HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

ManCAR:順次推薦における多様体制約付き潜在的推論と適応的テスト時計算

VLANeXt:強力なVLAモデル構築のためのレシピ






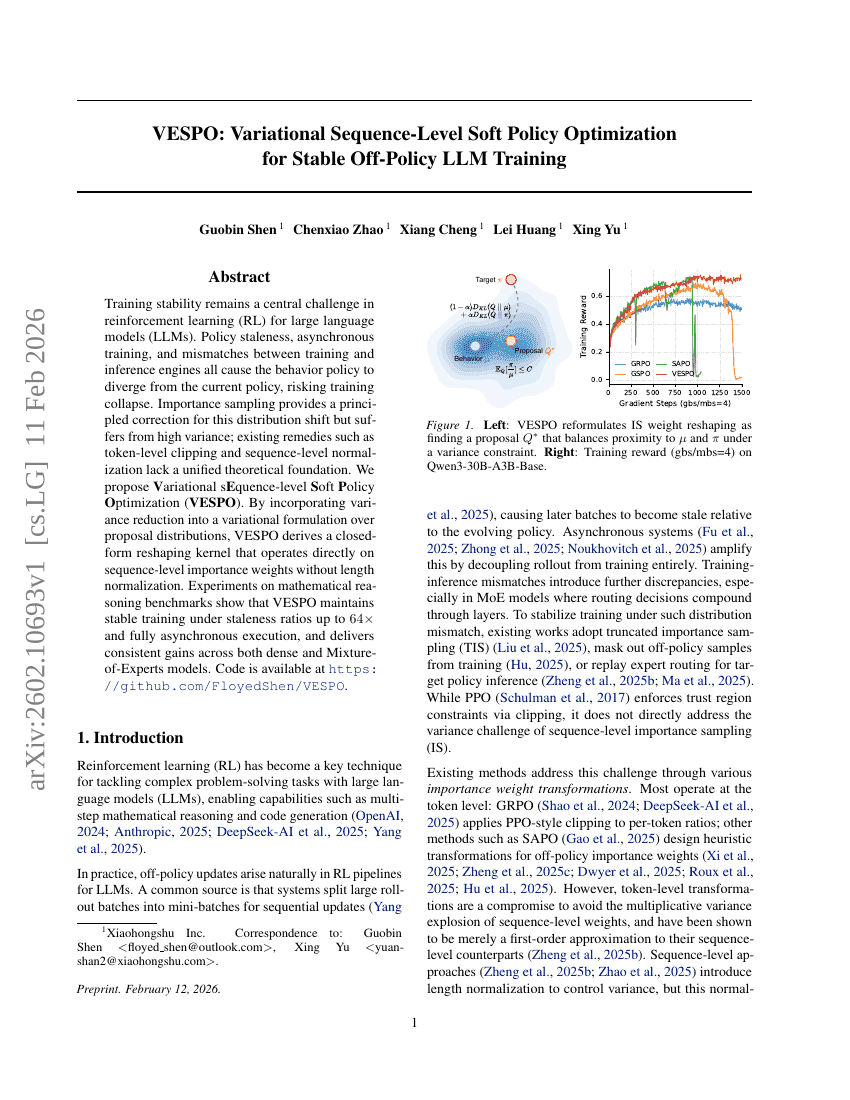
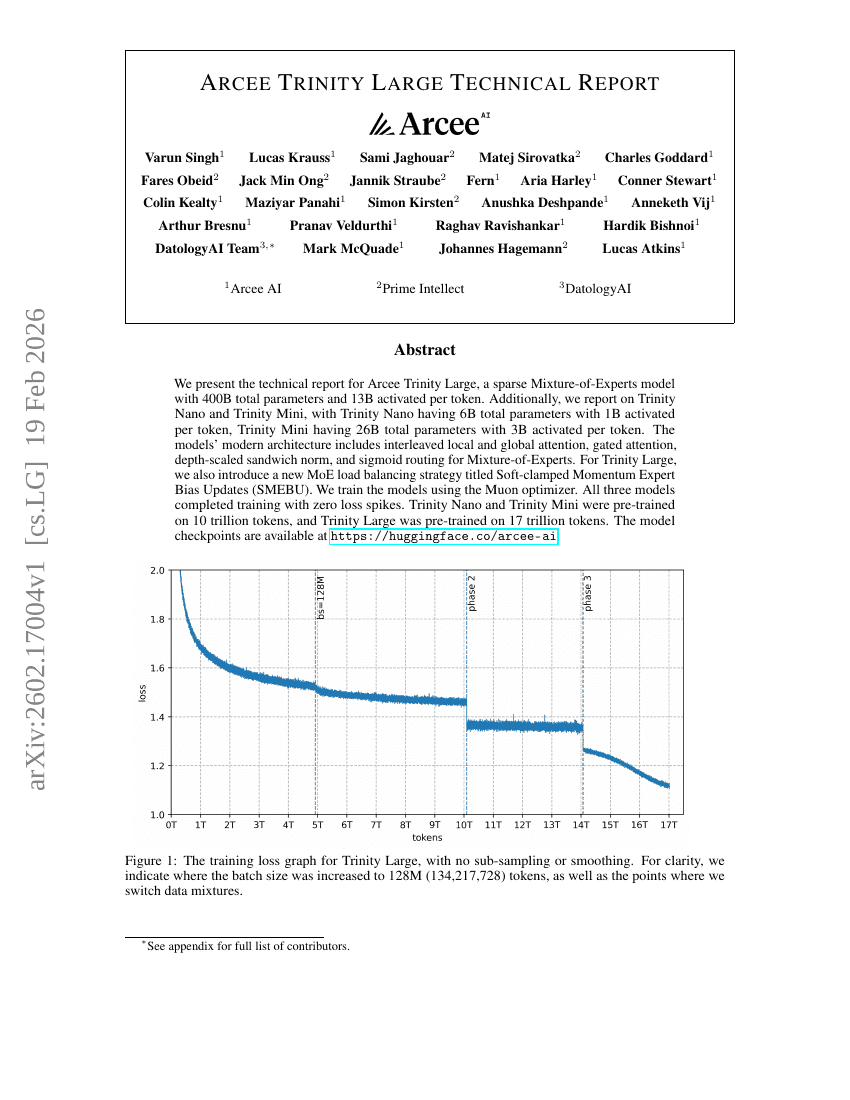













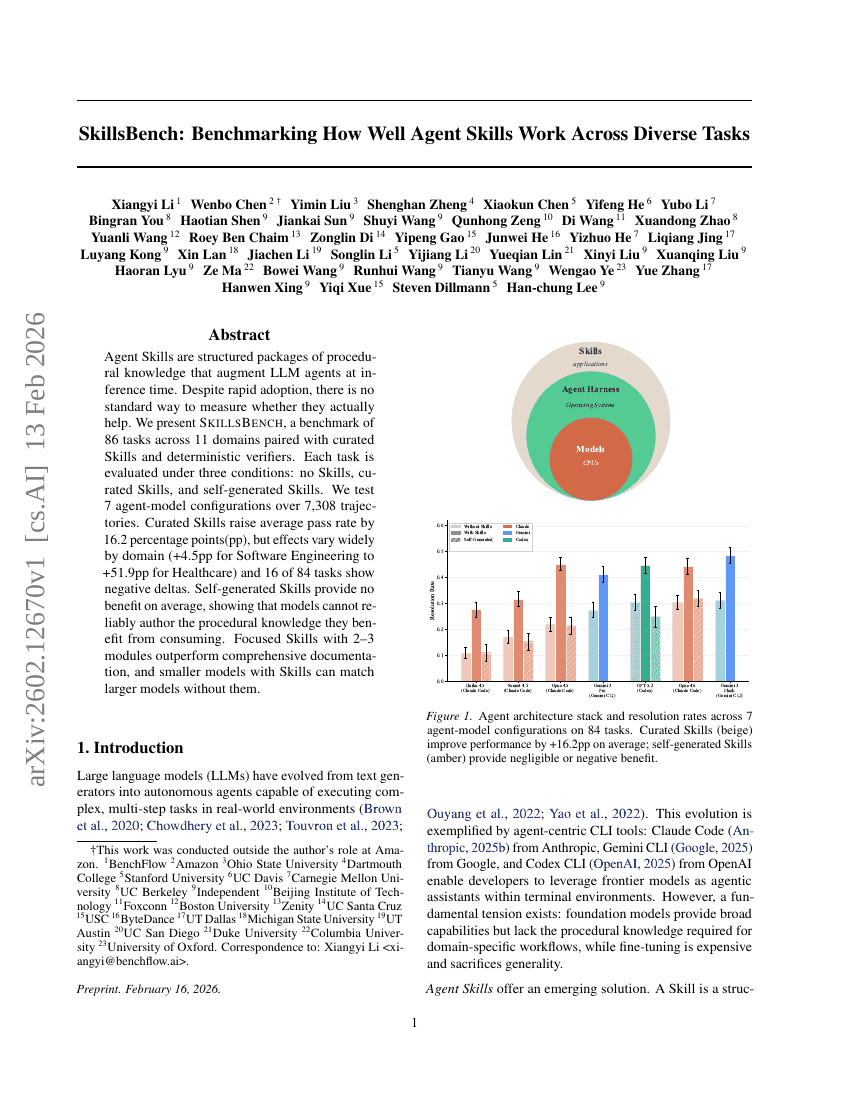

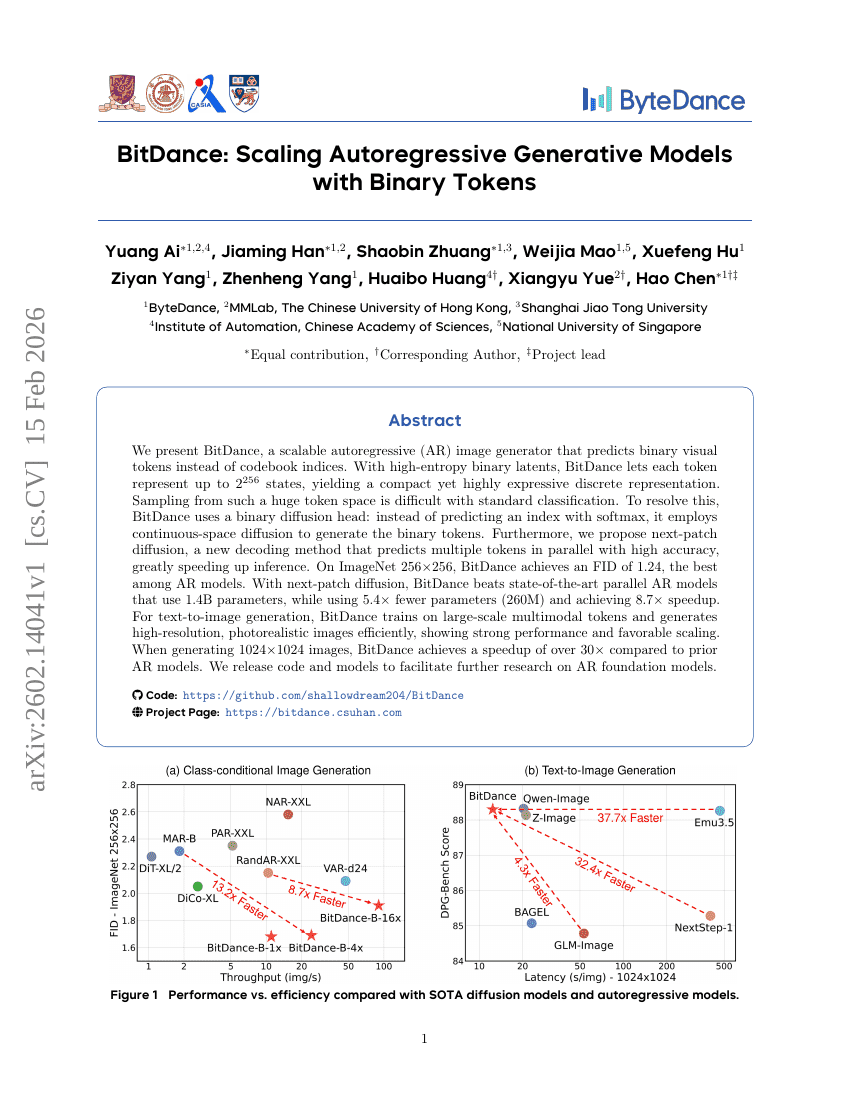





ManCAR:順次推薦における多様体制約付き潜在的推論と適応的テスト時計算
VLANeXt:強力なVLAモデル構築のためのレシピ
非常に大きなビデオ推論スイート
視覚情報ゲインを用いた大規模視覚言語モデルの選択的訓練
DeepVision-103K:視覚的に多様で広範なカバーを備え、検証可能な多モーダル推論向けの数学データセット
SARAH:空間認識型リアルタイムエージェント人間
EgoPush:モバイルロボット向けエゴセントリック多対象再配置のエンドツーエンド学習
生成された現実:手とカメラ操作を用いたインタラクティブな動画生成による人間中心の世界シミュレーション
VESPO:安定したオフポリシー LLM 学習のための変分シーケンスレベルソフトポリシー最適化
アーシー・トライニティ ラージテクニカルレポート
実践におけるフロンティアAIリスク管理フレームワーク:リスク分析技術報告書 v1.5
ユニファイド・ラテンス(UL):ラテンスをどのように訓練するか
Mobile-Agent-v3.5:マルチプラットフォーム基盤GUIエージェント
SpargeAttention2:ハイブリッドTop-k+Top-pマスキングおよび蒸留微調整を用いたトレーニング可能なスパースアテンション
AutoWebWorld:有限状態機械を用いた無限に検証可能なWeb環境の合成
無限クライアントサーバーシステムに対するボーデッドモデルチェック
リトリーブ増強モデルはLLMに比べてどの程度の推論能力を追加するのか?ハイブリッド知識上のマルチホップ推論のためのベンチマーキングフレームワーク
ビジョン・ワームホール:異種マルチエージェントシステムにおける潜在空間通信
パニーニ:構造化メモリを用いたトークン空間における継続的学習
ResearchGym:現実世界のAI研究における言語モデルエージェントの評価
エージェントAIシステムの構成を学ぶ
AIエージェント社会にソーシャリゼーションは生じるか? Moltbookを用いた事例研究
スパース自己符号化器の健全性チェック:SAEはランダムベースラインを上回るか?
SkillsBench:多様なタスクにおけるエージェントスキルの効果をベンチマークする
GLM-5:バイブコーディングからエージェント工学へ
ビットダンス:バイナリトークンを用いた自己回帰型生成モデルのスケーリング
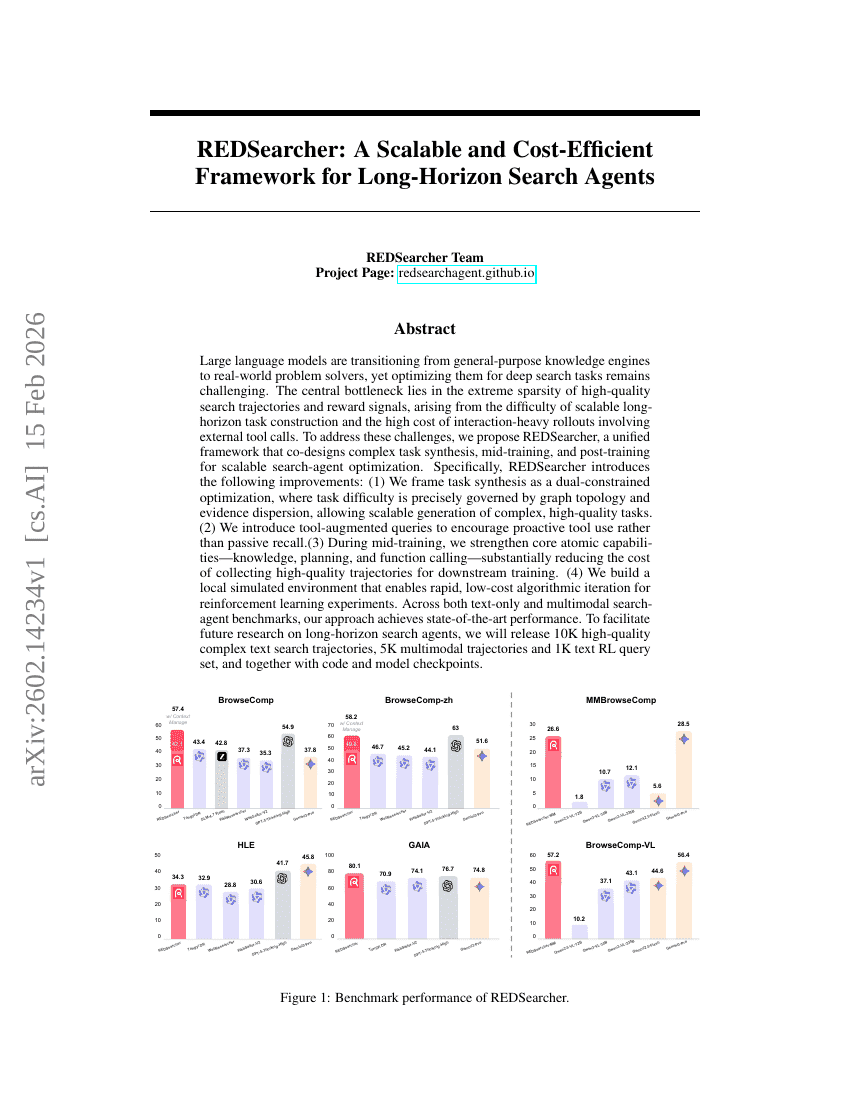
REDSearcher:長期予測用検索エージェント向けのスケーラブルでコスト効率の高いフレームワーク
Qute: 量子ネイティブデータベースへ向けて
InnoEval:研究アイデア評価を知識に基づく多視点推論問題として捉える
クエリをアンカーとする:大規模言語モデルを用いたシナリオ適応型ユーザ表現
SemanticMoments:第三モーメント特徴を用いた訓練不要なモーション類似性
RLinf-Co:VLAモデル向けの強化学習に基づくシミュレーション-現実共訓練手法
非常に大きなビデオ推論スイート
視覚情報ゲインを用いた大規模視覚言語モデルの選択的訓練
DeepVision-103K:視覚的に多様で広範なカバーを備え、検証可能な多モーダル推論向けの数学データセット
SARAH:空間認識型リアルタイムエージェント人間
EgoPush:モバイルロボット向けエゴセントリック多対象再配置のエンドツーエンド学習
生成された現実:手とカメラ操作を用いたインタラクティブな動画生成による人間中心の世界シミュレーション
VESPO:安定したオフポリシー LLM 学習のための変分シーケンスレベルソフトポリシー最適化
アーシー・トライニティ ラージテクニカルレポート
実践におけるフロンティアAIリスク管理フレームワーク:リスク分析技術報告書 v1.5
ユニファイド・ラテンス(UL):ラテンスをどのように訓練するか
Mobile-Agent-v3.5:マルチプラットフォーム基盤GUIエージェント
SpargeAttention2:ハイブリッドTop-k+Top-pマスキングおよび蒸留微調整を用いたトレーニング可能なスパースアテンション
AutoWebWorld:有限状態機械を用いた無限に検証可能なWeb環境の合成
無限クライアントサーバーシステムに対するボーデッドモデルチェック
リトリーブ増強モデルはLLMに比べてどの程度の推論能力を追加するのか?ハイブリッド知識上のマルチホップ推論のためのベンチマーキングフレームワーク
ビジョン・ワームホール:異種マルチエージェントシステムにおける潜在空間通信
パニーニ:構造化メモリを用いたトークン空間における継続的学習
ResearchGym:現実世界のAI研究における言語モデルエージェントの評価
エージェントAIシステムの構成を学ぶ
AIエージェント社会にソーシャリゼーションは生じるか? Moltbookを用いた事例研究
スパース自己符号化器の健全性チェック:SAEはランダムベースラインを上回るか?
SkillsBench:多様なタスクにおけるエージェントスキルの効果をベンチマークする
GLM-5:バイブコーディングからエージェント工学へ
ビットダンス:バイナリトークンを用いた自己回帰型生成モデルのスケーリング
REDSearcher:長期予測用検索エージェント向けのスケーラブルでコスト効率の高いフレームワーク
Qute: 量子ネイティブデータベースへ向けて
InnoEval:研究アイデア評価を知識に基づく多視点推論問題として捉える
クエリをアンカーとする:大規模言語モデルを用いたシナリオ適応型ユーザ表現
SemanticMoments:第三モーメント特徴を用いた訓練不要なモーション類似性
RLinf-Co:VLAモデル向けの強化学習に基づくシミュレーション-現実共訓練手法