HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

現実の大都市における世界シミュレーションモデルのグラウンディング
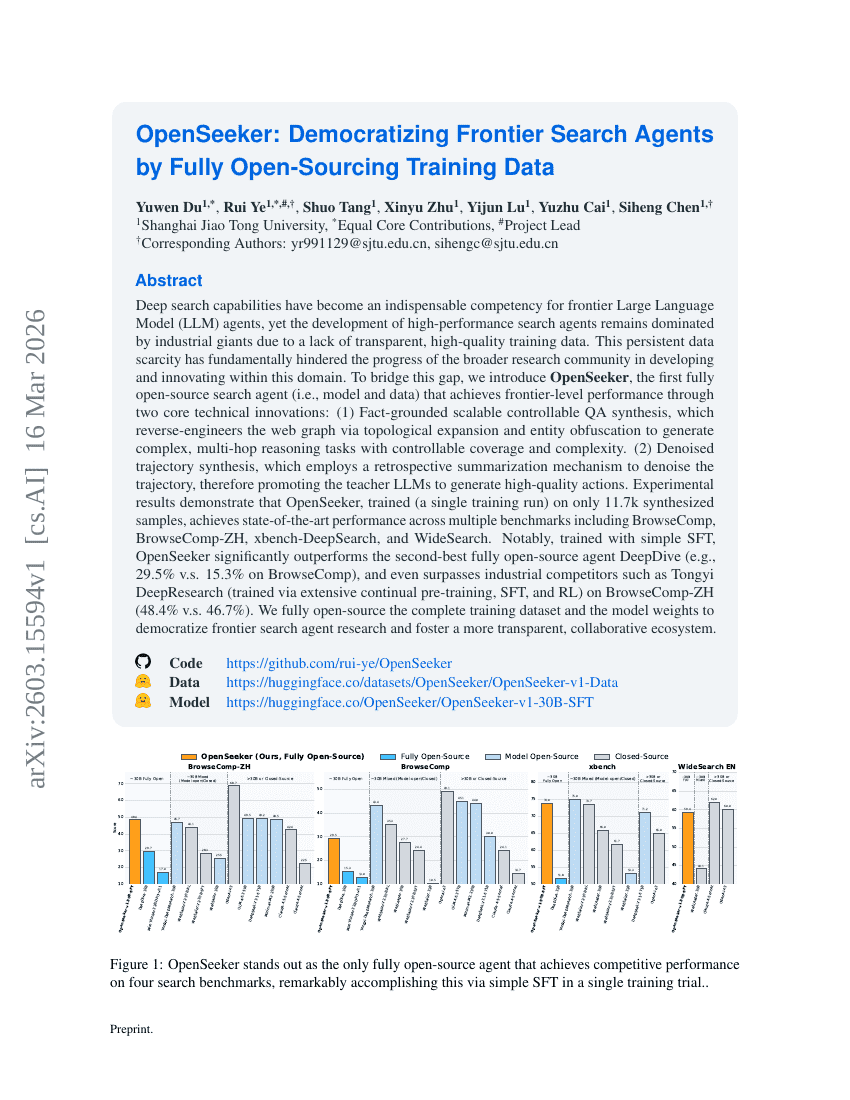
OpenSeeker:トレーニングデータを完全にオープンソース化することで、最先端の検索エージェントの民主化を実現



























現実の大都市における世界シミュレーションモデルのグラウンディング
OpenSeeker:トレーニングデータを完全にオープンソース化することで、最先端の検索エージェントの民主化を実現
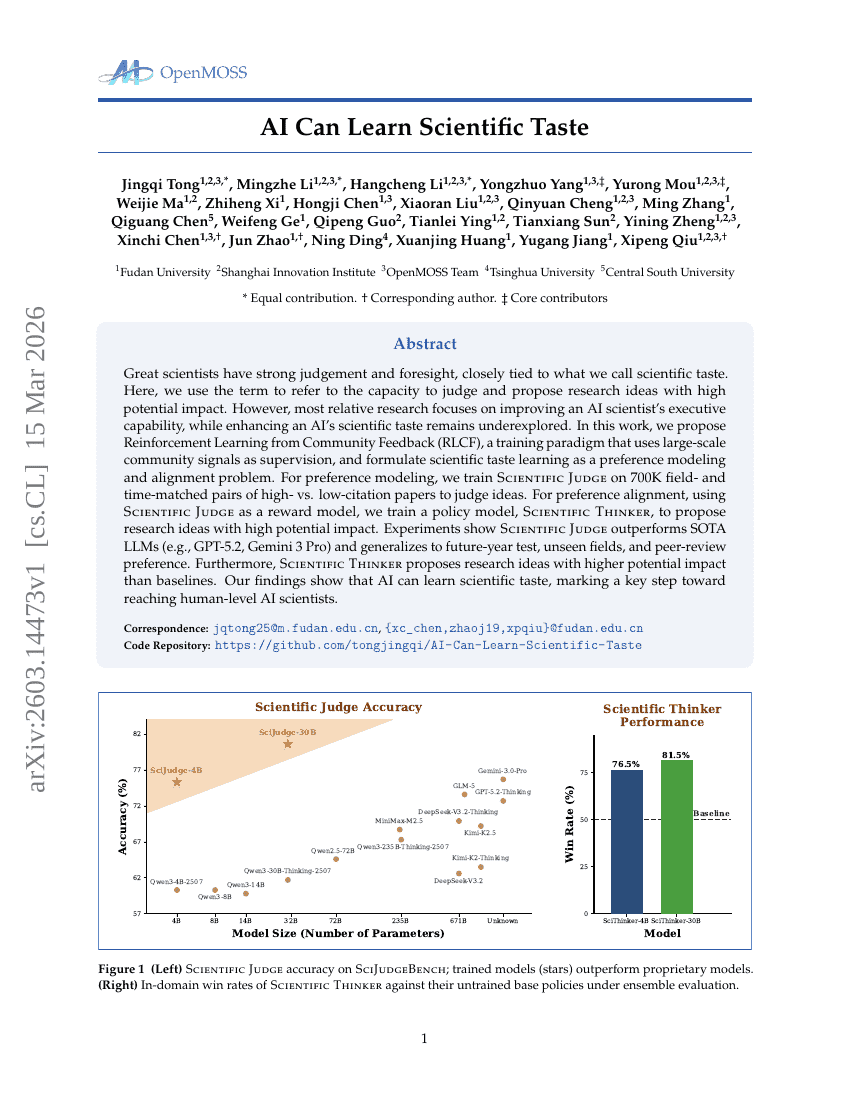
AI Can Learn Scientific Taste
MM-CondChain: 視覚的根拠に基づく深層構成的推論のためのプログラム検証済みベンチマーク
ビジョン・ランゲージモデルはシェルゲームを解決できるか?
OmniForcing:リアルタイムな音視覚生成の潜在能力を解放する
daVinci-Env:大規模スケーラブルなオープン SWE 環境合成
Cheers:パッチの詳細を意味表現から分離することで、統合されたマルチモーダル理解と生成を実現
LMEB:Long-horizon Memory Embedding Benchmark
DreamVideo-Omni:潜在アイデンティティ強化学習によるオムニモーション制御マルチサブジェクト動画カスタマイズ
ShotVerse:テキスト駆動型マルチショット動画生成のための映画撮影カメラ制御の進展
コンピュータ使用エージェントのためのビデオベース報酬モデリング
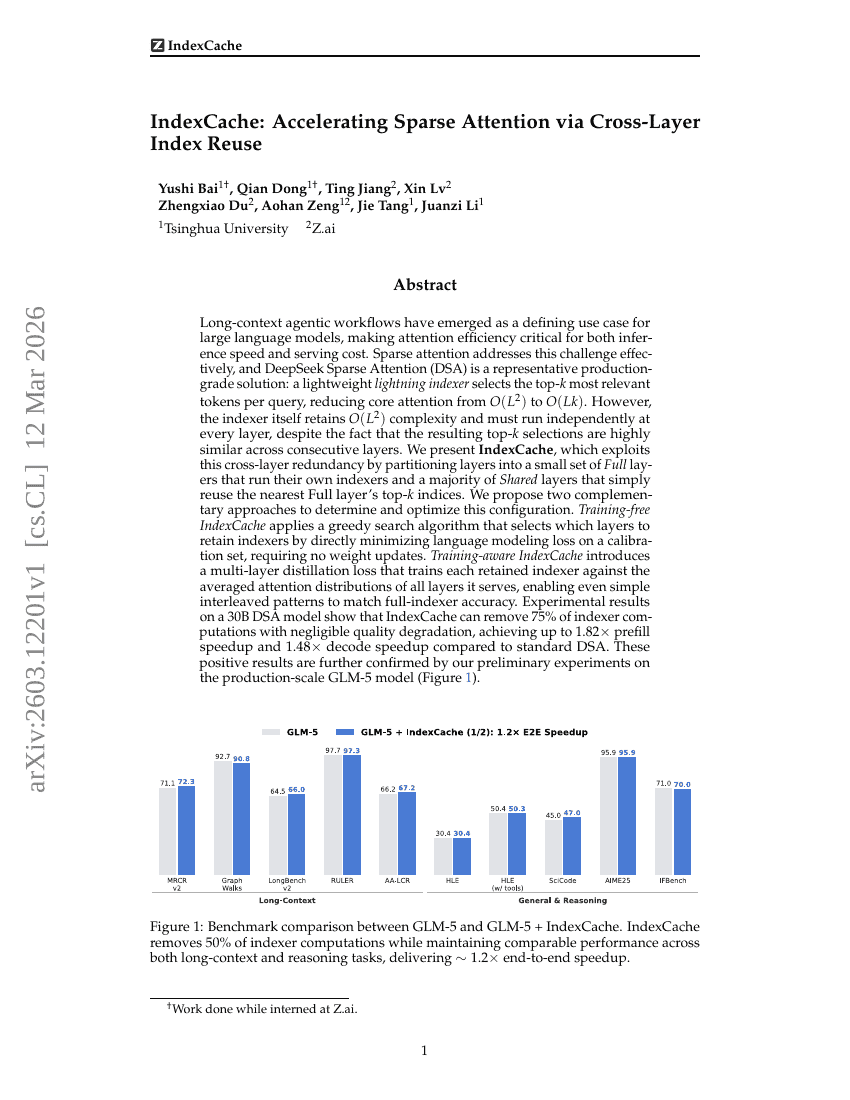
IndexCache: クロスレイヤーインデックスの再利用によるスパースアテンションの高速化
戦略的ナビゲーションか、確率的探索か?エージェントと人間がドキュメントコレクションに対してどのように推論するか
Spatial-TTT: テスト時トレーニングによるストリーミング視覚ベースの空間知能
大規模言語モデルは追随できるか?継続的知識ストリームへのオンライン適応のベンチマーク評価
ReMix:LLM 微調整における LoRA 混合物のための強化学習ルーティング
大規模言語モデルにおけるツール利用のためのコンテキスト内強化学習
MA-EgoQA: 複数の具現化エージェントによる第一人称視点動画からの質問応答
Flash-KMeans:高速かつメモリ効率に優れた厳密 K-Means
OpenClaw-RL: 対話のみによる任意の Agent の訓練
法廷へ VLM を招く:スポーツにおける空間知能のベンチマーク評価
InternVL-U: 理解、推論、生成、編集のための統合マルチモーダルモデルの民主化
MM-Zero:ゼロデータからの自己進化型マルチモデル視覚言語モデル
思考による想起:LLM における推論がパラメトリック知識を解き放つ仕組み
Omni-Diffusion: マスクド離散拡散による統合的マルチモーダル理解と生成
幾何学誘導型強化学習による多視点整合性を持つ 3D シーン編集
CARE-Edit: 文脈的画像編集のための条件感知型エキスパート経路選択
モデルを信頼せよ:分布誘導型信頼度較正
LoGeR:ハイブリッドメモリによる長文脈幾何学的再構成
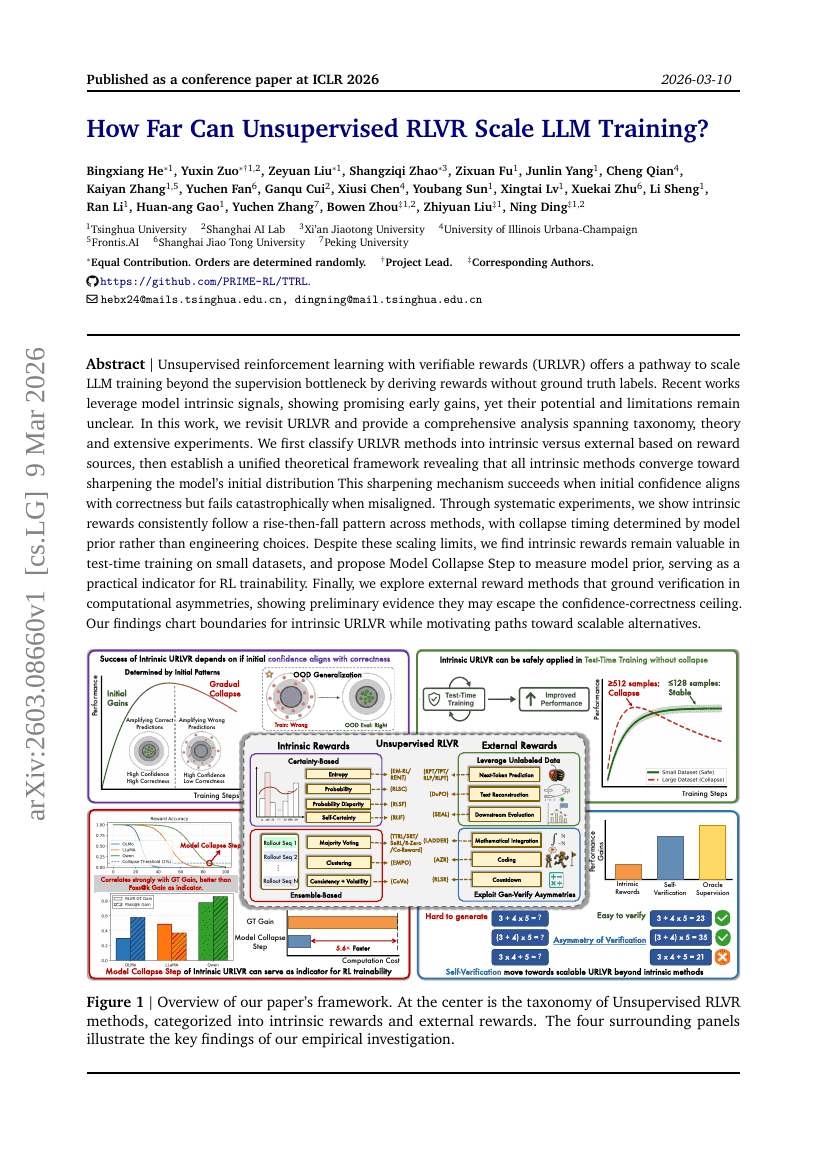
教師なし RLVR が LLM 訓練をどこまで拡張可能か
Holi-Spatial:動画ストリームを包括的な 3D 空間知能へと進化させる
AI Can Learn Scientific Taste
MM-CondChain: 視覚的根拠に基づく深層構成的推論のためのプログラム検証済みベンチマーク
ビジョン・ランゲージモデルはシェルゲームを解決できるか?
OmniForcing:リアルタイムな音視覚生成の潜在能力を解放する
daVinci-Env:大規模スケーラブルなオープン SWE 環境合成
Cheers:パッチの詳細を意味表現から分離することで、統合されたマルチモーダル理解と生成を実現
LMEB:Long-horizon Memory Embedding Benchmark
DreamVideo-Omni:潜在アイデンティティ強化学習によるオムニモーション制御マルチサブジェクト動画カスタマイズ
ShotVerse:テキスト駆動型マルチショット動画生成のための映画撮影カメラ制御の進展
コンピュータ使用エージェントのためのビデオベース報酬モデリング
IndexCache: クロスレイヤーインデックスの再利用によるスパースアテンションの高速化
戦略的ナビゲーションか、確率的探索か?エージェントと人間がドキュメントコレクションに対してどのように推論するか
Spatial-TTT: テスト時トレーニングによるストリーミング視覚ベースの空間知能
大規模言語モデルは追随できるか?継続的知識ストリームへのオンライン適応のベンチマーク評価
ReMix:LLM 微調整における LoRA 混合物のための強化学習ルーティング
大規模言語モデルにおけるツール利用のためのコンテキスト内強化学習
MA-EgoQA: 複数の具現化エージェントによる第一人称視点動画からの質問応答
Flash-KMeans:高速かつメモリ効率に優れた厳密 K-Means
OpenClaw-RL: 対話のみによる任意の Agent の訓練
法廷へ VLM を招く:スポーツにおける空間知能のベンチマーク評価
InternVL-U: 理解、推論、生成、編集のための統合マルチモーダルモデルの民主化
MM-Zero:ゼロデータからの自己進化型マルチモデル視覚言語モデル
思考による想起:LLM における推論がパラメトリック知識を解き放つ仕組み
Omni-Diffusion: マスクド離散拡散による統合的マルチモーダル理解と生成
幾何学誘導型強化学習による多視点整合性を持つ 3D シーン編集
CARE-Edit: 文脈的画像編集のための条件感知型エキスパート経路選択
モデルを信頼せよ:分布誘導型信頼度較正
LoGeR:ハイブリッドメモリによる長文脈幾何学的再構成
教師なし RLVR が LLM 訓練をどこまで拡張可能か
Holi-Spatial:動画ストリームを包括的な 3D 空間知能へと進化させる