HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

PrismAudio:動画から音声への生成のための分解型チェーン・オブ・ソートと多次元報酬

LeWorldModel:画素からの安定したエンドツーエンド型結合埋め込み予測アーキテクチャ




























PrismAudio:動画から音声への生成のための分解型チェーン・オブ・ソートと多次元報酬
LeWorldModel:画素からの安定したエンドツーエンド型結合埋め込み予測アーキテクチャ
FlowScene:マルチモーダルグラフ補正フローによるスタイル一貫性を持つ屋内シーン生成
LumosX: 個別化ビデオ生成のための、任意のアイデンティティとその属性との関連付け
LLM 向けの Y-Combinator:λ-Calculus による Long-Context Rot の解決
ProactiveBench: Multimodal Large Language Models における Proactiveness の Benchmarking
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
Astrolabe: 蒸留された自己回帰型動画モデルのための前進プロセス強化学習の制御
HopChain: 汎用性のある視覚言語推論のためのマルチホップデータ合成
Diffusion ベースの Discrete Motion Tokenizer による意味条件と運動学的条件の橋渡し
FASTER: リアルタイムフロー VLAs の再考
3DreamBooth:高忠実度3D被写体駆動型動画生成モデル
SAMA: 命令付きビデオ編集のための因子分解セマンティックアンカーと運動整合
生成モデルは空間を理解する:シーン理解のための暗黙的 3D 事前知識の解放
Efficient Reasoning with Balanced Thinking
行動に先立ち視察せよ:ビジョン・ランゲージ・アクションモデルのためのビジョン基盤表現の強化
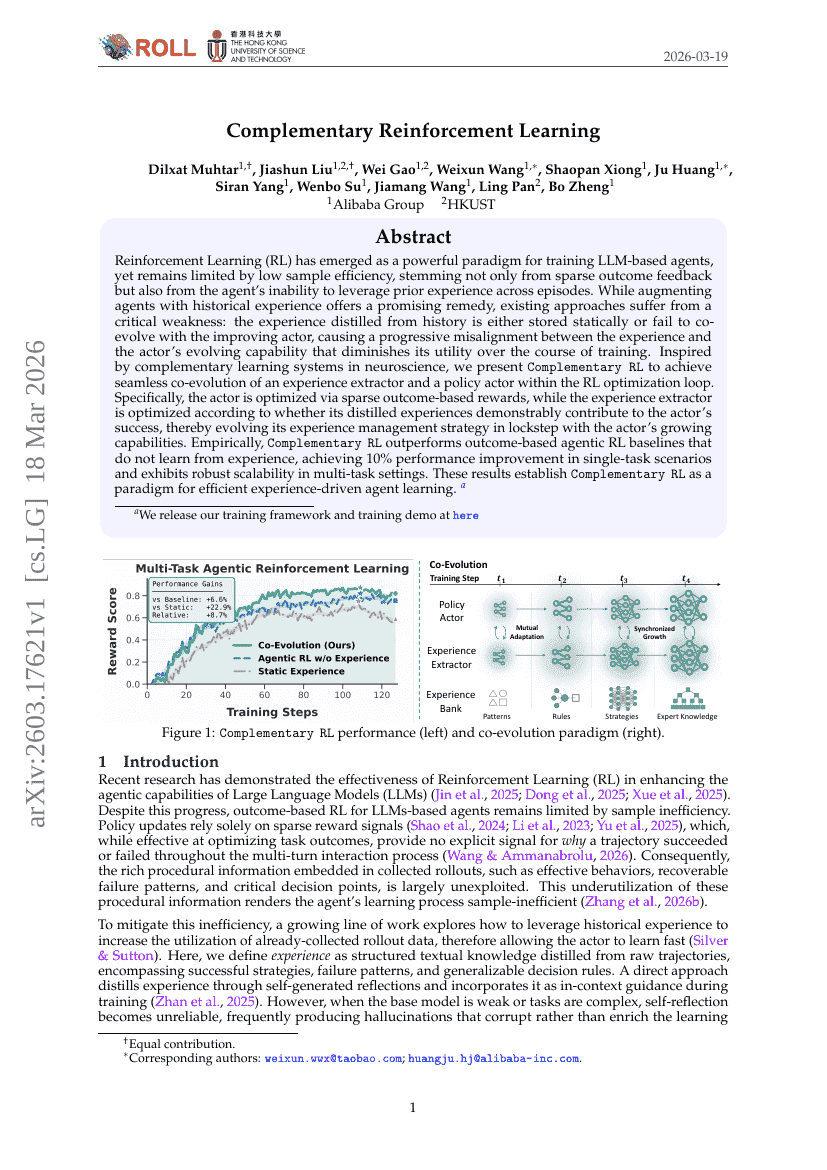
補完的強化学習
アライメントは言語モデルを記述的ではなく規範的にする
MosaicMem: 制御可能なビデオ世界モデルのためのハイブリッド空間メモリ
MetaClaw: Just Talk -- 自然環境下でメタ学習し進化するエージェント
Video-CoE: Chain of Events を用いた Video Event Prediction の強化
FunCineForge: 多様な映画シーンにおけるZero-Shot Movie Dubbingを実現するための統一データセット・ツールキットおよびモデル
Large Language ModelsのためのIn-Context Watermarks
WorldCam: カメラポーズを統一的な幾何学的表現として用いたインタラクティブな自己回帰的3Dゲームワールド
動画推論の解明
Kinema4D:時空間具象シミュレーションのための運動学的 4D 世界モデルリング
Qianfan-OCR: 文書知能のための統合型エンドツーエンドモデル
InCoder-32B:産業シナリオ向けコード基盤モデル
MiroThinker-1.7 & H1: 検証による高負荷研究エージェントの実現に向けて
HSImul3R:シミュレーション対応型人間・シーン相互作用の物理ループ内再構成
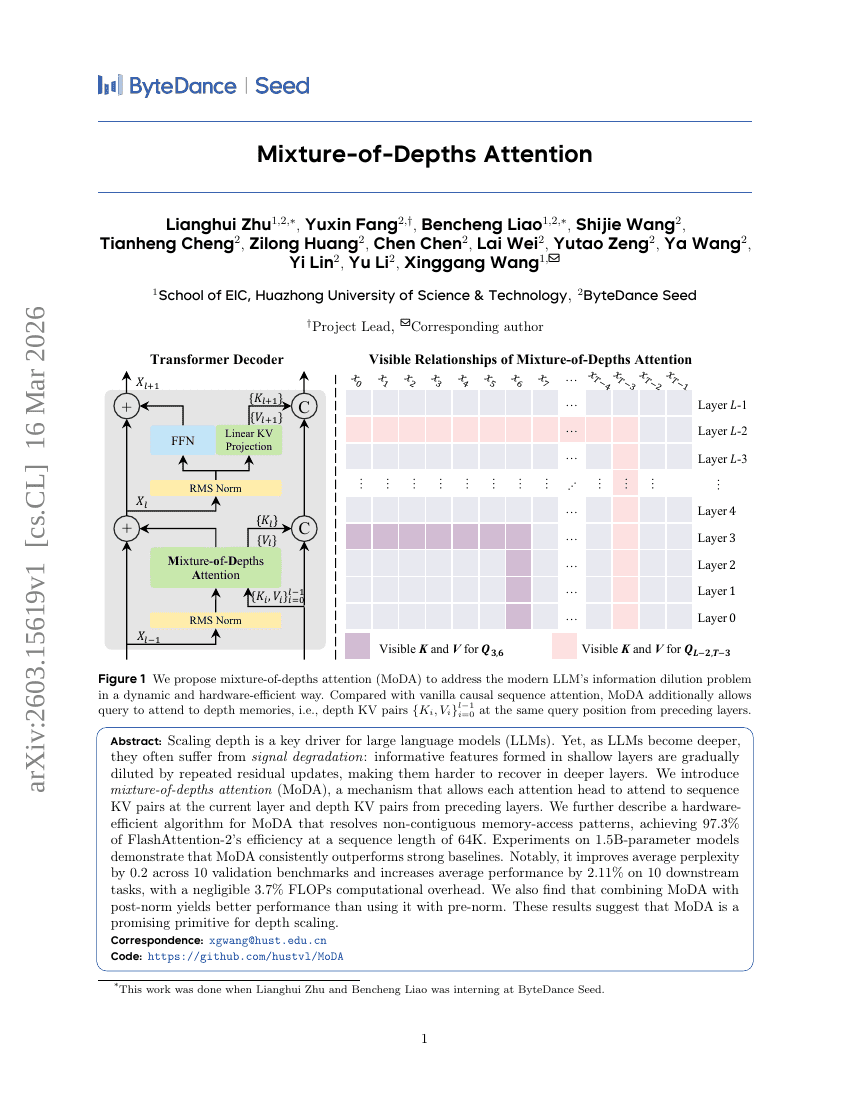
Mixture-of-Depths Attention
アテンション残差
FlowScene:マルチモーダルグラフ補正フローによるスタイル一貫性を持つ屋内シーン生成
LumosX: 個別化ビデオ生成のための、任意のアイデンティティとその属性との関連付け
LLM 向けの Y-Combinator:λ-Calculus による Long-Context Rot の解決
ProactiveBench: Multimodal Large Language Models における Proactiveness の Benchmarking
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
Astrolabe: 蒸留された自己回帰型動画モデルのための前進プロセス強化学習の制御
HopChain: 汎用性のある視覚言語推論のためのマルチホップデータ合成
Diffusion ベースの Discrete Motion Tokenizer による意味条件と運動学的条件の橋渡し
FASTER: リアルタイムフロー VLAs の再考
3DreamBooth:高忠実度3D被写体駆動型動画生成モデル
SAMA: 命令付きビデオ編集のための因子分解セマンティックアンカーと運動整合
生成モデルは空間を理解する:シーン理解のための暗黙的 3D 事前知識の解放
Efficient Reasoning with Balanced Thinking
行動に先立ち視察せよ:ビジョン・ランゲージ・アクションモデルのためのビジョン基盤表現の強化
補完的強化学習
アライメントは言語モデルを記述的ではなく規範的にする
MosaicMem: 制御可能なビデオ世界モデルのためのハイブリッド空間メモリ
MetaClaw: Just Talk -- 自然環境下でメタ学習し進化するエージェント
Video-CoE: Chain of Events を用いた Video Event Prediction の強化
FunCineForge: 多様な映画シーンにおけるZero-Shot Movie Dubbingを実現するための統一データセット・ツールキットおよびモデル
Large Language ModelsのためのIn-Context Watermarks
WorldCam: カメラポーズを統一的な幾何学的表現として用いたインタラクティブな自己回帰的3Dゲームワールド
動画推論の解明
Kinema4D:時空間具象シミュレーションのための運動学的 4D 世界モデルリング
Qianfan-OCR: 文書知能のための統合型エンドツーエンドモデル
InCoder-32B:産業シナリオ向けコード基盤モデル
MiroThinker-1.7 & H1: 検証による高負荷研究エージェントの実現に向けて
HSImul3R:シミュレーション対応型人間・シーン相互作用の物理ループ内再構成
Mixture-of-Depths Attention
アテンション残差