Command Palette
Search for a command to run...
Lance:通过多任务协同实现统一的多模态建模
Lance:通过多任务协同实现统一的多模态建模
摘要
我们提出了Lance,这是一种轻量级的原生统一模型,支持图像和视频的多模态理解、生成与编辑。与依赖模型容量扩展或文本-图像主导设计的方法不同,Lance通过协作式多任务训练探索了一种实用的统一多模态建模范式。该模型基于两个核心原则:统一上下文建模和解耦能力路径。具体而言,Lance从零开始训练,并在共享的交错多模态序列上采用双流混合专家架构,在实现联合上下文学习的同时,将理解与生成的路径解耦。我们进一步引入了模态感知的旋转位置编码,以减轻异构视觉token之间的干扰,并增强跨任务对齐。在训练过程中,Lance采用分阶段多任务训练范式,结合面向能力的目标和自适应数据调度,以强化语义理解和视觉生成性能。实验结果表明,Lance在图像和视频生成方面显著优于现有的开源统一模型,同时保持了强大的多模态理解能力。项目主页请访问 https://lance-project.github.io。
一句话总结
Lance 是一款轻量级统一多模态模型,通过协同多任务训练支持图像与视频的理解、生成及编辑。该模型采用双流混合专家架构、模态感知旋转位置编码以及自适应分阶段训练策略,在解耦理解与生成路径的同时,在生成任务上大幅超越现有开源模型,并保持了强大的多模态理解能力。
核心贡献
- 提出了 Lance 这款轻量级原生统一模型,能够同时针对图像和视频执行多模态理解、生成与编辑任务。
- 该架构在共享的交错序列上采用双流混合专家设计,并结合模态感知旋转位置编码与分阶段多任务训练范式,在解耦能力路径的同时实现联合上下文学习。
- 实证评估表明,该模型在生成、编辑和理解基准测试中大幅优于现有的开源统一系统,仅使用 3B 激活参数量和 128 块 GPU 的训练预算即达成上述结果。
引言
多模态人工智能正迅速向原生统一范式演进,该范式将理解、推理与生成整合于单一框架内,这对构建更具通用性和实用价值的基座模型至关重要。然而,先前的统一方法在表征层面存在根本性不匹配问题,即理解所需的高级语义特征与视觉合成所需的低级连续表示之间存在差异。此外,现有系统通常仅覆盖狭窄的任务子集,常将视频编辑等复杂操作视为独立的微调步骤,而非与核心理解及生成任务同步优化。为弥补这些不足,研究者利用多任务协同机制开发了 Lance 这款轻量级统一模型,该模型将交错上下文建模与解耦能力路径相结合。此架构使语义理解与视觉合成能够有效交互,同时保留任务特定的专业性,以极低的计算开销实现强大的跨模态性能。
数据集

- 数据集构成与来源:研究团队构建了涵盖图像-文本与视频-文本对的大规模多模态语料库,并收集了来自多样化视觉领域与任务类别的交错理解与生成样本。
- 子集详情:预训练阶段包含约 10 亿张图像-文本样本(涵盖自然场景、人物、物体、知识类及风格化内容)以及 1.4 亿张视频-文本样本(捕捉动态动作、事件与时间过渡)。持续训练阶段包含 273 万张交错理解样本(覆盖图像描述、VQA、OCR、推理、定位、分类、对话及文本生成任务),以及 1060 万张生成样本(包括图像与视频编辑及主体驱动生成)。监督微调阶段采用精心筛选的高质量子集,包含 19 万条图像描述、5000 条视频描述、273 万条理解样本,以及针对两种模态的专用生成、编辑和主体驱动样本。
- 训练使用与混合策略:预训练阶段冻结 VAE 与 ViT 编码器,仅优化多模态主干网络,并采用严格的 1:4 图像-视频采样比例以平衡计算难度并强化时序推理能力。在持续训练期间,研究团队实施渐进式混合策略,逐步提高编辑与主体驱动生成等复杂任务的采样权重,同时降低简单描述类监督信号的比重,总训练量约为 3000 亿 tokens。微调阶段对精选子集采用降低的学习率,以优先保障指令遵循度、视觉一致性与生成精度,而非盲目追求数据规模。
- 处理流程与元数据构建:该流水线采用渐进式分辨率课程学习,从 192p 逐步扩展至 360p 最终达到 480p,并在各阶段启用动态分辨率以提升可扩展性。研究团队构建了任务特定的系统提示词,以明确定义输入输出格式并提供清晰的任务先验,确保模型在统一序列中能够区分异构的理解与生成任务。高质量样本在微调阶段被明确分离并优先处理,以维持严格的标注标准并确保精准的指令对齐。
方法
研究团队采用双流混合专家架构,在单一模型内实现统一的多模态理解与生成,该方法基于两项核心原则:统一上下文建模与解耦能力路径。系统概览请参阅架构图 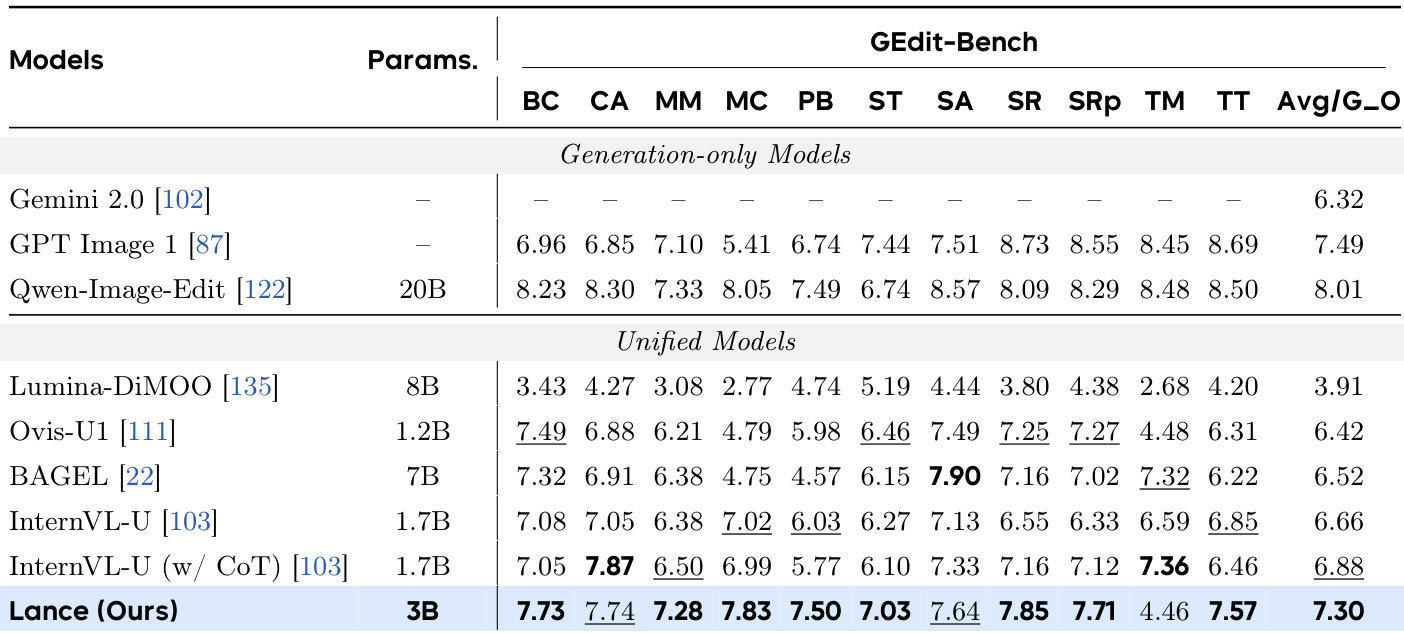 。整体框架处理来自文本、图像和视频的交错输入,将每种模态编码为适配任务的 token 表示。随后,这些异构 token 通过模态感知旋转位置编码组织为共享的交错多模态序列,从而支持跨多种任务格式的统一上下文学习。模型采用基于 Qwen2.5-VL 初始化的双专家主干网络,包含专用的理解专家(LLMUND)与生成专家(LLMGEN)。理解专家处理文本与语义视觉 token 以执行多模态推理与文本生成,而生成专家则基于 VAE 潜在 token 进行视觉合成与编辑。两位专家在同一交错多模态上下文中运行,在保留跨任务交互的同时避免异构目标间的直接竞争。
。整体框架处理来自文本、图像和视频的交错输入,将每种模态编码为适配任务的 token 表示。随后,这些异构 token 通过模态感知旋转位置编码组织为共享的交错多模态序列,从而支持跨多种任务格式的统一上下文学习。模型采用基于 Qwen2.5-VL 初始化的双专家主干网络,包含专用的理解专家(LLMUND)与生成专家(LLMGEN)。理解专家处理文本与语义视觉 token 以执行多模态推理与文本生成,而生成专家则基于 VAE 潜在 token 进行视觉合成与编辑。两位专家在同一交错多模态上下文中运行,在保留跨任务交互的同时避免异构目标间的直接竞争。
统一上下文学习通过将异构输入转换为共享的交错多模态序列来实现。文本指令通过 Qwen2.5-VL 的语言嵌入层进行编码。针对面向理解的视觉输入,采用 Qwen2.5-VL 的 ViT 编码器,该编码器使用 14× 空间与 2× 时间分块,随后进行 2×2 空间合并,以生成紧凑的语义视觉 tokens。针对面向生成的输入,图像或视频通过 Wan2.2 3D 因果 VAE 编码器转换为连续潜在表示,该编码器通过统一潜在空间支持两种模态,其中视频采用 16× 空间下采样与 4× 时间下采样。生成的潜在特征保留了高保真视觉生成所需的低级外观与时序结构。因此,Lance 将每个样本表示为包含文本 token、ViT 语义 token、干净 VAE 潜在 token 与噪声 VAE 潜在 token 的统一交错多模态序列。为处理此类异构序列,Lance 采用广义 3D 因果注意力机制,将序列划分为特定模态的片段,每个片段仅关注前序的干净片段以保留因果依赖关系。在每个片段内部,文本 token 使用因果注意力,而视觉 token 使用双向注意力以捕获空间与时空结构。
解耦能力路径通过专用的专家路径实现。理解专家 LLMUND 主要作用于文本 token 与语义视觉 token,自回归地预测用于多模态理解的目标文本 token。其隐藏状态经语言建模头映射,并通过标准的下一个 token 预测损失进行优化。生成专家 LLMGEN 作用于 VAE 潜在 token,并基于交错多模态上下文预测生成侧的隐藏状态。这些隐藏状态通过 LLM-to-VAE 连接器投影至潜在空间,随后传递至流预测头。生成专家采用流匹配目标进行优化,模型预测干净潜在表示与高斯噪声之间插值潜在表示的速度向量。整体目标函数为理解损失与生成损失的加权和,使模型在保留统一上下文交互的同时,允许语义理解与视觉合成在各自的表示、参数与目标上实现专业化。
为了更好地协调统一上下文序列中的异构视觉 token,研究团队引入了模态感知旋转位置编码(MaPE)。标准的 3D-RoPE 基于时空布局分配位置索引,但未明确区分异构 token 组。MaPE 仅在时间维度上应用模态特定的偏移量,从而将 token 组感知能力注入位置索引中。该设计在全局位置空间中明确分离不同的视觉 token 组,使模型能够更好地区分语义 ViT 特征、干净 VAE 条件与噪声 VAE 目标的作用,同时保留图像与视频内部固有的空间布局与时序连贯性。模态感知旋转位置编码的示意图请参阅  。
。
实验
评估工作采用图像与视频生成、多模态编辑及视频理解的标准基准,并辅以关于训练规模扩展、数据构成与架构设计的消融实验。这些实验验证了统一框架能够持续生成语义对齐的图像与时序连贯的视频,并在编辑任务中精确保留结构细节。进一步分析证实,引入面向理解的与多任务生成数据可显著提升跨任务上下文推理能力,而模态感知位置编码有效降低了异构视觉 token 之间的空间歧义。最终结果表明,在紧凑架构内联合优化生成、编辑与理解任务,能够产出稳健且可扩展的多模态能力。
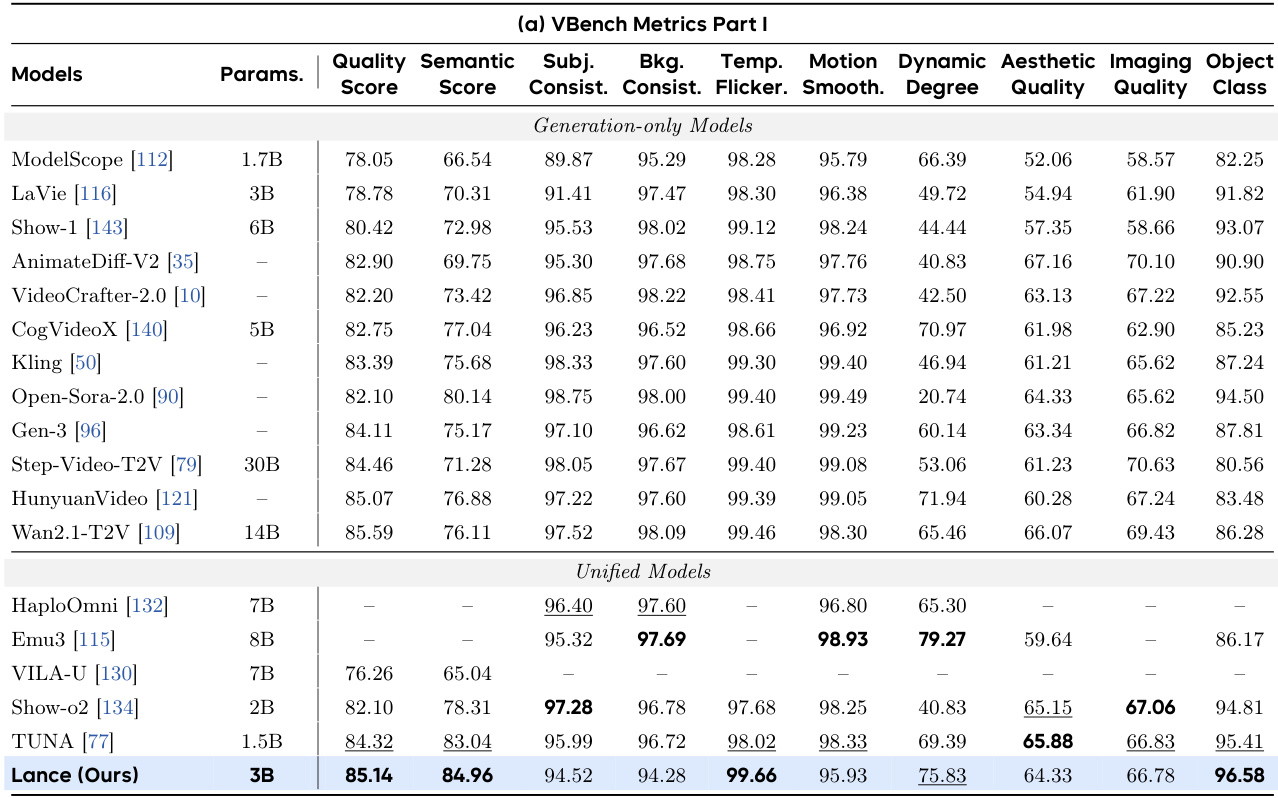
研究团队在图像与视频生成、编辑及理解任务上对统一多模态模型进行了评估。结果表明,该模型在多种基准测试中表现强劲,尤其在视频生成与编辑方面,尽管参数量少于许多专用模型,仍在理解任务中保持具有竞争力的成绩。模型能力随训练数据增加而提升,并受益于多任务学习与模态感知位置编码。在统一模型类别中,该模型在视频生成方面达到顶尖水平,在质量与语义维度均取得优异结果。其图像编辑能力同样具备竞争力,尤其在保持结构连贯性与真实纹理方面表现突出。性能随更大训练预算的提升而增强,并受益于多任务训练,表明生成与理解任务之间存在协同效应。
研究团队在 GEdit-Bench 上评估了模型 Lance 的图像编辑性能,并将其与其他统一模型及仅生成模型进行对比。结果表明,Lance 在统一模型中取得最高综合得分,在多个类别中展现出强大的编辑能力,尤其在背景更换、材质修改与主体替换方面表现优异。该模型在参数量相似或更大的基线模型中取得领先,表明其在紧凑参数预算下具备高效性能。Lance 在 GEdit-Bench 统一模型中综合得分最高。Lance 在背景更换与材质修改等关键编辑类别中表现强劲。Lance 超越多个参数量更大的基线模型,证明其在紧凑模型尺寸下具备极高效率。
研究团队评估了模态感知旋转位置编码(MaPE)对统一多模模型在多项任务(包括图像生成、图像编辑、视频生成与视频理解)上的影响。结果表明,引入 MaPE 持续提升了所有评估任务的性能,其中图像编辑的增益最为显著,这表明 MaPE 通过降低位置歧义增强了跨任务对齐与视觉合成能力。引入 MaPE 改善了图像生成、图像编辑、视频生成与视频理解等所有评估任务的表现。MaPE 带来的最显著改进体现在图像编辑领域,反映出跨任务推理与对齐能力的提升。移除 MaPE 会导致所有任务性能下降,凸显了其在统一多模态建模中维持上下文连贯性与视觉保真度的重要性。
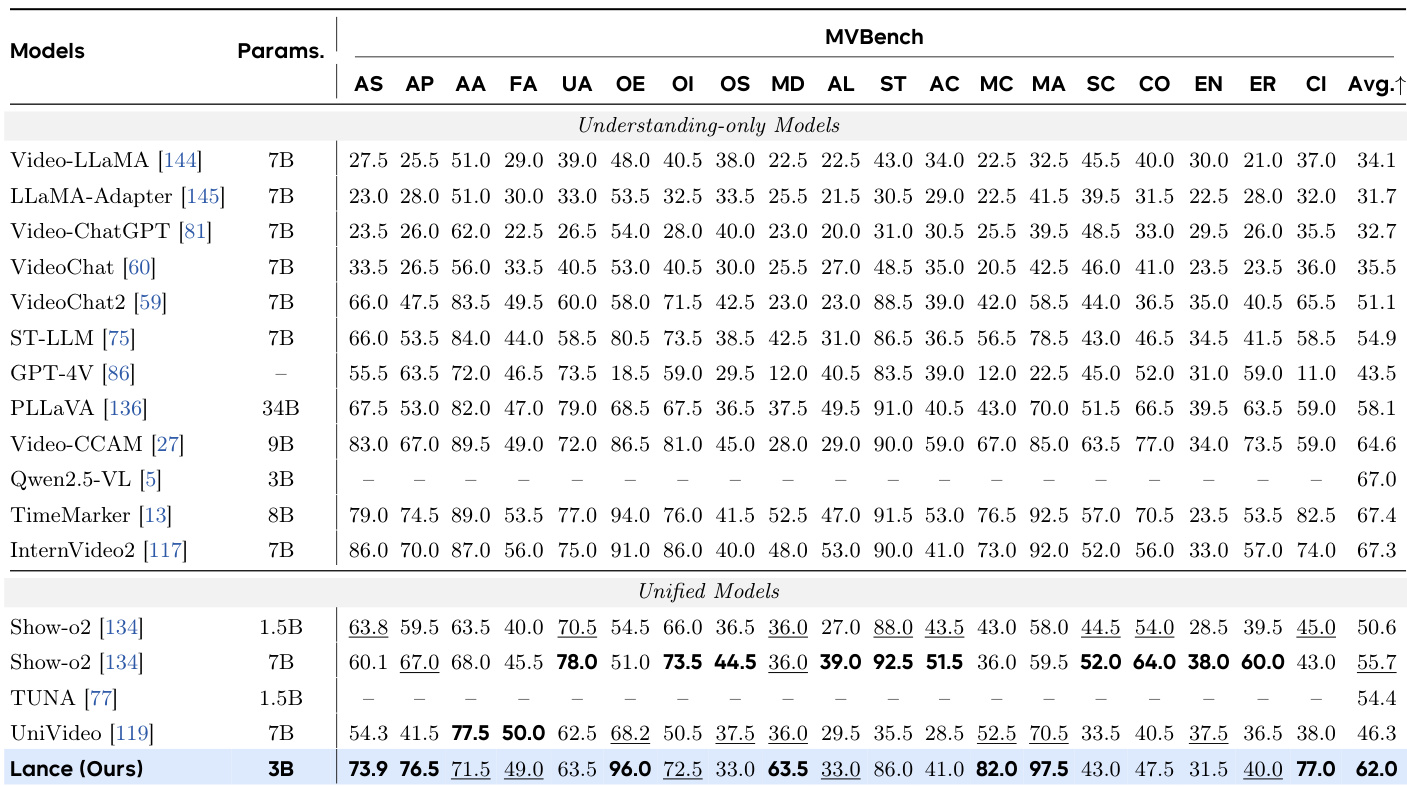
研究团队在视频理解、生成与编辑等多项任务上评估了激活参数量为 3B 的统一多模态模型 Lance。结果表明,Lance 在 MVBench 的统一模型中达到顶尖水平,以显著更少的参数量超越现有模型,同时在生成与理解方面保持强大能力。该模型在视觉质量、语义保真度与时序一致性等多个维度均表现稳健,表明单一框架内成功融合了多样化任务。Lance 在 MVBench 统一模型中综合得分最高,大幅领先参数量多得多的模型。该模型在生成与理解任务上均展现强劲性能,证实了多任务协同的有效性。Lance 在视频理解、生成与编辑中输出高质量结果,凸显了其在多模态应用中的广泛适用性。
研究团队在图像生成、视频生成、图像编辑与视频理解任务上评估了激活参数量为 3B 的统一多模态模型 Lance 的性能。结果表明,Lance 在图像与视频生成基准测试中,性能可与更大规模的模型竞争或达到顶尖水平,同时在图像编辑与视频理解方面展现出强大能力。多任务训练与模态感知位置编码机制进一步提升了模型性能。研究团队分析了训练数据构成与模型扩展的影响,表明增加训练 token 能够提升提示词对齐度、视觉保真度与时序一致性。尽管参数量显著少于竞争模型,Lance 仍在图像生成基准中达到顶尖水平。Lance 展现出强大的多模态编辑能力,尤其在保留图像与视频的结构连贯性与真实纹理方面表现突出。模型性能随训练 token 的增加而提升,并受益于多任务训练,表明跨不同模态与任务的共享学习具有显著有效性。
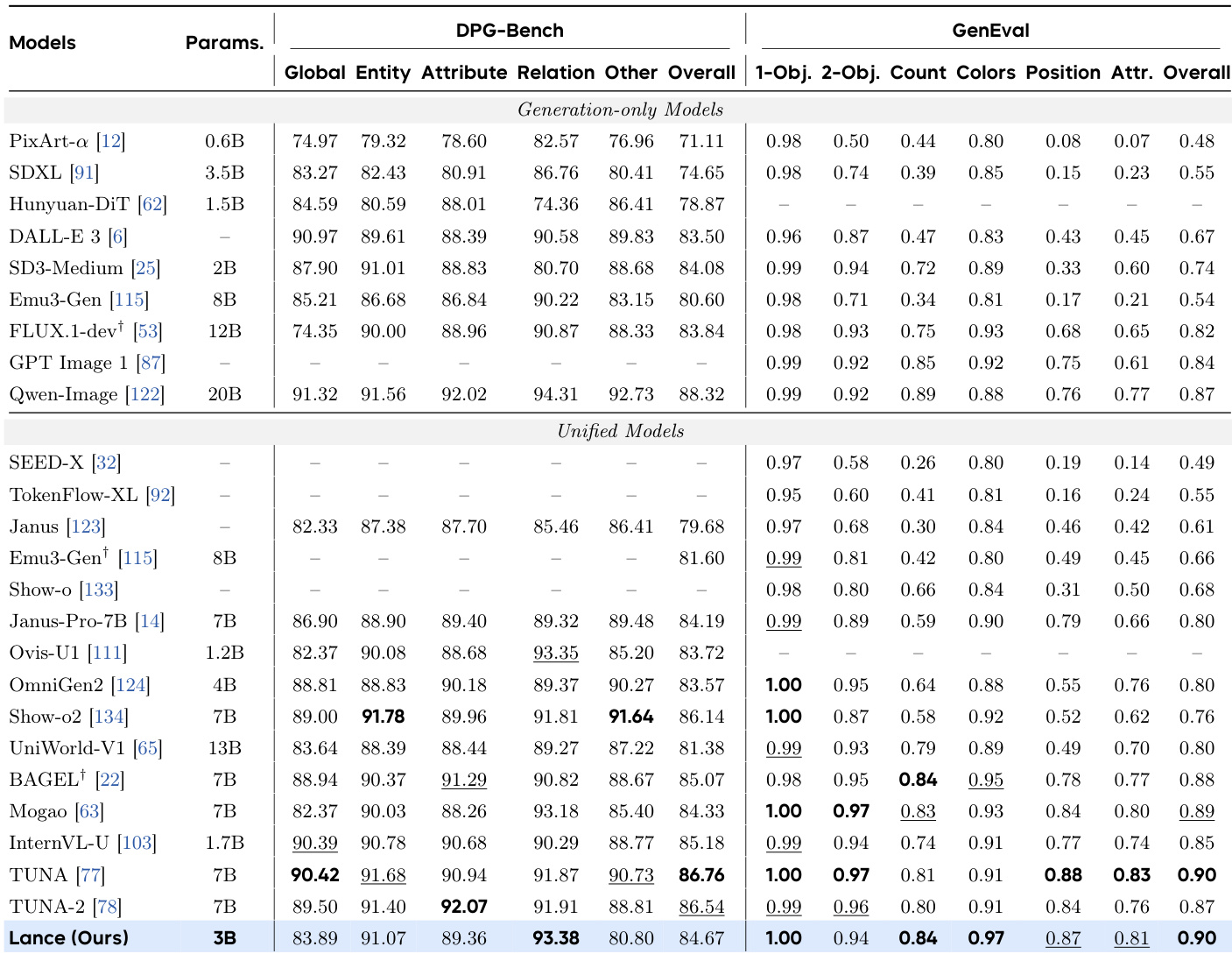
研究团队在图像与视频生成、编辑及理解任务上评估了紧凑的 3B 参数统一多模态模型,以验证其跨模态通用性与架构效率。基准评估证实,该模型在统一架构中提供顶尖性能,有效平衡高保真生成与稳健理解,同时超越更大规模的专用基线模型。消融与对比分析进一步表明,多任务训练与模态感知位置编码持续改善跨任务对齐、结构连贯性与时序一致性。这些定性结果共同表明,跨多样化模态的共享学习能够产生强烈的协同效应,使精简模型在无需牺牲视觉或语义保真度的前提下维持具有竞争力的性能。