Command Palette
Search for a command to run...
MinT:用于训练和服务数百万大语言模型的托管基础设施
MinT:用于训练和服务数百万大语言模型的托管基础设施
摘要
我们提出了 MindLab Toolkit(MinT),这是一个用于低秩自适应(LoRA)后训练和在线服务的托管基础设施系统。MinT 针对这样一种场景:在少量昂贵的基础模型部署上生成大量经过训练的策略。MinT 不将每个策略物化为合并后的完整检查点,而是保持基础模型常驻,并让导出的 LoRA 适配器修订版经历 rollout、更新、导出、评估、服务和回滚等流程,从而在服务接口背后隐藏分布式训练、服务、调度和数据移动等复杂操作。MinT 沿三个维度扩展了这一路径。Scale Up 将 LoRA 强化学习扩展至前沿规模的密集(Dense)和混合专家(MoE)架构,包括 MLA 和 DSA 注意力路径,并在总参数量超过 1T 的情况下验证了训练和服务的有效性。Scale Down 仅移动导出的 LoRA 适配器,在 rank-1 设置下其大小可低于基础模型的 1%;仅适配器的交接使 4B 密集模型的测量步骤减少了 18.3 倍,30B MoE 模型减少了 2.85 倍,同时并发的多策略 GRPO 在不增加峰值内存的情况下将墙钟时间缩短了 1.77 倍和 1.45 倍。Scale Out 将持久的策略寻址能力与 CPU/GPU 工作集分离:张量并行部署支持百万级规模的寻址目录(实测单引擎扫描通过 100K),并在集群规模上支持千级适配器的活跃波次,冷启动加载被视为计划内的服务工作,而打包的 MoE LoRA 张量将实时引擎加载速度提高了 8.5-8.7 倍。因此,MinT 在共享的 1T 级基础模型上管理百万级 LoRA 策略目录,并对选定的适配器修订版进行训练和服务。
一句话总结
本文提出 MinT,一种托管式基础设施,通过使基础模型常驻内存并循环使用轻量级适配器版本,消除完整检查点物化,从而简化基于 LoRA 的大语言模型后训练与推理服务。该系统将适配器交接时间减少高达 18.3 倍,将冷启动速度提升 8.5 至 8.7 倍,并能在共享的 1T 级基础模型上管理百万级策略目录。
核心贡献
- MinT 是一套托管式基础设施系统,在内存中维护共享的基础模型,同时将导出的 LoRA 适配器版本路由至完整的生命周期(包括 rollout、评估、服务和回滚)。这种适配器版本架构抽象了分布式训练、调度和数据移动的复杂性,从而实现可复现的大规模 LoRA 强化学习工作流。
- 该系统通过 LoRA 目标映射、rollout 校正以及打包的 MoE LoRA 张量加载,将 LoRA 强化学习扩展至参数量超过一万亿的密集型和混合专家(MoE)架构。这些机制消除了完整检查点物化,并将冷适配器加载重新定义为计划内的服务工作,从而将在线引擎加载速度提升 8.5 至 8.7 倍。
- 在四十亿和三百亿参数模型上的评估表明,仅交接适配器可将传输延迟分别降低 18.3 倍和 2.85 倍,而并发的 Group Relative Policy Optimization 在不增加峰值内存的情况下将运行时间缩短高达 1.77 倍。该基础设施支持单引擎遍历 10 万条记录的百万级策略目录,并在集群规模上支持千级适配器并发工作流。
引言
提供的文本仅列出了贡献者,这意味着缺乏可供分析的技术背景、现有工作局限性以及核心贡献。为提供所需的总结,请分享摘要或相关方法论部分。收到后,将以简洁且技术准确的形式概述应用背景、现有挑战及作者的核心创新。
方法
MinT 框架旨在大规模管理低秩自适应(LoRA)后训练与在线服务,其运行模式为少量高成本的基础模型在多种已训练的策略变体间共享。系统核心架构将服务控制与计算分离,服务层处理客户端交互,计算层执行训练与推理任务。如框架图所示,用户意图(包含基础模型、数据与奖励信号、LoRA 强化学习配方以及评估或服务目标)通过 API 提交。MinT 处理该输入,将其加入队列,维护策略状态并跟踪导出版本。随后,系统在共享的基础模型部署上管理大量策略,其中基础模型保持常驻内存,而策略特定行为则封装于 LoRA 适配器中。调度、容错及数据移动等底层基础设施复杂性在服务接口后方被抽象处理。
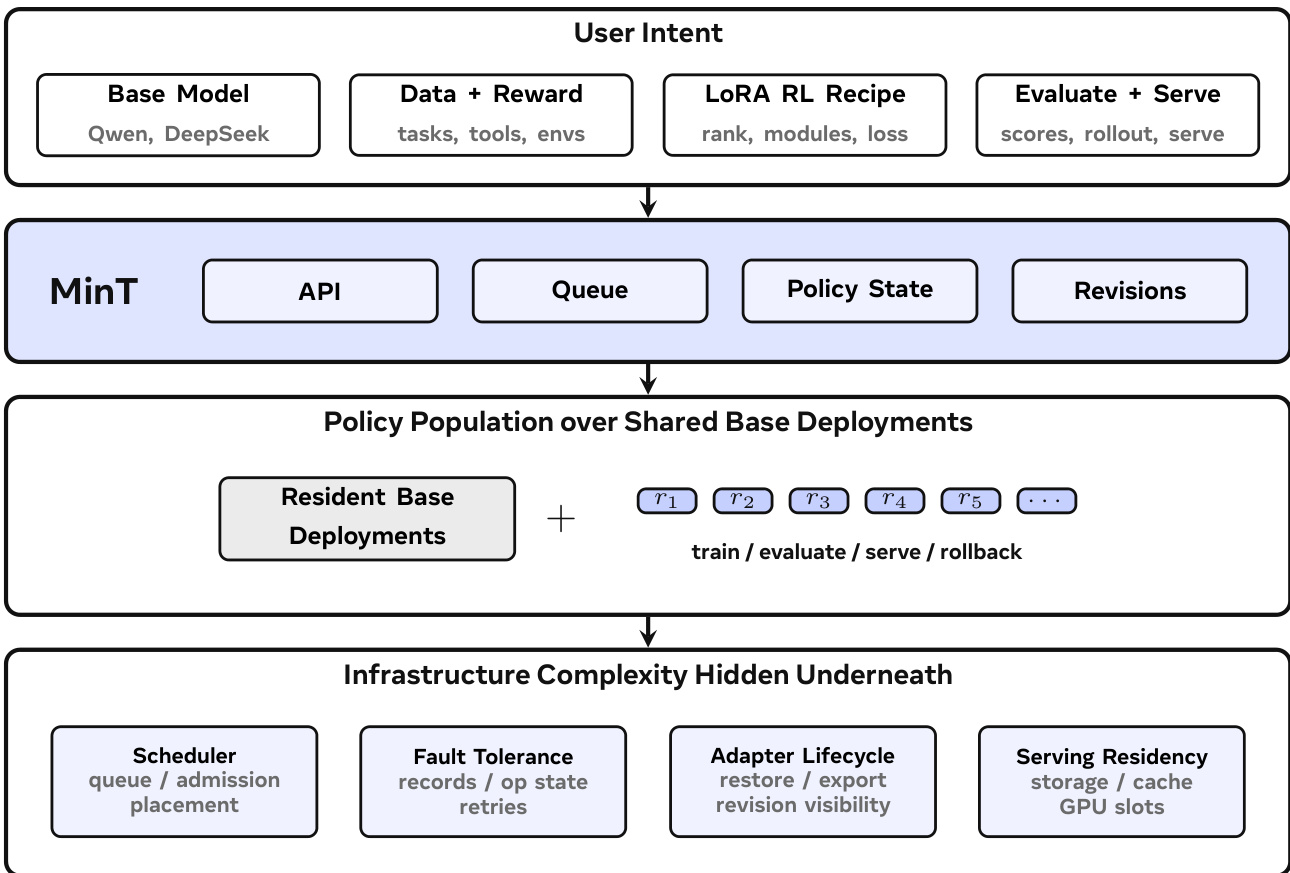
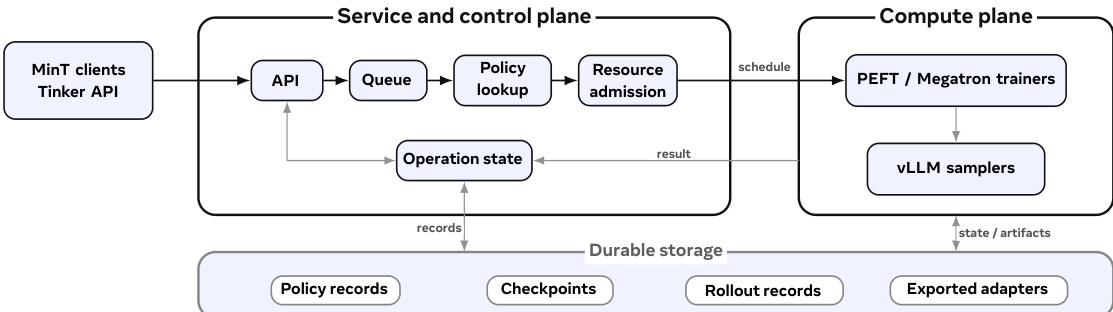
下图所示的 MinT 运行时架构进一步阐明了这种分离机制。MinT 客户端通过兼容 Tinker 的 API 与服务交互,该 API 负责验证请求并将其入队。服务层解析策略记录,将任务分配至兼容的工作节点,并记录操作结果。计算层由用于 LoRA 更新的 PEFT 或 Megatron 训练器,以及用于推理的 vLLM 采样器或服务代理组成,所有组件均在常驻基础模型上运行。服务层为策略记录、检查点、rollout 记录及导出适配器维护持久化存储,确保所有状态可恢复且操作具有幂等性。该设计使 MinT 能够管理大量策略变体,而无需为每个变体物化完整的模型检查点。
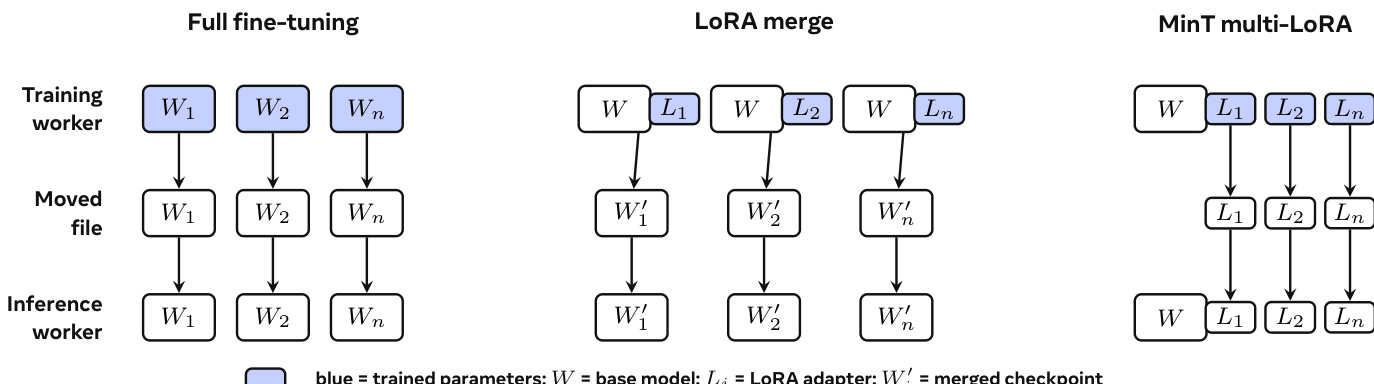
核心创新在于以适配器为中心的工作流,该工作流重新定义了从训练到服务的边界。如三种适配路径对比图所示,MinT 仅将导出的 LoRA 适配器版本从训练阶段迁移至服务阶段,而非完整的模型检查点。该适配器版本是 LoRA 适配器的固定导出快照,在特定训练步骤冻结,并以服务张量布局存储。它是跨越边界的可执行负载,而包含持久化生命周期状态的策略记录则保持独立。该记录包含基础版本、LoRA 秩与目标模块、最新训练检查点、rollout 记录及可用的导出版本。这种分离机制使共享基础模型能够支持大量 LoRA 策略,而无需为每个策略创建独立的完整模型服务器。
系统的扩展能力通过三个维度实现:Scale Up(向上扩展)、Scale Down(向下缩减)与 Scale Out(横向扩展)。Scale Up 将 LoRA 强化学习扩展至大规模密集型和混合专家(MoE)架构。这由模型并行训练与服务路径支持,并在总参数量超过 1T 的场景中经过验证。系统通过确保 LoRA 张量遵循基础模型的分片规则来处理模型并行部署,无论是针对密集权重的张量并行,还是针对 MoE 专家的专家并行。对于 MoE 模型,MinT 在 rollout 期间记录专家路由路径,并在训练时尽可能回放该路径,以缓解因路由不匹配导致的不稳定性。对于动态稀疏注意力(DSA),系统采用 IcePop 风格的 rollout 校正机制,过滤掉训练与 rollout 概率比值超出可信区间的 tokens。
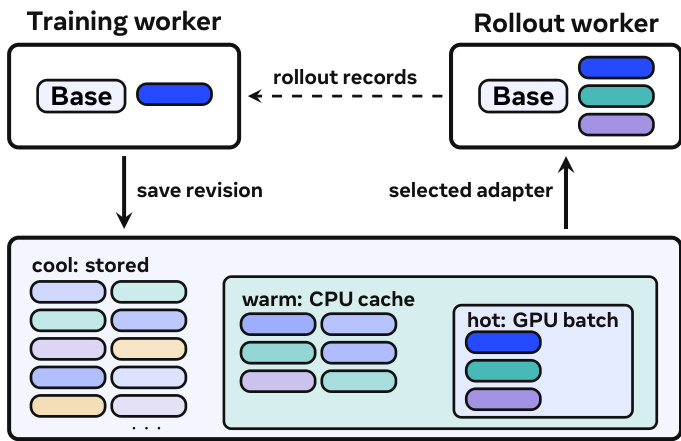
Scale Down 通过仅传输导出的 LoRA 适配器来最小化训练至服务的交接开销,在紧凑的 rank-1 设置中,其体积可低于基础模型的 1%。这消除了物化完整检查点的需求,显著降低了数据传输与存储开销。测量结果表明,仅交接适配器可将 4B 密集模型的交接步骤缩短 18.3 倍,将 30B MoE 模型缩短 2.85 倍。Scale Out 在保持引擎本地执行范围可控的前提下扩展策略命名空间。MinT 将策略的持久化寻址与 CPU/GPU 热工作集分离,使张量并行部署的服务能够支持规模达 106 的可寻址策略目录。策略版本可占用三个缓存层级的任意子集:目录(共享存储)、CPU 缓存(温缓存)与 GPU 批次(热缓存)。该分离机制使系统能够管理海量策略,同时限制单个引擎的内存占用。
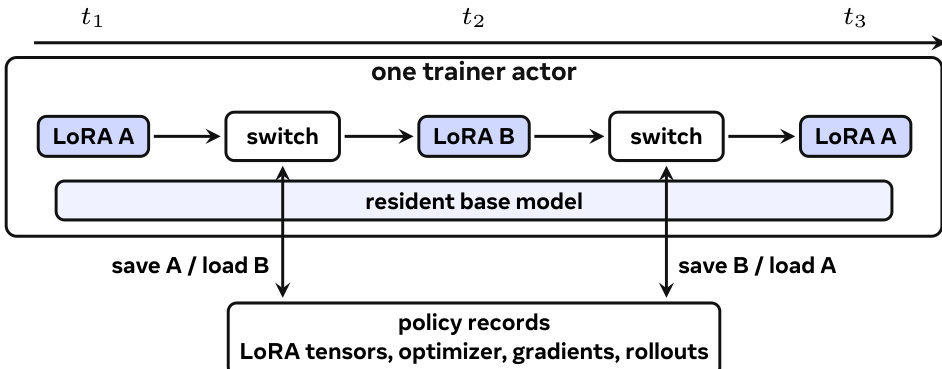
适配器生命周期通过一系列阶段进行管理。训练更新后,训练器将当前训练状态导出为固定的适配器版本,随后将其存入持久化存储。在 rollout 或服务期间,请求将面向用户的策略名称解析为导出版本及引擎本地适配器 ID。若适配器已在 GPU 批次中激活,则立即执行推理。若其缓存于 CPU 内存中,引擎会将其提升。若仅存在于共享存储中,服务代理会在解码前获取并加载该适配器。该过程将冷加载视为计划内的服务工作,并通过去重与背压机制管理大量独特策略并发到达时的负载阶梯。MinT 进一步通过打包 MoE LoRA 张量优化在线引擎加载,减少小对象数量,将性能提升 8.5 至 8.7 倍。系统设计确保基础模型在整个操作过程中保持常驻,仅 LoRA 张量与训练状态发生变化,从而实现高效的时分复用多 LoRA 训练与服务。
实验
经测量的适配器字节体积适中,但被分割为数万个小张量,其中大部分不超过 4 KB。因此,即使在总字节数较小的情况下,冷加载仍需承担对象创建与注册开销。
表 记录了经测量的 30B MoE LoRA 适配器文件的内存与表示开销。各行区分了字节体积、对象扇出与缓存压力。
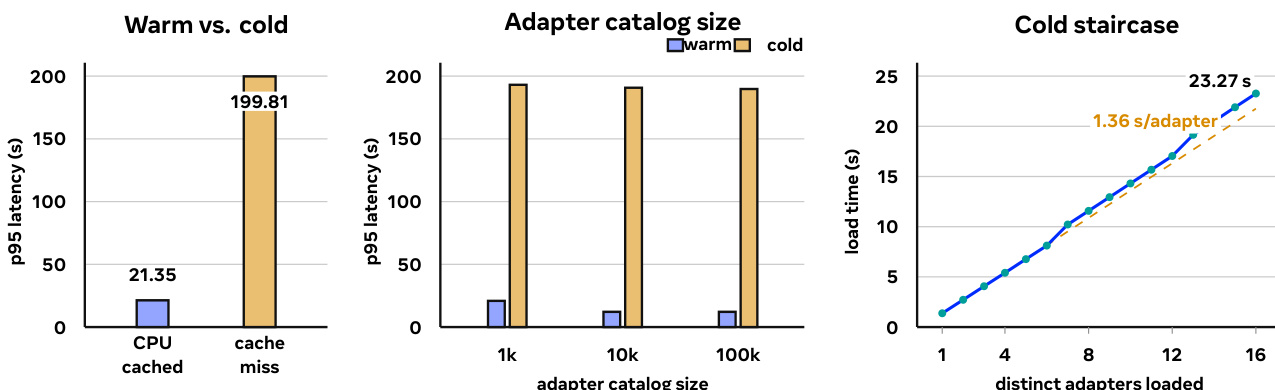
适配器目录规模。表 将适配器目录规模从 1k 调整至 100k 条记录。温/冷分离在遍历过程中持续存在,当大量不同的冷适配器进入冷加载时,可观察到测量尾部分布。
这些行数据支持正文中的观点,即 MinT 应在控制平面保持目录解析,并在服务平面管理缓存状态与冷加载。
表 展示了 N=64 服务场景下的适配器目录遍历。温行与冷行被分开列出,以便在各目录规模下观察稳定区间的差异。
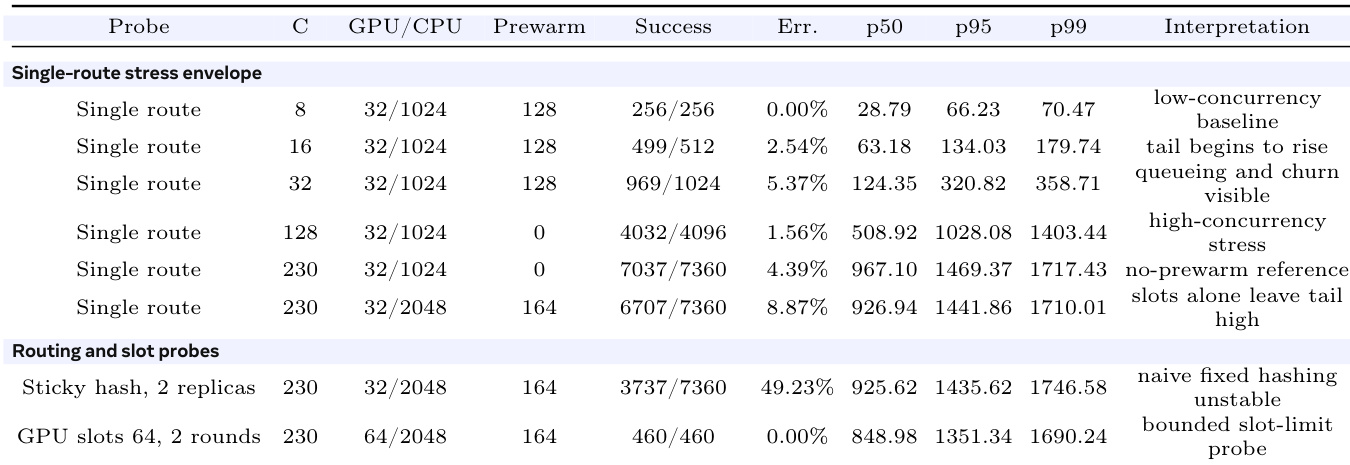
缓存工作集。表 提供了图中温缓存主张背后的有序数据。重复热集行对路由找到有效引擎部署后的适配器局部性进行建模。独立适配器行移除了该局部性,并测量在运行不再符合纯温路径主张前,单个引擎附近可缓存多少不同的适配器。这些测量定义了位于持久化适配器目录与同批次适配器窗口之间的 CPU 侧层级。
表 展示了单个 4-GPU Qwen3-30B rank-1 服务代理上的缓存工作集阶梯。阴影分组行区分了路由局部性与独立适配器负载压力。

混合在线长度压力流量。表 刻意排除了纯温路径设置。这些行数据结合了混合输出长度、高并发、弱局部性、预热变更及不同的槽位限制,以展示简单路由选择失效的边界。粘性哈希行属于负向探测;仅靠固定哈希无法在此压力形态下提供缓存感知路由。GPU-64 槽位行属于有界探测;它在两轮测试中验证了槽位限制设置,长期稳定性不在本主张范围内。
表 展示了 2048 适配器目录下的混合在线长度流量。GPU/CPU 列给出了 GPU 批次 LoRA 槽位限制与 CPU 缓存 LoRA 限制。
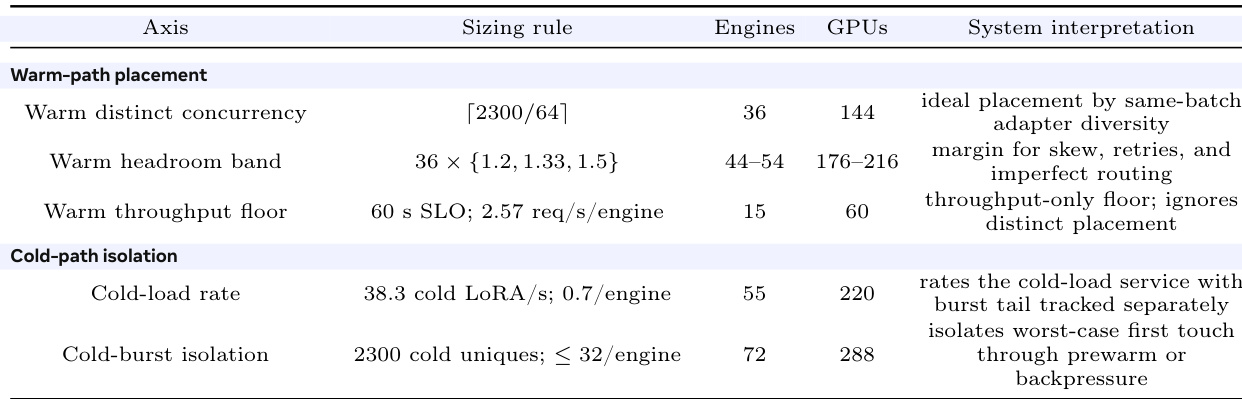
表 冷加载开销统计与服务保护。

表 容量规划概览,从测量的单引擎限制延伸至 100 万条累积适配器目录及 2300 独立适配器并发压力包络。
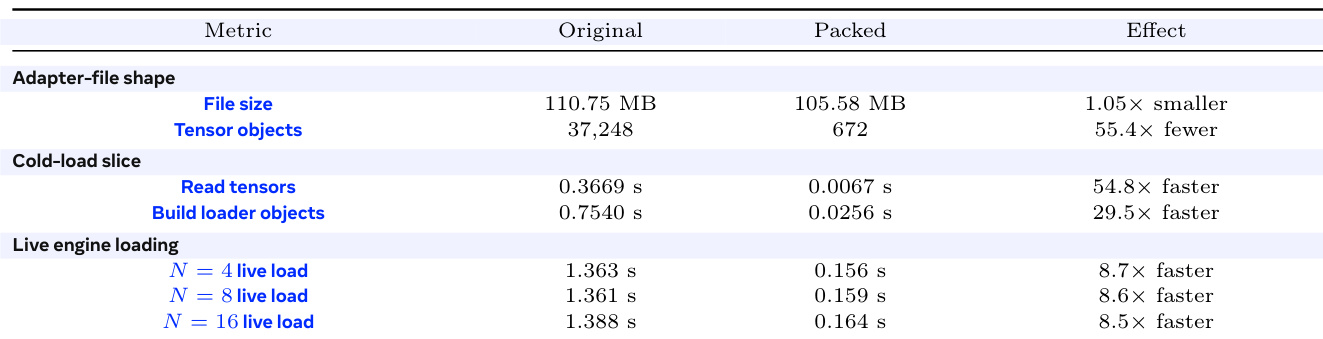
冷加载开销统计。表 将冷路径分解为 API 排队、重复缓存未命中的共享加载、独立适配器加载以及有界背压。探测结果表明瓶颈在于将独立冷适配器加载至单个引擎。请求在生成前等待 LoRA 加载;测量的 API 队列等待时间较短。对相同缺失适配器进行去重可避免重复加载工作,而不同的冷适配器则保持为独立的加载任务。这支持了正文中的观点,即冷加载是在普通采样延迟之前的计划内服务工作。
集群级规模规划概览。表 将测量的单引擎限制作为更大规模 MinT 部署的规模规划输入。该表在 2300 独立适配器并发假设下构建了 106 适配器容量模型。
主要服务实验将适配器目录规模遍历至 10 万条记录。外推分析探讨若更大的累积适配器目录在路由或预热恢复局部性前产生该并发波,需要多少引擎。60 秒服务等级目标是用于设定吞吐量底线的温响应目标,2.57 req/s/engine 是该行观测到的温吞吐量输入。冷加载行对另一种独立场景进行规模测算,即大量选定适配器在首次访问时处于冷状态。
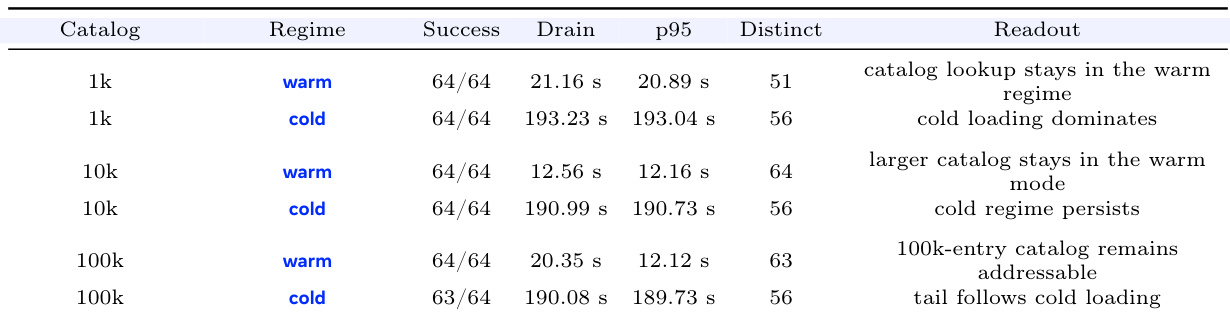
作者对比了两种部署已训练策略的方法:直接加载 LoRA 适配器与将适配器合并至完整检查点。结果表明,与合并路径相比,基于适配器的方法显著降低了总步骤时间,且模型越大加速效果越明显。柱状图显示,物化与加载时间主导了合并路径,而适配器路径将此类开销降至最低,从而实现更快的端到端执行。基于适配器的部署方法相比合并路径大幅减少总步骤时间,加速效果在大型模型中更为显著。物化与加载时间是合并路径的主要耗时环节,适配器路径则有效规避了这一开销。该方法通过缩短检查点物化与加载时间,实现更快的端到端执行。
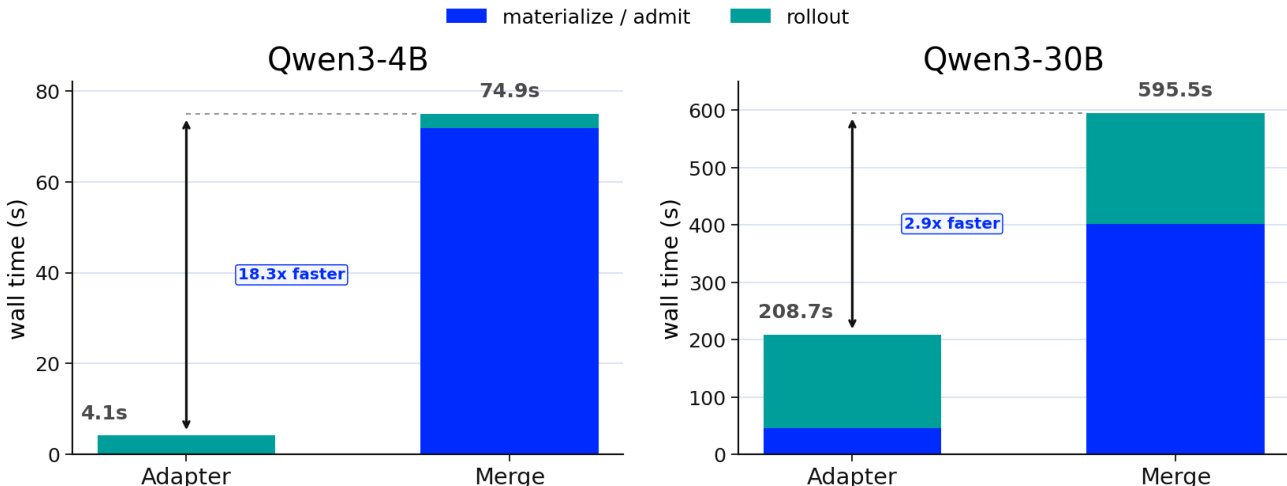
表 概述了服务系统中适配器管理的关键方面,重点关注文件形态、执行占用及冷加载表示。文中指出,适配器文件体积适中但包含大量小张量,导致冷加载时对象扇出显著。CPU 缓存大小被确定为温服务的主要限制因素,而基础模型的 HBM 占用则主导了内存使用。打包适配器文件在不改变总字节数的前提下降低了张量扇出,通过最小化需处理的小张量对象数量,显著提升了冷加载性能。适配器冷加载性能主要受小张量对象数量影响,而非文件大小。CPU 缓存大小限制了可保持温状态以供快速访问的适配器数量。打包适配器文件降低张量扇出,在不改变总文件大小的情况下实现更快的冷加载。
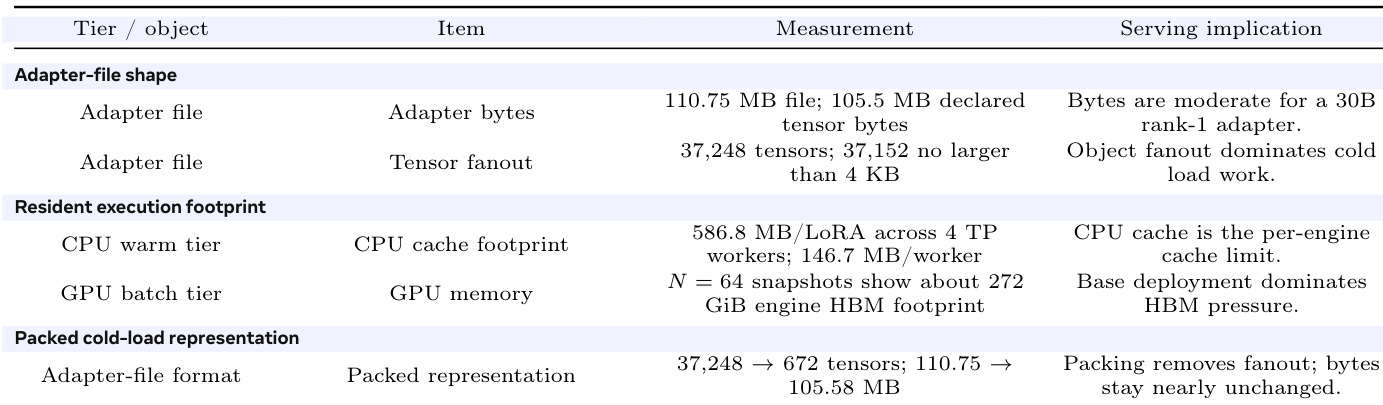
实验评估了多 LoRA 服务系统在目录规模与请求模式变化下的性能。结果表明,无论目录规模如何,温请求均能保持低延迟与高成功率;而冷请求延迟显著升高,且受目录增长影响。系统在温态与冷态之间保持清晰分离,随着目录规模扩大,冷路径逐渐占据主导。温请求在不同目录规模下维持一致的低延迟与高成功率。冷请求延迟显著升高,且随着目录规模扩大,冷加载模式成为主导。系统呈现明显的温冷态分离特征,在较大目录规模下,冷加载成为主要瓶颈。
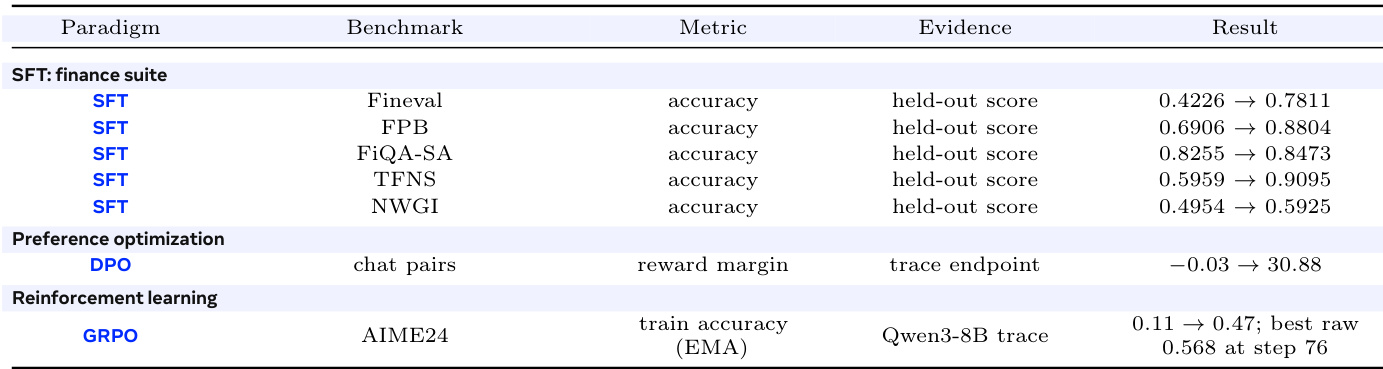
作者使用一致的适配器生命周期,在多个基准测试中评估了不同训练范式(监督微调、偏好优化与强化学习)的性能。结果表明,所有范式在准确率与奖励指标上均取得显著提升,证明同一适配器格式能够支持多样化的训练目标,且无需针对各范式进行工具链调整。强化学习结果凸显训练准确率的实质性增长,而偏好优化则展现出奖励边距的大幅改善。一致的适配器生命周期支持监督、基于偏好及强化学习范式,并在各项基准测试中带来稳定提升。监督微调在多个金融相关基准测试中实现准确率的大幅跃升。强化学习显示训练准确率显著增加,最佳原始分数在第 76 步达到 0.568。
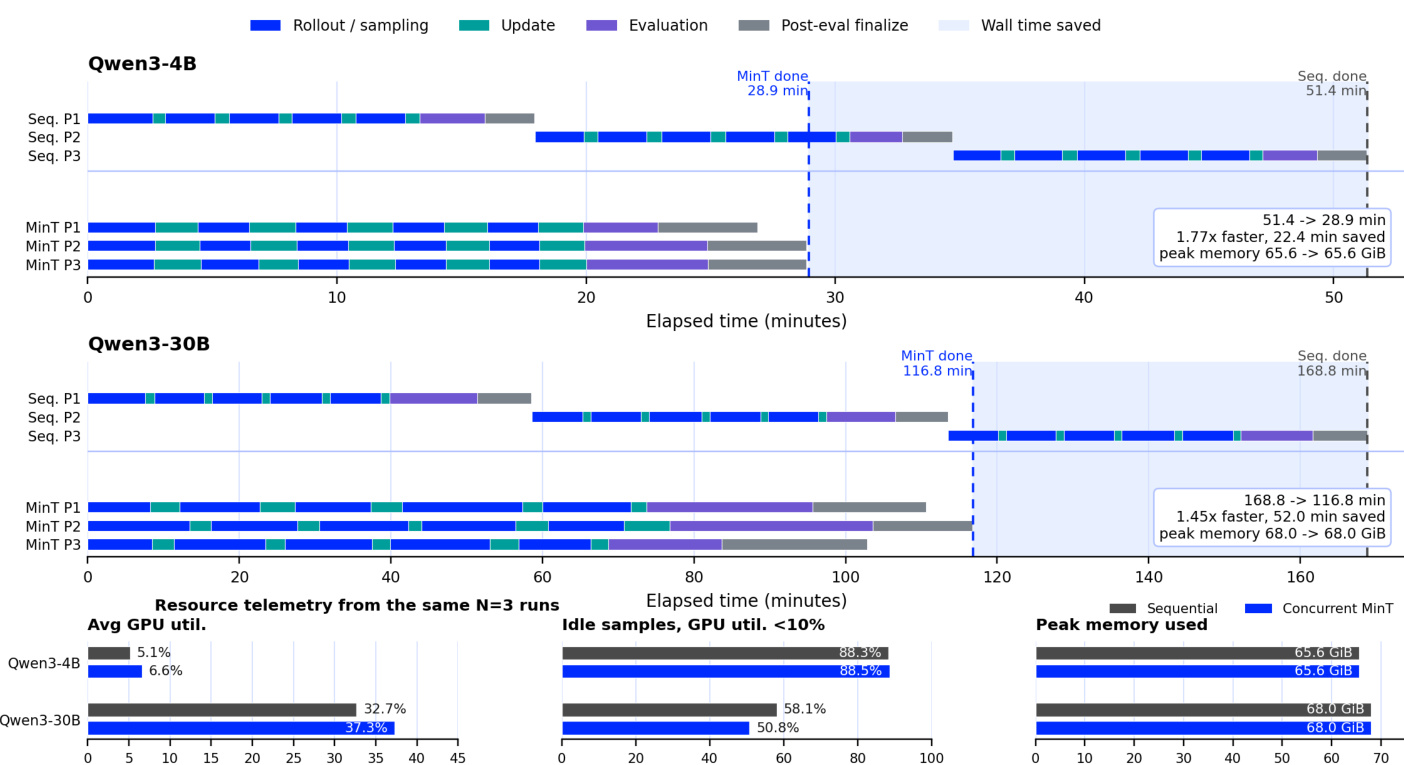
作者对比了多模型的顺序与并发训练调度,表明并发执行在保持峰值内存占用的同时显著缩短了运行时间。结果证明,并发训练通过重叠不同策略的空闲时段维持较高的 GPU 利用率,从而实现显著的时间节省。实验证实,同一适配器生命周期支持多种训练范式与模型规模,且无性能下降。与顺序执行相比,并发训练大幅缩短运行时间,同时保持峰值内存占用不变。由于策略间空闲时段重叠,并发运行的 GPU 利用率更高。同一适配器生命周期支持不同的训练范式与模型规模,且不会导致性能下降。
评估在模型规模、目录规模与执行调度变化的条件下,检验了统一 LoRA 适配器框架在部署、服务与训练阶段的表现。部署测试验证,直接加载适配器而非合并可最大程度降低物化开销,从而显著加速端到端执行。服务实验证实,尽管缓存请求能维持一致的低延迟,但随着目录规模扩大,冷加载成为主要瓶颈,而该限制可通过文件打包降低张量扇出来有效缓解。最后,训练评估表明,一致的适配器生命周期支持多样化的优化范式,并支持并发执行以在不增加峰值内存占用的情况下大幅缩短运行时间。