Command Palette
Search for a command to run...
OmniForcing:リアルタイムな音視覚生成の潜在能力を解放する
OmniForcing:リアルタイムな音視覚生成の潜在能力を解放する
Yaofeng Su Yuming Li Zeyue Xue Jie Huang Siming Fu Haoran Li Ying Li Zezhong Qian Haoyang Huang Nan Duan
概要
近年の共同音声・視覚拡散モデルは、生成品質において顕著な成果を挙げていますが、双方向アテンション依存性による高いレイテンシに悩まされており、リアルタイム応用を阻害しています。本研究では、オフラインの双ストリーム双方向拡散モデルを、高忠実度なストリーミング自己回帰生成器へ蒸留する初のフレームワーク「OmniForcing」を提案します。しかし、そのような双ストリームアーキテクチャに対して単純に因果蒸留を適用すると、モダリティ間の極端な時間的非対称性とそれに伴うトークンの希少性により、訓練の不安定性が深刻化します。我々は、マルチモーダル同期のドリフトを防止するゼロ切り捨てグローバルプレフィックスを備えた非対称ブロック因果アライメントを導入することで、本質的な情報密度のギャップを解決します。さらに、因果的シフト中に生じる極端な音声トークンの希少性による勾配爆発を、アイデンティティ RoPE 制約を備えた音声シンクトークン機構によって解消します。最後に、ジョイント・セルフ・フォース蒸留パラダイムを導入し、長時間のロールアウト中に露出バイアスから生じる累積的なクロスモーダル誤差をモデルが動的に自己修正できるようにしました。モダリティに依存しないローリング KV キャッシュ推論スキームを活用することで、OmniForcing は単一 GPU 上で約 25 FPS の最先端ストリーミング生成を実現し、双方向教師モデルと同等のマルチモーダル同期性と視覚品質を維持しています。プロジェクトページ:https://omniforcing.com
One-sentence Summary
Researchers from JD Explore Academy, Fudan University, Peking University, and the University of Hong Kong propose OmniForcing, a framework that distills bidirectional audio-visual diffusion models into real-time streaming generators. By introducing asymmetric block-causal alignment and audio sink tokens, it overcomes training instability to achieve 25 FPS generation while preserving high-fidelity synchronization.
Key Contributions
- OmniForcing addresses the high latency of bidirectional joint audio-visual diffusion models by distilling them into a high-fidelity streaming autoregressive generator that enables real-time applications.
- The framework introduces Asymmetric Block-Causal Alignment with a zero-truncation Global Prefix and an Audio Sink Token mechanism to resolve training instability caused by extreme temporal asymmetry and token sparsity.
- By employing a Joint Self-Forcing Distillation paradigm and a Modality-Independent Rolling KV-Cache, the method achieves state-of-the-art streaming generation at approximately 25 FPS on a single GPU while maintaining synchronization and visual quality comparable to the teacher model.
Introduction
Recent joint audio-visual diffusion models like LTX-2 deliver high-fidelity synchronized content but rely on bidirectional attention that requires processing the entire timeline at once. This architecture creates prohibitive latency and prevents real-time streaming, while existing workarounds either decouple modalities to degrade quality or fail to stabilize when applied to dual-stream systems due to extreme token sparsity and temporal asymmetry. The authors introduce OmniForcing, the first framework to distill an offline bidirectional model into a high-fidelity streaming autoregressive generator. They resolve training instability through an Asymmetric Block-Causal Alignment with a zero-truncation Global Prefix and an Audio Sink Token mechanism equipped with an Identity RoPE constraint. Additionally, a Joint Self-Forcing Distillation paradigm allows the model to self-correct cumulative errors, enabling state-of-the-art streaming generation at approximately 25 FPS on a single GPU.
Method
The authors leverage a dual-stream transformer backbone to enable real-time, streaming joint generation of temporally aligned video and audio. The overall framework, depicted in the OmniForcing pipeline, restructures a pretrained bidirectional model into a block-causal autoregressive system. This process involves a three-stage distillation pipeline designed to transfer the teacher's high-fidelity joint distribution to an ultra-fast causal engine.
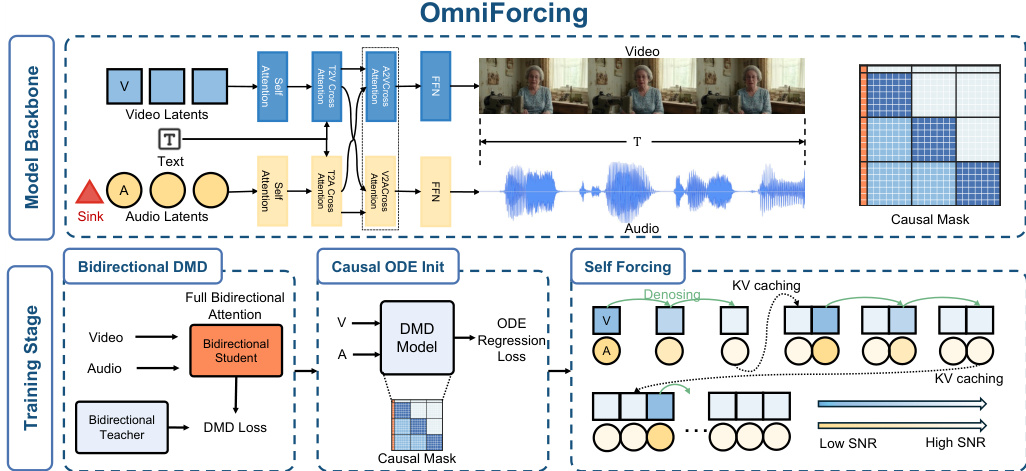
The training process follows a sequential distillation paradigm to smoothly decouple few-step denoising from the causal generation paradigm. Stage I employs Bidirectional Distribution Matching Distillation (DMD) to adapt the model for few-step denoising while preserving the global receptive field. Stage II utilizes causal ODE regression to adapt the network weights to the asymmetric block-causal mask, correcting the conditional distribution shift. Finally, Stage III implements joint Self-Forcing training by autoregressively unrolling the generation process to mitigate exposure bias and ensure cross-modal synchrony.
To address the extreme frequency asymmetry between video (3 FPS) and audio (25 FPS) latents, the method employs an Asymmetric Block-Causal Masking design. This approach bridges the information density gap by establishing a physical-time-based Macro-block Alignment. As shown in the figure below, the timeline is partitioned into 1-second macro-blocks, where each block encapsulates a fixed number of video and audio latents without fractional remainders.
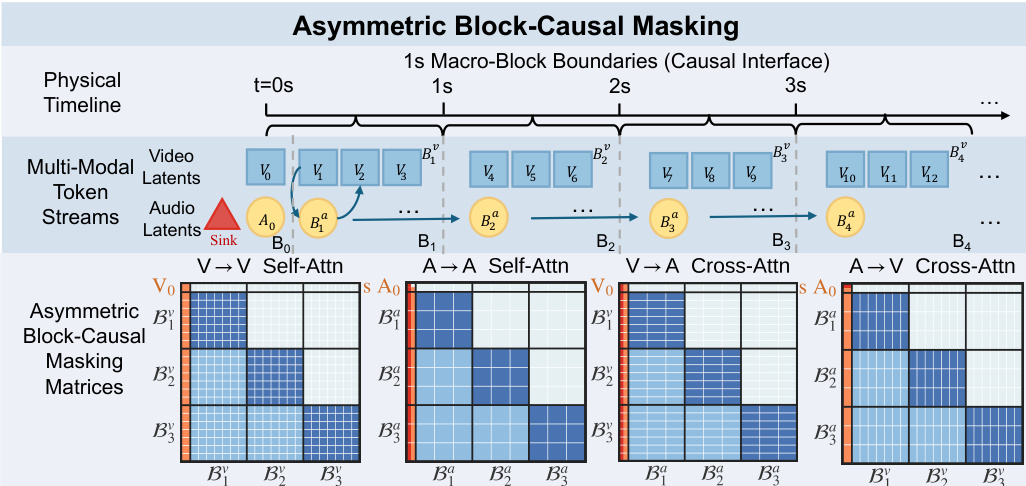
The initial components are merged into a Global Prefix block (B0) which functions as a system prompt, remaining globally visible to all future tokens. To prevent gradient explosions and Softmax collapse caused by the sparse history in early audio blocks, the authors introduce learnable Sink Tokens prepended to the audio sequence. These tokens are anchored within the global prefix and utilize an Identity RoPE constraint to remain position-agnostic. During inference, the architecture supports asymmetric compute allocation and parallel inference through modality-independent rolling KV caches, enabling real-time synchronized generation.
Experiment
- OmniForcing is evaluated against bidirectional and cascaded autoregressive baselines to validate its ability to achieve high-fidelity streaming audio-visual generation with real-time efficiency.
- The method demonstrates a significant speedup over offline teacher models, enabling true streaming playback with low latency while maintaining visual and audio quality comparable to the strongest joint models.
- Qualitative analysis confirms the model successfully generates layered sounds, synchronized speech, and complex audio blends that align precisely with visual events.
- Ablation studies validate that Audio Sink Tokens combined with Identity RoPE are essential for stabilizing training under causal constraints, whereas alternative stabilization methods lead to convergence failures or degraded output quality.
- Overall, the experiments confirm that OmniForcing achieves a massive reduction in inference time while preserving the perceptual fidelity and cross-modal coherence of the original bidirectional teacher.