Command Palette
Search for a command to run...
FashionChameleon:迈向实时且可交互的人-服装视频定制
FashionChameleon:迈向实时且可交互的人-服装视频定制
Quanjian Song Yefeng Shen Mengting Chen Hao Sun Jinsong Lan Xiaoyong Zhu Bo Zheng Liujuan Cao
摘要
以人为中心的视频定制,特别是在服装层面,已展现出显著的商业价值。然而,现有方法无法支持低延迟和交互式的服装控制,而这对于电子商务和内容创作等应用至关重要。本文研究了如何仅使用单件服装视频数据,在保持运动连贯性的同时实现交互式多服装视频定制。我们提出了 FashionChameleon,这是一个用于自回归视频生成中人-服装定制的实时交互式框架,用户可以在生成过程中交互式地切换服装。FashionChameleon 包含三项关键技术:(i) 我们不在多服装视频数据上进行训练,而是使用上下文学习(In-Context Learning)在单个参考服装对上训练一个教师模型(Teacher Model)。在保留图像到视频训练范式的同时,通过强制参考图像与服装图像之间的不匹配,鼓励模型在单件服装切换过程中隐式地保持连贯性。(ii) 为了实现生成过程中的一致性和效率,我们引入了带有上下文学习的流式蒸馏(Streaming Distillation with In-Context Learning),该方法通过上下文教师强制(in-context teacher forcing)对模型进行微调,并通过梯度重加权分布匹配蒸馏(gradient-reweighted distribution matching distillation)提高外推一致性。(iii) 为了扩展模型以支持交互式多服装视频定制,我们提出了免训练的 KV 缓存重调度(Training-Free KV Cache Rescheduling),其中包括服装 KV 刷新、历史 KV 撤回和参考 KV 解耦,以实现服装切换的同时保持运动连贯性。我们的 FashionChameleon 独特地支持交互式定制和一致性的长视频外推,并在单块 GPU 上实现了 23.8 FPS 的实时生成速度,比现有基线方法快 30-180 倍。
一句话总结
FashionChameleon 是一个实时、交互式的人-服装视频定制框架,支持在生成过程中动态切换服装。该框架利用单参考数据的上下文学习(in-context learning)实现服装切换,通过强制采用参考图像不匹配的 Training 范式以保持运动连贯性,并应用结合上下文教师强制(in-context teacher forcing)的流式蒸馏技术,确保面向电商和内容创作的低延迟性能。
核心贡献
- 提出 FashionChameleon,一个用于自回归视频生成中人-服装定制的实时交互式框架,能够在生成过程中动态切换服装,同时保持运动连贯性。
- 仅使用单服装参考对实现多服装控制。通过上下文学习训练教师模型,并故意使参考图像与目标服装图像不匹配,从而隐式维持时间一致性。
- 将结合上下文教师强制的流式蒸馏与梯度重加权分布匹配蒸馏相结合,以降低推理延迟,并提升生成视频序列间的外推一致性。
引言
基于扩散的视频生成领域近期取得了显著进展,主体到视频的定制技术使用户能够将参考概念注入生成内容中。服装级别的控制在电商与影视制作中具有重要价值,但现有方法普遍存在推理延迟高、交互能力有限,以及在动态切换服装时难以维持运动一致性的问题。为弥补上述不足,研究人员提出 FashionChameleon,这是一个实时交互式框架,通过适配混合自回归生成技术来实现流式人-服装定制。该框架利用具备上下文学习能力的教师网络从单服装数据中进行泛化,采用流式蒸馏以平衡效率与长视频一致性,并引入无需训练的 KV 缓存重排机制,从而在生成过程中实现无缝且动态的服装切换。
数据集
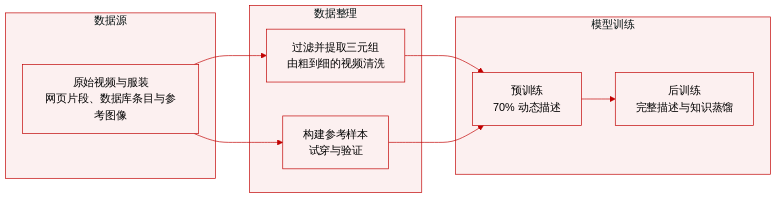
• 数据集构成与来源:研究人员构建了一个核心训练数据集与名为 HGC-Bench 的评估基准。两者均以三元组为基础结构,包含参考图像、服装图像以及配对的视频序列与结构化提示词。原始视频从互联网采集,服装图像取自专用数据库,参考图像则通过算法构建以提升训练鲁棒性。
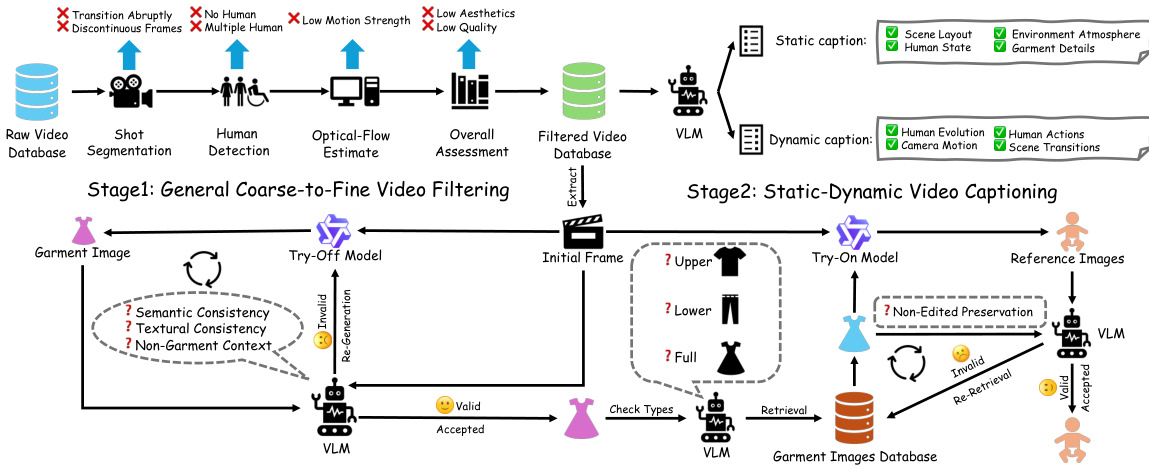
• 子集详情与过滤规则:训练流程初始生成约 8.2 万个三元组,经人工校验后缩减至 6.2 万个。视频数据经历四个阶段的由粗到细的过滤流程:将场景分割为 3 至 5 秒的片段,使用 YOLOv8-Seg 保留单人画面,通过光流阈值进行运动过滤,并利用 Q-Align 与 FAST-VQA-M 进行质量评估。HGC-Bench 子集包含 240 个高审美样本,其中面部通过替换实现匿名化,与数据库中的服装配对,并附带在严格动作与格式规范下生成的提示词。
• 模型使用与训练配置:在预训练与流式蒸馏后训练阶段,研究人员均采样 81 帧序列,并将视频与参考图像调整至 1280×704 像素,同时保持原始宽高比。服装图像通过中心填充以匹配该分辨率。预训练期间,采用仅动态描述与完整静态动态描述的 70:30 混合比例,以降低对文本的依赖。后训练阶段切换为完整描述以提升性能。该流程采用全分片数据并行(Fully Sharded Data Parallelism),全局批量大小为 64,使用 AdamW 优化器。精度设置方面,预训练期间 VAE 保持 float32,后训练阶段两个组件均切换至 bfloat16。
• 元数据构建与处理细节:研究人员采用基于 Gemini-3.1 的静态动态解耦策略,生成格式为 JSON 的中英双语描述。服装提取依赖 Qwen-Image-Edit,随后通过三个阶段的视觉语言模型(VLM)验证,检查语义、纹理与上下文一致性。参考图像通过分类服装类型、从数据库检索兼容物品并应用图像试穿模型来动态构建,VLM 验证确保未编辑区域保持不变。在交互式推理阶段,提示词中明确排除服装相关术语,以防止与视觉输入产生冲突。
方法
研究人员采用一个三组件框架,以实现自回归视频生成中的实时交互式服装定制。如框架示意图所示,整体架构包含:通过上下文学习训练的教师模型(Teacher Model)、用于高效推理的流式蒸馏流程,以及在不破坏运动连贯性的前提下实现动态服装切换的无需训练 KV 缓存重排机制。
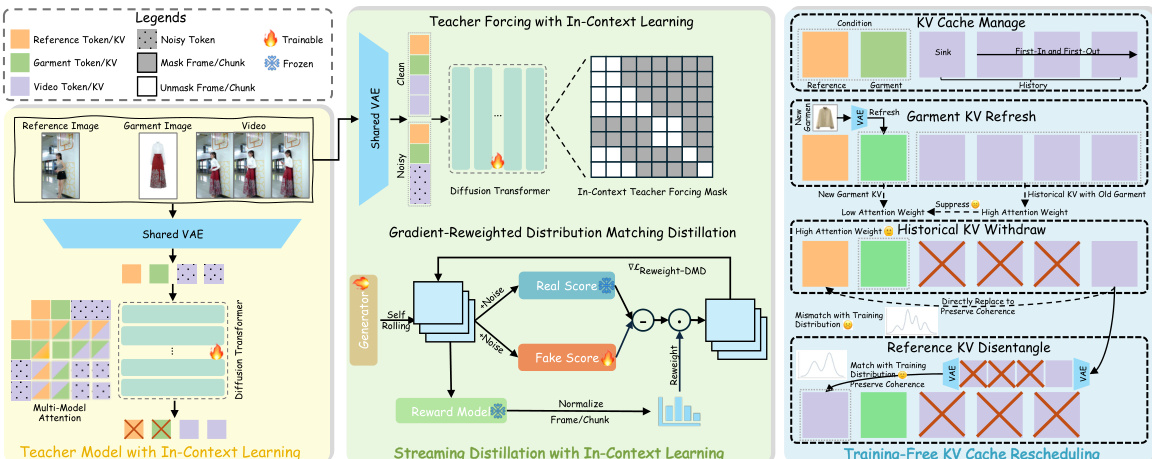
系统的基础是教师模型,该模型基于单个参考-服装对,采用上下文学习进行训练。该模型运行于统一的骨干网络中,处理离散的参考图像与服装图像,无需辅助编码器。训练过程保留图像到视频(I2V)范式,确保除服装信息外,首帧生成结果与参考帧保持一致。为实现这一目标,参考图像与服装图像分别通过共享的 VAE 编码器编码为潜在表示(latent representations)。这些潜在表示与带噪视频潜在表示拼接后,输入 Transformer 内的多模态注意力机制。该共享注意力机制在不引入额外参数的情况下,实现条件潜在表示与视频潜在表示的全局交互,使模型能够在保持连贯性的同时隐式学习单服装切换。

为实现实时生成,预训练的教师模型被蒸馏为少步自回归学生模型。该蒸馏过程称为“结合上下文学习的流式蒸馏”(Streaming Distillation with In-Context Learning),采用上下文教师强制掩码(in-context teacher forcing mask)以稳定训练。该掩码允许模型在生成过程中基于真实历史帧与条件信号进行条件生成,这对上下文学习架构至关重要。在教师强制之后,应用梯度重加权分布匹配蒸馏(gradient-reweighted distribution matching distillation)以提升外推一致性。该技术使用审美奖励模型在蒸馏过程中评估帧质量,并将分数归一化为逐帧梯度权重。这种自适应重加权机制增强了低质量帧的影响,同时降低高质量帧的影响,从而缓解自回归生成过程中后期帧的误差累积与漂移现象。
针对交互式多服装视频定制,系统采用无需训练的 KV 缓存重排(Training-Free KV Cache Rescheduling)机制。该机制负责管理键值(KV)缓存,以实现稳定的长视频外推。其包含三个核心操作:服装 KV 刷新(Garment KV Refresh),用于更新缓存中的服装 KV 条目以切换服饰;历史 KV 撤回(Historical KV Withdraw),用于移除历史 KV 条目,降低模型对旧服装上下文的依赖,使新服装生效;参考 KV 解耦(Reference KV Disentangle),用源自上一历史帧的新参考 KV 替换旧参考 KV,以在切换点维持时间连贯性。框架示意图展示了这些操作如何协同工作,在保持人体运动连贯性的同时实现无缝服装切换。
实验
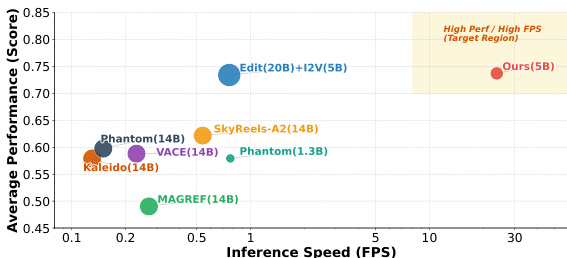
评估工作建立了一个全面的基准测试,将提出的自回归流式蒸馏框架与主流的多参考视频生成基线方法进行对比,通过自动化评估与人类偏好研究,验证了其在保持角色身份、服装保真度与运动连贯性方面的能力。定性分析表明,该方法在复杂姿态与长序列中始终能保留精细的服装细节与自然动作,有效缓解了竞争方法中出现的外观退化与时间不连贯问题。消融实验进一步证实,特定的训练策略与缓存重排机制对于防止长视频外推过程中的运动崩溃,以及实现实时交互式服装切换至关重要。总体而言,实验确认该框架能够提供卓越的视觉质量与时间一致性,并解锁现有双向模型无法实现的交互式定制能力。
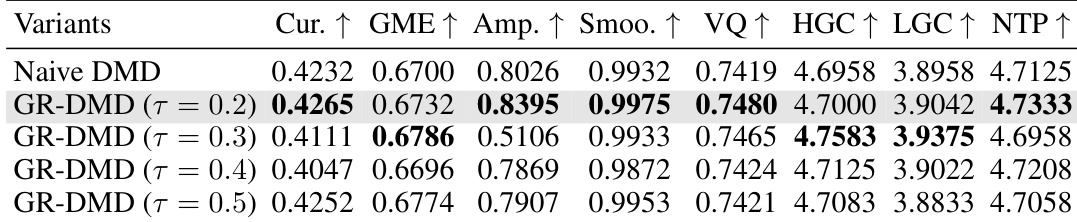
下表展示了针对梯度重加权分布匹配蒸馏(GR-DMD)不同变体及其温度系数的定量消融研究。结果表明,温度为 0.2 的变体在时间平滑度、视觉质量与服装一致性等多项指标上表现最佳。其他变体性能较低,部分在运动幅度与时间平滑度等关键领域出现显著下降。温度为 0.2 的变体在多项指标上取得最优成绩。较高的温度值会导致运动幅度与时间平滑度明显下滑。该变体在视觉质量与服装一致性指标上优于其他方法。
研究人员展示了多种人-服装视频定制方法的对比,重点关注身份一致性、文本对齐、运动幅度、时间平滑度、视觉质量与服装一致性等指标。FashionChameleon 在时间平滑度、视觉质量与服装一致性等关键领域取得最高分,同时展现出优于其他方法的推理效率。FashionChameleon 在时间平滑度、视觉质量与服装一致性指标上全面超越所有基线方法。该方法推理效率最高,能够以显著高于其他方法的帧率实现实时生成。在身份一致性与运动幅度方面,该方法排名第二,与表现最佳的基线方法差距极小。
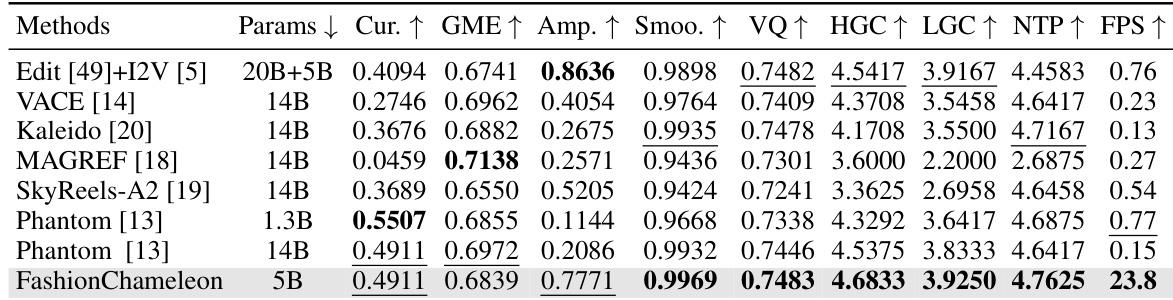
研究人员从性能与效率权衡的角度对比了不同方法,所提方法取得了最高的平均性能,且推理速度显著优于其他方案。结果表明,该方法在效率与有效性方面均超越基线方法,位于性能-速度空间中的优势区域。在所有对比方法中,该方法平均性能最高。其推理速度显著快于其他方法。该方法在性能与效率上全面领先,确立了在性能-效率权衡空间中的优越地位。
研究人员在消融实验中对比了不同的教师模型训练策略,重点分析其对视频生成质量的影响。结果表明,采用上下文学习结合全量微调的所提方法在多项指标上表现优异,尤其在时间平滑度、视觉质量与服装一致性方面。表现最佳的变体优于采用其他微调方法或基于拼接的方案。结合上下文学习与全量微调的方法在时间平滑度与视觉质量等关键指标上领先于替代方案。最佳变体在服装一致性与非目标服装保留方面得分最高。在大多数评估指标中,全量微调方法的表现持续优于采用注意力微调或 LoRA 微调的方法。

评估框架包含消融实验与对比分析,验证了分布匹配蒸馏的最优温度设置以及不同教师模型训练策略的有效性。实验表明,适中的温度系数结合全量微调与上下文学习,能够持续增强时间连贯性、视觉保真度与服装保留效果。与现有基线方法的对比评估进一步证实了该方法在视频定制质量上的优势,同时确认了其显著更快的推理速度。最终,该方案确立了一种高效解决路径,成功实现了计算性能与高保真人-服装视频合成之间的平衡。