Command Palette
Search for a command to run...
DexJoCo:面向 MuJoCo 上手操作的任务导向基准与工具包
DexJoCo:面向 MuJoCo 上手操作的任务导向基准与工具包
摘要
实现人类水平的操作能力需要具备灵巧交互能力的灵巧机械手。进一步提升此类能力需要标准化的基准测试以进行系统评估。然而,现有的灵巧操作基准缺乏能够体现灵巧手相较于平行夹爪的独特操作能力的任务,同时也缺乏全面的评估流程。在本文中,我们提出了 DexJoCo,这是一个面向任务的灵巧操作基准和工具包,包含11个功能导向的任务,用于评估工具使用、双手协调、长周期执行和推理能力。我们开发了一套低成本的数据采集系统,并收集了1.1K条轨迹数据,支持域随机化以评估鲁棒性。我们在多种设置下对现代模型进行了基准测试,包括视觉和动力学随机化、多任务训练以及动作头适配。通过广泛的实证分析,我们识别出当前灵巧操作策略中的若干重要见解和常见局限性,突出了灵巧手机器人学习未来研究的关键挑战。项目页面:https://dexjoco.github.io
一句话总结
DexJoCo 是一个基于 MuJoCo 的面向任务的灵巧操作基准与工具包,引入了十一个功能明确的基准任务,用于评估工具使用、双手协调、长周期执行与推理能力;集成了低成本数据采集系统,结合域随机化技术生成 1.1K 条轨迹;并在视觉与动力学随机化、多任务训练及动作头适配等多种设置下对现代策略进行系统基准测试,以揭示当前方法的局限性并指导未来研究。
核心贡献
- 本文提出 DexJoCo,一个包含十一个功能明确基准任务的基准与工具包,用于评估工具使用、双手协调、长周期执行与推理能力。
- 构建了一套低成本数据采集流水线,将动捕手套与专用重定向算法结合,记录 1.1K 条轨迹,并支持域随机化以进行鲁棒性评估。
- 在视觉与动力学随机化、多任务训练及动作头适配条件下对现代模型进行了广泛的实证评估,识别出策略的关键局限性,并证明了具身感知与多模态架构的必要性。
引言
实现人类级别的机器人操作需要灵巧手具备精细且富含接触力的交互能力,以超越标准平行夹爪,但该领域缺乏能够捕捉这些独特能力并支持完整评估流水线的标准化基准。现有研究存在仅使用简化手部设置、任务多样性有限、因硬件限制或遮挡导致数据采集不可靠等问题,且存在关键错位:现代视觉-语言-动作模型通常在夹爪数据上进行预训练,而非灵巧操作数据。为弥补这些不足,本文提出 DexJoCo,一个面向任务的灵巧操作基准与工具包,包含十一个功能明确的基准任务,用于评估工具使用、双手协调与长周期推理。研究利用带有重定向功能的低成本遥操作系统的 1.1K 条高质量人类演示轨迹,支持在域随机化条件下进行稳健的策略评估,并揭示了当前方法的关键局限性,例如具身感知表示与多模态感知的必要性。
数据集
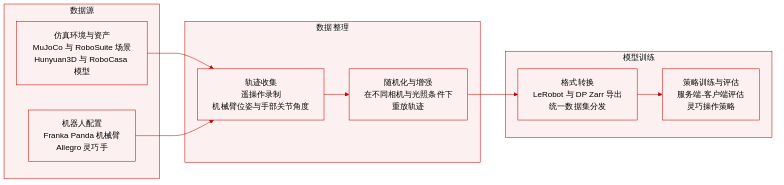
-
数据集构成与来源: 研究者在 MuJoCo 物理引擎中利用 Franka Panda 机械臂与 Allegro Hand 灵巧手构建了模拟灵巧操作数据集。任务环境与资产来源于 RoboSuite、MuJoCo Menagerie、RoboCasa 和 PartNet-Mobility,未标注资产通过 Hunyuan3D 生成并经过人工调整以确保物理合理性。该基准涵盖四大能力类别:工具使用、推理、双手协调与长周期操作。
-
子集详情与结构: 该基准按四大能力导向类别组织,而非传统的训练集或验证集划分。尽管未公开具体轨迹数量或明确的过滤规则,但每个任务子集均由交互物体与功能成功约束定义。观测数据结合第三人称与腕部安装的 RGB 或 RGB-D 图像,以及物体位姿、机器人运动状态、末端执行器位姿和手部关节角。动作记录为机械臂的目标绝对末端位姿与手部的目标绝对关节角。
-
数据使用与训练设置: 收集到的轨迹被转换为 LeRobot 和 DP Zarr 等标准格式,用于下游策略训练。该数据集作为服务器-客户端评估框架内灵巧操作策略评估的主要训练语料。未指定固定的训练划分或混合比例,而是将完整基准视为统一分布用于策略开发与评估。
-
处理与增强流水线: 为在不增加遥操作的情况下扩展数据多样性,采用基于回放的数据域随机化。该过程涉及在随机化的相机位姿、光照条件、桌面高度、桌面纹理及物体放置条件下重新渲染相同轨迹。相机位姿在球面上密集采样,并选取五十个以最小化遮挡。流水线还将显式的视觉状态变化嵌入资产以提供交互反馈,确保轨迹在通过提供的工具包接口导出前符合结构化的成功条件。
方法
研究利用基于遥操作的数据采集系统收集人类演示数据,用于训练机器人操作策略。如图所示的整体框架集成了硬件与软件组件,以实现准确且低成本的动作捕捉与重定向。系统采用 Rokoko Smartglove 捕捉手部位姿,并在腕部安装两个 HTC Vive 追踪器以记录末端执行器运动。这些传感器连接至计算机,手部运动数据在此进行实时处理。捕获的人类手部动作随后通过神经网络模型重定向至机器人,该模型将人类指尖位置映射至 Allegro 手的关节配置。该重定向过程由多层感知机(MLP)执行,其训练目标是在适应人与机器人手部结构差异的同时保留关键运动特征。

重定向模型采用自监督方法训练,无需成对的人机标注。训练重定向模型 f 的目标函数最小化复合损失,包含多项:Ldir 用于保留指尖运动方向,Lcover 用于最大化工作空间覆盖,Lflat 用于维持工作空间内的均匀灵敏度,Lpinch 用于保留捏取行为,以及 Lcol 用于防止自碰撞。演示采集期间仅记录指尖工作空间数据,从而降低训练数据复杂度并支持实时遥操作。对于手腕运动,系统追踪 HTC Vive 追踪器相对于初始参考位姿的相对位姿变化,使机器人能够执行模拟操作者手腕动作的增量动作。
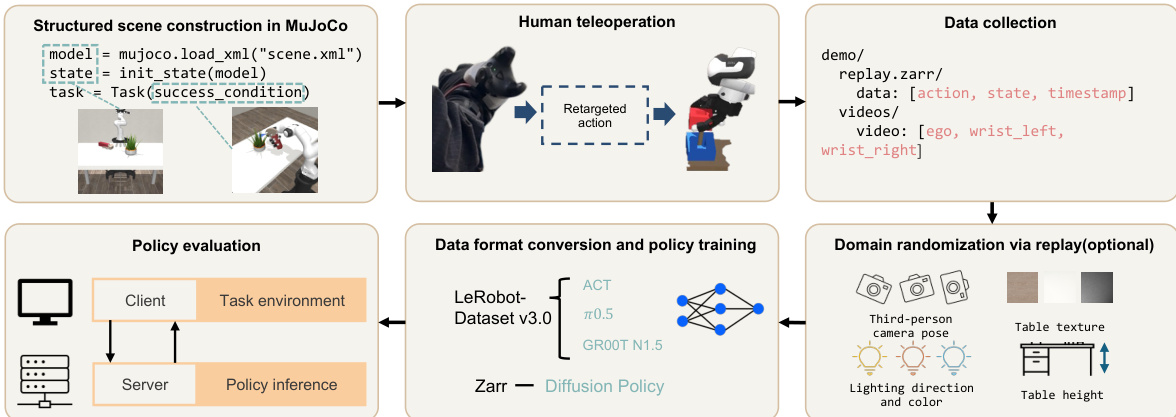
收集的数据(包含动作、状态与时间戳信息)以结构化格式存储,随后处理用于策略训练。数据被转换为兼容 LeRobot-Dataset v3.0 的标准格式,支持 ACT、Diffusion Policy 与 GR00T-N1.5 等多种模型评估。系统在数据采集阶段同步引入域随机化技术以增强学习策略的鲁棒性,包括随机化第三人称相机位姿、光照条件、桌面纹理与桌面高度,确保训练策略能够在多样且动态的环境中泛化。该框架支持广泛的灵巧操作任务,涵盖工具使用、双手操作、长周期与推理任务,各项任务旨在测试机器人灵巧性与决策能力的不同维度。
实验
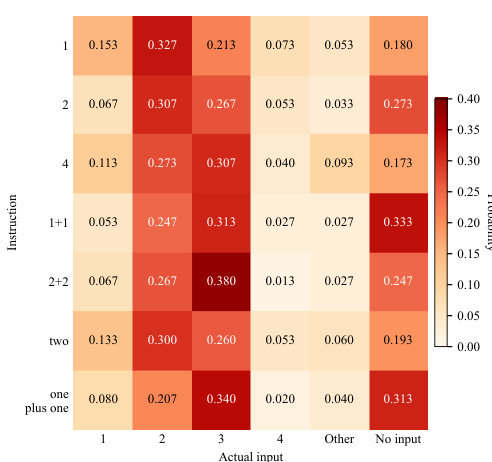
该评估在复杂的双手操作任务上对五种模仿学习策略进行基准测试,采用异步推理,系统验证了其在不同视觉随机化设置、物理动力学、多任务联合训练、动作头初始化策略及语言指令泛化方面的鲁棒性。定性分析表明,该基准有效揭示了预训练规模、架构设计与训练方法之间的根本权衡。尽管在从零开始随机初始化额外动作维度时性能出现下降,大规模预训练模型仍保持整体优势。策略在精细交互、精确插入与时间记忆需求方面普遍表现不佳,但保留预训练动作头可显著增强对动态变化的鲁棒性及整体任务成功率。此外,实验表明多任务联合训练往往导致各架构性能下降,且当前的视觉-语言-动作模型未能实现语言指令的泛化,反而依赖固定的动作偏差而非真正的语义条件控制。
研究在测试灵巧操作能力的基准上评估了多种模仿学习策略,重点关注不同训练与评估条件下的成功率。结果表明,尽管部分策略在特定任务上表现良好,但其他策略在精细动作、插入与记忆依赖型操作中表现出失效模式,其性能受预训练、模型架构与任务复杂度影响。该基准揭示了预训练、模型规模与架构之间的权衡,不同策略在精确操作或双手操作等特定任务中表现优异。策略在按钮按压与插入等精细动作上频繁失败,表明复杂操作任务在感知与记忆方面存在挑战。保留预训练动作头权重可提升性能,说明预训练有助于在多变条件下增强鲁棒性。

研究在灵巧操作基准上评估了多项模仿学习策略,对比其在不同任务与条件下的表现。结果显示,部分策略在特定任务上实现高成功率,而在其他任务上失败,且在视觉与动态随机化条件下性能波动显著。分析表明,预训练动作头与 FiLM 注入等架构选择有助于提升精确操作任务的性能。策略在不同任务上成功率各异,部分在按钮按压与铰链交互等特定操作中表现突出,但在插入与记忆依赖型动作上失败。视觉随机化导致性能急剧下降,表明鲁棒性有限,尽管部分模型在双手任务上仍保持竞争力。保留预训练动作头权重可提升成功率,FiLM 注入等架构差异也有助于精确操作任务的性能提升。
研究在具有挑战性的灵巧操作基准上评估了多项模仿学习策略,对比其在不同任务与条件下的表现。结果显示,尽管部分策略在特定任务上实现高成功率,但其他策略在精细动作、插入与记忆依赖型操作中失败,且性能在不同训练与评估设置下差异显著。尽管从头训练,DP-T 在双手任务上的表现与更大规模模型相当。DP-C 在需要精确操作与铰链交互的任务上优于其他模型。保留预训练动作头权重相比随机初始化带来了更高的整体成功率。
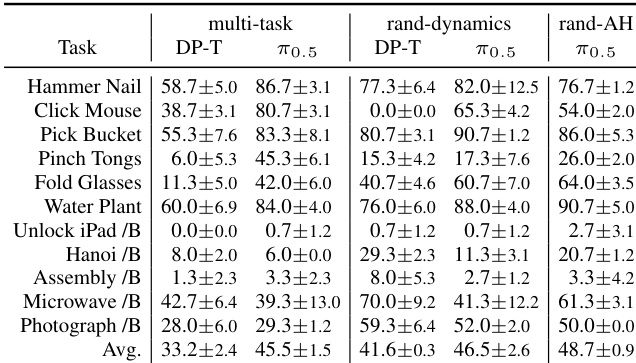
研究在具有挑战性的灵巧操作基准上评估了多项模仿学习策略,对比其在不同任务与条件下的表现。结果显示,尽管部分策略在特定任务上实现高成功率,但其他策略在精细动作与记忆依赖型操作中表现吃力,且性能在不同训练设置与架构选择下差异显著。DP-C 在需要精确操作与铰链交互的任务上优于其他策略,这很可能归功于其采用 FiLM 进行观测注入。视觉随机化导致成功率急剧下降,表明所有策略的鲁棒性均有限。在大多数任务上,保留预训练动作头权重相比完全随机初始化带来了更好的性能。
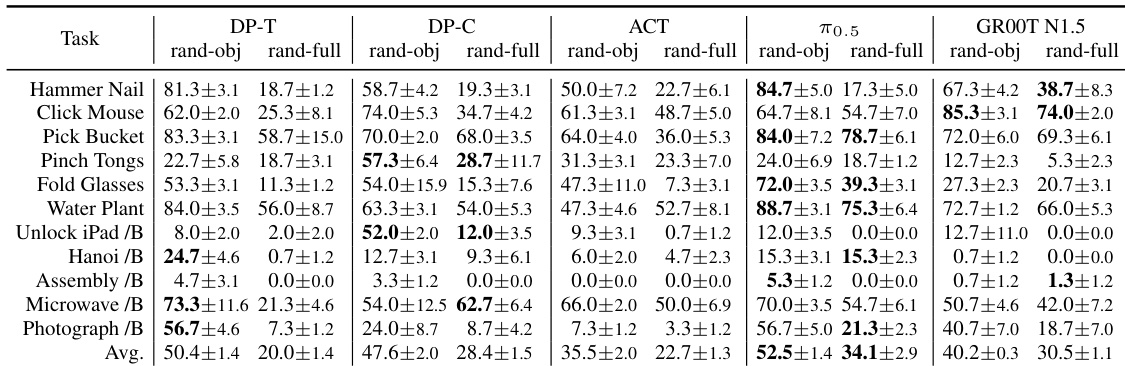
实验在灵巧操作基准上评估了多项模仿学习策略,以验证其特定任务能力、对环境随机化的鲁棒性以及架构设计选择的影响。定性结果表明,策略在精细动作、插入与记忆依赖型操作中普遍表现不佳,同时对视觉扰动高度敏感,限制了泛化能力。然而,保留预训练动作头权重并结合 FiLM 注入可显著提升不同条件下的精确度与整体成功率。这些发现共同表明,相较于单纯的模型规模,战略性初始化与架构特征对实现稳健的操作性能更具决定性作用。