Command Palette
Search for a command to run...
通过文本-表格建模从有限交互中预测 AI Agent 的决策
通过文本-表格建模从有限交互中预测 AI Agent 的决策
Eilam Shapira Moshe Tennenholtz Roi Reichart
摘要
AI智能体使用自然语言与不熟悉的对手进行谈判和交易:例如,面对未知卖家的买家机器人,或与供应商进行谈判的采购助手。在这些交互中,对手的LLM、提示词、控制逻辑以及基于规则的后备机制均处于隐藏状态,而每一次决策都可能产生经济后果。我们探讨一个智能体能否通过少量交互预测不熟悉对手的下一步决策。为避免现实世界日志带来的混淆因素,我们在受控的讨价还价和谈判游戏中研究这一问题,将其表述为面向目标的自适应文本-表格预测:每个决策点是一个表格行,结合了结构化游戏状态、报价历史和对话内容,而同一目标智能体(即被建模的对手)的前K场游戏作为带标签的适应示例提供在提示中。我们的模型基于一个表格基础模型,该模型使用游戏状态特征和基于LLM的文本表示来表征行,并引入“LLM作为观察者”(LLM-as-Observer)作为额外的表征方式:一个小型冻结的LLM读取决策时的状态和对话;其答案被丢弃,其隐藏状态成为面向决策的特征,使LLM充当编码器而非直接进行少样本预测。在13个前沿LLM智能体上进行训练,并在91个保留的脚手架智能体上进行测试,完整模型优于直接的“LLM作为预测器”提示方法和游戏+文本特征基线。在该表格模型内部,观察者特征相较于其他特征方案贡献更大:在K=16时,它们在两项任务中将响应预测AUC提高了约4个百分点,并将讨价还价报价预测误差降低了14%。这些结果表明,将对手预测表述为面向目标的自适应文本-表格任务能够实现有效的适应,且隐藏的LLM表征揭示了直接提示无法显现的与决策相关的信号。
一句话总结
作者提出了一种目标自适应的文本-表格框架,该框架整合了 LLM-as-Observer 模块,将冻结语言模型的隐藏状态转换为面向决策的特征。该模型在 13 个前沿 LLM Agent 上进行训练,并在 91 个未参与测试的对应模型上进行评估,结果显示可将响应预测 AUC 提升约 4 个百分点,并在 K=16 局历史对局中将议价报价误差降低 14%。
核心贡献
- 本研究将针对不熟悉语言类 Agent 的少样本预测问题构建为目标自适应的文本-表格任务,利用 K 次历史交互作为标注样本,从而在无需访问隐藏提示词或控制逻辑的情况下实现模型适配。
- 该工作引入了一种 LLM-as-Observer 机制,通过冻结的小型语言模型处理公开的决策时刻状态与对话内容,提取隐藏状态作为面向决策的特征供表格预测器使用,而非依赖直接的少样本提示。
- 研究发布了一个包含 91 个 Agent 的大学黑客松数据集,用于评估从前沿模型到脚手架 Agent 的跨群体迁移能力。实验证明,所提架构优于直接提示基线,且 Observer 特征使响应预测 AUC 提升约 4 个百分点,同时将议价报价预测误差降低 14%。
引言
随着 AI Agent 越来越多地以自然语言与陌生对手进行谈判,准确预测其下一步动作对于管理自动化交易中的财务风险至关重要。现实世界的交易数据大多难以获取,而传统的直接提示方法在无需暴露内部提示词或控制逻辑的情况下,难以快速适配新 Agent。为突破这些限制,作者采用了一种目标自适应的文本-表格框架,将少量历史交互视为标注样本以实现模型的快速适配。研究构建了一个表格预测器,该预测器融合了结构化的游戏变量、对话嵌入以及一种新颖的 LLM-as-Observer 模块,后者将冻结语言模型内部的隐藏状态重新用作面向决策的特征。该设计使模型能够对未见过的 Agent 实现稳健的少样本泛化,并通过可靠提取标准生成方法所忽略的行为信号,持续超越直接提示基线。
数据集
-
数据集构成与来源 作者基于 GLEE 基准构建了一个跨群体数据集,该基准是一个用于双人、顺序、基于语言的经济游戏的模拟框架。数据集将训练源群体与未参与测试的目标群体进行配对,以评估决策预测器能否在不同维度的 Agent 异质性之间实现迁移。
-
各子集关键详情
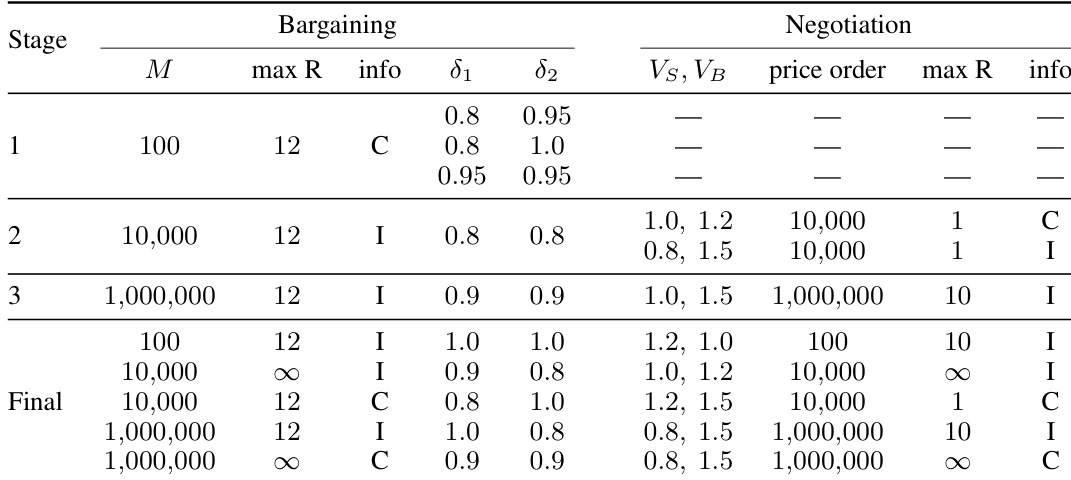
- GLEE 前沿 LLM 锦标赛(训练源): 数据来源于一场由六家供应商的 13 个前沿 LLM 参与的全循环锦标赛。数据集包含约 64,000 局游戏及 197,000 次接受或拒绝决策。各 Agent 仅在底层模型上存在差异,共参与 960 种配置,涵盖议价与谈判游戏,其游戏时长、贴现因子、估值及通信机制均经过系统化调整。
- 大学黑客松(未参与测试目标): 数据来源于 2025 年 12 月举行的一场竞技黑客松。数据集包含 4,921 局游戏及 11,341 次决策,涉及 91 个独立的团队阶段 Agent。所有 Agent 均被限制使用 Gemini 2.5 Flash 或 Flash-Lite API,但在控制逻辑与提示工作流等脚手架技术上存在差异。该子集筛选了启用自由文本的配置,并将每个团队阶段迭代视为独立的 Agent。
-
数据使用与处理 作者将数据结构化为两项预测任务:响应预测(针对接受或拒绝决策的二分类)与报价预测(针对归一化报价值的回归)。在评估阶段,分配 K 局已观测游戏用于指导预测,同时在未参与测试的游戏上进行测试。推理过程中绝不查询目标 Agent,预测器仅接收公开可观测的状态信息。研究采用严格的源到目标划分方式进行跨群体迁移评估,而非混合使用不同群体。
-
元数据构建与处理细节 每个决策点均被格式化为包含公开游戏配置、报价历史、对话上下文及目标 Agent 下一步动作的文本-表格行。作者对信息不完备配置中的私有值进行掩码处理,以防止数据泄露。游戏元数据(包括收益参数与配置标志)从 config.json 文件中提取,并用于系统化控制实验条件。冻结的 LLM Observer 隐藏状态亦被追加至每一行,以增强表格特征。
方法
作者利用一种目标自适应的表格学习框架,基于少量观测交互预测未见语言类 Agent 的下一步决策。该方法不同于 LLM 的直接模仿,而是将问题视为表格预测任务,条件同时包含大规模源群体与目标群体的少量标注样本。框架将结构化的游戏状态特征、对话表示以及来自冻结 LLM(称为 Observer)的面向决策隐藏状态,整合为多模态表格行。该行作为表格预测器的输入,预测器通过结合源群体与目标观测游戏实现针对目标 Agent 的适配。
框架示意图见  。模型主要运行于两种配置:基础文本-表格设置与包含 Observer 表示的增强版本。在这两种情况下,预测器均接收由三种不同特征模态构建的多模态输入向量。表格预测器(基于 TabPFN 实现)处理该输入,输出分类(接受/拒绝)或回归(报价)结果。
。模型主要运行于两种配置:基础文本-表格设置与包含 Observer 表示的增强版本。在这两种情况下,预测器均接收由三种不同特征模态构建的多模态输入向量。表格预测器(基于 TabPFN 实现)处理该输入,输出分类(接受/拒绝)或回归(报价)结果。
第一种模态由结构化的游戏状态特征组成,用于编码交互的战略背景。对于议价游戏,该特征包含配置级参数(如待分配总额、贴现因子与游戏时长),以及每轮历史报价与决策的摘要。对于谈判游戏,特征则涵盖买卖双方估值、参考价格与外部选项收益。这些特征使预测器能够直接获取塑造理性行为的激励因素与历史数据。
第二种模态为源自游戏内自然语言交互的对话表示。作者使用句子编码器处理截至当前决策点的所有交换消息,并通过主成分分析(PCA)将生成的高维嵌入降维至低维向量。该表示能够捕捉对话的语义上下文,但并未显式训练用于预测战略决策。
第三种模态即 Observer 表示,由一个处理当前公开游戏状态与对话的小型冻结 LLM 生成。该 LLM 被提示以预测下一步决策,但其输出结果被丢弃,转而提取内部隐藏状态作为面向决策的特征。该表示能够捕获决策过程中可能无法通过 LLM 生成输出直接获取的信息。Observer 始终未经微调,且不接收目标提示词或历史对局,从而确保适配过程完全在表格预测器内部完成。
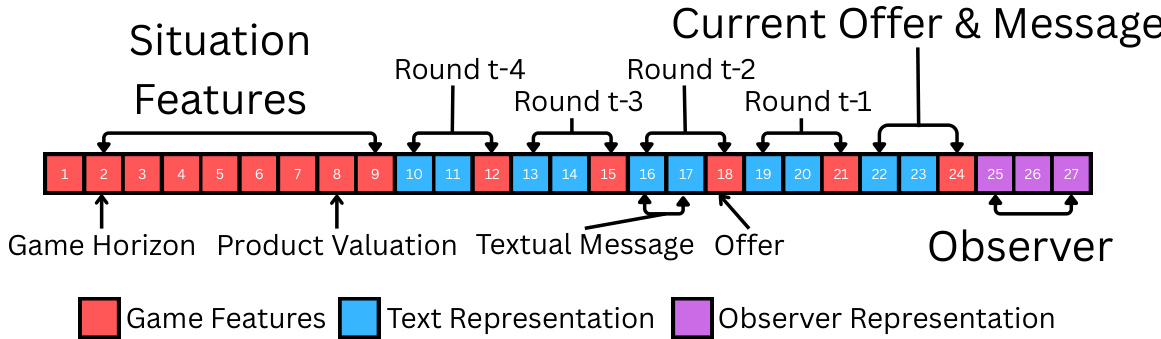 如图所示,多模态表格行的结构将游戏状态特征与对话表示和 Observer 隐藏状态进行拼接。该行还包含一个 Agent 身份指示器,即指定源 Agent 或目标 Agent 的独热向量。该指示器使表格预测器能够区分群体级模式与目标特异性行为,这在同时结合源数据与目标数据时尤为重要。
如图所示,多模态表格行的结构将游戏状态特征与对话表示和 Observer 隐藏状态进行拼接。该行还包含一个 Agent 身份指示器,即指定源 Agent 或目标 Agent 的独热向量。该指示器使表格预测器能够区分群体级模式与目标特异性行为,这在同时结合源数据与目标数据时尤为重要。
表格预测器通过对源群体的全部标注样本与目标群体的 K 局观测游戏进行条件计算来执行推理。这种联合条件计算使模型能够结合源群体的广泛统计规律与目标群体有限历史中的特定适配信号。该模型同时用于分类与回归任务,并针对 Observer 的提示后缀进行任务特定调整,以确保特征提取的准确性。对于报价预测,目标变量首先被归一化至单位尺度,随后进行逆变换以恢复原始货币值,其中议价与谈判游戏采用不同的归一化方案。模型性能采用中位数 R2 进行评估,以减轻单 Agent 预测准确率中重尾分布的影响。
实验
本研究通过在前沿 LLM Agent 上进行训练并在未参与测试的黑客松参与者上进行测试来评估跨群体迁移能力,并采用不同数量的适配样本,以验证利用冻结 LLM 潜状态的目标自适应表格框架是否优于结构化特征基线与直接少样本提示。定性分析表明,从模型中间层提取可复用表示,在响应预测与报价预测方面始终优于仅依赖游戏特征或直接 LLM 推理的方法。由于自回归解码的固有局限,直接提示在数值预测方面被证明极不可靠,而表格化方法能够有效解码稳定的战略信号,从而建立了一种稳健且独立于供应商的 Agent 适配方案。
作者在跨群体迁移设置下,将目标自适应文本-表格模型与直接提示及简化表格基线进行对比评估。结果显示,Observer 增强模型持续优于 LLM-as-Predictor 与游戏加文本特征基线,且随着适配样本数量的增加,性能提升愈发显著。Observer 隐藏状态为响应预测提供了显著增益,尤其在议价任务中,其提供的信号较 LLM 直接输出 logits 更为稳定可靠。Observer 增强模型在所有条件及两类任务族中均取得高于 LLM-as-Predictor 与游戏加文本特征基线的性能。Observer 隐藏状态相较于游戏加文本特征基线带来实质性改进,尤其在响应预测及适配样本较少时表现突出。LLM 的直接输出 logits 效果弱于隐藏状态表示,表明预测信号主要存在于潜空间而非模型最终输出中。
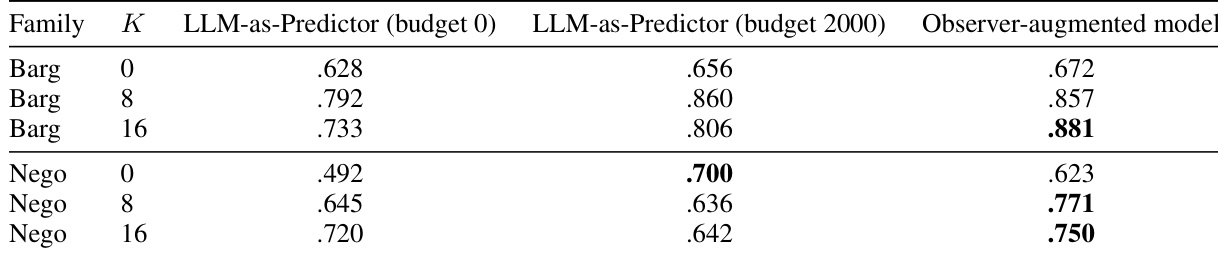
作者将目标自适应文本-表格模型与包含直接 LLM 提示及简化表格模型在内的基线进行对比,重点考察跨群体迁移能力。结果表明,引入 Observer 隐藏状态持续提升了相较于游戏加文本特征的性能,尤其在响应预测方面,而其对报价预测的增益在议价任务中较谈判任务更为明显。Observer 隐藏状态在不同 LLM 供应商与层中均提供稳定且鲁棒的信号,优于直接 LLM 输出。Observer 隐藏状态在所有设置下均显著优于游戏加文本特征与直接 LLM 提示的响应预测效果。报价预测仅在议价任务中受益于 Observer 特征,而在谈判任务中未显现,表明其具有任务特定效用。Observer 隐藏状态的预测优势在不同 LLM 供应商间保持一致,并在中后期层中保持稳定。
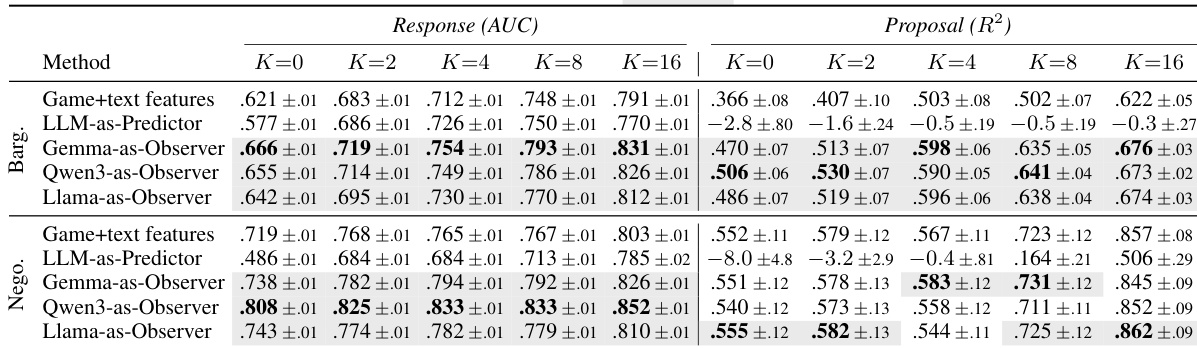
作者评估了融合冻结 LLM Observer 隐藏状态的目标自适应文本-表格模型,旨在提升跨群体迁移设置下的预测性能。结果显示,使用 Observer 表示在不同 LLM 供应商与适配层级中持续增强响应预测效果,而其对报价预测的增益在议价任务中较谈判任务更为显著。性能提升在中后期 LLM 层中保持稳定,并优于直接 LLM 提示,后者在数值报价预测方面表现尤为薄弱。Observer 隐藏状态在不同 LLM 供应商与适配层级中为响应预测带来一致改进。Observer 表示对报价预测的增益在议价任务中强于谈判任务。直接 LLM 提示在数值报价预测中表现不佳,而结合 Observer 特征的文本-表格方法则取得更优结果。
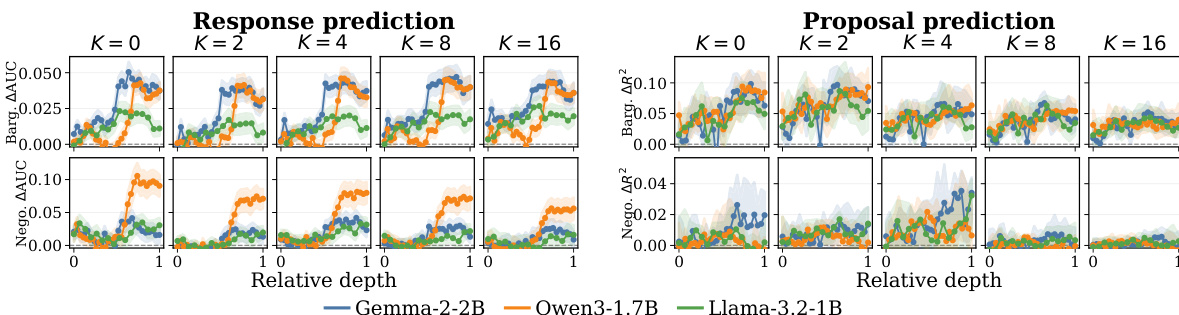
作者将目标自适应文本-表格模型与采用直接提示或简化表格特征的基线进行对比,重点考察从前沿 LLM 锦标赛到黑客松 Agent 的跨群体迁移。结果表明,引入 Observer 隐藏状态显著提升了议价与谈判两类任务的响应预测效果,尤其在适配样本数量较多时更为明显,而报价预测的增益在议价任务中更为突出。Observer 隐藏状态表示持续优于 LLM 的直接输出概率,表明表格模型比 LLM 自身的预测头更能从潜空间解码战略信号。Observer 隐藏状态在议价与谈判任务的响应预测中,均持续优于游戏加文本特征。Observer 隐藏状态表示在响应与报价预测中均比 LLM 直接输出概率更有效。Observer 的增益在不同 LLM 供应商间表现稳健,且在模型中后期层保持稳定。
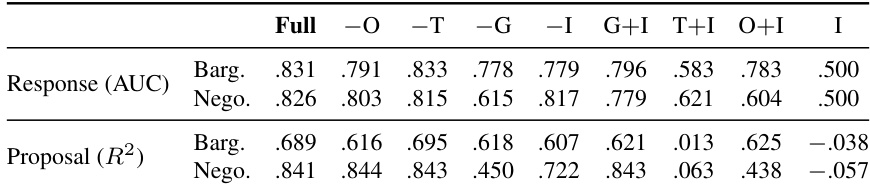
作者将目标自适应文本-表格模型与采用直接提示或简化表格特征的基线进行对比,重点考察从前沿 LLM 锦标赛到未参与测试黑客松 Agent 的跨群体迁移。结果表明,引入 Observer 隐藏状态提升了相较于游戏加文本特征与直接 LLM 提示的预测性能,尤其在响应预测及议价任务的报价预测方面,后者在仅依赖结构化历史数据时表现不足。性能提升在不同 LLM 供应商间保持一致,且在模型中后期层中保持稳定。Observer 隐藏状态在响应与报价预测中均持续优于游戏加文本特征与直接 LLM 提示。Observer 效应在议价任务中较谈判任务更为显著,后者本身已具备较强的结构化游戏特征。Observer 提供的预测信号在不同 LLM 供应商及中后期层中保持稳定,表明这是隐藏状态的内在属性,而非层选择导致的人为现象。
作者评估了融合冻结 LLM 隐藏状态的目标自适应文本-表格模型,在涉及议价与谈判任务的跨群体迁移设置下,将其与直接提示及简化表格基线进行对比。结果证明,利用这些潜表示持续生成比直接模型输出或结构化游戏特征更为稳定可靠的预测信号,尤其在议价场景的响应预测与报价生成方面。研究结论证实,Observer 架构的预测优势在不同语言模型与内部层中均表现稳健,表明战略行为信息被有效编码于中间表示中,而非最终输出概率内。