HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
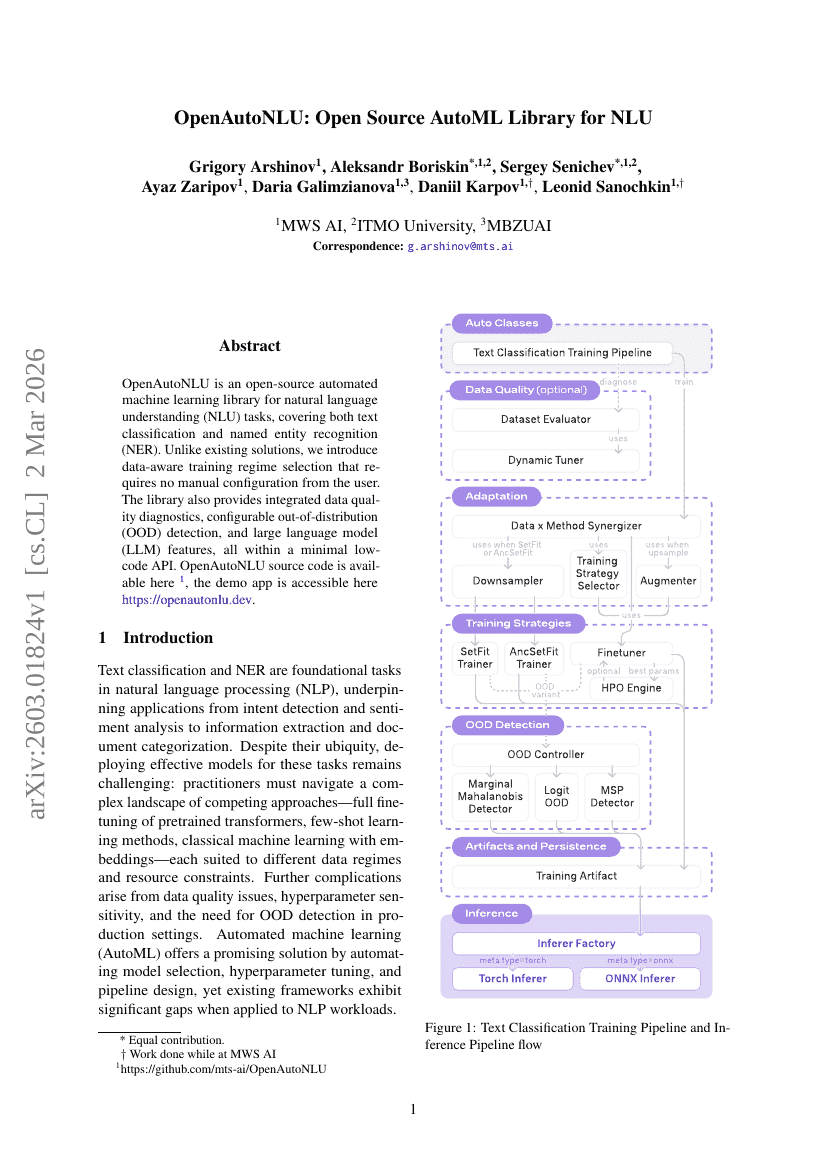
OpenAutoNLU:NLU向けオープンソースAutoMLライブラリ

OmniLottie:パラメータ化Lottieトークンを用いたベクターアニメーション生成









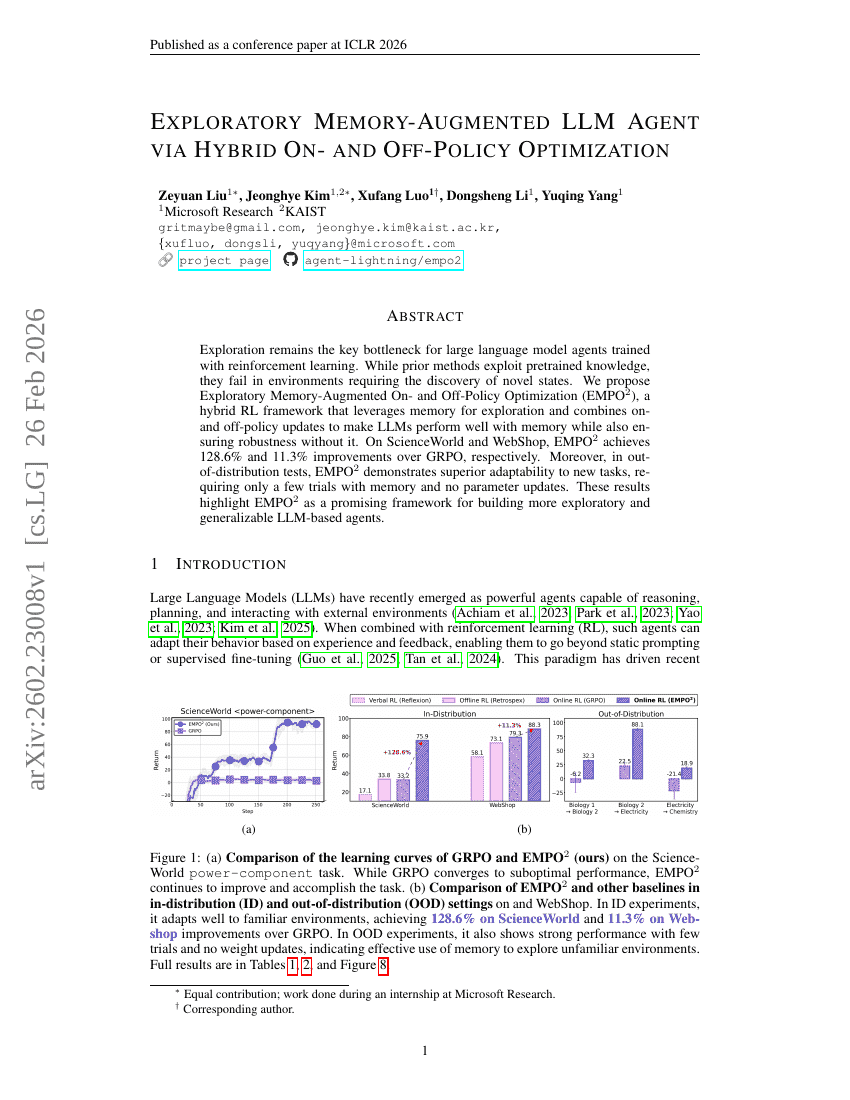









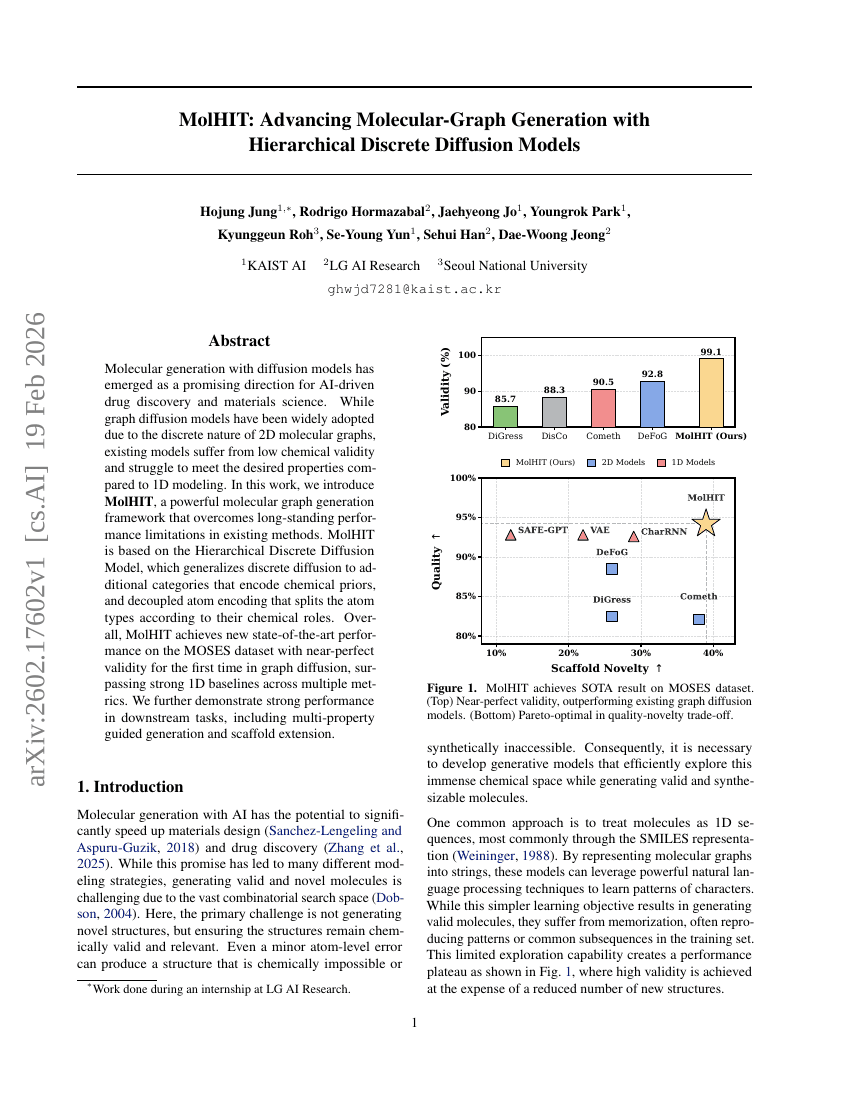
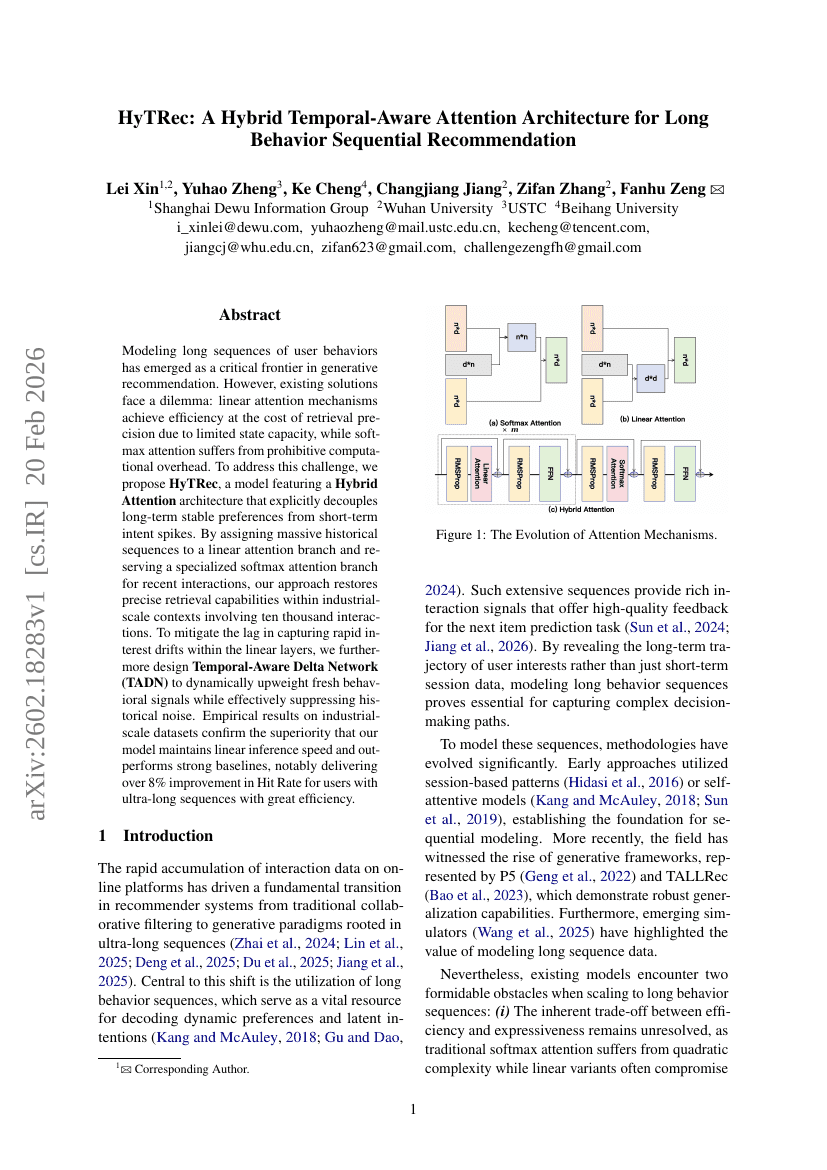









OpenAutoNLU:NLU向けオープンソースAutoMLライブラリ
OmniLottie:パラメータ化Lottieトークンを用いたベクターアニメーション生成
スケールからスピードへ:画像編集における適応的テスト時スケーリング
in-context co-player inference を介した Multi-agent 間の協力
ACTIONENGINE: State Machine Memory を介した Reactive な GUI Agent から Programmatic な Agent への転換
CiteAudit:あなたは引用しましたが、読んだでしょうか?LLM時代における科学的引用の検証のためのベンチマーク
モード探索が平均探索と融合した高速な長時間動画生成
CUDA Agent:高性能CUDAカーネル生成のための大規模エージェント型強化学習
翻訳による回復:ベンチマークおよびデータセットの自動翻訳を効率的に行うパイプライン
画像生成における空間理解の向上:報酬モデリングを活用して
dLLM:シンプルなディフュージョン言語モデリング
探索的メモリ拡張型LLMエージェント:ハイブリッドオンポリシーおよびオフポリシー最適化による実現
想像力は視覚的推論を支援するが、まだ潜在空間では実現していない
オムニGAIA:ネイティブなオムニモーダルAIエージェントへ向けて
MobilityBench:現実世界のモビリティシナリオにおけるルート計画エージェント評価のためのベンチマーク
盲点から利益へ:大規模なマルチモーダルモデルにおける診断駆動型反復学習
一貫性の三位一体が汎用世界モデルの定義的原則としての役割
GUI-Libra:アクション認識型の監督と部分検証可能なRLを用いたネイティブGUIエージェントの推論・実行訓練
SkyReels-V4:マルチモーダルな動画・音声生成、インペインティングおよび編集モデル
ARLArena:安定したエージェント強化学習を実現する包括的フレームワーク
DreamID-Omni:制御可能かつ人間中心型音声・映像生成のための統合枠組み
MolHIT:階層的離散拡散モデルによる分子グラフ生成の進展
HyTRec:長期間行動順序推薦のためのハイブリッド時系列認識アテンションアーキテクチャ
DREAM:エージェンティックメトリクスを用いたディープリサーチ評価
LongCLI-Bench:コマンドラインインターフェースにおける長期視野型エージェントプログラミングのための初期ベンチマークと研究
PyVision-RL:RLを活用したオープン型エージェント視覚モデルの構築
知覚から行動へ:視覚推論のためのインタラクティブベンチマーク
クエリ中心型かつメモリ認識型リランカーによる長文脈処理
LLM端末機能のスケーリングのためのデータ工学
DSDR:LLM推論における探索のためのデュアルスケール多様性正則化
Mobile-O:モバイルデバイス上の統合的マルチモーダル理解と生成
TOPReward:ロボティクスにおける隠れたゼロショット報酬としてのトークン確率
スケールからスピードへ:画像編集における適応的テスト時スケーリング
in-context co-player inference を介した Multi-agent 間の協力
ACTIONENGINE: State Machine Memory を介した Reactive な GUI Agent から Programmatic な Agent への転換
CiteAudit:あなたは引用しましたが、読んだでしょうか?LLM時代における科学的引用の検証のためのベンチマーク
モード探索が平均探索と融合した高速な長時間動画生成
CUDA Agent:高性能CUDAカーネル生成のための大規模エージェント型強化学習
翻訳による回復:ベンチマークおよびデータセットの自動翻訳を効率的に行うパイプライン
画像生成における空間理解の向上:報酬モデリングを活用して
dLLM:シンプルなディフュージョン言語モデリング
探索的メモリ拡張型LLMエージェント:ハイブリッドオンポリシーおよびオフポリシー最適化による実現
想像力は視覚的推論を支援するが、まだ潜在空間では実現していない
オムニGAIA:ネイティブなオムニモーダルAIエージェントへ向けて
MobilityBench:現実世界のモビリティシナリオにおけるルート計画エージェント評価のためのベンチマーク
盲点から利益へ:大規模なマルチモーダルモデルにおける診断駆動型反復学習
一貫性の三位一体が汎用世界モデルの定義的原則としての役割
GUI-Libra:アクション認識型の監督と部分検証可能なRLを用いたネイティブGUIエージェントの推論・実行訓練
SkyReels-V4:マルチモーダルな動画・音声生成、インペインティングおよび編集モデル
ARLArena:安定したエージェント強化学習を実現する包括的フレームワーク
DreamID-Omni:制御可能かつ人間中心型音声・映像生成のための統合枠組み
MolHIT:階層的離散拡散モデルによる分子グラフ生成の進展
HyTRec:長期間行動順序推薦のためのハイブリッド時系列認識アテンションアーキテクチャ
DREAM:エージェンティックメトリクスを用いたディープリサーチ評価
LongCLI-Bench:コマンドラインインターフェースにおける長期視野型エージェントプログラミングのための初期ベンチマークと研究
PyVision-RL:RLを活用したオープン型エージェント視覚モデルの構築
知覚から行動へ:視覚推論のためのインタラクティブベンチマーク
クエリ中心型かつメモリ認識型リランカーによる長文脈処理
LLM端末機能のスケーリングのためのデータ工学
DSDR:LLM推論における探索のためのデュアルスケール多様性正則化
Mobile-O:モバイルデバイス上の統合的マルチモーダル理解と生成
TOPReward:ロボティクスにおける隠れたゼロショット報酬としてのトークン確率