Command Palette
Search for a command to run...
AnyFlow:具有在线策略流映射蒸馏的任意步视频扩散模型
AnyFlow:具有在线策略流映射蒸馏的任意步视频扩散模型
Yuchao Gu Guian Fang Yuxin Jiang Weijia Mao Song Han Han Cai Mike Zheng Shou
摘要
一致性蒸馏显著推动了少步视频生成的发展。然而,一致性蒸馏模型的性能在测试时分配更多采样步数后往往会下降,这限制了其在任意步数视频扩散中的有效性。这一局限性源于一致性蒸馏用一致性采样轨迹替换了原始的概率流常微分方程(ODE)轨迹,从而削弱了ODE采样在测试时随步数增加而性能提升的良好特性。为了解决这一局限性,我们提出了AnyFlow,这是首个基于流映射(flow maps)的任意步数视频扩散蒸馏框架。与仅针对少数固定采样步数进行蒸馏不同,AnyFlow优化了完整的ODE采样轨迹。为此,我们将蒸馏目标从端点一致性映射(zt→z0)转变为任意时间间隔上的流映射过渡学习(zt→zr)。我们进一步提出了流映射反向模拟(Flow Map Backward Simulation),将完整的欧拉展开分解为捷径流映射过渡,从而实现高效的在线策略蒸馏,减少测试时误差(即少步采样中的离散化误差和因果生成中的暴露偏差)。在双向和因果架构上,参数量从13亿到140亿不等的广泛实验表明,AnyFlow在少步场景下达到或超越了基于一致性蒸馏的模型,并且其性能随采样步数预算的增加而提升。
一句话总结
作者提出 AnyFlow,这是一种支持任意步数的视频扩散框架。该框架通过流映射反向模拟(Flow Map Backward Simulation)将端点一致性映射替换为流映射过渡学习,从而实现完整 ODE 轨迹的高效策略内(on-policy)蒸馏。该方法在降低测试阶段离散化与暴露误差的同时,支持跨步长预算的灵活采样,并在四步采样下于因果文本到视频生成中取得 84.05 的 VBench 分数,在图像到视频生成中取得 87.87 的分数,性能匹配或超越 Krea-Realtime-14B 和 Wan2.1-I2V-14B 等基线模型。
核心贡献
- 提出 AnyFlow,这是首个基于流映射的支持任意步数的视频扩散蒸馏框架。该框架将蒸馏目标从固定点端点映射转变为任意时间间隔的过渡学习。此设计使单一模型能够支持灵活的推理预算,同时保留概率流 ODE 采样在测试阶段的良好缩放特性。
- 提出流映射反向模拟(Flow Map Backward Simulation),这是一种轨迹分解技术,将完整的欧拉采样路径拆解为捷径流过渡,以实现高效的策略内蒸馏。该机制可校正少步采样过程中的离散化误差,并缓解因果生成中的暴露偏差。
- 在 13 亿至 140 亿参数规模的模型上验证了该框架,证明其在少步采样场景下的性能匹配或超越基于一致性模型的基线,且随采样步数增加性能持续提升。该方法在因果与双向的文本到视频及图像到视频生成中均取得具有竞争力的 VBench 分数,文本到视频在 32 次 NFE 时达到 84.41,图像到视频在 4 次 NFE 时达到 87.87。
引言
视频扩散模型已实现卓越的生成质量,但大多数流水线仍受限于固定的推理预算,这催生了对能够在测试阶段动态权衡延迟与保真度的系统的实际需求。现有的少步蒸馏方法主要依赖一致性模型,将中间状态直接映射至初始噪声分布。这种固定点方法在多步采样过程中会引发累积的轨迹漂移,导致性能随步数增加而下降,同时引入严重的离散化与暴露偏差。为突破这些结构性瓶颈,作者提出 AnyFlow,这是首个基于流映射构建的支持任意步数的视频扩散蒸馏框架。该模型不针对端点一致性,而是学习任意时间对之间的过渡,从而自然支持可变步长。作者进一步提出用于策略内蒸馏的流映射反向模拟技术,将完整的欧拉展开过程分解为高效的捷径片段,以校正展开失配问题,并在不同计算预算下保持稳健的测试阶段缩放能力。
方法
作者采用流映射公式来实现任意步数视频扩散,该设计基于广义过渡算子的概念,用于建模概率流 ODE 轨迹上任意点之间的映射关系。该框架统一了一致性建模与标准流匹配方法,为扩散蒸馏提供了统一的视角。方法的核心是神经流映射模型,其学习近似关系 fθ(zt,t,r)≈zr(其中 1≥t>r≥0),用于参数化任意时间对之间的过渡。该公式通过学习连续过渡算子而非仅针对端点的映射,支持可变步长与任意步数推理。模型采用 MeanFlow 目标函数进行训练,该目标函数近似 [r,t] 区间上的平均输运速度,并优化预测速度场 uθ。为解决导数项中雅可比向量积的计算成本问题,作者采用有限差分近似法,该方法每训练步仅需两次前向传播,且兼容完全分片数据并行(FSDP)训练。
训练过程分为两个互补阶段。第一阶段为前向流映射训练,在此阶段对预训练的视频扩散模型进行微调,以学习稳定的过渡算子 fθ。该阶段采用多项设计以提升性能与稳定性。插值时间步条件机制用于保持与预训练模型嵌入范数的一致性,避免过度饱和。结合重加权函数 w(t) 的时间采样策略在不同噪声级别间平衡训练目标。融合引导训练通过将无分类器引导(CFG)目标融入预测来引入 CFG,使其与预训练模型的引导尺度对齐,并允许在测试阶段省略 CFG。自适应损失重加权方案以 t=r 时的回归损失为基准,动态调整非边界时间步的损失权重,从而保留已学习的瞬时速度并防止梯度不稳定。
第二阶段为策略内流映射蒸馏,模型在此阶段进一步精化以减少训练与测试阶段的分布差异,重点解决低采样预算下的离散化误差及因果生成中的暴露偏差。该阶段采用分布匹配蒸馏(DMD)目标,要求学生模型先自展开至 z0,随后重新添加噪声以计算 Kullback–Leibler(KL)梯度。核心创新在于流映射反向模拟范式,该范式利用流映射的组合性质将完整展开轨迹分解为捷径过渡。针对目标采样预算 N 步,从 T 到 0 的轨迹被分解为若干片段:T→t、t→r 与 r→0。首尾片段由已学习流映射的捷径过渡处理,而 t→r 为目标的过渡步骤。由于同一模型在测试阶段天然支持不同采样预算,该方法能够以相同的计算成本高效模拟不同的推理步长预算。
如图 4 所示,AnyFlow 的整体流水线整合了上述组件。框架首先基于教师模型合成的数据进行前向流映射训练,以提供高质量的初始化。随后进行策略内蒸馏,在此过程中流映射反向模拟生成学生模型的展开轨迹,并引入强教师模型的逆向散度监督,从而在保留任意步数能力的同时降低离散化误差与暴露偏差。该方法支持双向与因果架构,为高保真视频生成提供高效且灵活的推理支持。流映射公式与轨迹捷径分解设计使得训练具备可扩展性与高效性,使 AnyFlow 成为任意步数视频扩散的实用且稳健的解决方案。
实验
在统一协议下的标准化视频生成基准上进行评估,主要实验验证了该方法在显著减少采样步数的同时实现高保真文本到视频与图像到视频合成的能力。定性与定量评估表明,该方法始终优于同类领先模型,能够提供更清晰的视觉细节、更平滑的运动以及更强的提示词遵循能力,同时有效缓解测试阶段误差。消融研究进一步验证,特定设计选择(包括结合流映射反向模拟的策略内蒸馏、优化的时间采样策略以及插值时间步条件机制)共同作用,有效保留了预训练知识,防止训练不稳定,并维持了实用的计算效率。总体而言,结果确立了该框架作为快速高质量视频生成的高效稳健解决方案的地位。
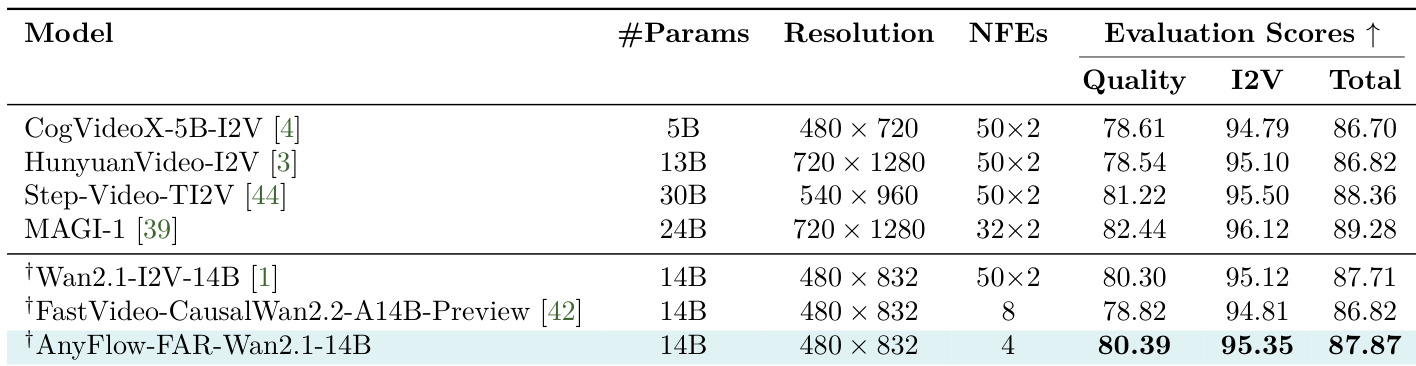
作者对比了多种视频生成模型,重点关注其在不同评估指标与采样效率上的表现。结果表明,与其他模型相比,所提出的 AnyFlow 方法在显著减少采样步数的同时,在生成质量与图像到视频保真度上均取得具有竞争力或更优的分数。该方法在质量与图像到视频保真度方面表现强劲,超越多项已有模型。AnyFlow 在不同模型架构与训练协议下均保持了高效性与有效性。
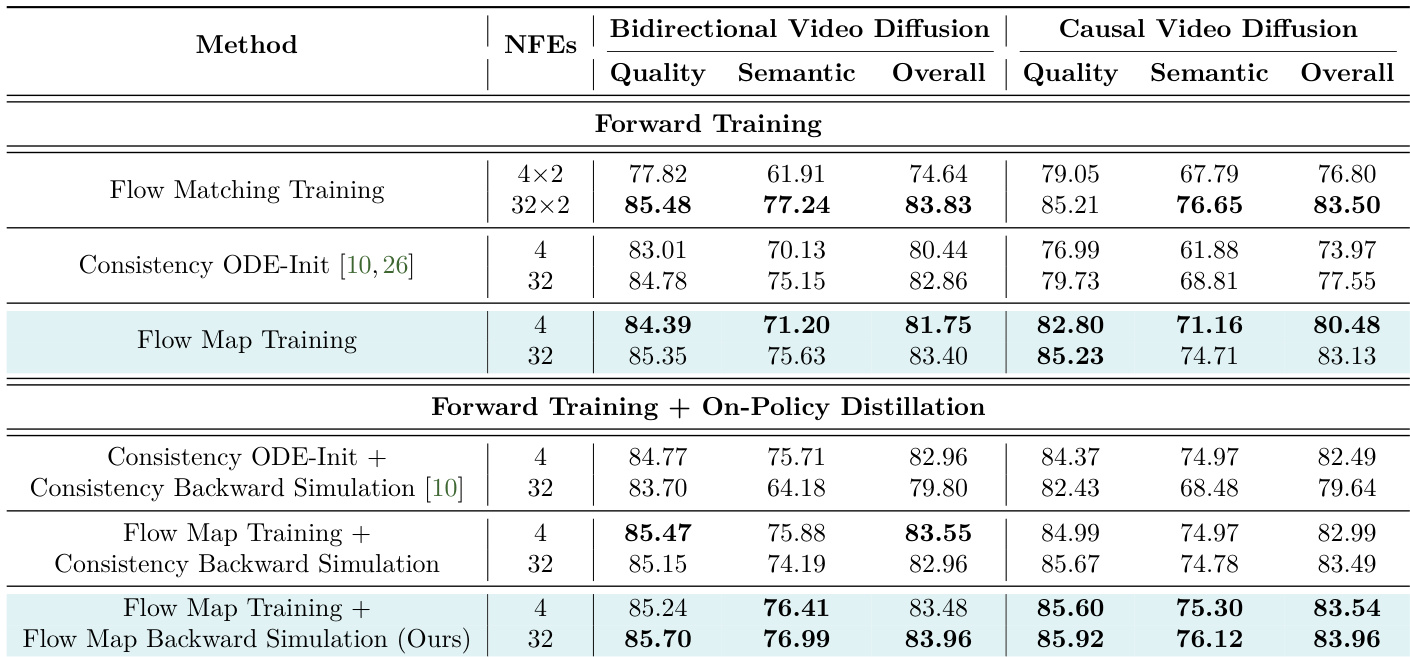
作者开展消融研究以评估不同训练与蒸馏策略对视频生成性能的影响。结果表明,结合流映射训练与流映射反向模拟的 AnyFlow 在因果、双向及任意步数生成设置中均优于其他方法。研究强调,流映射反向模拟在保持强大采样效率的同时实现了高效的多步生成。AnyFlow 在因果与双向视频生成设置中均表现领先。流映射反向模拟支持任意步数视频生成,并在较大步数下提升效率。流映射训练与策略内蒸馏的结合降低了测试阶段误差并增强了采样性能。

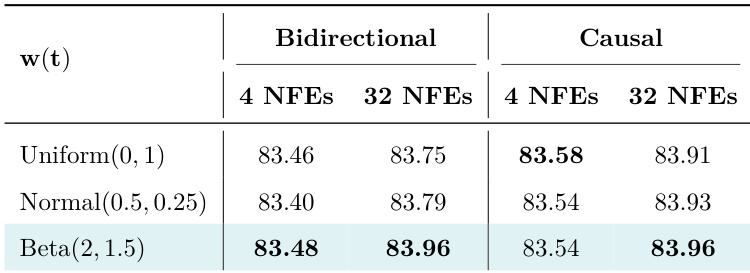
作者对方法中的不同时间采样器进行评估,比较其在少步与多步采样设置下的表现。结果表明,特定参数的 Beta 分布在双向与因果设置中均取得最高性能,尤其在 32 次 NFE 时表现突出,相较于均匀分布与正态分布展现出更优的测试阶段缩放能力。参数为 (2, 1.5) 的 Beta 分布在 32 次 NFE 的双向与因果设置中均达到最佳性能。均匀分布与正态分布的性能低于 Beta 分布,多步采样时差异更为明显。Beta 分布展现出卓越的测试阶段缩放能力,在 32 次 NFE 设置中优于其他采样器。
作者评估了视频扩散模型的不同训练与蒸馏策略,重点分析流映射训练与策略内蒸馏的影响。结果表明,流映射训练提供的初始化质量优于基于一致性模型的方法,且与策略内蒸馏结合后性能进一步提升,少步采样场景下尤为明显。所提出的流映射反向模拟在较大步数下相比一致性基线展现出更高效率。流映射训练在少步与多步设置中均优于一致性 ODE-Init 方法,为采样提供更强的初始化。策略内蒸馏进一步缓解测试阶段误差并提升性能,与流映射训练结合时效果更佳。所提出的流映射反向模拟在较大步数下比一致性方法更高效,支持多步生成的快速训练。
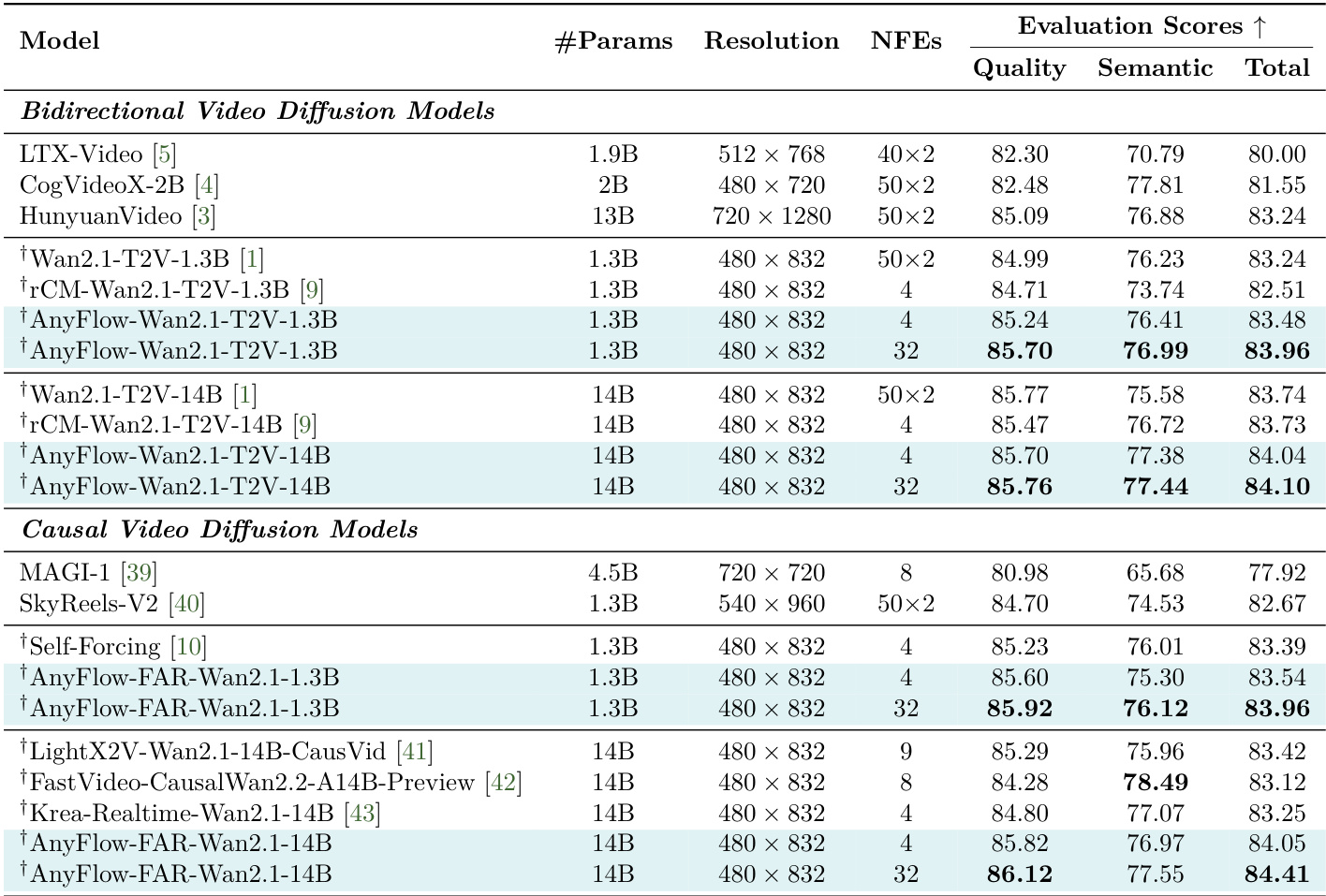
作者对比了多种视频扩散模型,重点考察 AnyFlow 在不同配置与主干架构下的表现。结果表明,AnyFlow 取得强劲的评估分数,少步采样设置下尤为突出,且随采样预算增加性能持续提升。表格数据突出显示,AnyFlow 变体在双向与因果设置中均优于其他模型,在使用较高 NFE 数量时优势更为明显。AnyFlow 在双向与因果视频扩散模型中均取得最高评估分数,高 NFE 设置下表现最佳。AnyFlow 的双向主干在少步采样设置中展现出优于因果主干的性能。AnyFlow 变体在质量与语义分数上始终领先其他模型,表明其视觉质量与语义保真度得到显著提升。
实验评估在多样化架构、采样预算与生成设置下将 AnyFlow 与现有视频生成模型进行对比,以验证其整体效率与保真度。消融研究进一步剥离了特定训练策略、蒸馏技术及时间采样器分布的独立影响。定性结果表明,AnyFlow 在显著减少采样步数的同时,始终提供卓越的视觉质量与语义准确性。流映射训练与反向模拟及策略内蒸馏的集成在因果与双向生成中均被证明高度有效,支持稳健的多步采样并增强测试阶段的可扩展性。