Command Palette
Search for a command to run...
Spatial-TTT: テスト時トレーニングによるストリーミング視覚ベースの空間知能
Spatial-TTT: テスト時トレーニングによるストリーミング視覚ベースの空間知能
Fangfu Liu Diankun Wu Jiawei Chi Yimo Cai Yi-Hsin Hung Xumin Yu Hao Li Han Hu Yongming Rao Yueqi Duan
概要
人間は、視覚的観測の連続を通じて現実世界の空間を知覚・理解する。したがって、潜在的に無限の動画ストリームから空間的証拠を逐次維持・更新する能力は、空間的知能にとって不可欠である。本研究の核心的な課題は、単にコンテキストウィンドウを延長することではなく、時間経過に伴って空間情報がどのように選択・整理・保持されるかという点にある。本論文では、テスト時学習(Test-Time Training: TTT)を用いたストリーミング型視覚ベースの空間的知能を実現する「Spatial-TTT」を提案する。本手法は、パラメータの一部(高速重み)を適応させることで、長視野のシーン動画から空間的証拠を捉え、整理する。具体的には、効率的な空間的動画処理のためにハイブリッドアーキテクチャを設計し、大規模チャンク更新とスライディングウィンドウ・アテンションを並列に採用する。さらに空間的認識を強化するため、3D 時空畳み込みを備えた TTT レイヤーに空間予測メカニズムを導入し、モデルがフレーム間における幾何的対応関係と時間的連続性を捉えるよう促す。アーキテクチャ設計に加え、高密度な 3D 空間記述を備えたデータセットを構築し、モデルがグローバルな 3D 空間信号を構造化された形で記憶・整理するために高速重みを更新するよう導く。広範な実験により、Spatial-TTT が長視野の空間理解を向上させ、動画空間ベンチマークにおいて最先端(state-of-the-art)の性能を達成することが示された。プロジェクトページ:https://liuff19.github.io/Spatial-TTT。
One-sentence Summary
Researchers from Tsinghua University, Tencent Hunyuan, and NTU propose Spatial-TTT, a test-time training model that utilizes fast weights and 3D spatiotemporal convolutions to efficiently organize streaming visual evidence, achieving state-of-the-art long-horizon spatial understanding on video benchmarks.
Key Contributions
- Spatial-TTT addresses the challenge of maintaining spatial evidence from unbounded video streams by employing test-time training to adapt fast weights as a compact non-linear memory for accumulating 3D scene information.
- The framework introduces a hybrid architecture with large-chunk updates and parallel sliding-window attention, alongside a spatial-predictive mechanism using 3D convolutions to capture geometric correspondence and temporal continuity.
- To provide rich supervision for learning effective weight update dynamics, the authors construct a new dataset with dense 3D spatial descriptions, enabling the model to achieve state-of-the-art performance on video spatial benchmarks.
Introduction
Real-world spatial intelligence requires systems to continuously process unbounded video streams to maintain an accurate 3D understanding of dynamic environments, a capability essential for robotics, autonomous driving, and augmented reality. Current Multimodal Large Language Models struggle with this task because they lack inherent 3D geometric priors and fail to scale to long-horizon videos without incurring prohibitive computational costs or losing critical spatial details through aggressive subsampling. To address these limitations, the authors introduce Spatial-TTT, a framework that leverages test-time training to update adaptive fast weights online, effectively creating a compact non-linear memory for accumulating spatial evidence. They enhance this approach with a hybrid architecture that balances efficient long-context compression with reasoning, a spatial-predictive mechanism using 3D convolutions to capture geometric continuity, and a new dense scene-description dataset to guide the learning of effective weight update dynamics.
Dataset
-
Dataset Composition and Sources The authors construct a two-stage training pipeline using a dense scene-description dataset and a large-scale spatial question-answering (QA) dataset. The first stage relies on object-centric 3D scene graphs from SceneVerse, while the second stage combines open-source benchmarks with self-collected data derived from ScanNet reconstructions.
-
Key Details for Each Subset
- Dense Scene-Description Subset: This set contains approximately 16,000 samples split between 3,600 from ScanNet and 12,500 from ARKitScenes. Each sample pairs a spatial video stream with a target description formatted as a coherent scene walkthrough.
- Spatial QA Subset: This set comprises roughly 3 million samples, including 2.5 million open-sourced entries and 0.5 million self-collected entries. The open-sourced portion aggregates data from VSI-590K, VLM-3R, InternSpatial, and ViCA. The self-collected portion consists of indoor-scene video sequences sampled from raw ScanNet reconstructions at 24 fps with a resolution of 640x480.
-
Model Usage and Training Strategy The authors use the dense scene-description data in the first stage to train the hybrid TTT architecture, enabling fast weights to learn chunk-by-chunk updates that retain comprehensive scene-level information. In the second stage, the model trains on the large-scale spatial QA dataset to refine spatial reasoning capabilities. This approach complements the sparse, local supervision of standard QA tasks with the rich, high-coverage signals provided by the dense descriptions.
-
Processing and Metadata Construction For the self-collected QA data, the authors align raw meshes with axis-alignment matrices and convert them to point clouds. They estimate room extent and centroids using the alpha-shape algorithm and fit oriented bounding boxes (OBBs) for valid object instances while discarding structural elements like walls and floors. Semantic labels are remapped to a consolidated 40-class indoor set, and 2D projected semantic annotations are computed to support appearance-order reasoning. The final metadata per sample includes room dimensions and coordinates, 2D semantic projections, OBB parameters for objects, and their corresponding semantic labels.
Method
The authors propose Spatial-TTT, a framework designed to enhance visual-based spatial reasoning in long-horizon video understanding by integrating Test-Time Training (TTT) into a multimodal transformer. The core methodology relies on a hybrid architecture that interleaves TTT layers with standard self-attention layers to balance memory efficiency with the preservation of pretrained visual-semantic knowledge.
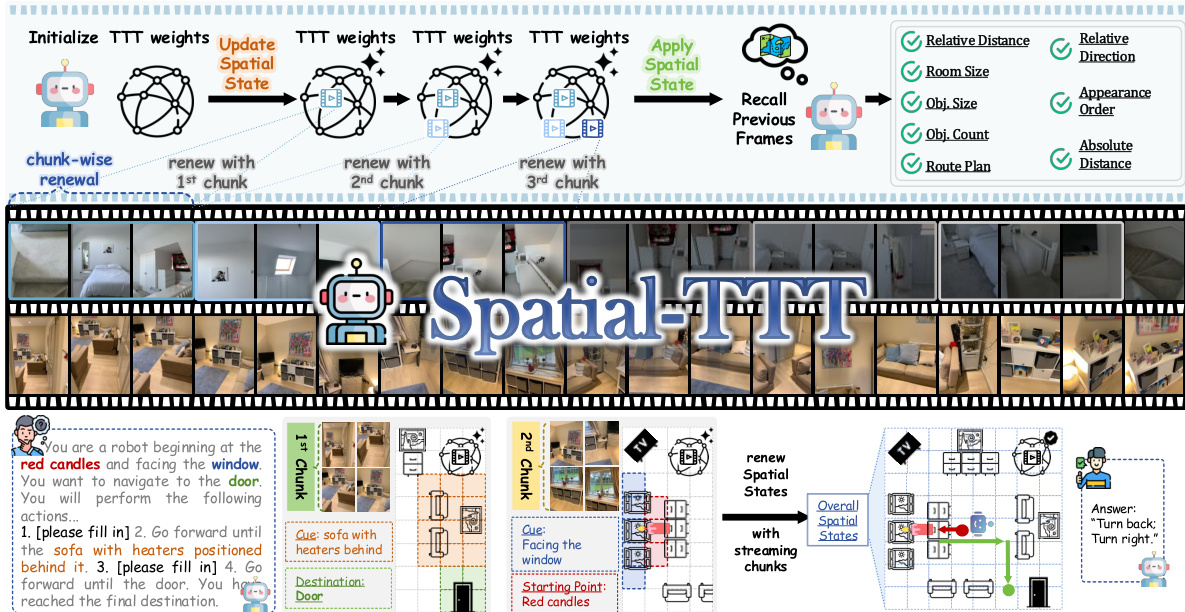
The overall framework operates by processing video streams in chunks to update and apply spatial states. As illustrated in the framework diagram, the model initializes TTT weights and performs chunk-wise renewal to update the spatial state. This process allows the system to recall previous frames and reason about spatial attributes such as relative distance, room size, and route plans. The workflow demonstrates how the model transitions from raw video inputs to a structured spatial representation that supports complex navigation and reasoning tasks.
To implement this, the authors design a Hybrid TTT Architecture where 75% of the decoder layers utilize TTT while the remaining 25% retain standard self-attention as anchor layers. These anchor layers maintain full attention access over the entire context to preserve the pretrained model's semantic reasoning ability. Meanwhile, TTT layers compress long-range temporal dependencies into adaptive fast weights Wt, achieving sublinear memory growth. Within each TTT layer, the authors adopt a large chunk size for visual tokens to substantially improve parallelism and hardware efficiency. To address causal constraints that prevent intra-chunk token interactions, they incorporate Sliding Window Attention (SWA) within each TTT layer, operating in parallel with TTT. The layer output combines both branches as:
ot=WindowAttn(qt,K∣t−w:t∣,V∣t−w:t∣)+fWt(qt)where K[t−w:t] and V[t−w:t] denote the keys and values within the sliding window. For the fast-weight network fW, a bias-free SwiGLU-MLP is used to increase the nonlinearity and expressiveness of the memory.
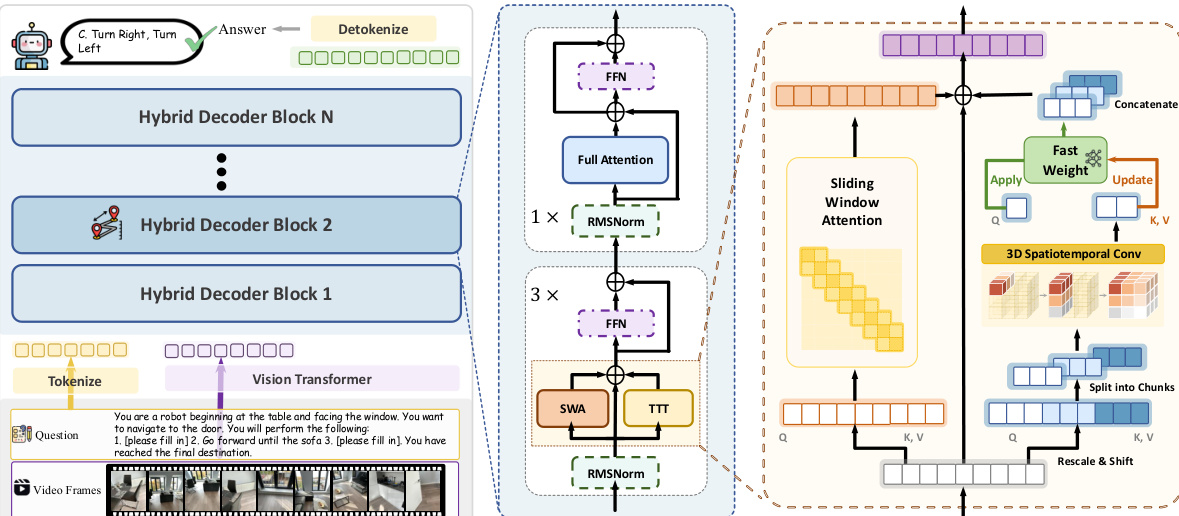
The detailed architecture of the Hybrid Decoder Block is shown in the figure below, highlighting the integration of the TTT branch with Sliding Window Attention and standard Feed-Forward Networks. A key component of this design is the Spatial-Predictive Mechanism. Streaming spatial understanding poses unique challenges as spatial information emerges from continuous visual observations with strong geometric and temporal continuity. To address this, the authors introduce a spatial-predictive mechanism with lightweight depthwise spatiotemporal convolution on the Q, K, V of the TTT branch. For visual tokens from videos, they are reshaped into a spatiotemporal grid to aggregate neighborhood information through local aggregation. This ensures that fast weights learn predictive mapping between spatial-temporal contexts rather than isolated tokens.
To further improve the stability and effectiveness of the TTT update, the authors adopt the Muon update rule instead of the vanilla implementation. This involves orthogonalizing the gradient with momentum and normalizing weights while preserving their original magnitude. The model is trained using a spatial-aware progressive training strategy. It is first initialized with dense scene description data to teach fast weights to retain comprehensive scene-level information, followed by fine-tuning on large-scale spatial VQA data to enhance streaming reasoning. At inference time, a dual KV cache mechanism is employed for constant-memory streaming, utilizing a sliding window cache for local context and a pending cache for fast weight updates.
Experiment
- VSI-Bench evaluation demonstrates that the model achieves superior general spatial understanding, excelling in geometric reasoning for navigation and direction while providing accurate metric grounding for distance and scene-scale estimation.
- MindCube testing confirms enhanced fine-grained spatial capabilities, specifically in maintaining object consistency across views and reasoning about occluded elements under changing camera perspectives.
- Streaming benchmarks on long-horizon videos show the model effectively accumulates spatiotemporal evidence over time, significantly outperforming baselines in object counting and temporal recall where other models fail due to memory constraints.
- Ablation studies validate that the spatial-predictive mechanism, dense scene-description supervision, and hybrid architecture are all critical for stabilizing updates, retaining global 3D evidence, and enabling cross-modal alignment.
- Efficiency analysis reveals that the model maintains linear computational scaling with input length, avoiding the memory overflow and super-linear cost growth observed in competing general-purpose and geometry-augmented models during extended video processing.