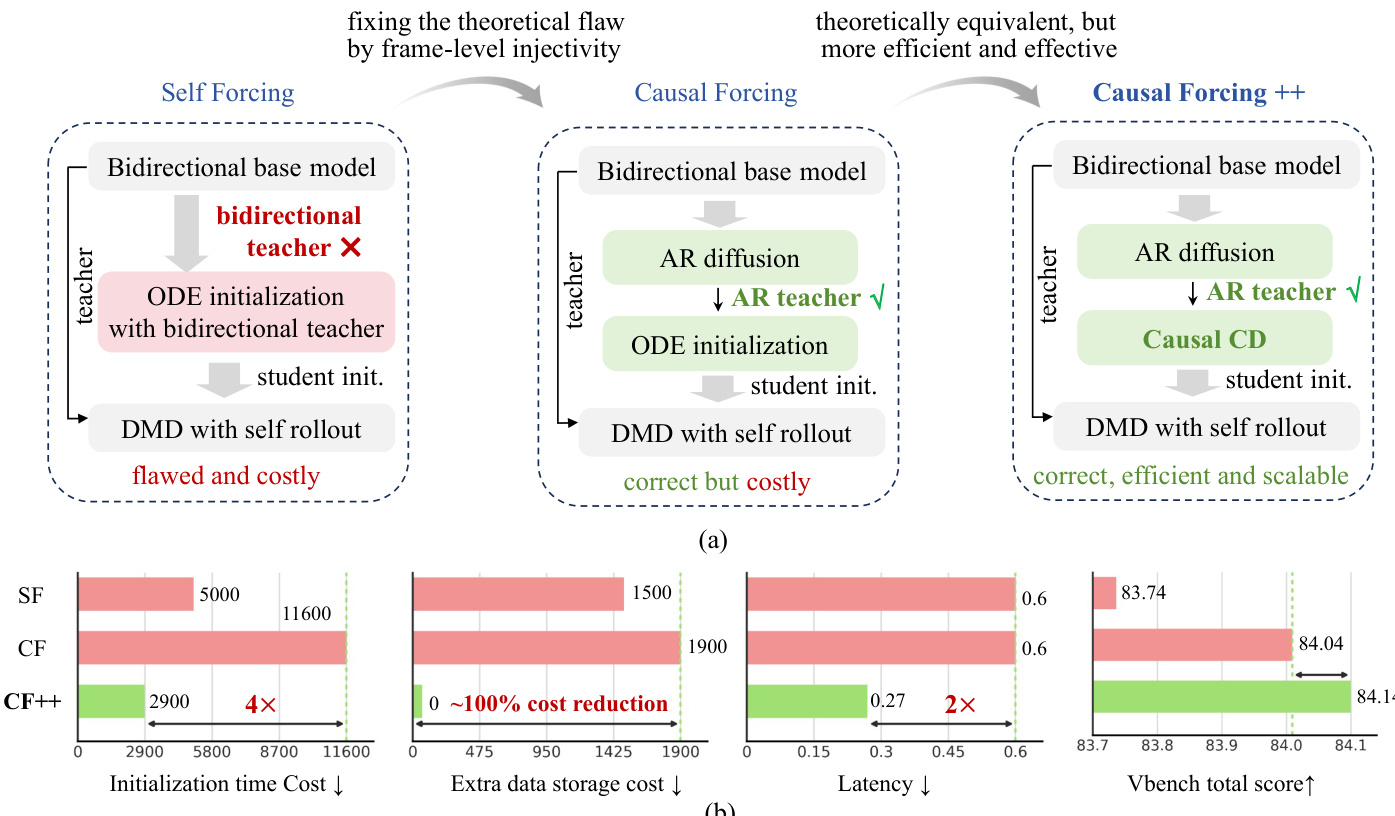
该方法建立在现有的自回归扩散蒸馏流程之上,通常包含三个阶段:(1) 通过教师强制进行的多步自回归扩散训练;(2) 使用自回归教师的因果 ODE 初始化;(3) 结合学生自展开的非对称扩散匹配蒸馏 (DMD)。然而,作者指出,在激进的低延迟场景(具体为仅含一到两个采样步长的逐帧生成)中,现有初始化策略存在关键缺陷。研究发现,使用双向教师进行 ODE 初始化因违反帧级单射性而在架构上不匹配,导致输出模糊且对齐不佳。直接复用多步 AR 扩散模型作为初始化缺乏少步长能力,导致在自展开时性能下降。尽管使用 AR 教师的因果 ODE 初始化在理论上合理,但由于需要为每个训练样本生成并存储完整的多步轨迹,其计算成本极高,造成了显著的扩展瓶颈。
为应对这些挑战,作者提出 Causal Forcing++ 作为一种原则性且可扩展的替代方案。核心创新在于使用一种名为因果一致性蒸馏(Causal CD)的新型初始化机制,替代昂贵的 ODE 轨迹生成。该方法确保初始化既兼容自回归又高效,避免了对大量数据人工筛选的需求,同时保持理论正确性。如下图所示的整体框架展示了从 Self Forcing 到 Causal Forcing 再到 Causal Forcing++ 的演进过程,突出了效率、可扩展性和性能的提升。
该方法进一步扩展至动作条件世界模型生成,模型以相机位姿为条件以模拟相机运动与交互。该过程首先构建带有相机位姿标注的数据集,使用位姿条件微调双向扩散模型,随后利用 Causal Forcing++ 流程将其蒸馏为交互式动作条件模型。该框架能够根据用户指定的动作生成逼真的动态场景,展现出其在实时交互式系统中的适用性。

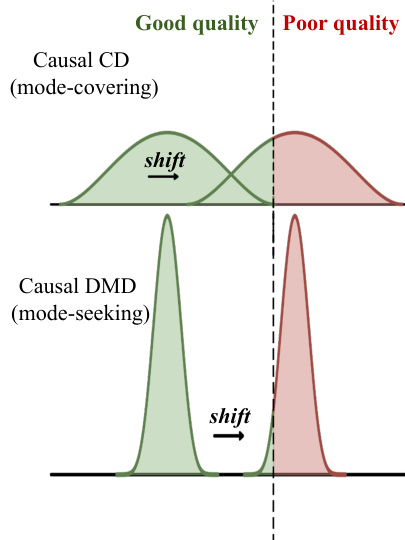
该方法的一个关键在于区分蒸馏过程中的模式覆盖(mode-covering)与模式搜索(mode-seeking)行为。如下所示,传统的因果 DMD 倾向于产生模式搜索分布,这可能导致因过拟合特定模式而质量下降。相比之下,因果一致性蒸馏促进模式覆盖,从而产生更多样化且高质量的输出。
通过定性比较展示了所提方法的有效性。与以往方法相比,Causal Forcing++ 在逐帧 1 步长和 4 步长设置下均取得更优结果。该框架通过降低延迟并保持高生成质量实现实时交互,适用于需要快速用户反馈和动态内容生成的应用。

实验
实验在单张 GPU 上评估了逐帧自回归视频生成流程,结合标准视觉质量与指令遵循基准,以及延迟和吞吐量测量。与以往蒸馏方法的对比表明,所提方法显著降低了生成延迟并提升了吞吐量,同时保持或增强了视觉保真度、运动动态和语义一致性。消融实验进一步验证了鲁棒少步长初始化的必要性,结果显示传统 ODE 和直接 AR 扩散策略效果较差,而引入的因果 CD 初始化大幅降低了计算与存储成本,并在所有步长设置下优于其他替代方案。最终,研究结果证实,使用因果 CD 替代因果 ODE 能够实现高效、高质量的视频合成,具备更优的动态行为和伪影抑制能力。
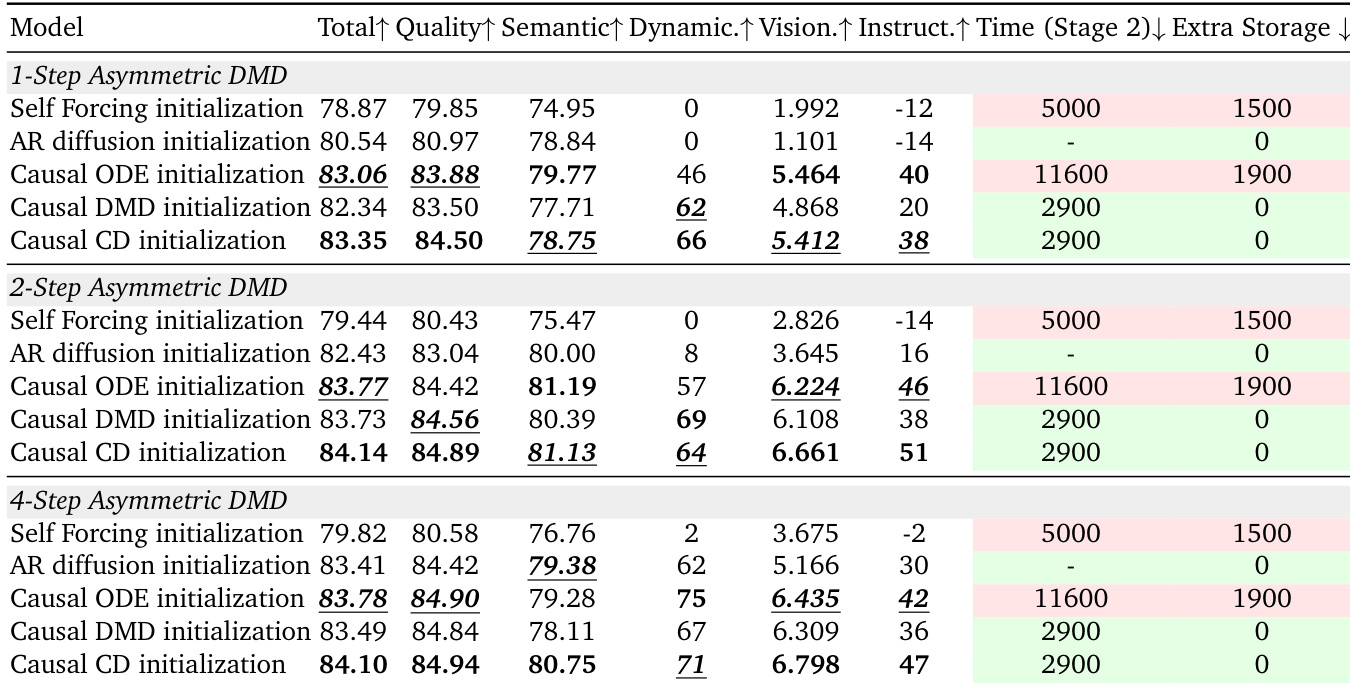
作者评估了不对称 DMD 在 1 步长、2 步长和 4 步长设置下的不同初始化方法,比较了它们对生成质量、动态和效率的影响。结果表明,因果 CD 初始化实现了最佳的整体性能,在质量和动态方面超越其他方法,同时相比因果 ODE 显著降低了计算和存储成本。因果 CD 初始化在所有步长设置下均取得最高的质量和动态表现,同时相比因果 ODE 缩短了训练时间并降低了存储需求。在所有指标和设置中,因果 CD 均优于因果 ODE 初始化,后者具有显著更高的计算和存储成本。AR 扩散初始化在低步长设置下表现不佳,尤其在动态和指令遵循方面,表明需要显式的少步长适配。
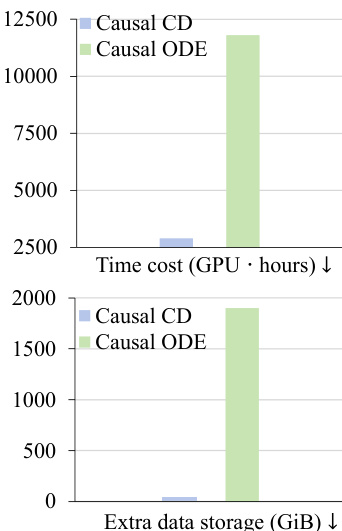
作者比较了少步长视频生成的不同初始化方法,重点关注其效率与性能。结果表明,Causal CD 在时间成本和存储需求方面均优于 Causal ODE,同时实现了相当或更优的生成质量。与 Causal ODE 相比,Causal CD 显著降低了时间成本。Causal CD 消除了 Causal ODE 所需的额外存储。Causal CD 以更低计算开销实现了与 Causal ODE 相当或更优的性能。
作者将 Causal Forcing++ 视为 Causal Forcing 的改进版本,重点通过一种名为 Causal CD 的新少步长初始化方法提升效率与性能。结果表明,与以往方法相比,Causal Forcing++ 实现了更高的生成质量和更好的效率,其中 Causal CD 显著缩短了初始化时间并降低了存储需求,同时保持或提升了性能。与以往方法相比,Causal Forcing++ 实现了更高的生成质量和更好的效率。Causal CD 初始化在保持或提升性能的同时,缩短了初始化时间并降低了存储成本。Causal Forcing++ 在质量和效率指标上均优于 Causal Forcing 及其他基线。
作者从生成质量、效率和动态表现方面,将所提方法 Causal Forcing++ 与现有方法进行了对比。结果表明,Causal Forcing++ 在所有指标上均取得更优或相当的性能,同时显著降低了延迟并提升了吞吐量,尤其在 2 步长和 4 步长设置下。消融实验进一步证明,因果 CD 初始化在质量和效率上均优于其他方法,尤其在低步长生成场景中。与以往方法相比,Causal Forcing++ 在保持或提升生成质量的同时实现了更高的吞吐量和更低的延迟。采用 2 步长和 4 步长生成的 Causal Forcing++ 在总分、质量和动态程度方面超越了以往的最先进方法。因果 CD 初始化在质量和效率上始终优于其他初始化方法,尤其在低步长设置下表现突出。
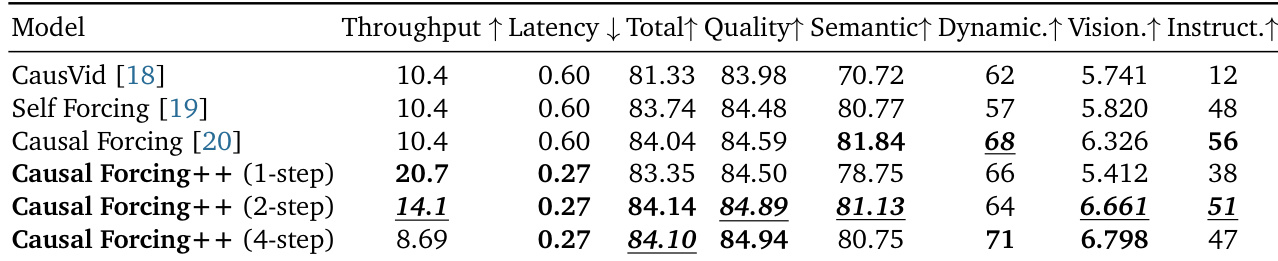
实验评估了少步长视频生成在一步、两步和四步设置下的不同初始化策略,验证了其对输出质量、时间动态和计算效率的影响。结果一致表明,所提出的因果 CD 初始化优于因果 ODE 和 AR 扩散基线,在提供更高生成质量和更平滑动态的同时,大幅缩短了训练时间并降低了存储需求。在替代方法难以克服性能下降的低步长配置中,这一优势尤为明显。最终,研究结果证实,将 Causal CD 整合至 Causal Forcing++ 框架中,为快速视频合成确立了高效且有效的标准。