HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

見えずとも忘れず:動的動画世界モデルのためのハイブリッドメモリ

BeSafe-Bench: 機能的環境におけるSituated Agentの行動的安全リスクの解明



























見えずとも忘れず:動的動画世界モデルのためのハイブリッドメモリ
BeSafe-Bench: 機能的環境におけるSituated Agentの行動的安全リスクの解明
World Reasoning Arena
MSA: 1 億トークン規模への効率的なエンドツーエンドメモリモデルのスケーリングを実現するメモリスパースアテンション
Voxtral TTS
RealRestorer: Large-Scale Image Editing Models による汎用性のある実世界画像復元への挑戦
Calibri: Parameter-Efficient Calibration による Diffusion Transformer の高度化
Intern-S1-Pro:兆規模の科学マルチモーダル基盤モデル
PixelSmile: Toward Fine-Grained Facial Expression Editing
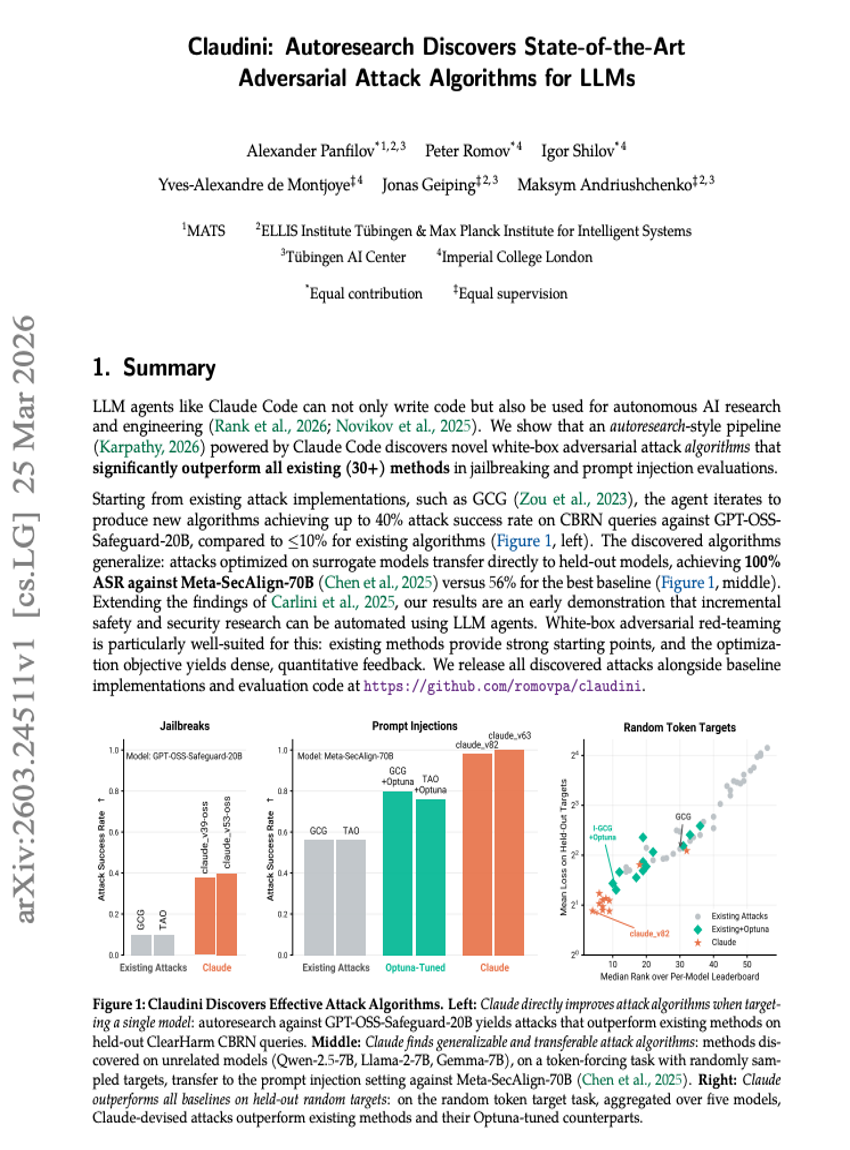
Claudini: AutoresearchによりLLMsに対する最先端のAdversarial Attackアルゴリズムを発見
AutoHarness: Code Harnessの自動合成によるLLM Agentsの向上
GameplayQA: 3D 仮想エージェントの意思決定が密集した POV 同期型マルチビデオ理解のためのベンチマークフレームワーク
なぜ自己蒸留(Self-Distillation)は、LLM の推論能力を(時として)劣化させるのか?
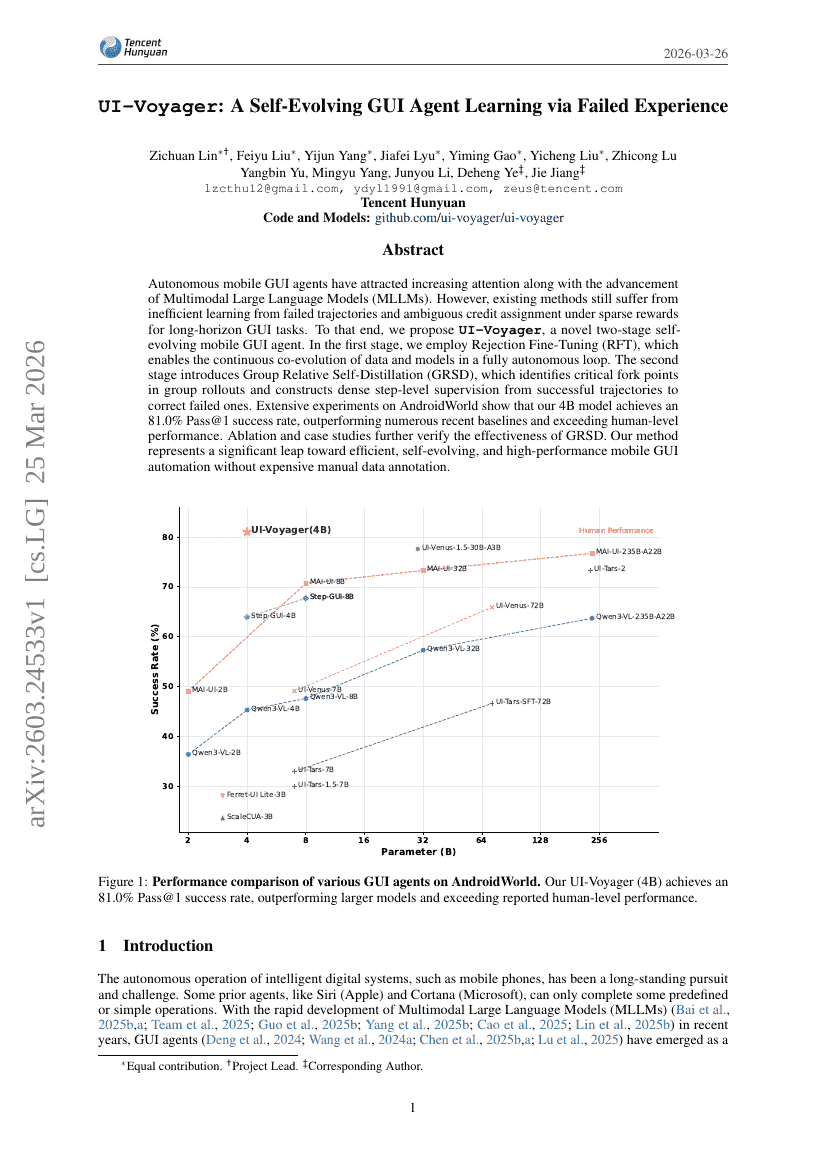
UI-Voyager: 失敗経験を通じた自己進化型 GUI Agent
T-MAP:Trajectory-aware Evolutionary Search による LLM Agents に対する Red-Teaming
CUA-Suite:コンピュータ使用 Agent 向けの大規模な人間注釈付きビデオ実証データセット
EVA: エンドツーエンドの Video Agent 向け効率的強化学習
Foveated Diffusion: Efficient Spatially Adaptive Image and Video Generation
Ego2Web: Egocentric Videoに基づいたWeb Agentベンチマーク
静的テンプレートから動的ランタイムグラフへ:LLM Agents 向けワークフロー最適化に関するsurvey
SpecEyes:Speculative Perception と Planning による Agentic Multimodal LLMs の高速化
DA-Flow: Diffusion Models を用いた Degradation-Aware な Optical Flow 推定
PEARL:パーソナライズされたストリーミング動画理解モデル
WildWorld:アクションと明示的状態を備えた動的世界モデリングおよび生成型 ARPG に向けた大規模データセット
MinerU-Diffusion: Diffusion によるデコーディングを介した逆レンダリングとしての文書 OCR の再考
PivotRL:低計算コストを実現する高精度なAgentic Post-Training
F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
SpatialBoost: 言語誘導推論による視覚表現の強化
VideoDetective:長動画理解のための外生的クエリと本質的関連性の両方による手がかりの探索
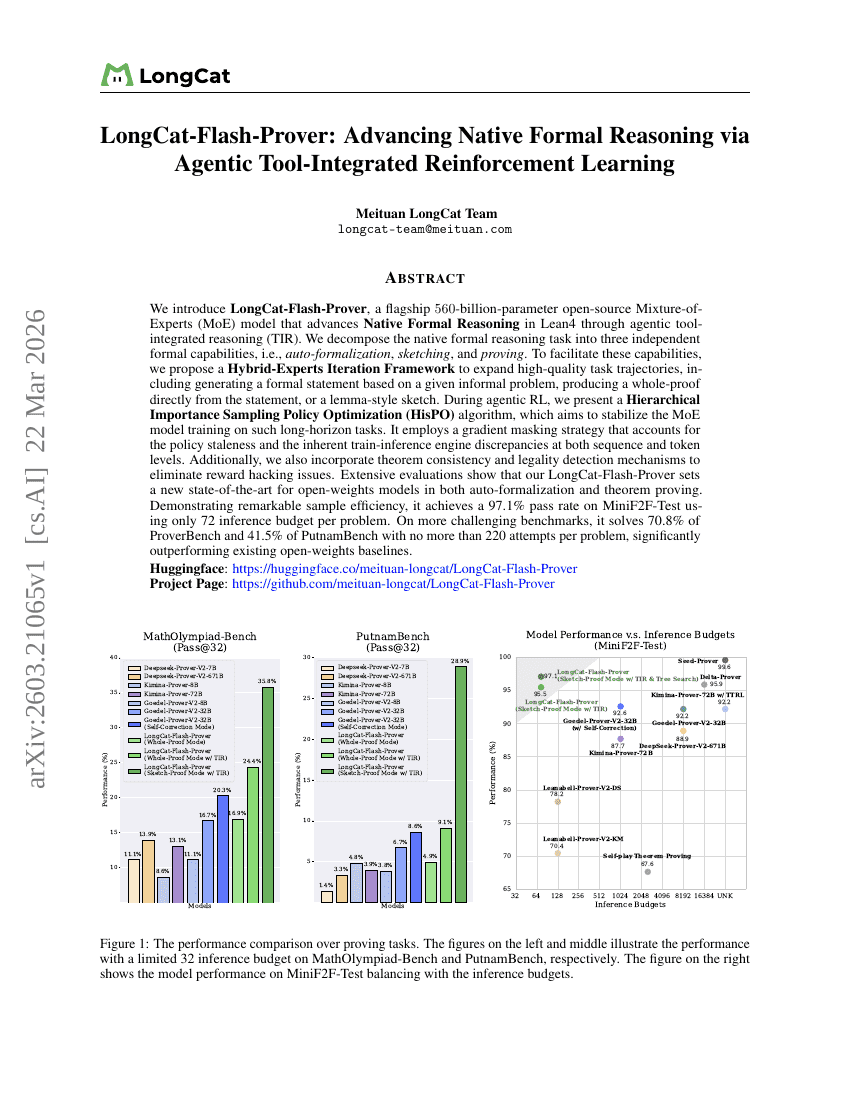
LongCat-Flash-Prover:Agentic Tool-Integrated Reinforcement Learning による Native Formal Reasoning の進展
シンプルさによる高速化:音声・動画生成基盤モデルのための単一ストリームアーキテクチャ
Omni-WorldBench: 世界モデルのための包括的な相互作用中心評価への指向
World Reasoning Arena
MSA: 1 億トークン規模への効率的なエンドツーエンドメモリモデルのスケーリングを実現するメモリスパースアテンション
Voxtral TTS
RealRestorer: Large-Scale Image Editing Models による汎用性のある実世界画像復元への挑戦
Calibri: Parameter-Efficient Calibration による Diffusion Transformer の高度化
Intern-S1-Pro:兆規模の科学マルチモーダル基盤モデル
PixelSmile: Toward Fine-Grained Facial Expression Editing
Claudini: AutoresearchによりLLMsに対する最先端のAdversarial Attackアルゴリズムを発見
AutoHarness: Code Harnessの自動合成によるLLM Agentsの向上
GameplayQA: 3D 仮想エージェントの意思決定が密集した POV 同期型マルチビデオ理解のためのベンチマークフレームワーク
なぜ自己蒸留(Self-Distillation)は、LLM の推論能力を(時として)劣化させるのか?
UI-Voyager: 失敗経験を通じた自己進化型 GUI Agent
T-MAP:Trajectory-aware Evolutionary Search による LLM Agents に対する Red-Teaming
CUA-Suite:コンピュータ使用 Agent 向けの大規模な人間注釈付きビデオ実証データセット
EVA: エンドツーエンドの Video Agent 向け効率的強化学習
Foveated Diffusion: Efficient Spatially Adaptive Image and Video Generation
Ego2Web: Egocentric Videoに基づいたWeb Agentベンチマーク
静的テンプレートから動的ランタイムグラフへ:LLM Agents 向けワークフロー最適化に関するsurvey
SpecEyes:Speculative Perception と Planning による Agentic Multimodal LLMs の高速化
DA-Flow: Diffusion Models を用いた Degradation-Aware な Optical Flow 推定
PEARL:パーソナライズされたストリーミング動画理解モデル
WildWorld:アクションと明示的状態を備えた動的世界モデリングおよび生成型 ARPG に向けた大規模データセット
MinerU-Diffusion: Diffusion によるデコーディングを介した逆レンダリングとしての文書 OCR の再考
PivotRL:低計算コストを実現する高精度なAgentic Post-Training
F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
SpatialBoost: 言語誘導推論による視覚表現の強化
VideoDetective:長動画理解のための外生的クエリと本質的関連性の両方による手がかりの探索
LongCat-Flash-Prover:Agentic Tool-Integrated Reinforcement Learning による Native Formal Reasoning の進展
シンプルさによる高速化:音声・動画生成基盤モデルのための単一ストリームアーキテクチャ
Omni-WorldBench: 世界モデルのための包括的な相互作用中心評価への指向