Command Palette
Search for a command to run...
MA-EgoQA: 複数の具現化エージェントによる第一人称視点動画からの質問応答
MA-EgoQA: 複数の具現化エージェントによる第一人称視点動画からの質問応答
Kangsan Kim Yanlai Yang Suji Kim Woongyeong Yeo Youngwan Lee Mengye Ren Sung Ju Hwang
概要
具身化モデルの能力が飛躍的に向上するにつれ、将来は人間が職場や家庭において複数の具身型AIエージェントと協働するようになることが予想されます。人間ユーザーとマルチエージェントシステムとの間の円滑なコミュニケーションを実現するためには、エージェントから並行的に流入する情報を解釈し、各問い合わせに対して適切な文脈を参照することが不可欠です。現状の課題としては、動画形式で提供される膨大な個別の感覚入力情報を効果的に圧縮・伝達すること、ならびに複数の第一人称視点(egocentric)動画を適切に集約してシステムレベルの記憶を構築することが挙げられます。本研究では、まず、複数の具身型エージェントから同時に収集された複数の長期的な第一人称視点動画の理解という新たな問題系を形式化して定義します。この方向性の研究を促進するため、本シナリオにおける既存モデルを体系的に評価するためのベンチマーク「MultiAgent-EgoQA(MA-EgoQA)」を提案します。MA-EgoQAは、第一人称視点ストリームに特化した1,700件の質問を提供し、社会的相互作用、タスク協調、心の理論、時間的推論、環境との相互作用という5つのカテゴリーに分類されます。さらに、MA-EgoQA用の簡易ベースラインモデル「EgoMAS」を提案します。EgoMASは、具身型エージェント間での共有メモリとエージェントごとの動的検索を活用する仕組みを備えています。MA-EgoQA上での多様なベースラインモデルおよびEgoMASに対する包括的な評価を通じて、現在の手法は複数の第一人称視点ストリームを効果的に処理できないことを明らかにしました。この結果は、エージェント間におけるシステムレベルの理解を今後さらに進展させる必要性を浮き彫りにしています。コードおよびベンチマークは、https://ma-egoqa.github.io で公開されています。
One-sentence Summary
Researchers from KAIST, New York University, and collaborators introduce MA-EgoQA, a benchmark for answering questions across multiple long-horizon egocentric video streams, alongside EgoMAS, a baseline using shared memory and dynamic retrieval to outperform existing models in complex multi-agent scenarios.
Key Contributions
- The paper addresses the critical challenge of interpreting parallel sensory inputs from multiple embodied agents to enable effective human-AI communication and system-level memory aggregation.
- It introduces MultiAgent-EgoQA, a new benchmark featuring 1.7k questions across five categories like social interaction and temporal reasoning, derived from long-horizon egocentric video streams.
- The authors propose EgoMAS, a baseline model using shared memory and dynamic retrieval that outperforms existing approaches by 4.48% and demonstrates the limitations of current video LLMs on this task.
Introduction
As embodied AI agents become common in shared environments like homes and workplaces, the ability for humans to query these multi-agent systems for progress monitoring or anomaly detection is critical for transparency and control. Prior research has largely focused on task allocation and action execution, leaving a significant gap in systems that can integrate long-horizon egocentric video streams from multiple agents to answer complex questions. Existing video models struggle with the massive data volume generated over days and fail to effectively aggregate experiences across different agents to form a coherent system-level memory. To address this, the authors introduce MA-EgoQA, a new benchmark featuring 1.7k questions across five reasoning categories derived from six agents operating over seven days. They also propose EgoMAS, a baseline model that utilizes shared memory and agent-wise dynamic retrieval to efficiently locate relevant events, demonstrating that current state-of-the-art models cannot yet handle the complexities of multi-agent egocentric understanding.
Dataset
MA-EgoQA Dataset Overview
-
Dataset Composition and Sources The authors construct MA-EgoQA using the EgoLife dataset, which consists of super-long egocentric video recordings from six individuals wearing camera-equipped glasses over seven consecutive days in a shared house. This foundation allows the benchmark to evaluate reasoning across multiple, temporally aligned video streams rather than relying on single-agent assumptions found in prior work.
-
Key Details for Each Subset The benchmark contains 1,741 high-quality multiple-choice questions distributed across five distinct categories designed to capture unique multi-agent dynamics:
- Social Interaction (SI): Evaluates grounding of conversations and affiliative behaviors, including 15.9k generated single-span and multi-span samples.
- Task Coordination (TC): Focuses on role assignment and goal completion, featuring 16.3k multi-span samples alongside single-span variants.
- Theory of Mind (ToM): Assesses reasoning about the mental states, beliefs, and intentions of others.
- Temporal Reasoning (TR): Divided into concurrency and comparison subcategories to test timeline alignment across agents.
- Environmental Interaction (EI): Tracks object usage and environmental state changes distributed among agents.
-
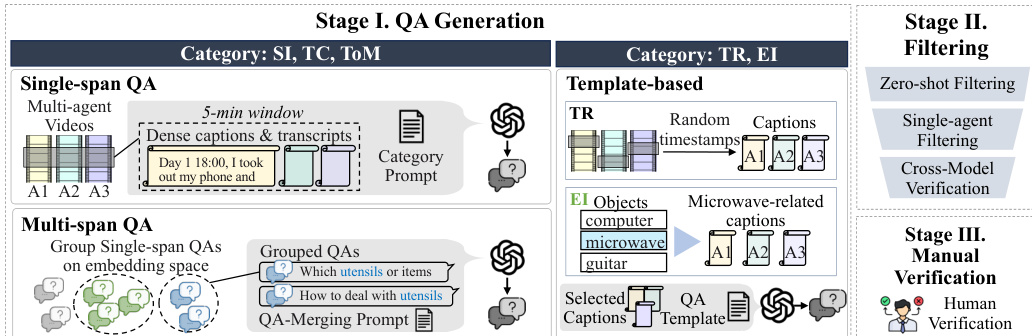
Data Usage and Generation Strategy The authors employ a hybrid generation pipeline to create the dataset, utilizing GPT-4o and GPT-5 for candidate creation followed by rigorous filtering.
- Open-ended Categories (SI, TC, ToM): The team generates large pools of samples by providing 5-minute video segments with dense captions and transcripts to the model, instructing it to create questions grounded by at least two agents.
- Structured Categories (TR, EI): The authors use predefined templates and specific temporal windows (30 seconds to 1 hour) to generate queries regarding event ordering and object interaction frequency.
- Multi-span Construction: For SI and TC, the authors group semantically similar single-span questions using cosine similarity on text embeddings to synthesize complex questions requiring reasoning across non-contiguous time windows.
-
Processing and Quality Control To ensure the benchmark is challenging and strictly multi-agent, the authors implement a multi-stage filtering and verification process:
- LLM Filtering: Candidates undergo zero-shot testing to remove trivial questions and single-agent filtering to eliminate samples answerable by one person's memory.
- Cross-model Validation: External models (Gemini-2.5-Flash and Claude-Sonnet-4) verify correctness and option validity to prevent model-specific biases.
- Human Verification: Four human reviewers manually inspect 3,436 candidates against full video and transcript context, ultimately selecting the final 1,741 samples for the benchmark.
Method
The authors propose EgoMAS (Egocentric Multi-Agent System), a centralized, training-free baseline designed to address the challenges of multi-agent egocentric reasoning. The system operates through a two-stage architecture comprising an event-based shared memory and an agent-wise dynamic retrieval mechanism.
Event-based Shared Memory To achieve a system-level global understanding, the system aggregates fragmented events from multiple agents. At every 10-minute interval, each embodied agent provides a caption summarizing its observations. A centralized manager then integrates these individual captions into a system-level summary. Rather than producing a flat textual condensation, the manager identifies key events across agents and explicitly records the corresponding 4W1H fields: When, What, Where, Who, and How. This produces a coherent global memory that aligns agent perspectives while preserving critical details for reasoning.
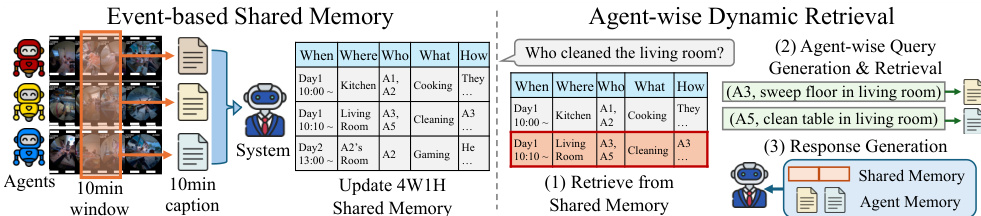
Agent-wise Dynamic Retrieval Given a query q, EgoMAS employs a hierarchical retrieval strategy to ensure fine-grained reasoning across multiple perspectives. First, the system retrieves the top-n system-level memories from the shared memory Mshared using BM25 ranking:
Rsvs(q)=Top⋅n{(m,s(m,q))∣m∈Mshared},where s(m,q) denotes the BM25 score between memory m and query q. From the retrieved system-level context, EgoMAS generates a set of agent-specific retrieval requests Qagent={(aj,qj)}j=1J, where each request consists of an agent identifier aj and a sub-query qj. For each (aj,qj), the system performs agent-level retrieval from the specific agent's memory Mai:
Rai(qj)=Top\textsl−k{(m,s(m,qj))∣m∈Mai}.To ensure relevance, memories with scores below a threshold τ are filtered out:
Rai(qj)={(m,s(m,qj))∈Rai(qj)∣s(m,qj)≥τ}.Finally, the system generates the final response by conditioning on both the retrieved system-level context Rsys(q) and the aggregated agent-level results R=⋃i=1JRai(qj):
y^=F(q,Rsys(q),R),where y^ and F denote the response and response generation function.
Benchmark Generation Process To support this research, the authors also establish a rigorous data generation pipeline. This process involves three stages: QA Generation, Filtering, and Manual Verification. In Stage I, questions are generated based on categories such as Single-span QA, Multi-span QA, and Template-based queries (TR, EI). Stage II applies zero-shot filtering, single-agent filtering, and cross-model verification to ensure quality. Finally, Stage III involves human verification to validate the dataset.
Experiment
- Evaluation on the MA-EgoQA benchmark demonstrates that current models struggle with multi-agent egocentric video understanding, with even top proprietary models achieving low accuracy, highlighting the task's difficulty.
- Experiments comparing input strategies reveal that concatenating all captions or frames without retrieval introduces noise and high computational costs, whereas retrieval-based approaches significantly improve efficiency and performance.
- The EgoMAS framework outperforms all baselines by effectively aggregating memories from multiple agents, proving that multi-agent memory access is essential for accurate reasoning.
- Analysis of sub-categories shows that performance degrades as the number of required agents or time spans increases, and Theory of Mind tasks remain the most challenging due to the need for inferring latent mental states.
- Ablation studies confirm that EgoMAS benefits from combining shared memory construction with agent-wise dynamic retrieval, and that an event-based memory structure is superior to alternative methods.
- Sensitivity analysis indicates that accuracy improves with the number of available agents, while modality experiments suggest that visual frames are crucial for specific queries but can distract models if not selected adaptively.