Command Palette
Search for a command to run...
ビジョン・ランゲージモデルはシェルゲームを解決できるか?
ビジョン・ランゲージモデルはシェルゲームを解決できるか?
Tiedong Liu Wee Sun Lee
概要
視覚的実体追跡は人間に固有の認知能力であるが、視覚言語モデル(VLM)にとっては依然として重要なボトルネックとなっている。この欠陥は、既存の動画ベンチマークにおいて視覚的ショートカットによってしばしば覆い隠されている。我々は、視覚的に同一の物体を空間的・時間的連続性のみによって追跡することを要する合成診断テストベッド「VET-Bench」を提案する。実験の結果、現在の最先端 VLM は VET-Bench において偶然レベル、あるいはそれに近い性能しか示さず、以下の根本的な限界が露呈した。すなわち、静的なフレームレベル特徴への過度な依存と、時間的経過後の実体表現の維持失敗である。我々は状態追跡問題との関連を論じた理論的分析を提供し、中間教師信号なしに識別不能な物体を追跡する固定深度のトランスフォーマーベース VLM は、表現力制約により本質的に限界があることを証明する。これに対処するため、物体の軌跡を明示的な中間状態として生成する「時空間的グラウンディング連鎖思考(Spatiotemporal Grounded Chain-of-Thought; SGCoT)」を提案する。Molmo2 の物体追跡能力を活用し、合成されたテキストのみのデータに対する微調整によるアライメントを通じて SGCoT 推論を誘発する。本手法は VET-Bench において 90% を超える最先端の精度を達成し、外部ツールなしに動画のシェルゲームタスクをエンドツーエンドで信頼性高く解決可能であることを示した。コードおよびデータは https://vetbench.github.io で公開されている。
One-sentence Summary
Researchers from the National University of Singapore introduce VET-Bench to expose tracking failures in Vision-Language Models and propose Spatiotemporal Grounded Chain-of-Thought, a technique that generates explicit object trajectories to overcome expressivity limits and achieve over 90% accuracy on indistinguishable object tracking tasks.
Key Contributions
- Existing video benchmarks obscure the critical bottleneck of visual entity tracking by allowing models to rely on static appearance cues, prompting the introduction of VET-Bench, a synthetic testbed featuring visually identical objects that necessitate tracking through spatiotemporal continuity alone.
- Theoretical analysis proves that visual entity tracking is NC1-complete, demonstrating that fixed-depth transformer-based VLMs are fundamentally limited in solving this task without intermediate supervision due to expressivity constraints.
- The proposed Spatiotemporal Grounded Chain-of-Thought method elicits explicit object trajectory generation as intermediate reasoning states, enabling the Molmo2 model to achieve state-of-the-art accuracy exceeding 90% on VET-Bench without external tools.
Introduction
Visual entity tracking is a foundational capability for embodied AI and game-playing agents, yet current Vision-Language Models (VLMs) struggle with this task due to an over-reliance on static appearance cues rather than genuine spatiotemporal continuity. Existing benchmarks often mask this deficit by including visual shortcuts, such as distinctive object features, which allow models to achieve high scores without performing actual tracking across frames. The authors address these limitations by introducing VET-Bench, a synthetic testbed using visually identical objects to force models to rely solely on motion continuity, while also proving that fixed-depth transformers are theoretically limited in solving such tasks without intermediate computation. To overcome these expressivity constraints, they propose Spatiotemporal Grounded Chain-of-Thought (SGCoT), a method that elicits explicit object trajectory generation as intermediate reasoning steps, enabling models to achieve over 90% accuracy on the benchmark without external tools.
Dataset
-
Dataset Composition and Sources: The authors introduce VET-Bench, a fully synthetic dataset generated via a three.js pipeline to evaluate visual entity tracking. Unlike real-world benchmarks, this approach offers fine-grained control over environmental parameters such as color, material, texture, lighting, and camera viewpoint to prevent data leakage and overfitting.
-
Key Subset Details: The benchmark focuses on two canonical tasks:
- Cups Game: Modeled after the Shell Game, this task requires tracking a ball hidden under identical opaque containers that undergo positional swaps.
- Cards Game: Inspired by Three-Card Monte, this task involves tracking a card after it is flipped face-down and shuffled.
- The pipeline allows precise adjustment of object counts and swap counts to create unlimited episodes and enable diagnostic evaluation of specific factors.
-
Usage and Training Strategy: The dataset is designed for diagnostic evaluation rather than standard training, forcing models to rely exclusively on fine-grained spatiotemporal perception. The authors use it to demonstrate that models achieving high scores on other benchmarks often fail here because they cannot solve the task without explicit frame-level cues.
-
Processing and Filtering Rules: To ensure realism and prevent shortcuts, the generation process enforces strict constraints:
- No single frame reveals the target identity or the swap operation.
- All containers are visually identical and opaque to block appearance-based re-identification.
- The dataset removes static cues and symbolic annotations (such as arrows) found in other benchmarks like VideoReasonBench.
- This design ensures that correct answers depend on exploiting spatiotemporal continuity across frames rather than static in-frame information.
Method
The authors formulate the visual entity tracking task as determining the terminal index π(i) of a target object i within a video sequence V={F0,…,FT} containing N visually indistinguishable objects. To ensure the problem is well-posed, a continuity constraint is enforced where the maximum displacement d between consecutive frames satisfies 2d<Δ, preventing identity aliasing during object crossovers. As illustrated in the benchmark overview below, the Visual Entity Tracking Benchmark (VET-Bench) evaluates this capability through scenarios like the "Cups Game" and "Cards Game," where objects undergo shuffling permutations. The figure highlights that while humans can intuitively track these entities, standard Vision-Language Models (VLMs) often fail to provide correct answers even when attempting step-by-step reasoning.
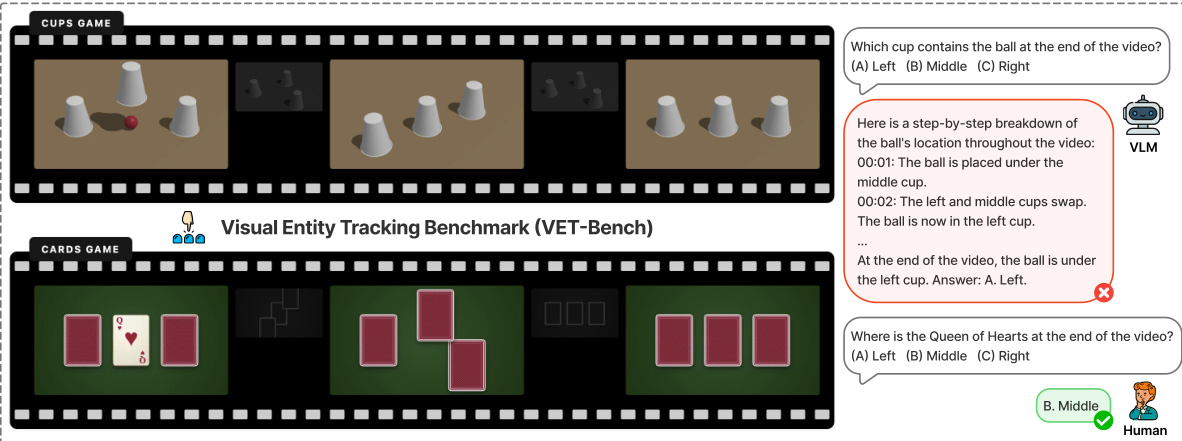
Theoretical analysis reveals that for k≥5 objects, the tracking problem is NC1-complete, placing it beyond the theoretical capacity of constant-depth transformers to solve via direct end-to-end training. Empirical results confirm that training with direct-answer supervision leads to stagnant loss at random chance levels. To overcome these limitations, the authors propose Spatiotemporal Grounded Chain-of-Thought (SGCoT). This method leverages Molmo2, a model pre-trained on video object tracking, to generate explicit spatiotemporal trajectories as intermediate reasoning steps.
Instead of providing a direct answer, the model is prompted to output a structured trajectory in the format <tracks coords="timestamp object_idx x y;...">, where timestamps are spaced at 0.5-second intervals and coordinates are normalized. This trajectory serves as the Chain-of-Thought, explicitly aligning when events occur and where entities are located. The training process is designed to be highly efficient and text-only. The authors synthesize trajectories using a Python script and align the model by masking the loss on the generated trajectory tokens while supervising only the final answer. This approach encourages the model to retain its grounding capabilities while learning to derive the final answer from the explicit state representation provided by the SGCoT. By discretizing time at consistent intervals and ensuring precise spatial states for each timestamp, SGCoT avoids the temporal misalignment and underspecification issues found in generic descriptive CoTs.
Experiment
- Evaluation of diverse proprietary and open-source video-language models on the VET-Bench shell game reveals that all systems perform near random chance, indicating a universal failure in fine-grained spatiotemporal entity tracking.
- Qualitative analysis identifies three primary failure modes: direct guessing without reasoning, coarse semantic descriptions that miss specific swap events, and hallucinated swap sequences where models generate logically coherent but visually incorrect tracking steps.
- Experiments varying swap counts show that while models succeed on zero-swap tasks by relying on static visual cues, performance collapses to random guessing with just a single swap, proving an inability to maintain object continuity.
- Tests with varying object counts demonstrate that accuracy scales inversely with the number of objects, confirming that models do not perform genuine entity tracking but instead resort to statistical guessing.
- A filtered subset of videos with identical opaque cups and no visual shortcuts confirms that current models excel only when exploiting dataset artifacts and fail completely when robust visual perception is strictly required.
- Fine-tuning a model with Spatiotemporal Grounded Chain-of-Thought improves reasoning structure but still fails when the model cannot distinguish between visually identical objects, leading to tracking jumps and incorrect final predictions.