Command Palette
Search for a command to run...
智能体驱动的网络架构发现:AIRA-Compose 与 AIRA-Design
智能体驱动的网络架构发现:AIRA-Compose 与 AIRA-Design
Alberto Pepe Chien-Yu Lin Despoina Magka Bilge Acun Yannan Nellie Wu Anton Protopopov Carole-Jean Wu Yoram Bachrach
摘要
为实现递归式自我改进迈出关键一步,我们深入探究了大语言模型(LLM)智能体在标准 Transformer 范式之外,自主设计基础模型的能力。为此,我们提出了一种双框架方法:AIRA-Compose 用于高层架构搜索,AIRA-Design 用于底层机制实现。在计算资源固定为 24 小时的约束下,AIRA-Compose 部署了一个由 11 个智能体组成的集成系统,以探索由基本计算原语(如 Attention、MLP、Mamba)构成的组合设计空间。该系统分两个阶段运行:智能体首先在百万参数量级上迭代地设计和评估候选模型,随后将表现最优的设计拓展至 3.5 亿、10 亿和 30 亿参数规模。此次搜索产生了 14 种全新的架构,涵盖两个家族:AIRAformers(基于 Transformer)和 AIRAhybrids(基于 Transformer-Mamba 混合架构)。在固定 Token 预算下以 10 亿参数规模进行预训练时,由智能体发现的表现最优的架构 consistently(持续)优于 Llama 3.2 以及通过 Composer 搜索得到的替代方案。在下游任务中,AIRAformer-D 和 AIRAhybrid-D 的准确率分别比 Llama 3.2 高出 2.4% 和 3.8%。此外,AIRA-Compose 还发现了一些能够达到更陡峭、更高效的最优计算扩展前沿的新颖模型架构。具体而言,AIRAformer-C 的扩展速度比 Llama 3.2 快 54%,比 Composer 找到的最佳 Transformer 架构快 71%;而 AIRAhybrid-C 的扩展速度分别比改进版的 Nemotron-2 和 Composer 找到的最佳混合架构快 23% 和 37%。AIRA-Design 任务则分配给多达 20 个智能体,使其直接编写新颖的注意力机制以处理长距离依赖关系,并实现高性能的训练脚本。在 Long Range Arena (LRA) 基准测试中,表现最佳的由智能体设计的架构,在文档匹配任务上的准确率仅比人类最新成果低 2.3%,在文本分类任务上仅低 2.6%。在 Autoresearch 基准测试中,Greedy Opus 4.5 在固定时间预算下优化训练过程,达到了 0.968 的验证集 bits-per-byte 指标,超越了已公布的最低参考值。综上所述,AIRA-Compose 和 AIRA-Design 共同证明,AI 研究智能体能够自主发现混合架构和算法优化方案,其性能可与人工设计的基线模型相媲美甚至超越。这为发现下一代基础模型建立了一个灵活且强大的范式,也是迈向递归式自我改进的重要一步。
一句话总结
本工作介绍了 AIRA-Compose 和 AIRA-Design,这是一个双框架,其中 LLM agent 自主设计超越标准 Transformer 的基础模型。AIRA-Compose 部署 11 个 agent 生成 AIRAformer 和 AIRAhybrid 架构,在准确率上超越 Llama 3.2 达 2.4% 和 3.8%,扩展速度快达 Llama 3.2 的 54%。AIRA-Design 采用多达 20 个 agent 实现新机制,在 Long Range Arena 基准上达到人类最先进水平 2.6% 以内,并在 Autoresearch 基准上实现 0.968 验证每字节比特数,确立了递归自我改进的灵活范式。
核心贡献
- 本工作介绍了一种双框架方法,包括用于高层架构搜索的 AIRA-Compose 和用于底层机制实现的 AIRA-Design。该系统部署 agent 集合,在固定的计算预算下探索计算原语的组合设计空间。
- Agent 发现的架构在固定 token 预算下的 1B 规模预训练时,始终优于 Llama 3.2 和 Composer 发现的替代方案。特定模型将下游准确率提高多达 3.8%,并且扩展速度显著快于标准基线。
- AIRA-Design 组件任务 agent 编写新的注意力机制并实现用于评估的高性能训练脚本。在 Long Range Arena 和 Autoresearch 基准上,这些 agent 设计的系统实现了接近最先进水平的准确率,并分别超越了已发布的最低参考每字节比特数。
引言
当前基础模型主要依赖 Transformer 架构,但其二次复杂度为长上下文处理和推理效率带来了瓶颈。虽然社区正转向结合不同计算原语的混合模型,但人工探索无法有效导航巨大的组合空间,传统搜索方法在计算上仍然不可行。本工作利用由 AIRA-Compose 和 AIRA-Design 组成的双框架方法,使 LLM agent 能够自主发现并实现这些下一代架构。该系统成功识别出优于 Llama 3.2 等人工工程基线的新型混合设计,同时确立了更高效的计算最优扩展前沿。
数据集
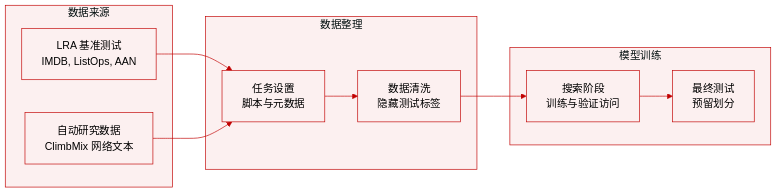
-
数据集组成与来源
- 本工作引入了 12 个 RSI 任务,分为 AIRA-Compose 和 AIRA-Design 类别,基于 AIRS-BENCH 框架,其中任务由问题、数据集和指标三元组定义。
- 两个主要基准推动评估:用于底层机制设计的 Long Range Arena (LRA) 和用于优化训练脚本的 Autoresearch。
-
每个子集的关键细节
- LRA 任务采用三个基于文本的数据集:用于情感分类的 IMDB,用于分层数学表达式的 ListOps,以及用于文档检索的 ACL Anthology Network。
- Autoresearch 利用来自 ClimbMix 语料库的预 tokenized 网络文本,搭配包含约 8192 个词汇项的预训练 BPE tokenizer。
- Autoresearch 的文献增强版本包括 41 篇研究论文的结构化摘要和 14 个按主题组织的参考代码仓库。
-
模型使用与训练划分
- Agent 在搜索阶段访问训练和验证划分,以使用贪婪或 One-Shot 脚手架评估假设。
- 最终性能在保留的测试划分上进行评估,该划分在搜索过程中不可访问,以确保公平性。
- Autoresearch 指标为验证每字节比特数,在单个 GPU 上固定的 5 分钟挂钟训练预算内计算。
-
处理与元数据构建
- 标准化任务目录包括用于数据清理的准备脚本和封装完整训练管道的隔离评分脚本。
- 元数据文件定义任务约束和评估指标,同时确保在解决方案构建期间隐藏测试标签。
- 文献变体将资源组织在专用的 pwc/ 文件夹内的架构改进、训练策略和优化器中。
方法
AIRA-Compose 流程将 Composer 框架重铸为等效的 AIRS-Bench 任务,以自动化混合基础模型的发现。该过程遵循四步方法:搜索、评估、聚合和外推。系统不依赖严格的贝叶斯优化,而是利用 agent 自由制定结构假设并提出新的原语排列。
参考框架图以了解整体工作流程,其中数据、计算原语和代码库馈入 AIRS-Bench 任务。

搜索引擎由充当 harness 内 agent 的大型语言模型 (LLM) 驱动,该 harness 包括用于 One-Shot 或贪婪执行的脚手架。Agent 的任务是使用预定义的计算原语组装 16 层小规模架构,例如 MLPs (M)、多头 Attention (mA) 和 Mamba SSM (Mb)。两个原语配置的搜索空间跨越 216=65,536 种可能的排列,而三个原语空间扩展到约 4300 万种组合。
本工作利用贪婪树搜索方法,其中 agent 迭代探索架构空间。如下图所示,agent 起草初始解决方案并根据验证分数进行细化。
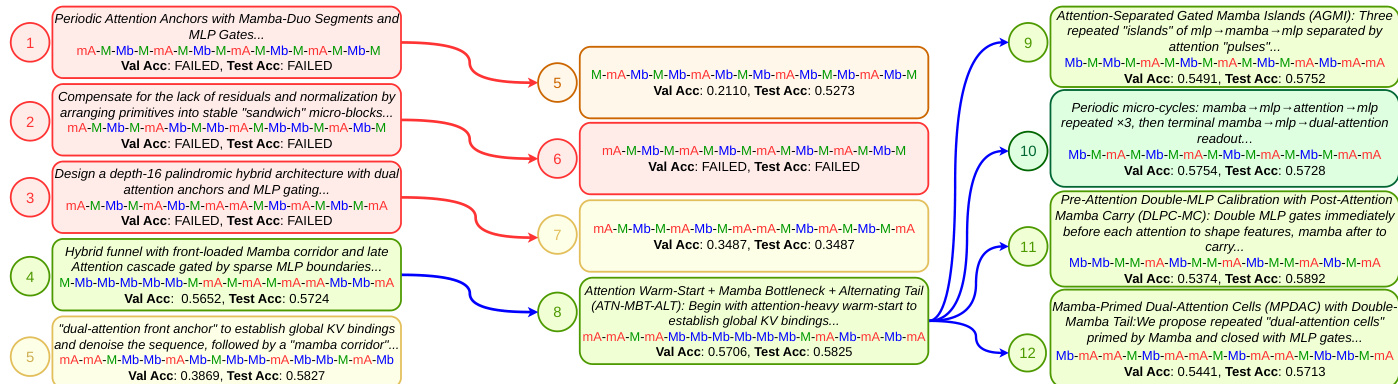
在搜索树的每个节点,agent 阐述设计选择,生成候选架构文件,并编写评估脚本。提交的架构在代理数据集(包括 MAD、BabiStories 和 DCLM)上从头开始训练。选择具有最高验证分数的节点,通过改进操作进行进一步探索,允许 agent 利用领域知识有意义地导航组合空间。图中的红色箭头表示调试操作,蓝色箭头表示改进操作,这些操作根据父节点的推理和分数提出新架构。
一旦 agent 探索结束,流程进入聚合和外推。聚合器收集所有 agent 提交的架构及其测试分数。它采用逐层聚类技术,例如 k-means,以选择聚类中最频繁的计算原语。此过程平滑了代理训练中的噪声和过拟合,以获得鲁棒的小规模架构。应用了不同的聚合策略,包括 N0、N1 和 N2 聚合,它们根据排名或聚类成员资格对架构进行加权。
最后,外推器将聚合的小规模架构扩展到 350M、1B 或 3B 的目标参数计数。这种扩展通过拉伸实现,即按比例扩展连续块,或通过堆叠实现,即按顺序重复整个发现的架构。在小规模下,所有原语共享模型维度 d=128,而大规模配置根据 IsoFLOP 方法调整模型维度、注意力头数和隐藏维度。生成的架构利用 SwiGLU 变体用于 MLP,以及分组查询注意力用于注意力块,以确保大规模效率。
实验
本研究评估 AI agent 在架构搜索和训练设计任务上的表现,使用 One-Shot 和贪婪脚手架,基准包括 MAD、Long Range Arena 和 Autoresearch。AIRA-Compose 中的实验表明,agent 可以发现新型神经网络架构,在验证损失和下游性能方面优于既定基线,平衡设计显示出更好的计算效率。在 AIRA-Design 任务中,贪婪 agent 在机制挑战上达到了接近人类领先性能水平的峰值准确率,并优化了训练循环以超越参考基线,尽管它们主要重新组合现有技术而非生成根本性的科学创新。总体而言,结果表明 agent 驱动的搜索是生成竞争性基础模型组件的可行方法,突出了工程合成的优势,同时指出了真正算法发现的局限性。
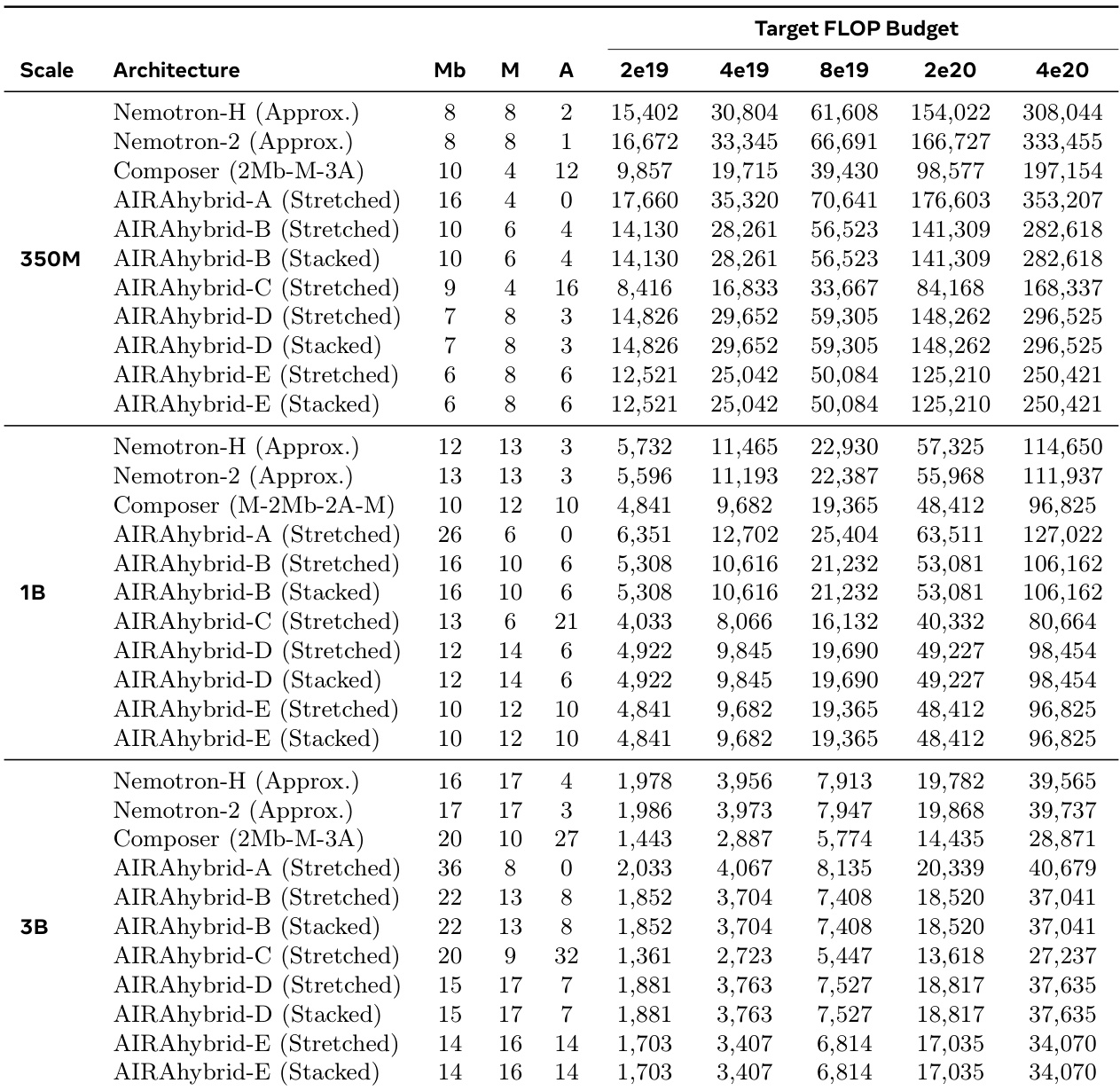
该表展示了在不同参数规模下,各种混合架构在五个不同 FLOP 预算下可实现的训练步骤数量。数据显示,随着模型规模增加,在固定计算预算下可行的训练步骤数量减少。此外,架构组成显著影响计算效率,其中具有更高注意力层数的设计相比 Mamba 主导或平衡替代方案导致更少的训练步骤。增加模型规模减少了固定 FLOP 预算下可用的训练步骤总数。具有更高比例注意力层的架构比由 Mamba 或 MLP 层主导的架构允许更少的训练迭代。同一基础架构配置的堆叠和拉伸变体在所有测试预算下产生相同的训练步骤计数。
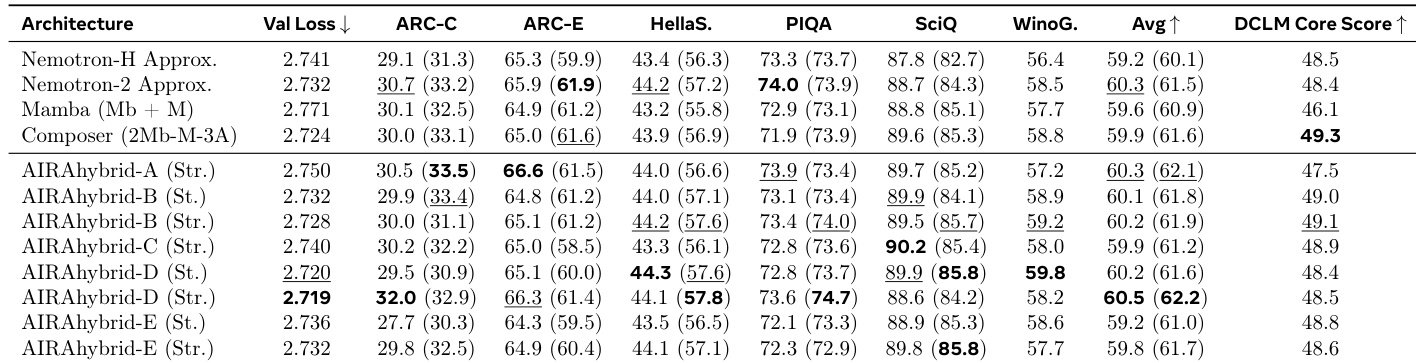
本工作在 1B 参数规模下评估 3 原语混合架构,对比包括 Mamba 和 Composer 在内的既定基线。Agent 发现的 AIRAhybrid-D (Stretched) 变体表现出最强的整体性能,实现了最低的验证损失和下游任务中最高的平均准确率。虽然 Composer 基线确保了最高的 DCLM Core Score,但 AIRAhybrid 模型在语言和推理基准上通常优于 Mamba 和 Nemotron 基线。AIRAhybrid-D (Stretched) 在所有测试架构中实现了最低的验证损失和最高的平均 0-shot 准确率。Composer 基线确保了最高的 DCLM Core Score,在此特定指标上优于 agent 发现的变体。AIRAhybrid 模型与 Mamba 和近似 Nemotron-2 等基线相比,通常保持更高的平均准确率。
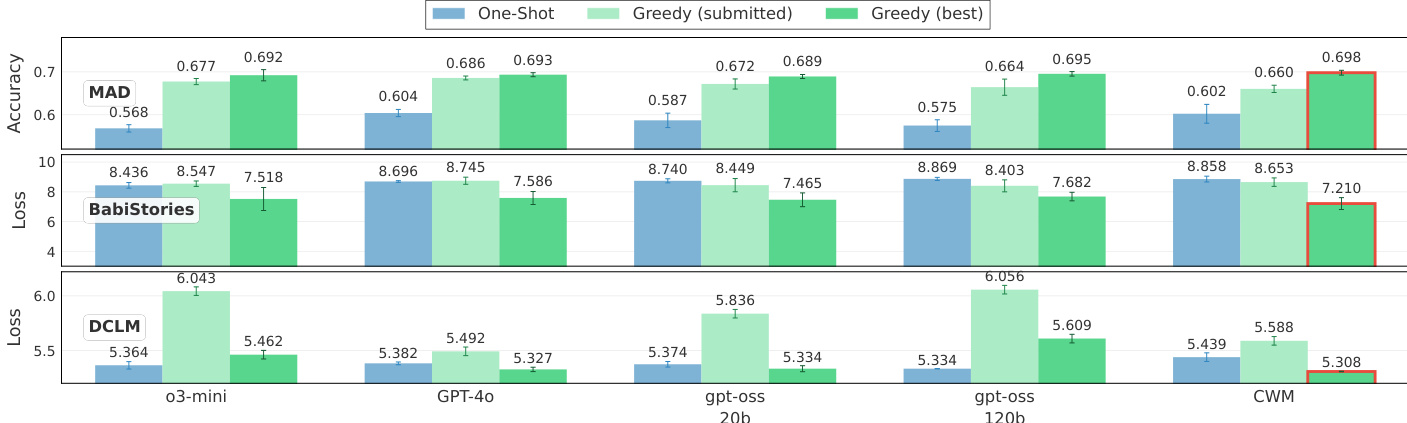
本工作在 MAD、BabiStories 和 DCLM 数据集上使用 2 原语架构搜索任务评估 LLM agent。结果比较了 One-Shot 生成与 Greedy 搜索,区分了最终提交的解决方案和探索过程中发现的最佳解决方案。在所有数据集上,Greedy 搜索始终优于 One-Shot 生成,并且发现的最佳解决方案通常在准确率或损失方面优于提交的解决方案。Greedy 搜索脚手架在所有三个数据集上始终产生比 One-Shot 生成更好的性能。搜索过程中发现的最佳解决方案通常优于 agent 提交的最终解决方案。CWM agent 在 MAD 数据集上实现了最高准确率,在 BabiStories 和 DCLM 上实现了最低损失,在评估的模型中。
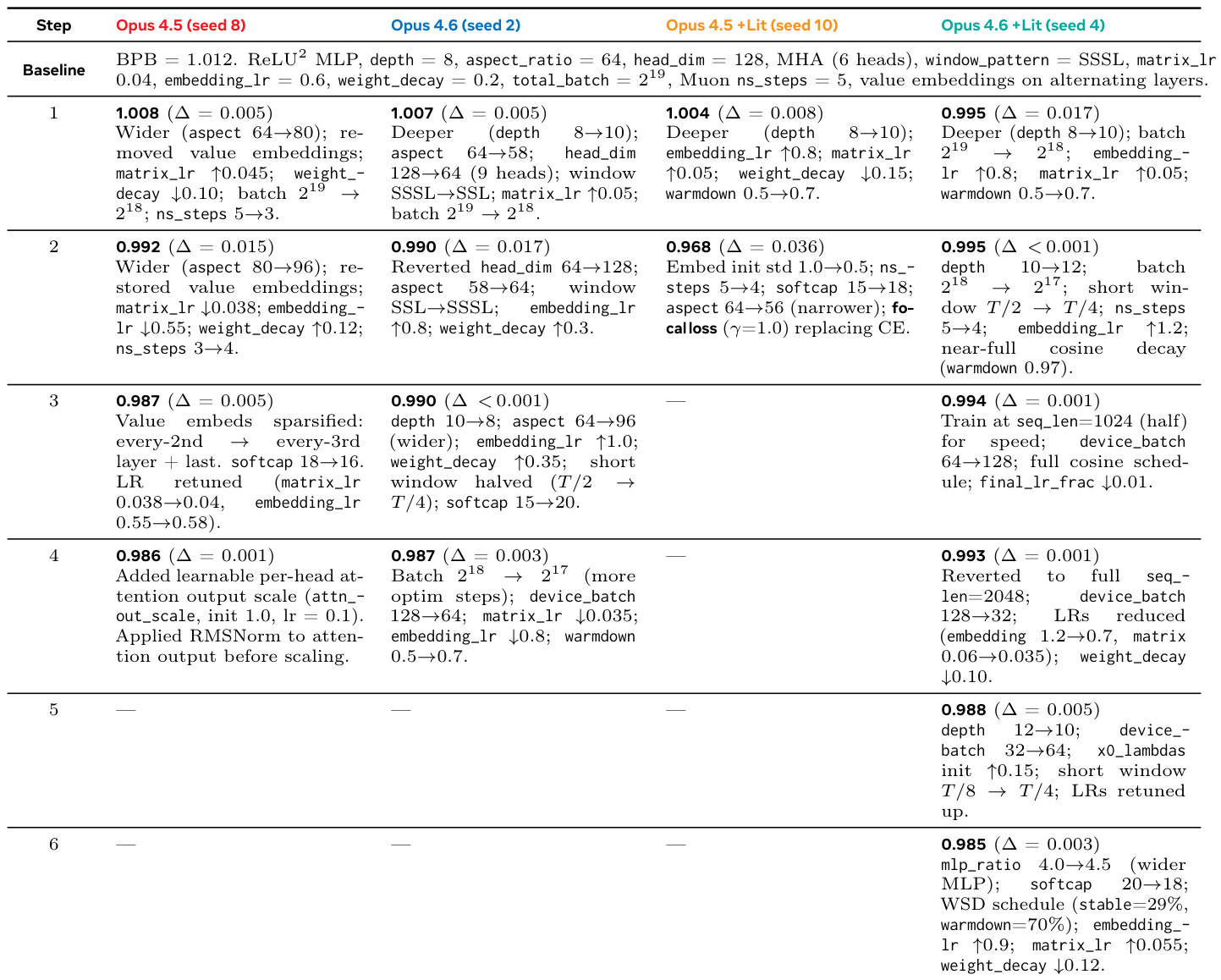
该表详细说明了不同 agent 变体在 Autoresearch 任务上采取的迭代优化步骤,跟踪相对于基线的验证损失改进。本工作表明,agent 通过一系列架构更改和超参数调整成功降低损失,性能根据模型能力和文献访问权限而变化。具有文献访问权限的 Opus 4.6 变体在经过多次迭代步骤调整深度、批量大小和学习率后,实现了最佳最终验证性能。文献增强的 Opus 4.5 agent 通过引入 focal loss 替换标准交叉熵目标,实现了最大的单步增益。优化策略在不同模型家族之间分化,Opus 4.5 专注于架构加宽和值嵌入稀疏化,而 Opus 4.6 强调深度更改和优化器步骤增加。
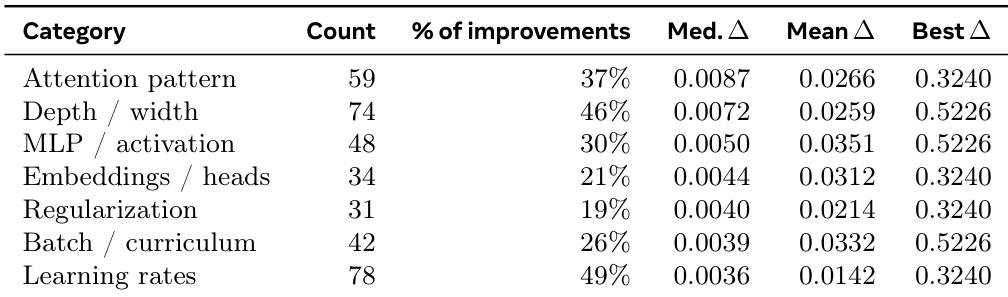
该表分类了在 Autoresearch 任务期间导致性能提升的架构和超参数修改。它表明,虽然学习率和深度调整是最常见的改进来源,但注意力模式的更改产生了最高的中位单步增益。学习率修改是最频繁的改进驱动因素,出现在近一半的成功优化步骤中。注意力模式的调整产生了最高的中位性能增益,在典型的逐步进展中优于其他类别。模型深度、宽度和 MLP 激活的更改实现了最大的单步性能跳跃,共享了最高的最大改进值。
实验评估了混合架构和 LLM agent 在各种参数规模、FLOP 预算和搜索任务上的表现,以评估计算效率和模型性能。结果表明,虽然较大模型在固定预算下需要较少的训练步骤,但 agent 发现的混合变体在下游任务上通常优于 Mamba 和 Composer 等既定基线。此外,agent 的迭代优化表明,贪婪搜索策略产生比 One-Shot 生成更优越的解决方案,注意力模式修改在搜索过程中提供了最高的中位性能增益。