Command Palette
Search for a command to run...
Qwen-Image-VAE-2.0 技术报告
Qwen-Image-VAE-2.0 技术报告
摘要
我们提出了 Qwen-Image-VAE-2.0,这是一套高压缩变分自编码器(VAE)套件,在重建保真度和可扩散性方面均取得了显著进展。为了解决高压缩带来的重建瓶颈,我们采用了一种改进的架构,该架构具有全局跳跃连接(GSC)和扩展的潜在通道。此外,我们将训练规模扩展至数十亿张图像,并引入合成渲染引擎以提升文本丰富场景下的性能。为应对高维潜在空间的收敛挑战,我们实施了一种增强的语义对齐策略,使潜在空间高度适配扩散建模。为优化计算效率,我们利用一种非对称且无注意力机制的编码器-解码器主干网络,以最小化编码开销。我们在公开的重建基准上对 Qwen-Image-VAE-2.0 进行了全面评估。为了评估文本丰富场景下的性能,我们提出了 OmniDoc-TokenBench,这是一个新的基准测试,包含多样化的真实文档集合以及基于专用 OCR 的评估指标。Qwen-Image-VAE-2.0 实现了最先进的重建性能,在高压缩比下,在通用领域和文本丰富场景均展现出卓越的能力。此外,下游 DiT 实验表明,我们的模型具有优越的可扩散性,与现有高压缩基线相比,显著加速了收敛过程。这些成果确立了 Qwen-Image-VAE-2.0 作为一款领先模型的地位,具备高压缩比、卓越的重建能力和出色的可扩散性。
一句话总结
Qwen团队推出了Qwen-Image-VAE-2.0,这是一款高压缩变分自编码器套件。该套件融合了全局跳跃连接、扩展的潜在通道、不对称的无注意力骨干网络以及增强的语义对齐策略,以优化重建效果与扩散兼容性。同时,通过将训练规模扩展至数十亿张图像并引入合成渲染引擎,该模型在通用领域及文本密集型场景中实现了业界领先的性能。这一成果在公开基准测试、新型OmniDoc-TokenBench基准以及下游DiT实验中加速收敛的表现均得到了验证。
核心贡献
- Qwen-Image-VAE-2.0引入了支持f16与f32压缩比的高压缩VAE架构,利用全局跳跃连接和扩展的潜在通道来保留细粒度细节。不对称且无注意力的编解码器骨干网络将编码开销降至最低,从而促进高效的原生高分辨率生成。
- 采用分阶段语义对齐策略,借助DINOv2中间特征加速高维潜在空间中的扩散Transformer收敛。该训练范式从严格对齐过渡到重建与生成优化的平衡,有效突破了潜在空间可扩散性瓶颈。
- 该模型在公开基准测试中实现了业界领先的重建保真度,并在文本密集型文档场景中表现卓越。通过提出的OmniDoc-TokenBench评估及下游DiT实验,证实了相比现有高压缩基线模型,其收敛速度显著提升。
引言
潜在扩散模型依赖变分自编码器将图像压缩至潜在空间,但随着现代扩散Transformer的计算复杂度随token数量呈二次方增长,业界标准的八倍压缩会引发严重的计算瓶颈。向更高压缩比演进对于高效的原生高分辨率合成至关重要,然而现有方法始终在压缩效率、重建保真度与潜在空间可扩散性之间面临难以调和的权衡。更高的压缩率通常会损害细节,尤其是在文本密集的内容中;而通过扩展潜在通道进行补偿,往往会产生无序分布,导致扩散模型收敛停滞。为此,研究团队利用全局跳跃连接架构、专注于文档的定制化数据筛选,以及基于DINOv2特征的分阶段语义对齐策略来突破这些限制。该方法提供了领先的重建质量与快速的下游生成兼容性,有效解决了传统上压缩比、图像保真度与训练效率之间的权衡难题。
数据集
-
数据集构成与来源
- 研究团队构建了一个多源训练语料库,融合了数十亿张通用领域图像、精心筛选的真实世界文本密集型文档截图,以及一套合成文本渲染管线。
- 评估基准OmniDoc-TokenBench源自OmniDocBench文档解析数据集,包含约3,000张文本密集的文档图像,涵盖学术论文、幻灯片、教科书和财务报告等九个类别。
-
各子集关键细节
- 主训练语料库涵盖多样化的类别、分辨率与长宽比,并通过清晰度与模糊度过滤器剔除低质量样本,以去除边缘伪影与压缩噪声。
- 文本密集型真实世界子集应用OCR过滤器以优先保留高字符密度的样本,包含学术论文、演示幻灯片、海报及复杂网页的截图。
- 合成子集支持中英文文本,在5至20像素的多种粒度下渲染字符,并将文本叠加于随机采样的通用领域背景之上,以提升真实场景的泛化能力。
- 基准子集保持中英文分布均衡,严格限制字符数量,并剔除重复样本及视觉质量受损的样本。
-
数据使用与训练策略
- 研究团队使用经过过滤的真实世界与合成数据集训练VAE,确保模型能够学习高保真信号,并在不同压缩设置下捕捉细微的笔画细节。
- OmniDoc-TokenBench仅作为评估基准,不参与训练。
- 模型性能通过同时对原始图像与重建图像执行全页OCR,并计算归一化编辑距离(Normalized Edit Distance)来衡量,从而在不依赖词级边界框的情况下量化页面级文档的可读性。
-
处理与筛选管线
- 文本块从每份文档的左上角裁剪,并调整大小为256乘256像素,中文字体参考大小设为16像素,英文字体参考大小设为10像素。
- 内容筛选依赖PP-OCRv5,仅保留包含200至600个中文字符或300至600个英文字符的样本。
- 去重操作采用字符级n-gram重叠阈值,页内比较阈值为0.2,类别内比较阈值为0.3,重叠组中仅保留字符数最高的样本。
- 最后的人工审核步骤手动剔除模糊、视觉冗余或过度空白的样本,以确保基准质量。
方法
研究团队采用高压缩变分自编码器(VAE)框架,旨在同时实现高效的下游扩散建模与高重建保真度。整体架构遵循在激进的空间压缩下最大化潜在空间信息容量的原则。给定输入图像 I∈RH×W×3,VAE将其映射为潜在表示 z∈RfH×fW×C,其中 f 为空间压缩比,C 为通道维度。这使得下游扩散Transformer(DiT)的序列长度变为 L=HW/f2。为缓解DiT的二次方计算复杂度,研究团队采用了 f16 与 f32 的高压缩比,从而大幅降低训练成本。为抵消此类高压缩带来的固有信息损失,团队增加了通道维度 C,从而保持总信息瓶颈 N(z)=CHW/f2 不变。
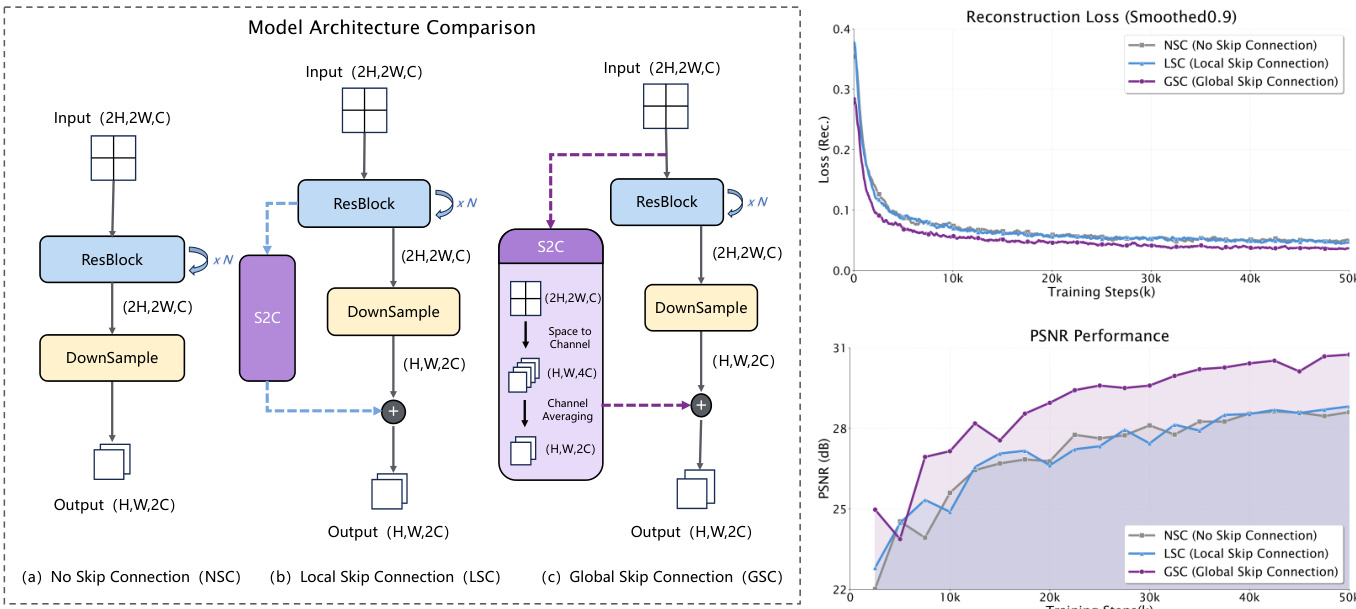
参考框架示意图,图中展示了核心架构创新。所解决的主要挑战是在激进下采样过程中保留细粒度细节。为此,研究团队引入了全局跳跃连接(GSC),这是一条绕过初始下采样层的残差路径。如图所示,该设计通过空间到通道(S2C)操作结合重排实现,有效将输入图像的空间信息折叠至通道维度,并直接输入至更深的潜在空间。该设计与无跳跃连接(NSC)及局部跳跃连接(LSC)配置形成对比,后两者在下采样过程中会导致信息丢失或仅局部保留。图中展示的消融研究表明,GSC显著加快了收敛速度并提升了重建性能,重建损失更低且PSNR值更高。
为优化计算效率,模型采用了无注意力骨干网络。对于序列长度为 N 的输入,自注意力的计算复杂度呈二次方增长,为 O(N2),而卷积的复杂度为 O(N⋅k2)。这种二次方缩放为高分辨率图像带来了严重的吞吐量与内存瓶颈。研究团队发现移除注意力模块并未导致显著的性能下降,因此采用了基于ResBlocks与下采样层的骨干网络,以确保可扩展性与训练效率。此外,该架构呈不对称设计:采用轻量级编码器以最小化编码开销并降低下游DiT的训练延迟,同时采用重量级解码器以确保高保真重建并保留复杂的图像细节。

训练流程设计简洁高效,专注于高保真重建与语义对齐。总训练损失 Ltotal 由像素级 L1 重建损失 Lrecon、感知损失 Llpips 以及语义对齐损失 Lalign 组合而成。研究团队移除了传统的Kullback-Leibler(KL)散度损失与对抗性GAN损失,以提升性能与训练稳定性。移除KL损失是因为其会限制潜在容量并与语义对齐目标产生竞争;而GAN损失在大规模训练中被认为并非必需,因为 Lrecon 与 Llpips 已足以生成清晰的重建结果。这一简化的目标函数优化了优化过程并加速了训练。训练策略采用多阶段方式,首先使用低分辨率图像以确保稳定收敛,随后逐步扩展至具有多样长宽比的2K分辨率。独立阶段整合真实文本密集型样本与合成文本数据以优化字符识别。最后,语义对齐从严格的初始阶段校准至平衡阶段,确保潜在空间既具备语义对齐能力,又能实现高质量像素级重建。
实验
评估框架结合了标准的像素级重建指标与一种新型OCR派生编辑距离度量,以严格评估高压缩基准下的视觉保真度与文本可读性。实验结果表明,所提架构在极端压缩条件下(此时竞品模型出现严重退化)仍能保持清晰的字符边界、准确的间距与细微笔画细节,性能显著优于现有模型。此外,下游扩散训练与大规模基础模型集成的验证表明,学习到的潜在空间保持了卓越的语义连贯性与结构稳定性,成功实现了高保真生成与复杂构图任务,且无需传统的性能妥协。
研究团队在不同压缩设置下评估了Qwen-Image-VAE-2.0的重建与扩散兼容性,并在标准基准上与现有基线模型进行对比。结果表明,Qwen-Image-VAE-2.0在像素级重建与文本保真度方面均达到业界领先水平,尤其在较高压缩比下表现突出,并为下游生成任务展示了更优的潜在空间可扩散性。在同等压缩级别下,该模型性能超越竞品,在文本保留与生成质量上取得显著提升。与同等压缩比下的基线模型相比,Qwen-Image-VAE-2.0实现了更优的文本保真度与重建质量,尤其在极端压缩设置下优势明显。该模型展现出强大的扩散兼容性,支持高质量图像生成,收敛速度更快且下游任务表现更佳。定性结果证实,即使在较高压缩级别下,Qwen-Image-VAE-2.0仍能保留细节与文本可读性,在视觉连贯性与语义一致性方面均优于现有方法。
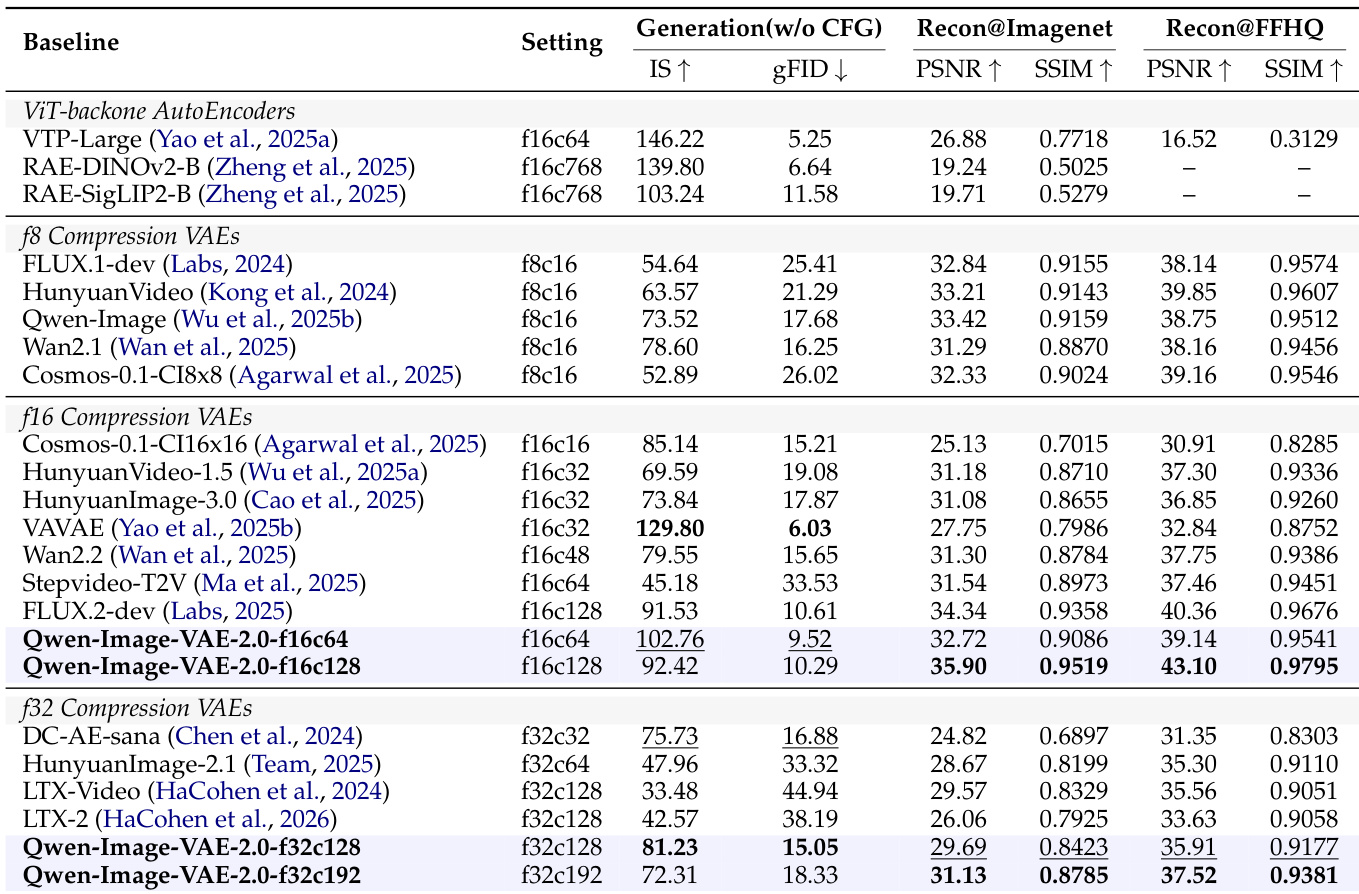
研究团队在不同压缩设置下评估了Qwen-Image-VAE-2.0的重建性能,并在标准基准上与多种基线模型进行对比。结果表明,Qwen-Image-VAE-2.0在像素级重建与文本保真度方面均达到业界领先水平,尤其在较高压缩比下,在SSIM、PSNR与NED等指标上优于现有方法。该模型在低压缩与高压缩设置下均实现了业界领先的重建保真度,超越了成熟的基线模型。在极端压缩条件下,模型展现出卓越的文本保真度,在竞品失效时仍能维持较高的NED分数。Qwen-Image-VAE-2.0表现出强大的扩散兼容性,支持高质量图像生成及大规模文本到图像合成。
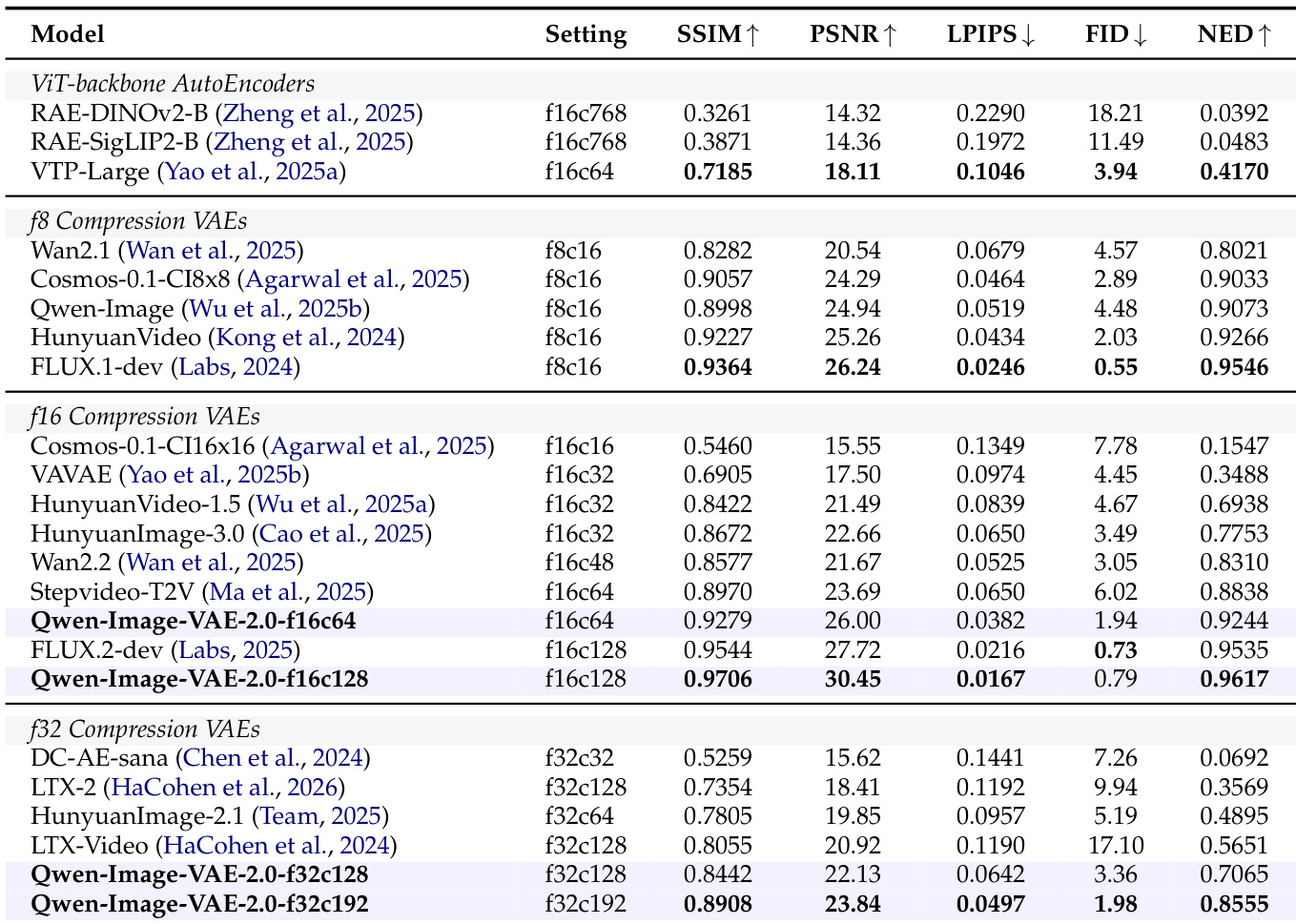
研究团队在标准基准上评估了Qwen-Image-VAE-2.0的重建性能,在各种压缩设置下均展现出业界领先的像素级保真度与文本保留能力。与现有基线相比,该模型性能更优,尤其在高压缩场景中表现突出,并在下游生成任务中展现出强大的潜在空间可扩散性。Qwen-Image-VAE-2.0在不同压缩层级中均实现了业界领先的重建保真度,在低压缩比与高压缩比下均优于现有方法。模型表现出卓越的文本保真度,即使在极端压缩条件下,通过NED指标衡量仍能保持极高的字符级准确率。学习到的潜在空间展现出强大的扩散兼容性,支持高质量图像生成,并满足大规模文本到图像系统中的复杂构图约束。

研究团队在标准基准上针对多种压缩设置评估了Qwen-Image-VAE-2.0,以检验其在下游生成任务中的重建保真度、文本保留能力与潜在空间可扩散性。与成熟基线模型的对比表明,该模型始终维持业界领先的性能,尤其在较高压缩比下,成功保留了精细的视觉细节并维持了极高的文本可读性。此外,学习到的潜在表示展现出强大的扩散兼容性,支持高质量图像合成,收敛速度更快,并能稳健处理大规模文本到图像管线中的复杂构图约束。