Command Palette
Search for a command to run...
SANA-WM:基于混合线性扩散Transformer的高效分钟级世界模型
SANA-WM:基于混合线性扩散Transformer的高效分钟级世界模型
Haoyi Zhu Haozhe Liu Yuyang Zhao Tian Ye Junsong Chen Jincheng Yu Tong He Song Han Enze Xie
摘要
标题:摘要:我们介绍了 SANA-WM,这是一个高效的 2.6B 参数开源 world model,原生支持一分钟视频生成,能够合成高保真、720p 分辨率、分钟级时长的视频,并具备精确的相机控制能力。SANA-WM 在视觉质量上可与 LingBot-World 和 HY-WorldPlay 等大型工业基线模型相媲美,同时显著提升了效率。我们的架构由四项核心设计驱动:(1)混合线性注意力(Hybrid Linear Attention)将逐帧门控 DeltaNet(GDN)与 softmax 注意力相结合,以实现内存高效的长上下文建模;(2)双分支相机控制(Dual-Branch Camera Control)确保对 6-DoF 轨迹的精确遵循;(3)两阶段生成流程(Two-Stage Generation Pipeline)对阶段一输出应用长视频精炼器,从而提升序列间的整体质量与一致性;(4)鲁棒的标注流程(Robust Annotation Pipeline)从公开视频中提取精确的度量尺度 6-DoF 相机位姿,以生成高质量、时空一致的动作标签。得益于这些设计,SANA-WM 在数据、训练算力和推理硬件方面均展现出卓越的效率:它仅使用 213K 个带有度量尺度位姿监督的公开视频片段,在 64 块 H100 GPU 上训练 15 天即可完成训练,并在单块 GPU 上生成每个 60 秒的视频片段;其蒸馏变体可通过 NVFP4 量化部署在单块 RTX 5090 GPU 上,在 34 秒内完成一个 60 秒 720p 视频片段的去噪。在我们构建的一分钟 world model 基准测试中,SANA-WM 展现出优于先前开源基线模型的动作跟随精度,并在可扩展的 world modeling 场景中实现了高 36 倍的吞吐量,同时保持相当的视觉质量。
一句话总结
SANA-WM 是一个参数量为 26 亿(2.6B)的开源世界模型。它通过结合门控 DeltaNet(Gated DeltaNet)与 softmax 注意力机制的混合线性注意力机制、双分支相机控制模块以及两阶段优化管线,能够合成高保真、720p 分辨率、时长达分钟的短视频,并严格遵循 6 自由度(6-DoF)轨迹。该模型实现了比工业基线高 36 倍的吞吐量,同时支持在消费级 GPU 上高效部署。
核心贡献
- SANA-WM 是一个参数量为 26 亿的开源世界模型,原生训练用于合成高保真、720p 分辨率、时长达分钟的短视频,并具备精确的相机控制能力。
- 该架构集成了四项核心创新以实现高效的长周期生成:混合线性注意力机制(结合逐帧门控 DeltaNet 与 softmax 注意力,实现内存高效的上下文建模)、双分支相机控制模块(确保严格的 6 自由度轨迹遵循)、两阶段生成管线(应用长视频优化器以增强序列一致性),以及稳健的标注管线(从公开视频中提取度量级相机位姿,生成高质量时空标签)。
- 该模型在仅需 21.3 万条训练片段和 64 张 H100 GPU 上训练 15 天的情况下,达到了与大规模工业基线相当的视频质量。其吞吐量比此前开源方法高出 36 倍,可在单张 GPU 上生成 60 秒视频,并支持蒸馏版本:在 RTX 5090 上使用 NVFP4 量化技术,仅需 34 秒即可处理一段 1 分钟长的 720p 视频。
引言
世界模型正逐渐成为具身仿真与交互式环境中的关键接口,然而,合成具备精确相机控制能力的高保真分钟级视频仍然是重大的计算瓶颈。现有的开源方法通常需要大规模模型、海量训练数据以及多 GPU 推理。此外,从短视频生成器中蒸馏长程 rollout 能力时,由于缺乏长周期监督,往往会导致场景持久性差和轨迹跟踪不准确。研究团队提出了 SANA-WM,这是一款以高效为核心设计的 26 亿参数开源世界模型。它使用适中规模的数据集进行原生训练,可实现 1 分钟 720p 视频生成,并支持多种部署模式下的单 GPU 推理。为实现这一目标,研究团队采用了一种混合线性 DiT 骨干网络,将循环状态聚合与周期性注意力相结合,以实现高效的长上下文建模。同时配合双分支相机控制机制,即使在高度压缩的情况下,也能保持全局轨迹结构与细粒度运动细节。通过引入来自公开视频的度量级位姿监督以及专用的视觉优化阶段,SANA-WM 将动作跟随准确率和吞吐量相比基线提升了最高 36 倍,使长周期世界建模能够惠及更广泛的研究人员与应用场景。
数据集
数据集构成与来源
- 研究团队通过对七个开源视频源重新标注度量级相机位姿,构建了一个包含 21.3 万条片段的语料库。主要来源包括 Sekai-Game、DL3DV 和 OmniWorld,并补充了其他网络与游戏视频素材。
子集详情与筛选
- 针对 DL3DV 数据集,研究团队将 FCGS 3D 高斯溅射模型拟合至静态 3D 捕捉数据,渲染多样化的 1 分钟轨迹,并使用 DiFix3D 对输出结果进行优化以去除渲染伪影。
- 对于 Sekai-Game 和 DL3DV,保留原始真实轨迹,并应用 Pi3X 算法恢复长序列的度量尺度。
- 对于 OmniWorld,在 VIPE 框架内利用提供的真实深度数据,并使用 MoGe-2 进行逐帧度量恢复。
- 所有子集均通过统一的质量过滤器,该过滤器评估色彩饱和度、VMAF 运动分数、光流一致性、场景切换以及 DOVER 美学评分。研究团队还实施了针对相机的特定阈值要求:水平与垂直视场角需介于 25 至 120 度之间,焦距失配率低于 0.20,尺度变化系数低于 2.0。此外,通过 Qwen3.5 视觉语言模型(VLM)进行二次筛选,进一步剔除画质不佳或实体数量不合适的片段。
训练用途与处理
- 研究团队使用筛选后的数据集训练一个多步、未蒸馏的自回归世界模型。他们将原始的 VIPE 深度后端替换为 Pi3X 以保证序列一致性,并采用 MoGe-2 实现精确的度量缩放,同时对 VIPE 进行适配以支持逐帧内参优化。
- 静态场景数据通过合成相机路径进行增强,路径涵盖多种运动家族,包括环绕、螺旋、推拉以及穿梭轨迹。在训练前,执行严格的高斯覆盖度测试,并丢弃任何包含超过 30% 近空白帧的渲染片段。
元数据构建与描述策略
- 研究团队生成场景静态描述文本,涵盖物体、布局与光照信息,同时明确省略所有描述相机运动的动词。此举可防止文本泄露轨迹监督信号,并强制模型通过专用的位姿分支学习运动控制。
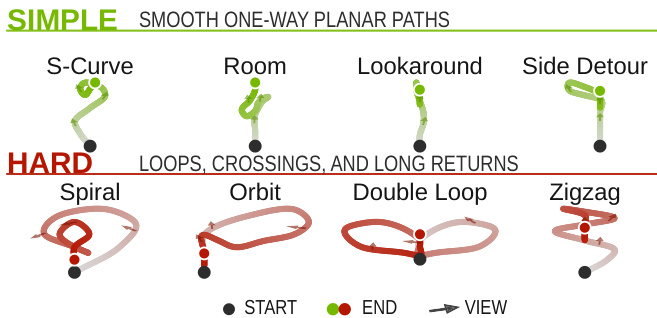
- 在评估阶段,研究团队基于四个场景类别的 80 张首帧条件图像构建了基准测试。每个场景均配对简单与困难轨迹划分,包含平滑导航路径与极端运动模板,并附带重访元数据、基于度量点云的碰撞检测以及平滑度统计信息。
方法
研究团队采用两阶段生成管线,以实现具备精确相机控制能力的高效、高保真分钟级视频合成。整体框架如图所示,包含一个主生成阶段与一个优化阶段。初始阶段 SANA-WM 根据文本、相机位姿及参考图像 tokens 生成潜在序列。该序列随后被送入第二阶段优化器,以提升视觉质量与时间一致性。该架构采用混合注意力机制,将逐帧门控 DeltaNet(GDN)与 softmax 注意力相结合,从而实现内存高效的长上下文建模。每个 Transformer 块均集成双分支相机条件输入:粗粒度分支使用基于射线的 UCPE 编码全局 6 自由度位姿,细粒度分支使用原始帧的 Plücker 混合以捕捉 VAE 时间步长内的运动。模型分四个阶段进行渐进式训练:从高效的 VAE 适配开始,随后进行混合架构适配、加入动作条件的分钟级扩展,最后进行分块因果微调与少步蒸馏以提升推理效率。 
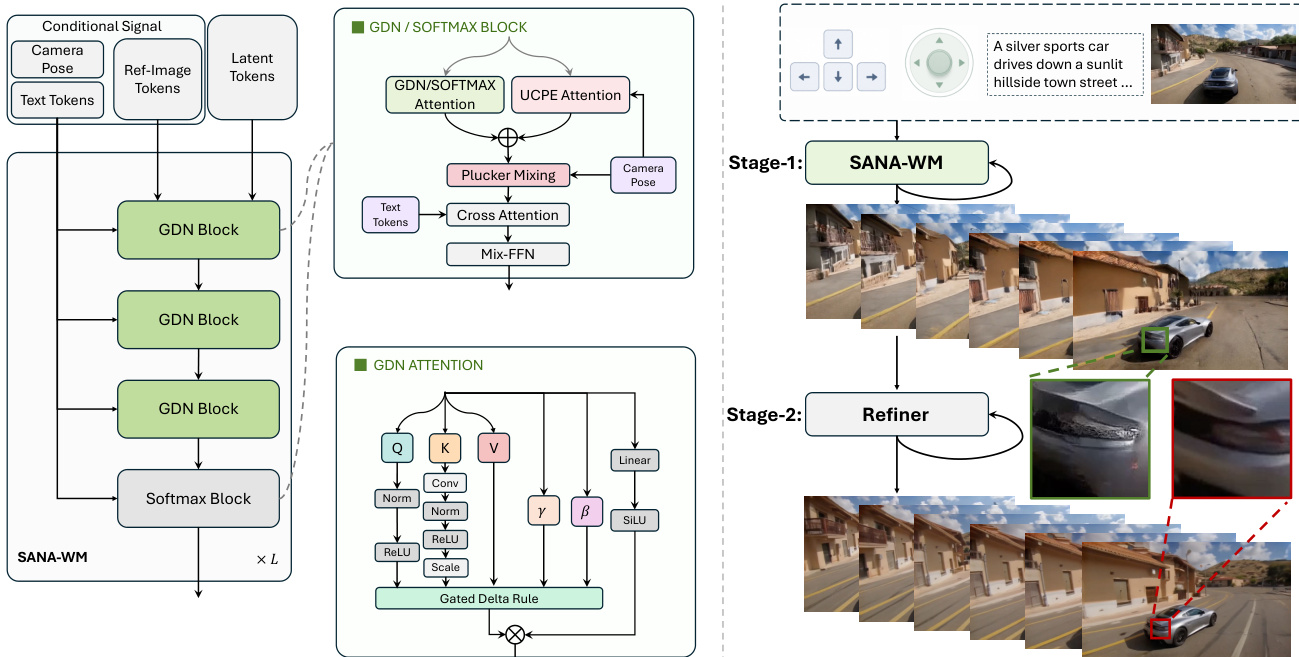
SANA-WM 的核心架构基于包含 20 个 Transformer 块的扩散 Transformer(DiT)。模型在特定层将 15 个逐帧 GDN 块与 softmax 注意力块进行交错排列。这种混合设计结合了 GDN 的内存效率与 softmax 注意力的长程依赖建模能力。GDN 块在帧级别运行,在单次循环步骤中处理潜在帧的所有空间 tokens,从而维持恒定的 D×D 循环状态,避免累积线性注意力带来的内存爆炸问题。逐帧 GDN 通过代数键缩放与衰减门控进行稳定处理,确保长序列上的数值稳定性。在推理阶段,采用分块因果变体,在分块边界处重置反向时间扫描,以提供局部未来上下文且避免信息泄露。该模型还引入了双速率相机条件输入,其中粗粒度 UCPE 分支在潜在帧速率下运行,细粒度 Plücker 混合分支则在每个 VAE 时间步长内处理原始帧射线图。 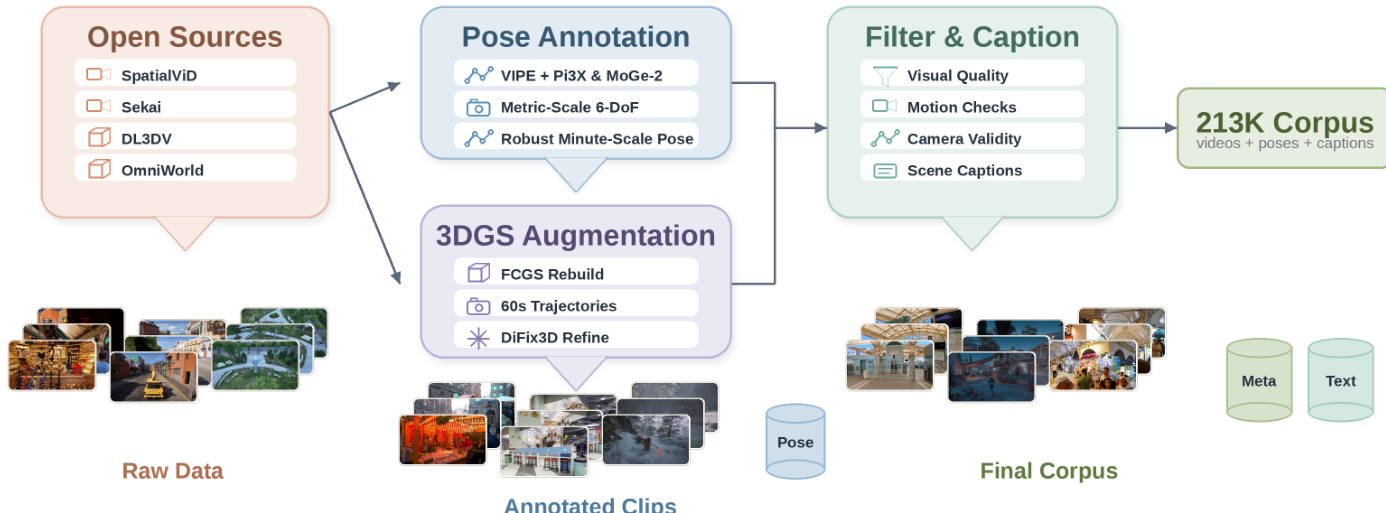
实验
评估在简单与困难相机轨迹上对比了 SANA-WM 与当前世界模型基线。主实验用于验证动作跟随、视觉保真度与部署效率,消融实验则评估架构组件在训练稳定性、内存扩展与相机条件输入方面的表现。结果表明,该架构成功在高分辨率视频生成与严格的单 GPU 限制之间取得平衡,并显著降低了后期窗口的视觉漂移。定性来看,模型在复杂相机运动下始终能保持连贯的场景几何结构与视角一致性,而竞争方法则频繁出现结构模糊或布局崩溃现象。
研究团队在两个轨迹划分上,将 SANA-WM 与多种基线方法在相机控制精度、视觉质量与推理效率方面进行了对比。结果显示,SANA-WM 在位姿精度与视觉质量上表现强劲,尤其是在结合优化器使用时,同时保持了具有竞争力的推理速度与内存占用。优化器提升了长周期稳定性并减少视觉漂移,在挑战性轨迹上效果尤为明显。SANA-WM 在两个轨迹划分上均取得了最佳的位姿精度与视觉质量,在关键指标上超越基线方法。第二阶段优化器进一步提升了视觉质量并降低长周期退化,增强了时间稳定性。与其他 720p 方法相比,SANA-WM 在低内存占用与快速生成速度的同时,保持了极高的推理效率。
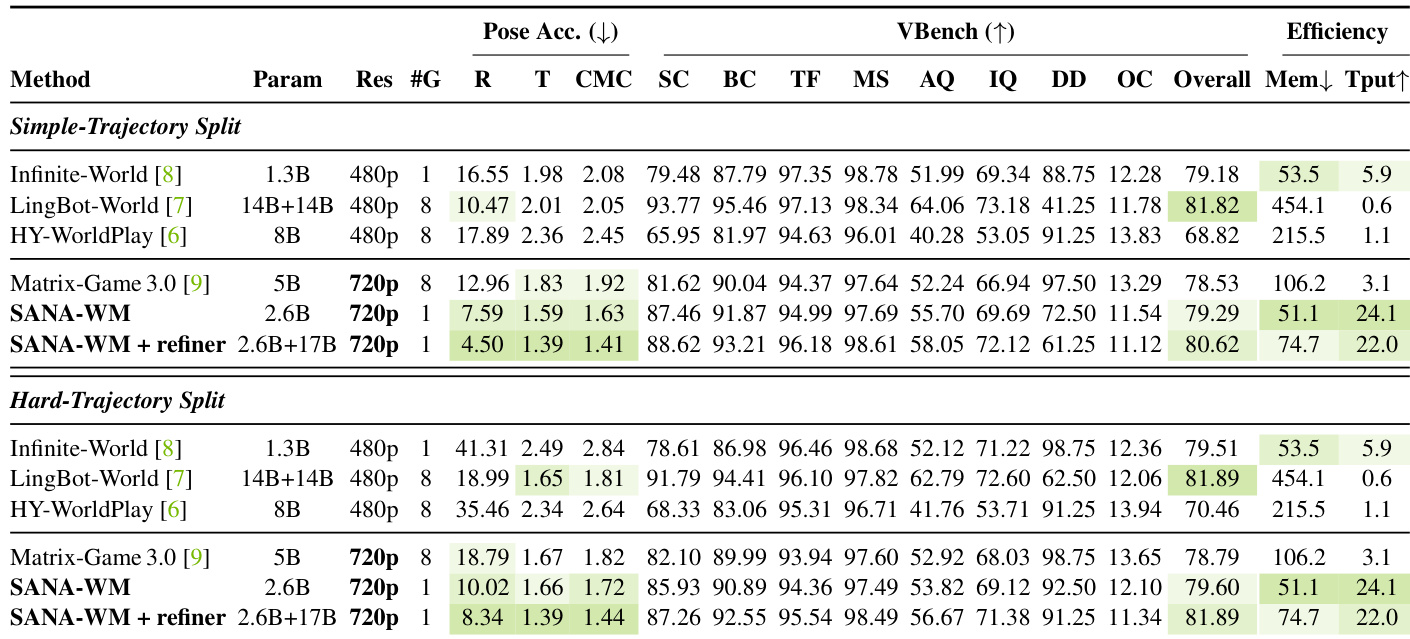
研究团队在相机控制精度、视觉质量与时间稳定性方面将所提方法与基线进行对比,结果表明该方法在各指标上均表现优异,尤其在减少视觉漂移与提升相机跟随方面。优化版模型在多数方面优于原始版本,特别是在维持场景一致性与降低长视频时长退化方面。结果表明,所提方法在实现高效推理与稳健相机控制的同时,保持了高视觉质量。与原始版本及其他基线相比,优化版模型实现了更优的相机控制精度与更低的视觉漂移。该模型在长视频时长内维持高视觉质量且退化极小,在困难划分(Hard split)上表现尤为突出。优化版模型在重访记忆与时间稳定性指标上均优于原始版本及其他基线。

研究团队展示了研究中使用的不同数据集对比,突出了各项指标(如运动幅度、色彩饱和度、场景切换与质量)的各自范围。表格显示,数据集的参数范围各不相同,部分数据集支持更高的运动幅度,而其他数据集则侧重色彩与场景变化,表明实验中存在多样化的评估条件。数据集在运动范围上存在差异,部分支持的运动幅度高于其他数据集。色彩饱和度与场景切换在不同数据集中的定义方式不同,反映了评估条件的多样性。质量指标在各数据集中定义一致,表明采用标准化方法评估视频质量。

表格概述了跨四个阶段的渐进式训练管线,各阶段具有明确的目标、数据需求与计算预算。第一阶段专注于使用 SANA-Video SFT 数据进行逐帧 GDN 训练;第二阶段进行混合注意力训练;第三阶段开展分钟级视频与相机控制训练;第四阶段则使用高质量片段进行 SFT。管线从较短片段逐步过渡至较长片段,计算预算递增,学习率递减。训练管线共分为四个阶段,各阶段对应特定的数据类型与片段时长,从 5 秒片段逐步扩展至 1 分钟片段。有效全局批次大小从第一阶段的 64 降至第四阶段的 32,而训练步数与计算预算在各阶段逐步增加。学习率在各阶段逐步降低,从第一阶段的 5 × 10^-5 降至第四阶段的 1 × 10^-5。

研究团队对比了模型的不同训练配置,突出了在质量、效率与内存使用方面的改进。结果显示,混合注意力变体在保持具有竞争力的延迟与内存消耗的同时取得了最高质量评分,其中 GDN + softmax 配置在两项指标上均优于其他方案。混合注意力配置在维持竞争性延迟与内存占用的前提下获得最高质量评分。与累积线性基线相比,GDN + softmax tokenizer 同时提升了质量与效率。LTX2 VAE 变体在保持质量的同时降低了内存消耗与延迟,表明在效率与性能之间存在权衡。
评估涵盖多样化的视频数据集与渐进式训练管线,旨在多种实验设置下验证相机控制精度、视觉保真度与时间一致性。结果表明,专用优化器显著增强了长周期稳定性并减少视觉漂移,在挑战性运动条件下效果尤为明显。针对架构配置的进一步消融实验证实,混合注意力机制与优化 tokenizer 在保持竞争性推理效率的同时,带来了更优的视觉质量。综上所述,这些发现确立了该方法作为一种稳健且资源高效的技术框架,可用于实现精确相机引导的视频生成。