Command Palette
Search for a command to run...
LongLive-2.0:用于长视频生成的NVFP4并行基础设施
LongLive-2.0:用于长视频生成的NVFP4并行基础设施
摘要
我们提出了 LongLive-2.0,这是一种基于 NVFP4 的并行基础设施,贯穿长视频生成的完整训练和推理工作流程,旨在解决速度和内存瓶颈。在训练方面,我们引入了序列并行自回归(AR)训练,具体实现为 Balanced SP,它通过将每个 rank 上的干净历史时间块与噪声目标时间块配对,协同设计了高效的教师强制布局与 SP 执行,从而实现了具有 SP 感知分块 VAE 编码的自然教师强制掩码。结合 NVFP4 精度,它降低了 GPU 内存成本并加速了训练期间的 GEMM 计算,随着视频长度的增加,GEMM 计算的比例也随之增加。此外,我们表明,高质量的基础设施和数据集能够实现非常干净的训练流程。与现有的依赖 ODE 初始化和后续分布匹配蒸馏(DMD)的 Self-Forcing 系列方法不同,LongLive-2.0 直接将扩散模型微调为长程、多镜头、交互式自回归(AR)扩散模型。它还可以进一步转换为实时生成(4 到 2 个去噪步骤),并配备独立的 LoRA 权重。在 Blackwell GPU 上进行推理时,我们启用了 W4A4 NVFP4 推理,将 KV 缓存量化为 NVFP4 以节省内存,并通过异步流式 VAE 解码提升端到端吞吐量。在非 Blackwell GPU 架构上,我们部署了 SP 推理以匹配 Blackwell GPU 的速度,同时量化后的 KV 缓存可以降低 SP 的 GPU 间通信。实验表明,训练速度最高提升了 2.15 倍,推理速度提升了 1.84 倍。LongLive-2.0-5B 在基准测试中取得强劲性能的同时,实现了 45.7 FPS 的推理速度。据我们所知,LongLive-2.0 是首个用于长视频生成的 NVFP4 训练和推理系统。
一句话总结
LongLive-2.0 提出了一种基于 NVFP4 的并行基础设施,通过结合序列并行自回归训练与 W4A4 NVFP4 推理,直接将对流扩散模型转换为交互式自回归系统,无需 ODE 初始化或蒸馏,实现了最高 2.15 倍的训练加速和 1.84 倍的推理提速,并使 5B 参数变体达到 45.7 FPS 的处理速度。
核心贡献
- 本文提出 Balanced SP,一种序列并行自回归训练框架。该框架通过为每个计算节点配对干净历史与含噪目标的时序块,协同设计教师强制布局与并行执行流程。该架构支持感知序列并行的分块 VAE 编码,并直接将对流扩散模型微调为多镜头交互式自回归系统,无需依赖 ODE 初始化或分布匹配蒸馏。
- 系统构建了端到端的 W4A4 NVFP4 推理流水线,将 KV 缓存压缩至 NVFP4 格式,并集成异步流式 VAE 解码以最大化 Blackwell GPU 的吞吐量。该方法将序列并行推理扩展至非 Blackwell 架构,在降低 GPU 间通信开销的同时维持生成速度。
- 实验评估显示训练加速最高达 2.15 倍,推理提速最高达 1.84 倍,LongLive-2.0-5B 模型达到 45.7 FPS,并在多项标准基准测试中表现优异。该框架进一步结合独立的 LoRA 适配器,将训练模型转换为两至四个去噪步数,从而实现实时生成。
引言
因果自回归合成已成为流式长视频生成的标准方案,提供可扩展的逐帧生成能力并具备实时处理潜力。尽管在缓解暴露偏差与时间漂移方面取得进展,但现有方法在内存管理、缓存开销以及训练精度与部署效率之间的关键不匹配问题上仍面临持续瓶颈。虽然 FP4 等低位宽格式已成功用于压缩大语言模型,但在视频扩散领域仍缺乏充分验证。视频生成场景中的长时空序列、重复去噪周期以及不断增长的键值缓存,对精度对齐提出了严格要求。研究者利用统一的 NVFP4 量化框架解决上述瓶颈,同步稳定训练过程、实现权重与激活值的 4 位推理、压缩键值缓存存储空间,并简化长视频部署流程。
数据集

-
数据集构成与来源
- 研究团队从原始素材中构建大规模长视频数据集,用于训练 LongLive-2.0。
- 最终数据集包含 120,000 个视频,每个视频均被分割为独立镜头。
-
子集详情与分布
- 数据集均匀划分为三个时长组:16 至 32 秒、32 至 64 秒以及超过 64 秒,每类各占总量的三分之一。
-
筛选与质量控制
- 剔除镜头过短、包含标志或水印、文字突出、严重画面抖动、播放速度异常、曝光问题、模糊以及包含静止帧或微缩放低动态片段。
- 使用 MANIQA 指标评估视觉质量,根据采样帧的平均得分确定整体评级,仅保留排名最高的视频。
-
元数据构建与处理
- 为每个镜头生成结构化描述,涵盖视觉元素、场景背景、人物、动作及运镜手法。
- 合并单视频内所有镜头的描述文本并加以优化,确保连续帧与场景间的时间连贯性与逻辑一致性。
-
模型应用
- 构建的数据集作为 LongLive-2.0 的核心训练资源,研究团队利用镜头级标注与时间对齐的长文本描述以优化模型性能。
方法
LongLive-2.0 框架提出了一种专为高效长视频生成设计的协同基础设施,将新型训练方法与并行推理系统深度融合。训练流程的核心为序列并行自回归(AR)训练,具体实现为 Balanced SP。该方法协同设计数据布局与序列并行执行流程,以解决内存与计算瓶颈。此方案确保每个 GPU 计算节点负责同一时序块中的干净与含噪潜在 token,在设备间均衡损失计算负载,并自然生成教师强制注意力掩码。该配对布局一致应用于 VAE 编码、潜在空间构建与损失计算环节,消除了重复 VAE 预处理的需求,并确保序列分片与 DiT 注意力机制保持对齐。NVFP4 精度进一步加速训练过程,降低显存占用并提升 GEMM 运算速度,视频时长增加时效果尤为显著。研究团队基于此基础设施,直接将对流扩散模型微调为长程交互式多镜头 AR 模型,规避了现有方法复杂的多阶段流程。最终模型可结合独立 LoRA 权重转换为少步数去噪的实时生成模式,该权重通过简化的 DMD 蒸馏过程获得,仅优化 LoRA 适配器。

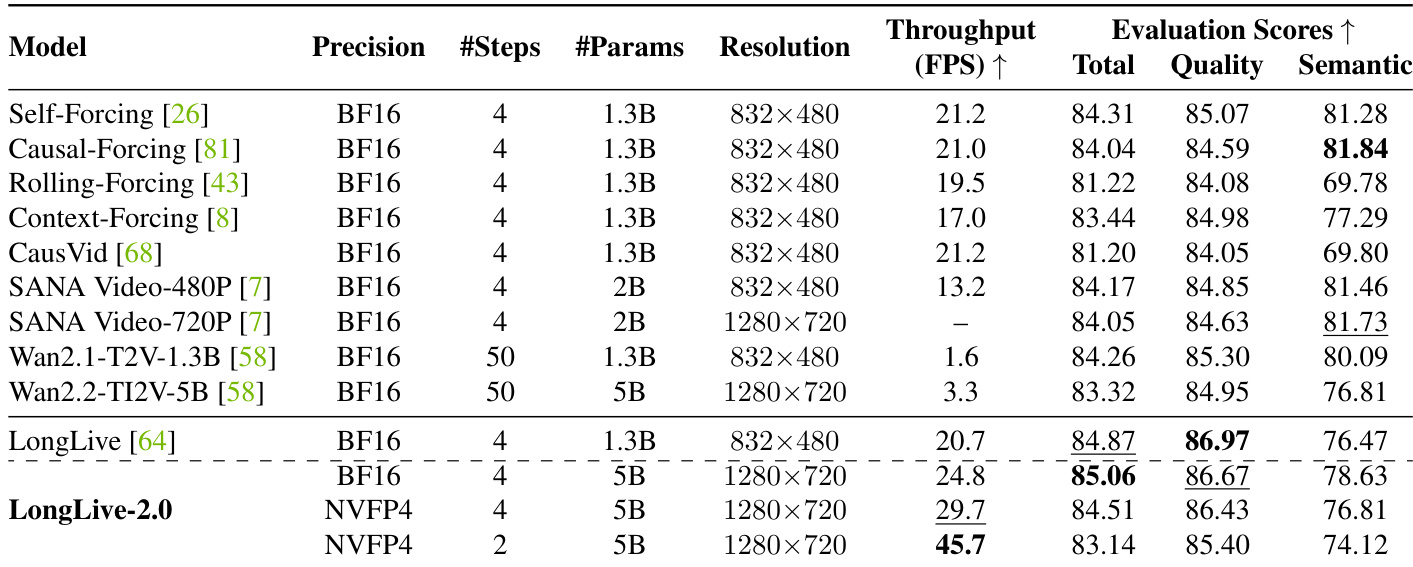
在推理阶段,LongLive-2.0 采用多维度策略以实现高吞吐量与低延迟。在 Blackwell GPU 上,系统支持 W4A4 NVFP4 推理,将模型权重与键值(KV)缓存量化至 NVFP4 格式,显著降低显存占用并加速计算。KV 缓存以帧块为单位进行量化,每个块包含八帧,并采用定制化的并行 CUDA 反量化内核重建缓存,以支持高效的窗口内注意力计算。为进一步提升吞吐量,框架实现异步流式 VAE 解码。该异构流水线专设一块 GPU 负责 VAE 解码,与 DiT 推理集群并行运行,有效将解码延迟掩盖于主导的 DiT 去噪步骤之后。此设计降低端到端延迟,实现显存高效的流式生成。针对非 Blackwell GPU 架构,LongLive-2.0 部署序列并行推理以匹配 Blackwell GPU 的速度,量化后的 KV 缓存有效降低 GPU 间通信开销。系统还引入多镜头注意力汇聚机制,以维持多镜头生成过程中的连贯性。该机制采用两组协同锚点:全局汇聚节点用于保持整段视频的主体一致性,镜头级汇聚节点用于维持单镜头内的局部连贯性。此设计与分块交互式提示接口无缝集成,支持分钟级交互生成且无需冗余重计算。整体架构旨在最大化端到端生成速度,该指标较单纯依赖扩散模型 FPS 更具实际意义,通过最小化低位宽 KV 计算开销并将 VAE 解码与模型去噪重叠,实现性能优化。
实验
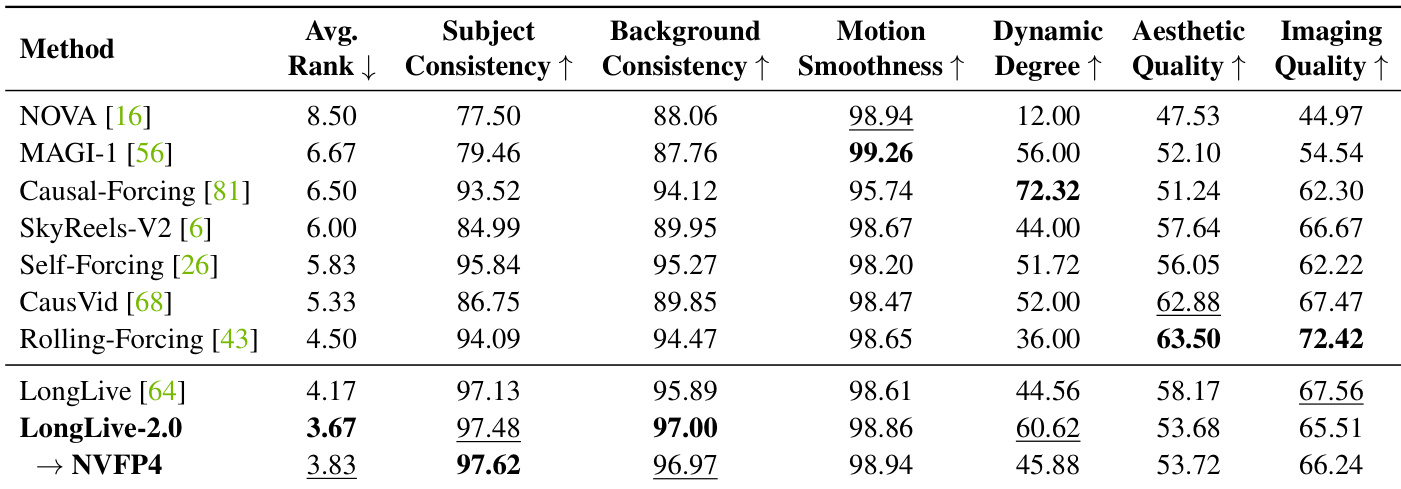
评估方案全面考察训练与推理效率、短长视频的生成质量,以及关键架构与精度设计选择的影响。实验验证了平衡序列并行与 NVFP4 量化相结合可显著降低显存占用并加速训练,同时保持视觉保真度。定性消融实验进一步证实,多镜头注意力机制有效防止时间漂移,在长序列中维持主体一致性,而量化精度的预训练策略避免了后训练转换带来的细节退化。综合结果表明,优化后的框架支持高吞吐量、实时视频生成,具备强长程稳定性与极低的质量损失。
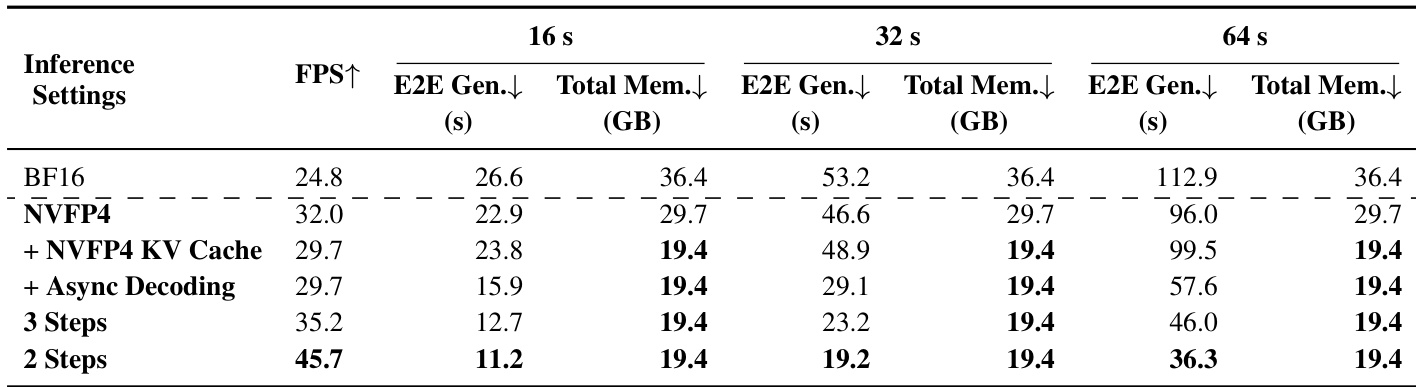
研究团队在不同设置下评估推理效率,对比各视频长度下的帧率、端到端生成时间与显存占用等性能指标。结果表明,减少去噪步数并结合 NVFP4、KV 缓存与异步解码可提升吞吐量并降低延迟,同时保持显存占用稳定。减少去噪步数显著提升推理速度,两阶段设置达到最高帧率。结合 KV 缓存与异步解码的 NVFP4 方案在维持低显存占用的同时,大幅缩短端到端生成时间。两阶段配置在所有视频长度下均实现最快推理速度与最低端到端延迟。
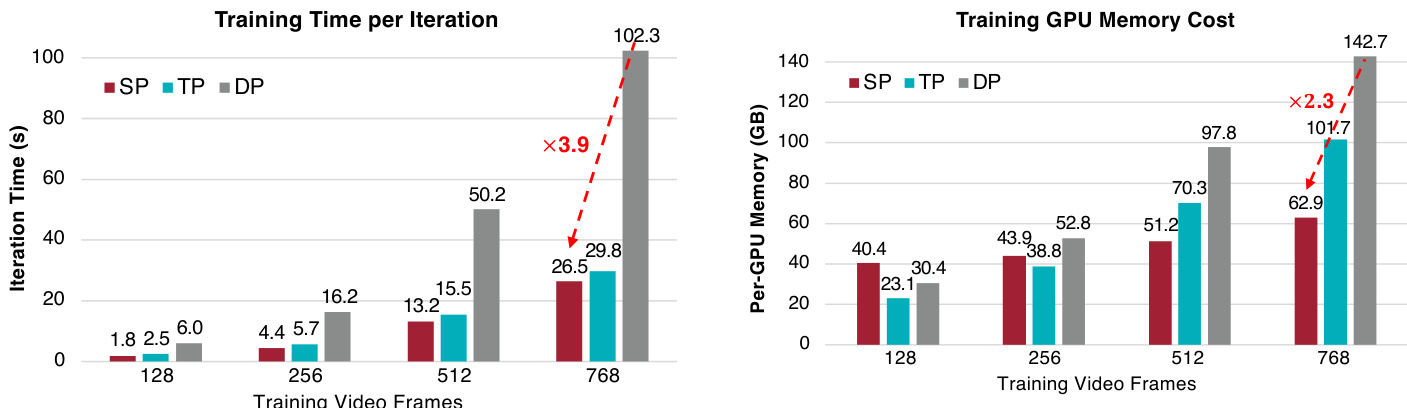
研究团队通过对比不同并行策略与精度设置分析训练效率,表明序列并行支持更长视频的训练,且与 NVFP4 量化结合可大幅缩减迭代时间与显存占用。结果证实,所提方法在各类视频长度下均提升可扩展性与效率,长序列场景增益最为显著。相较于基线方法,序列并行通过降低显存占用与迭代时间支持更长视频训练。NVFP4 量化与平衡序列并行的结合实现最快训练迭代速度与最低显存成本。所提方法在最长视频长度下展现出最高效的效率提升,时间与显存需求均大幅降低。
研究团队评估视频生成模型的不同精度配置,重点关注显存占用与运行效率。结果表明,相较于 BF16,NVFP4 结合 LoRA 显著降低峰值显存占用,最终配置提升幅度最大。显存缩减比例显示,NVFP4+LoRA 方案较基线具有明确的效率优势。相较于 BF16 与 NVFP4 配置,NVFP4+LoRA 有效降低峰值显存占用。NVFP4 与 LoRA 的组合在测试方案中实现最低显存占用。显存缩减比例较基线配置呈现显著提升。
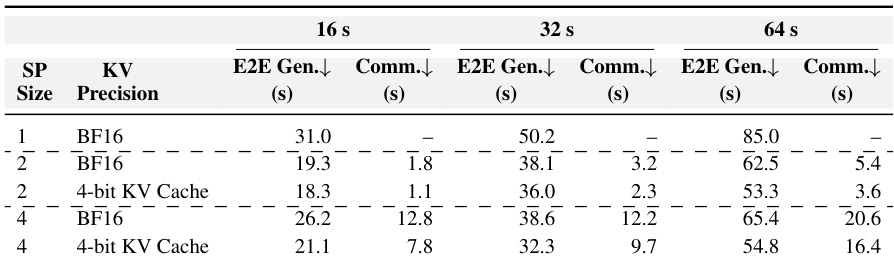
研究团队围绕训练与推理效率开展系列消融实验,聚焦序列并行、量化与 KV 缓存压缩技术。结果表明,结合上述技术可显著缩短端到端生成时间与显存占用,尤其在长序列场景下表现突出,同时保持或提升生成质量。所提方法支持高效高分辨率视频生成,降低延迟与显存需求。序列并行结合量化与 KV 缓存压缩技术,在不同序列长度下均缩减端到端生成时间与显存占用。NVFP4 量化与 KV 缓存压缩的融合在几乎不增加延迟成本的前提下,大幅提升推理效率。所提方法在长视频生成任务中表现强劲,较基线展现出更优的一致性与质量。
研究团队对比视频生成模型的不同精度配置,侧重训练与推理效率。结果表明,采用预训练量化 NVFP4 可在降低显存占用并提升速度的同时保持高质量,结合少步数去噪效果尤为明显。预训练量化 NVFP4 实现高质量与高效率,在匹配 BF16 性能的同时减少显存占用。减少去噪步数显著提升推理速度,支持实时视频生成。预训练 NVFP4 在保留视觉细节与维持质量方面优于后训练量化方案。

研究团队通过系统测试精度配置、序列并行与解码优化,评估不同视频长度下的推理与训练效率。实验证实,将 NVFP4 量化与序列并行、KV 缓存压缩及减少去噪步数相结合,可大幅加速模型执行并显著降低显存消耗。组合方案支持可扩展的高分辨率视频生成,在延迟极低且视觉质量不受损的前提下,为长序列任务提供持续的性能优势。