Command Palette
Search for a command to run...
自蒸馏式 Agent 强化学习
自蒸馏式 Agent 强化学习
摘要
强化学习(RL)已成为大语言模型(LLM)智能体后训练的核心范式,然而其轨迹级奖励信号为长时程交互提供的监督较为粗糙。策略内自蒸馏(On-Policy Self-Distillation, OPSD)通过引入由特权上下文增强的教师分支提供的密集 token 级指导,对 RL 进行了补充。然而,将 OPSD 迁移至多轮智能体时面临诸多问题:多轮不稳定性会加剧,导致监督信号失稳;而技能条件化的特权指导需要非对称处理,因为负面的教师拒绝可能源于技能检索或利用的不完美。我们提出了 SDAR(自蒸馏智能体强化学习,Self-Distilled Agentic Reinforcement Learning),将 OPSD 视为门控辅助目标,同时保持 RL 作为主要的优化骨干。SDAR 将解耦的 token 级信号映射为 Sigmoid 门控,在教师认可的具有正向差距的 token 上增强蒸馏,并柔和地衰减负面的教师拒绝。在 ALFWorld、WebShop 和 Search-QA 数据集上,针对 Qwen2.5 和 Qwen3 系列模型,SDAR 显著优于 GRPO(在 ALFWorld 上提升 9.4%,在 Search-QA 上提升 7.0%,在 WebShop-Acc 上提升 10.2%),避免了朴素 GRPO+OPSD 的不稳定性,并在不同模型规模下持续优于混合 RL--OPSD 基线方法。
一句话总结
SDAR(Self-Distilled Agentic Reinforcement Learning)通过将在线自我蒸馏(On-Policy Self-Distillation)作为门控辅助目标,将 token 级信号映射至 sigmoid 门控,从而稳定多轮 LLM agent 的训练。该方法强化正向 token 引导并减弱负向拒绝信号,使 Qwen2.5 与 Qwen3 系列在 ALFWorld、WebShop 和 Search-QA 任务上显著优于 GRPO,同时避免了朴素 GRPO+OPSD 带来的训练不稳定性。
核心贡献
- SDAR 提出了一种自我蒸馏强化学习框架,将在线自我蒸馏作为门控辅助目标,以稳定多轮策略优化。
- 该方法将解耦的 token 级信号通过 sigmoid 门控进行映射,选择性放大教师模型认可的正向 gap token 的蒸馏效果,同时温和地衰减因技能检索不完善而产生的负向教师拒绝信号。
- 在 Qwen2.5 与 Qwen3 系列上针对 ALFWorld、WebShop 和 Search-QA 的评估表明,该方法相比 GRPO 及混合 RL-OPSD 基线实现了稳定提升,准确率最高提升 10.2%,且未出现朴素蒸馏方法常见的训练不稳定性。
引言
将大语言模型在训练后作为自主 agent 用于多轮交互,高度依赖强化学习,然而轨迹级奖励仅为复杂的序列决策提供了粗粒度的监督。先前通过在线自我蒸馏注入密集 token 级引导的尝试在多轮设置中失败,因为累积的不稳定性会导致训练失稳,且当负向反馈源于不完善的技能检索时,特权教师信号会引发不对称的信任问题。为解决该问题,作者提出 SDAR,将自我蒸馏作为门控辅助目标,同时保持强化学习作为主要优化骨干。通过将 token 级的师生差距映射至 sigmoid 门控,该方法放大了对认可步骤的学习,并温和地衰减负向拒绝信号,从而在标准 agent 基准测试中实现稳定的训练与显著的性能提升。
方法
提出的 SDAR 方法将在线自我蒸馏(OPSD)作为精心控制的辅助目标,整合至用于训练多轮语言 agent 的验证器驱动强化学习框架中。整体架构如框架图所示,包含两个主要部分:基于 GRPO 的强化学习骨干与并行运行的 OPSD 模块。GRPO 组件利用源自环境奖励的任务结果信号优化学生策略,计算序列级优势并应用标准策略优化技术。相比之下,OPSD 组件利用依赖特权训练上下文(如检索到的技能)的自我教师机制,提供 token 级引导。该引导并非均匀应用,而是通过 token 级门控机制进行选择性调节,确保仅在信号可靠且有益时注入蒸馏信号。
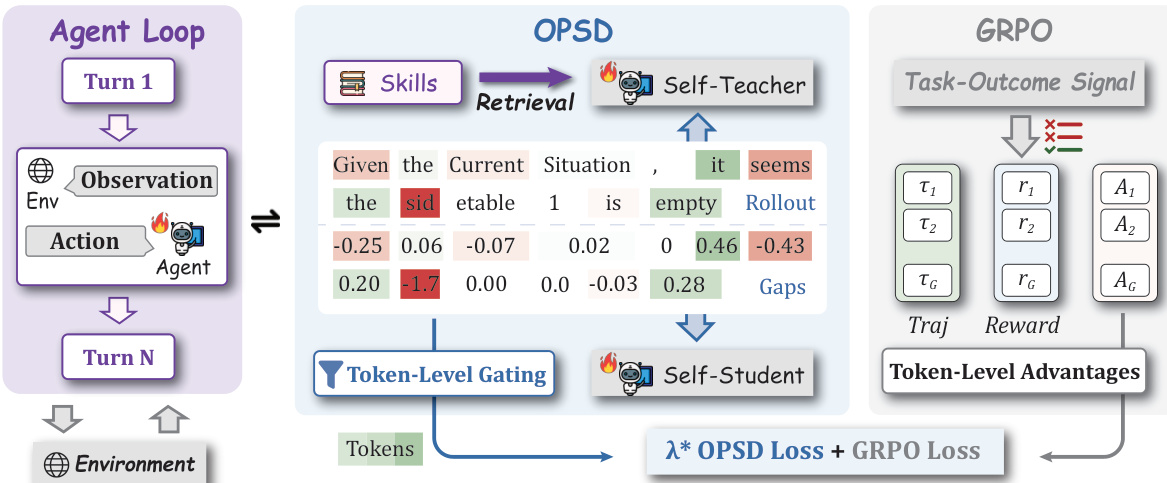
OPSD 模块的核心是 token 级损失,该损失源自学生模型与自我教师模型在每个位置 t 的条件 token 分布之间的反向 KL 散度。为避免全词表求和的计算开销,采用单样本估计,得到师生对数概率差距 Δt=logπT(yt∣st+)−logπθ(yt∣st),作为衡量两个模型差异的直接指标。该原始差距随后通过 sigmoid 函数处理,生成有界门控 gt=σ(βΔt),作为置信度权重。该变换确保梯度更新平滑且有界,防止因不可控的高方差更新引发的不稳定性,这在训练初期或师生模型严重不匹配时尤为关键。该门控与梯度断开连接,仅作为纯置信度权重,避免引入可能导致不稳定的自引用优化路径。最终的 token 级损失为该门控与差距的乘积,整体 OPSD 目标函数通过对轨迹中所有有效 token 的损失求平均得到。
该框架引入自适应平滑门控机制,以解决特权引导的不对称信任问题及多轮 OPSD 的不稳定性。实例化了三种不同的门控策略:熵门控,针对学生模型最不确定的位置;gap 门控,为教师模型认可的正向 gap token 分配较大权重,同时衰减负向 gap token;以及软 OR 门控,将学生不确定性与师生差距结合,作为替代策略。该设计允许在尽可能细的粒度(即单个 token 级别)上运行动态、自进度的课程学习,每个 token 均可自主决定其监督强度。整体训练目标为标准 GRPO 损失与 SDAR 损失的加权和,确保验证器驱动的 RL 策略损失保持不变,从而保留 RL 优势函数的语义与无偏性。
实验
实验在家庭任务规划、搜索增强问答及基于网页的购物基准上进行评估,将 SDAR 与免训练、后训练及混合基线进行对比,以评估其协调强化学习与特权知识蒸馏的能力。主要结果验证了该方法成功内化了外部技能,而非在推理阶段依赖它们,相较于朴素混合方法展现出更优的泛化能力与稳定性。训练动态与鲁棒性测试进一步证实,自适应门控机制在优化过程中自主过滤了负向教师信号,在不同技能检索质量下均保持了稳定的性能提升。最后,消融实验验证了 token 级差距门控与反向 KL 目标对于在不破坏核心强化学习过程的前提下选择性增强有益引导至关重要。
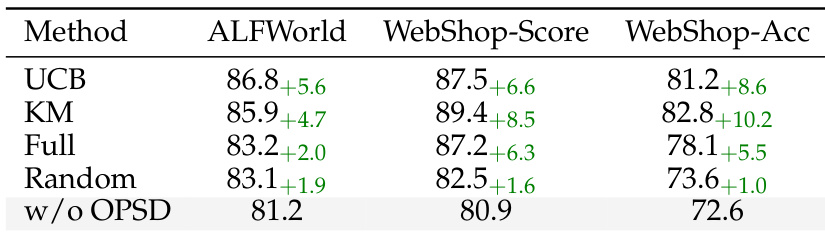
作者在不同技能检索策略下评估了方法的鲁棒性,结果表明所有检索方法均稳定优于无特权知识蒸馏的基线。即使检索质量较低,该方法仍能取得性能提升,且随着检索质量提高,性能进一步改善,这表明收益主要源于门控机制而非单纯的检索保真度。所有技能检索方法均稳定优于无特权知识蒸馏的基线。性能提升幅度随检索质量增加而扩大,但在低质量检索下仍保持增益。该方法的有效性归因于其门控机制,而非检索技能的质量。
作者在不同训练配置下将 SDAR 与多种基线方法进行了对比,重点考察了 GRPO、Skill-GRPO、OPSD、Skill-SD 及 RLSD 等方法的超参数设置。表格显示,SDAR 采用的学习率与分组大小与其他方法相似,但引入了基线中未包含的蒸馏系数与门控锐度参数,表明其优化设置更为复杂。所有方法均采用相同的技能检索策略,体现出一致的技能整合思路。SDAR 独有的蒸馏系数与门控锐度参数进一步区分了其与基线方法。各方法共享相同的学习率与分组大小,确保训练设置的一致性。统一的技能检索策略在所有方法中保持一致,强调了技能整合的标准化流程。
作者在多个模型尺寸下于 ALFWorld、Search-QA 和 WebShop 三个基准上评估了 SDAR,展现出相对于基线的稳定性能提升。结果表明,SDAR 在大多数设置下取得最佳或次佳成绩,增益稳定且泛化能力强,尤其在较小模型上表现突出。该方法成功内化了特权知识,推理阶段无需依赖外部技能,其自适应门控机制通过选择性引入教师引导实现了稳健的训练动态。SDAR 在所有基准与模型尺寸上均取得最佳或次佳性能,超越纯强化学习与混合基线。该方法有效内化特权知识,即便在推理阶段不使用外部技能,仍优于技能增强型基线。通过选择性融合教师引导的门控机制,SDAR 展现出稳健的训练动态,确保优化过程稳定。
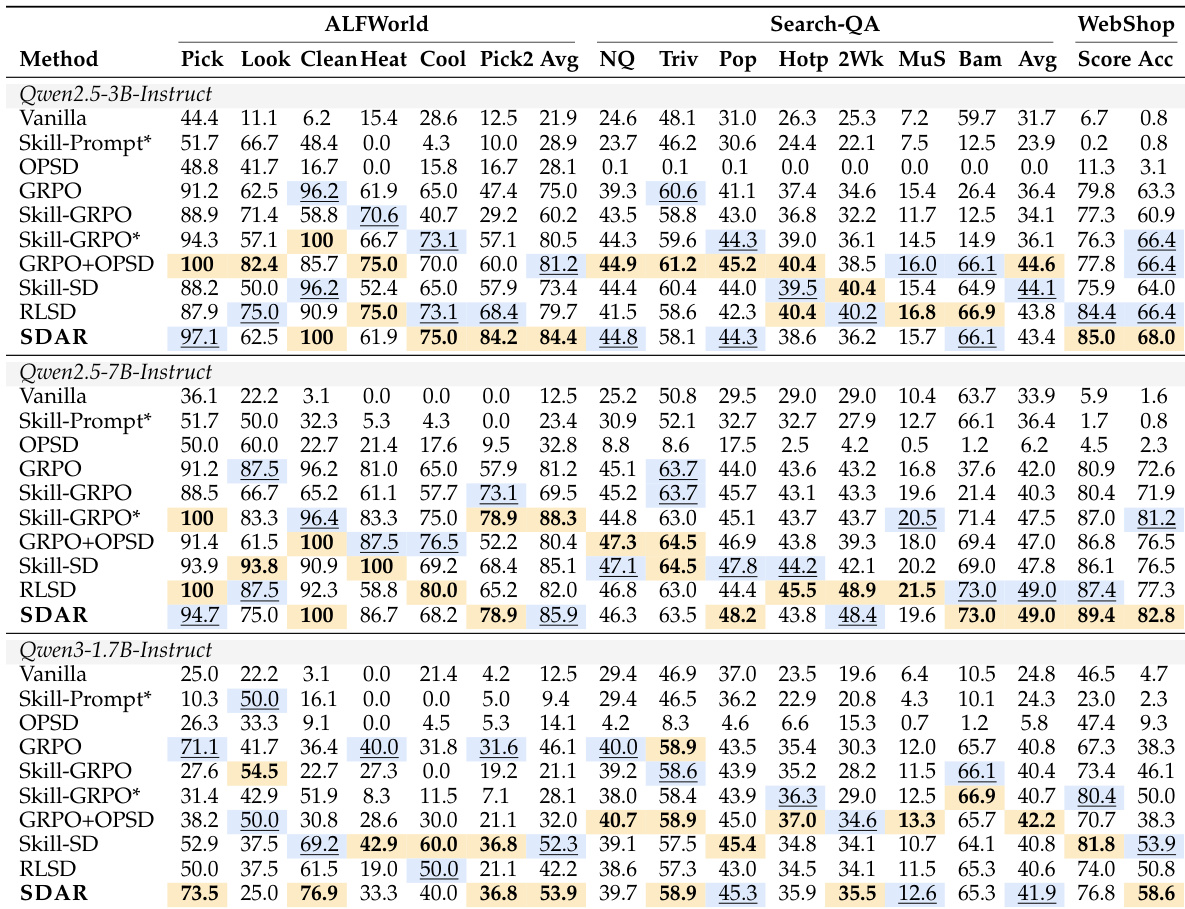
作者在三个基准与多个模型尺寸下评估了 SDAR,在统一训练配置下将其与标准强化学习及混合基线进行对比。一项实验验证了该方法对技能检索质量的鲁棒性,表明即使检索技能非最优,性能提升依然持续。另一项评估确认该方法始终匹配或超越基线结果,同时成功内化特权知识且推理阶段无需外部技能。综合来看,这些发现表明自适应门控机制有效平衡了教师引导与学生优化,使模型能够在多样化任务中保持稳定的训练动态与强大的泛化能力。