Command Palette
Search for a command to run...
MulTaBench:基于文本和图像的多模态表格学习基准测试
MulTaBench:基于文本和图像的多模态表格学习基准测试
摘要
标题:(无)摘要:表格基础模型(Tabular Foundation Models)最近通过利用预训练来学习数值和分类结构化数据的可泛化表示,在监督式表格学习中确立了最先进的水平。然而,它们缺乏对文本和图像等非结构化模态的原生支持,并依赖冻结的预训练嵌入来处理这些模态。在既定的多模态表格学习基准测试中,我们表明,对嵌入进行任务微调可以提升性能。然而,现有的基准测试往往仅关注模态的共现;这导致数据集间的高方差,并掩盖了任务特定微调带来的益处。为弥补这一空白,我们引入了 MulTaBench,这是一个包含 40 个数据集的基准测试,图像-表格任务和文本-表格任务各占一半。我们专注于那些模态提供互补预测信号、且通用嵌入会丢失关键信息的预测任务,这需要与任务对齐的、目标感知(Target-Aware)的表示。我们的实验结果表明,目标感知表示微调带来的增益在文本和图像模态、多种表格学习器、编码器规模以及嵌入维度上均具有泛化性。MulTaBench 构成了迄今为止规模最大的图像-表格基准测试工作,涵盖了医疗保健和电子商务等高影响力领域。它旨在促进研究结合联合建模和目标感知表示的新型架构,为开发新型多模态表格基础模型铺平道路。
一句话总结
MulTaBench 是一个包含 40 个数据集的基准测试,图像表格任务与文本表格任务各占一半。该基准测试展示了目标感知表示微调(target-aware representation tuning)如何通过将嵌入与互补的预测信号对齐,从而超越冻结的预训练嵌入。其性能提升在多种表格学习器、编码器规模和嵌入维度上均具有泛化能力,并覆盖了医疗与电子商务领域。
核心贡献
- MulTaBench:一个包含 40 个数据集的基准测试,图像表格任务与文本表格任务均匀分配。该基准测试通过聚焦于各模态提供互补信号的预测任务,解决了先前评估结果方差过高的问题,从而能够对目标感知微调进行严格评估。
- 目标感知表示(Target-Aware Representations):一种微调方法,通过将冻结的预训练嵌入适配至下游目标,而非依赖静态特征。该过程动态调整模型注意力至与任务相关的区域,恢复被通用嵌入丢弃的关键预测信息。
- 实验结果表明,目标感知微调在多种表格学习器、编码器规模和嵌入维度上均能稳定提升性能。这些发现证实,该适配策略在医疗与电子商务等高影响力领域的文本与图像模态中均能有效泛化。
引言
现代表格基础模型虽为结构化数据树立了新的性能标准,但本质上仍为单模态,依赖冻结嵌入来处理文本和图像等非结构化输入。这种静态方法在医疗与电子商务等高风险领域造成了显著瓶颈,因为通用表示往往会丢弃准确预测所需的细粒度、任务特定信号。现有基准测试进一步通过优先考虑数据集多样性而非预测必要性来阻碍进展,这掩盖了联合建模与目标感知微调的真正价值。为弥补这些不足,作者引入了 MulTaBench,这是一个经过精心筛选的 40 个数据集基准测试,严格筛选出模态间提供互补信息且需要目标感知表示微调的任务。其实验验证表明,将嵌入适配至特定预测目标的方法在多种架构下均稳定优于冻结基线,为开发下一代多模态表格基础模型确立了严格标准。
数据集
- 数据集构成与来源:作者推出了 MulTaBench,这是一个包含 40 个多模态表格数据集的基准测试,图像表格对与文本表格对各占一半。文本表格子集在去重后整合了来自四个知名公共基准测试的 56 个独立数据集。图像表格子集将源自学术文献的 16 个候选数据集与从 Kaggle 及公共仓库手动收集的数据集进行了合并。
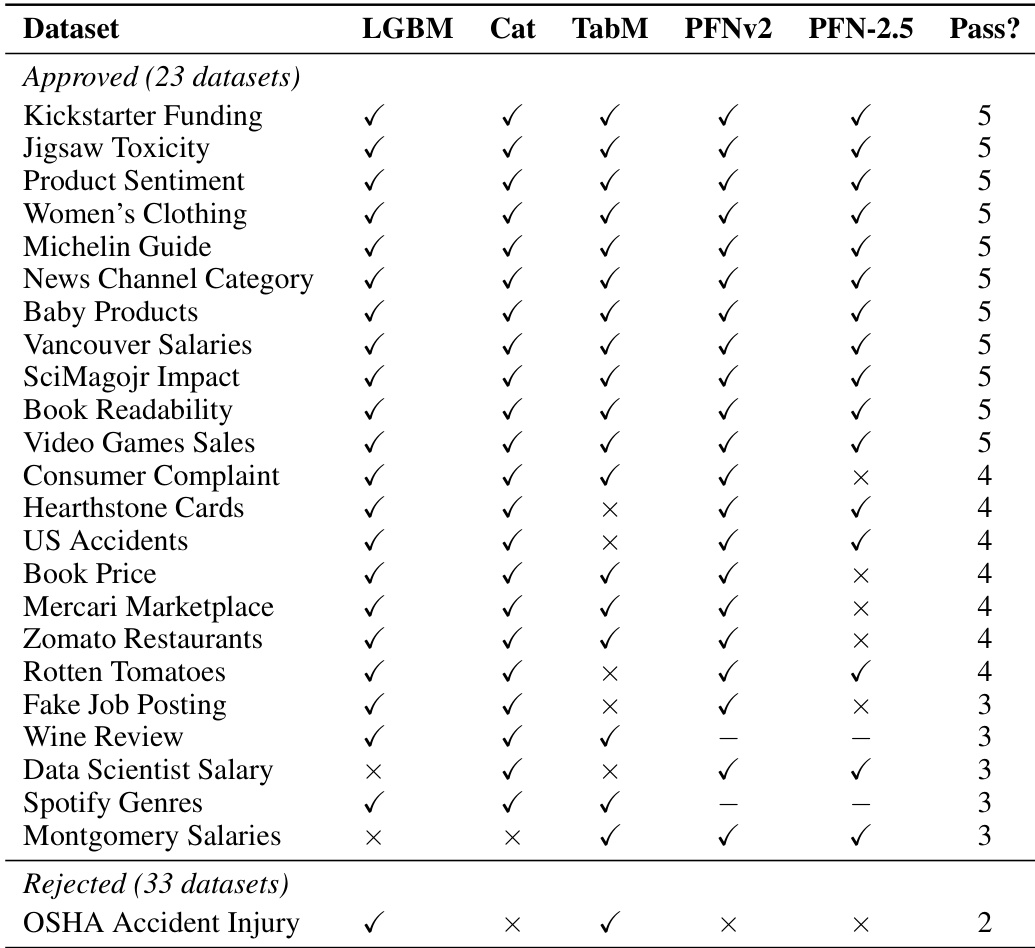
- 子集详情与过滤规则:数据集规模涵盖 400 至 114,000 行,包含 1 至 245 个结构化特征,在分类与回归目标之间保持平衡。作者实施了两部分筛选流程,要求满足“联合信号(Joint Signal)”,即每种模态必须提供独立的预测价值,以及“任务感知(Task-awareness)”,即细粒度的目标线索必须依赖表示微调而非通用编码器。约 41% 的文本表格候选集满足这两项标准,作者从中抽取 20 个以匹配图像子集的数量。16 个文献图像表格候选集中仅 5 个通过筛选,因此作者手动筛选了额外的 Kaggle 数据集以补齐最终的 20 个。
- 数据使用与处理:作者通过 Kaggle 发布该基准测试,采用统一的加载 API 标准化所有来源的数据摄入。他们利用该数据对目标感知表示与冻结嵌入进行基准测试,将 AUC 和 R² 指标归一化至 0 至 1 的尺度以进行跨任务评估,并报告 95% 置信区间。包含缺失或损坏图像的样本行将被直接删除而不进行插补,为每个条目提供多个图像列的数据集将被简化为单张图像。
- 裁剪策略与元数据构建:部分数据集依赖定向裁剪,包括乳腺肿块区域与病灶裁剪,以引导视觉编码器关注诊断相关区域。作者对基于价格的回归目标应用对数变换,并使用分位数分箱将连续值离散化为多类标签。为维持真正的多模态学习条件,移除了泄露目标变量或主导视觉信号的结构化列。文本特征要么保留为原始字符串,要么预嵌入为连续向量,同时采用扁平化的图像目录结构配合相对路径,确保训练期间元数据对齐的一致性。
方法
作者利用一个多阶段框架来整合表格学习任务中的结构化与非结构化特征,重点在于确保鲁棒且具备目标感知的表示。整体架构始于一个预处理步骤,该步骤适配预训练编码器以生成目标感知表示(TAR)。该适配过程通过低秩自适应(LoRA)微调编码器的最顶层三层来实现,并采用单个线性头将编码器输出(384 维)映射至输出类别数量。微调仅在训练集划分上进行,采用分层 90/10 的训练/验证划分来筛选最佳检查点,确保测试集数据无泄漏。对于 DINO-v3-small 和 e5-small-v2,LoRA 配置固定为:r=16,α=32,以及 0.1 的 dropout。训练采用 AdamW 优化器,e5 的学习率为 10−4,DINO 为 0.001,批量大小为 256,权重衰减为 0.01。DINO 的训练最多进行 100 个 epoch,而由于数据集中普遍存在多个文本特征,e5 的训练限制为 50 个 epoch。若验证损失连续三个 epoch 未改善则触发早停,所有超参数在数据集间保持恒定以避免针对单一数据集的微调。
对于回归任务,连续标签被离散化为 20 个等频分箱,适配目标为这些分箱上的交叉熵。与直接进行回归微调相比,该方法通过降低对异常值的敏感性来增强稳定性。在通常包含多个文本字段的文本表格数据集中,作者将至少包含 100 个不同值的字符串特征定义为文本列。为保持效率,单个 e5 模型将在所有这些文本列上进行联合微调。每个“行-列”对被视为格式为“col_name : col_val”的训练样本,并与该行的目标标签配对,使模型能够同时学习所有文本特征的共享表示。尽管随着特征规模增加该方法可能影响表示质量,但为每个特征微调专用的嵌入模型在计算上将是不可行的。
实验
评估采用四条件协议来筛选数据集,通过隔离单模态与联合表示,验证所选基准测试是否具备强多模态信号与任务感知特性。鲁棒性分析随后证实这些特性可泛化至多种表格学习器、更大规模的嵌入以及不同的降维设置中,表明目标感知表示始终能优于冻结基线。定性注意力图进一步揭示,该微调机制能有效将模型注意力重定向至语义相关特征。总体而言,实验确立表示适配作为多模态表格学习中可靠且必要的预处理步骤,其有效性独立于特定架构或嵌入容量。
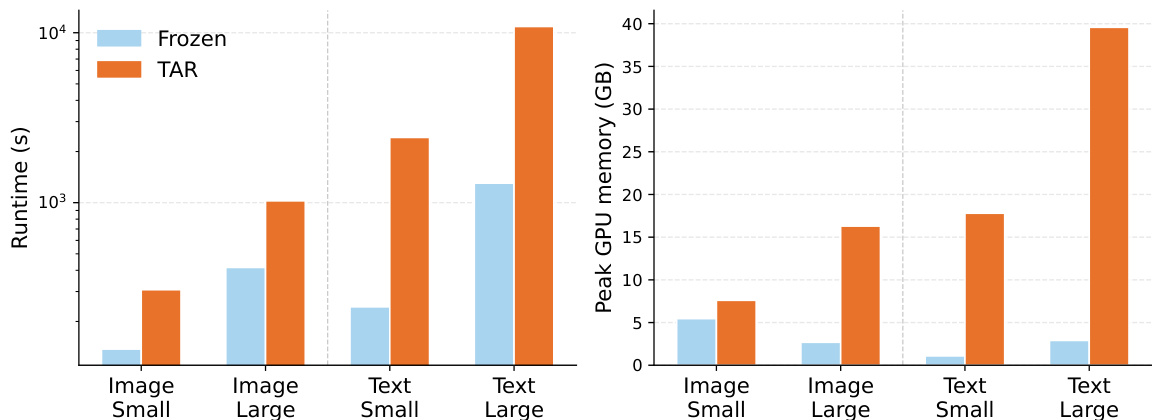
作者分析了目标感知表示微调(TAR)与冻结嵌入在不同模态及编码器规模下的计算成本。结果表明,TAR 显著增加了运行时间与 GPU 内存占用,其中基于文本的任务与更大的编码器导致计算需求大幅上升。成本增加主要归因于编码器的微调步骤。与冻结嵌入相比,目标感知表示微调会增加运行时间与 GPU 内存占用。无论冻结条件还是 TAR 条件,基于文本的任务均比基于图像的任务需要更多的计算资源。更大的编码器模型会导致运行时间与峰值 GPU 内存的计算成本显著上升,在 TAR 条件下尤为明显。
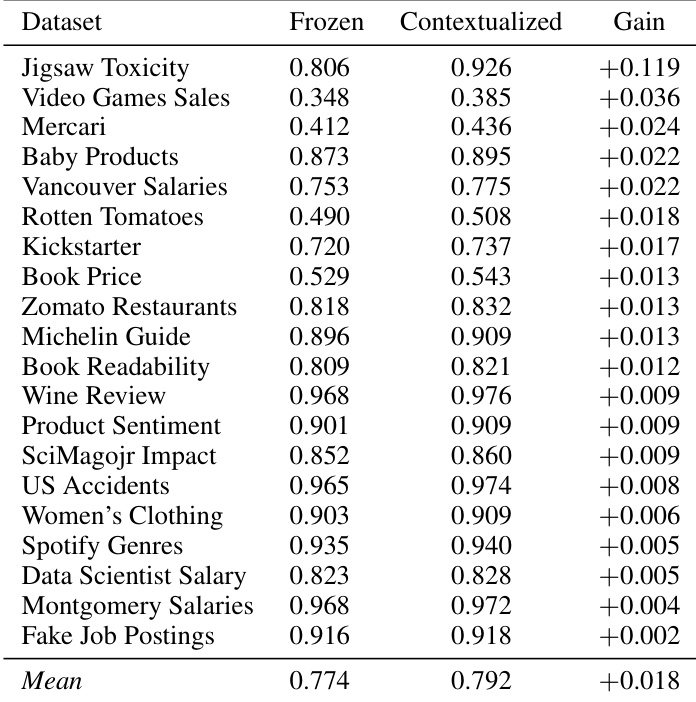
作者评估了表格模型在使用冻结表示与目标感知上下文表示时的性能。结果表明,上下文表示始终优于冻结表示,在不同模型与数据集中均观察到性能提升。所有数据集的平均提升幅度较小但为正值,表明目标感知微调具有普遍益处。上下文表示在所有数据集中均稳定优于冻结表示。目标感知微调带来的改进在多种模型与数据集中均有体现。上下文化带来的平均增益较小但为正,说明其具有普遍收益。
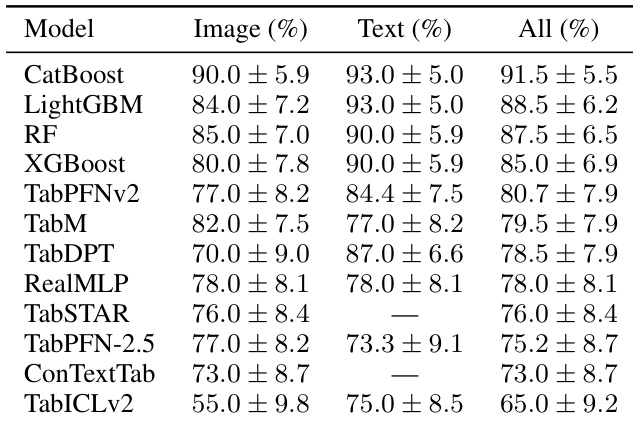
作者评估了多种表格模型在图像与文本模态下的表现,以检验目标感知表示微调的有效性。结果表明,与冻结表示相比,使用目标感知表示的模型始终能取得更高性能,且该提升在不同模型类型与模态中均有体现。性能提升具有鲁棒性,不依赖于特定模型架构或嵌入维度。目标感知表示在所有评估的模型与模态中均稳定优于冻结表示。目标感知微调带来的性能增益在不同模型架构中均有体现,包括传统模型与基于神经网络的模型。目标感知微调的收益对嵌入维度与模型规模的变化具有鲁棒性,表明其具备良好的泛化能力。
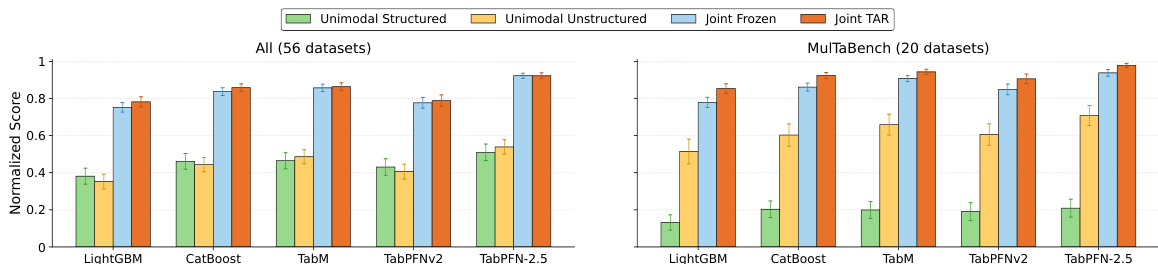
作者评估了该基准测试在多种表格学习器与实验条件下的表现,对比了有无目标感知表示微调的单模态与联合建模方法。结果表明,结合目标感知表示的联合建模方法始终优于其他配置,尤其是在经过筛选的数据集子集中,且该提升在不同模型类型与模态中均表现鲁棒。结合目标感知表示的联合建模在所有评估的模型与数据集中均稳定优于其他配置。与候选数据集全集相比,经过筛选的数据集子集展现出更强且更一致的性能排序。目标感知表示相较于冻结嵌入带来了显著改进,该提升在文本与图像模态及多种模型类型中均有体现。
作者在不同实验条件下使用多种表格学习器评估了一组数据集,以检验其适用于多模态任务的程度。评估聚焦于两项标准:联合信号与任务感知,数据集需至少在五种模型中的三种同时满足这两项标准方可通过。结果表明,部分数据集始终满足这些标准,而其他数据集则因多模态交互不足或缺乏目标感知表示微调的收益而未能通过。分析证实,所提出的筛选方法能有效识别出非结构化模态对表格预测具有实质贡献的数据集。筛选过程找出了同时满足联合信号与任务感知标准的数据集子集,表明其具备有意义的多模态交互及目标感知表示微调收益。绝大多数通过筛选标准的数据集在多种表格学习器中均得到一致验证,而被拒绝的数据集至少在一项标准上未达标。评估揭示,具备原生多模态支持的模型未必始终优于采用目标感知表示微调的模型,这凸显了筛选框架的重要性。
实验在多种表格学习器、模态与建模配置下,将目标感知表示微调与冻结嵌入进行对比,以评估计算效率、预测性能与数据集适用性。定性结果表明,尽管目标感知微调显著增加了计算开销,特别是在基于文本的任务与更大模型中,但它始终能在不同架构与模态中带来稳健的性能提升。利用这些上下文表示的联合建模方法展现出更优的预测能力,尤其是在应用于具备强多模态交互的筛选数据集时。总体而言,研究结果强调,将严谨的数据集筛选与目标感知微调相结合,能有效利用非结构化数据进行表格预测,其效果往往优于具备原生多模态架构的模型。