Command Palette
Search for a command to run...
Cheers:パッチの詳細を意味表現から分離することで、統合されたマルチモーダル理解と生成を実現
Cheers:パッチの詳細を意味表現から分離することで、統合されたマルチモーダル理解と生成を実現
概要
マルチモーダルモデルにおける最近の最先端トピックとして、視覚的理解と生成を単一のモデル内で統合することが挙げられます。しかし、これら二つのタスクは、非整合なデコード機構と視覚表現を要求するため、共有特徴空間内での同時最適化は容易ではありません。本研究では、Cheers と呼ばれる統合型マルチモーダルモデルを提案します。Cheers は、パッチレベルの詳細を意味表現から分離することで、マルチモーダル理解における意味の安定化を図り、ゲート付き詳細残差を通じて画像生成の忠実度を向上させます。Cheers は以下の三つの主要コンポーネントで構成されます。(i) 画像の潜在状態をエンコードし、意味トークンに圧縮する統合型ビジョントークナイザー(これにより大規模言語モデル(LLM)の条件付けを効率的に実現)、(ii) テキスト生成のための自己回帰的デコードと画像生成のための拡散デコードを統合する LLM ベースのトランスフォーマー、(iii) まず視覚的意味をデコードし、次にビジョントークナイザーから意味的にゲートされた詳細残差を注入して高周波成分を精緻化するカスケード型フローマッチングヘッドです。主要ベンチマークにおける実験により、Cheers は視覚的理解と生成の両面において、最先端の統合型マルチモーダルモデル(UMM)と同等かそれ以上の性能を達成することが示されました。さらに、Cheers は 4 倍のトークン圧縮を実現し、高解像度画像のエンコードおよび生成の効率化を可能にしています。特に、Cheers は一般的なベンチマークである GenEval および MMBench において、Tar-1.5B を上回る性能を示しながら、トレーニングコストは 20% で済んでおり、効果的かつ効率的(すなわち 4 倍のトークン圧縮を伴う)な統合型マルチモーダルモデルの有用性を示しています。今後は、すべてのコードとデータを公開し、今後の研究に貢献いたします。
One-sentence Summary
Researchers from Tsinghua University, Xi'an Jiaotong University, and the University of Chinese Academy of Sciences present CHEERS, a unified multimodal model that decouples patch-level details from semantic representations to stabilize understanding and enhance generation fidelity. This approach outperforms Tar-1.5B on key benchmarks while requiring only 20% of the training cost.
Key Contributions
- CHEERS addresses the optimization conflict in unified multimodal models by decoupling patch-level details from semantic representations to stabilize understanding and improve generation fidelity.
- The model introduces a hybrid architecture featuring a unified vision tokenizer for efficient token compression, an LLM-based Transformer for mixed autoregressive and diffusion decoding, and a cascaded flow matching head that injects gated detail residuals.
- Extensive experiments show that CHEERS outperforms the Tar-1.5B model on GenEval and MMBench benchmarks while requiring only 20% of the training cost and achieving a 4x token compression rate.
Introduction
Unified multimodal models aim to integrate visual comprehension and high-fidelity image generation within a single architecture, yet they struggle because these tasks require fundamentally different decoding mechanisms and visual representations. Prior approaches often force a compromise by using a single shared feature space, which leads to optimization conflicts where semantic understanding suffers from quantization errors or generative fidelity loses high-frequency details. The authors leverage a novel decoupling strategy in CHEERS that separates patch-level details from semantic representations to resolve this tension. Their approach utilizes a unified vision tokenizer for efficient semantic compression and a cascaded flow matching head that first synthesizes global structure before injecting semantically gated detail residuals, achieving superior performance in both understanding and generation with significantly reduced training costs.
Dataset
-
Dataset Composition and Sources: The authors construct a multi-stage training pipeline using a diverse mix of image-caption pairs, multimodal samples, and pure text data sourced from LLaVA-UHD-v3, ImageNet, Infinity-MM, TextAtlas5M, BLIP-3o, DiffusionDB, Objects365, Nemotron-Cascade, Echo-4o-Image, MoviePosters, and ShareGPT-4o-Image.
-
Key Details for Each Subset:
- Stage I (Vision-Language Alignment): Utilizes 4.5M image-caption pairs from LLaVA-UHD-v3 and 1.3M ImageNet samples re-annotated by Qwen2.5-VL-3B, with the ImageNet dataset repeated 10 times to establish generative capability.
- Stage II (General Pre-Training): Optimizes on 30M multimodal samples with a 3:6:1 ratio of understanding, generation, and text data, incorporating captions from Infinity-MM and LLaVA-UHD-v3, generation data from BLIP-3o and synthetic FLUX.2 outputs, and text from LLaVA-UHD-v3.
- Stage III (Refined Pre-Training): Expands to 33M samples maintaining the 3:6:1 ratio, combining LLaVA-UHD-v3 instruction data, synthetic images generated via FLUX.2-klein-9B using DiffusionDB and LLaVA-OneVision-1.5 prompts, 466K compositional reasoning instructions based on Objects365, and text from Nemotron-Cascade.
- Stage IV (Supervised Fine-Tuning): Focuses on 3.8M curated samples including high-quality subsets from Stage III, Echo-4o-Image, MoviePosters, and ShareGPT-4o-Image.
-
Model Usage and Training Strategy: The authors employ a four-stage progressive training approach where image resolution is fixed at 512x512. Stage I trains only randomly initialized modules, Stage II and III optimize all parameters except the VAE, and Stage IV performs supervised fine-tuning with a 1:1 batch ratio between understanding and generation tasks.
-
Processing and Metadata Details: Synthetic data is generated using FLUX.2-klein-9B with prompts from DiffusionDB and LLaVA-OneVision-1.5 to enhance generation and reasoning capabilities. Specific subsets like Objects365 are used to synthesize 466K instructions targeting compositional reasoning skills such as counting, color recognition, and spatial understanding.
Method
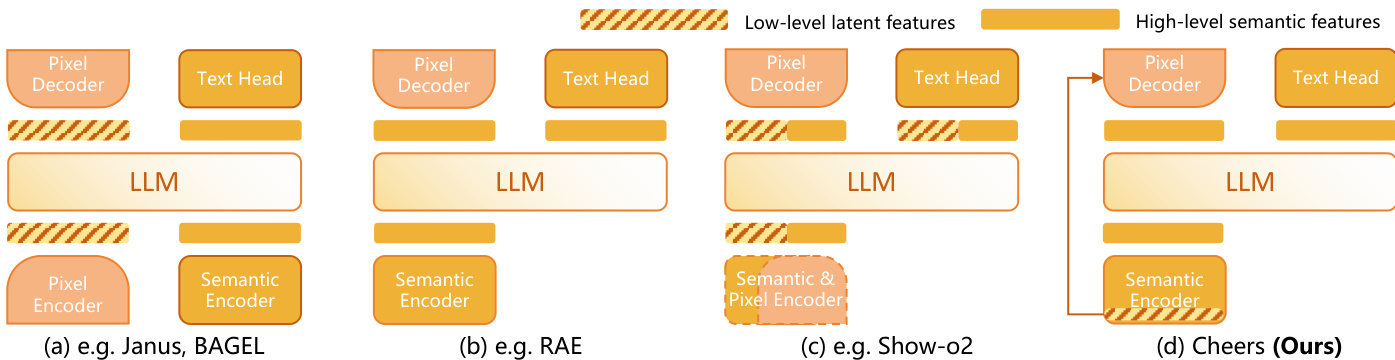
The authors present the CHEERS framework, which is designed to unify multimodal understanding and image generation through a specialized architecture. The design philosophy prioritizes the separation of feature granularities to handle the trade-off between semantic reasoning and pixel-perfect reconstruction. Refer to the framework diagram below which contrasts CHEERS with prior approaches such as Janus, BAGEL, and RAE. Unlike methods that process latent features directly or rely on a single encoder, the proposed architecture employs a dedicated Semantic Encoder for high-level features while maintaining a separate path for low-level latent features, ensuring that fine-grained details are not discarded during the encoding process.
The core of the system relies on a Unified Vision Tokenizer, a Unified LLM-based Transformer, and a Cascaded Flow Matching Head. As shown in the figure below, the Unified Vision Tokenizer bridges latent representations and unified semantic visual embeddings. It comprises a VAE decoder and a semantic encoder, specifically SigLIP2-ViT. Given an input image X, the VAE encoder yields latent states z1. To unify diverse tasks, a task-dependent latent zt is formulated as zt=tz1+(1−t)z0, where z0 represents latent noise. For visual understanding, t is fixed at 1, while for image generation, t is sampled from (0,1). Instead of processing these latents directly, zt is passed through a VAE decoder to reconstruct the pixel-level image, which is then encoded by the ViT backbone to extract high-level semantic tokens zs(t). This reconstruction step is crucial as it circumvents the loss of fine-grained features often associated with direct latent processing.
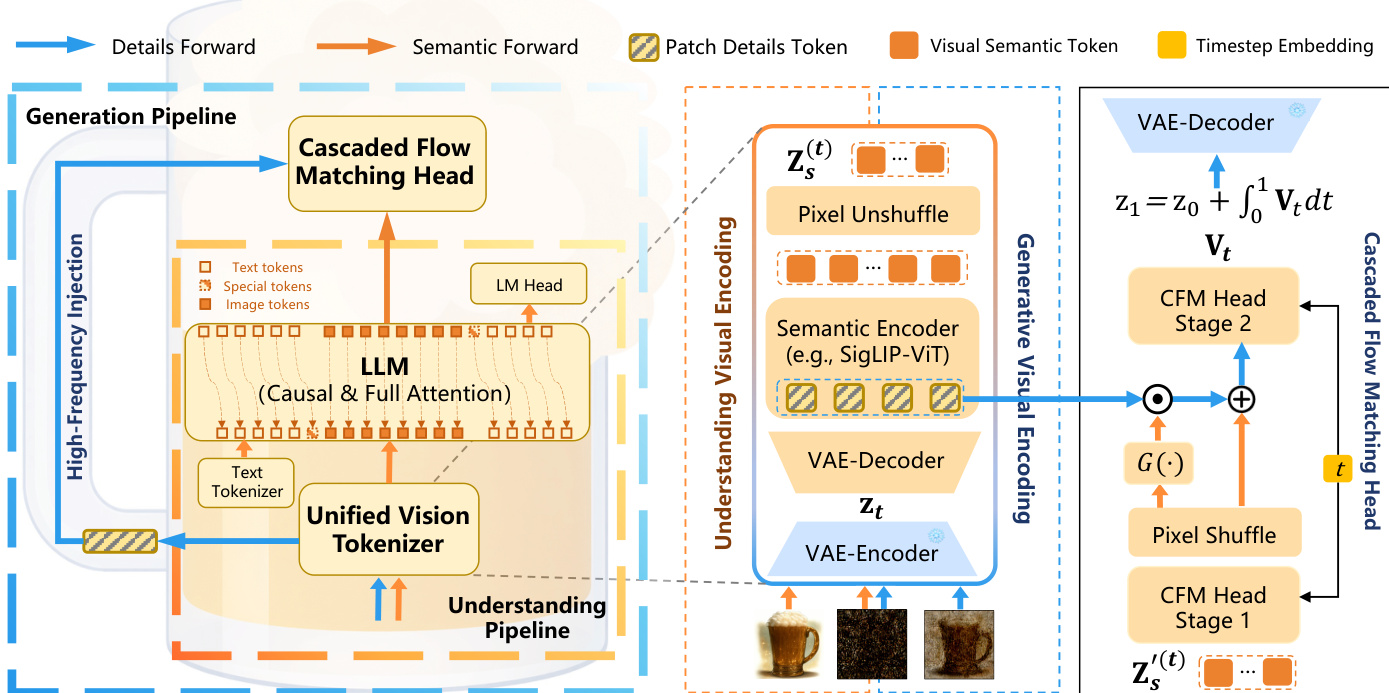
These semantic tokens are subsequently processed by the Unified LLM-based Transformer. The authors utilize an autoregressive backbone where semantic visual tokens and text embeddings are concatenated into a unified input sequence. A bidirectional attention mask is applied to the visual tokens to capture global context, whereas a causal mask is employed for text tokens to enable autoregressive decoding. Depending on the task, the LLM outputs are routed to different decoding paradigms. For image generation, the continuous visual hidden states are decoded via the Cascaded Flow Matching Head.
This head explicitly decouples high-frequency visual details from low-frequency semantic features. It consists of two cascaded stages. The first stage performs low-resolution semantic generation, followed by a PixelShuffle module that up-samples the feature maps. In the second stage, high-frequency patch details are introduced to update the decoded features. As shown in the figure below, the intensity of high-frequency injection dynamically increases as the denoising step progresses, mirroring the hierarchical nature of human drawing. The injection is controlled by a gating network G(⋅), updating the features according to the equation: Zs′(t)←G(Zs′(t))⊙S(D(zt))+Zs′(t) where G(Zs′(t)) denotes a scalar map and ⊙ represents element-wise multiplication.

The framework is trained end-to-end using a unified optimization objective. For text and understanding tasks, a standard cross-entropy loss is used. For image generation, a flow matching loss is applied to predict the velocity field Vt. During inference, the latent trajectory evolves from Gaussian noise z0 to the terminal state z1 via numerical integration of the predicted velocity field, allowing for continuous-time flow-based sampling.
Experiment
- Comprehensive benchmarking on multimodal understanding and visual generation tasks validates that CHEERS achieves competitive performance across general, OCR, spatial, and knowledge-focused domains while demonstrating superior data efficiency.
- Analysis of the training pipeline confirms that generation capabilities improve progressively, with synthetic instruction-oriented data driving significant gains in fidelity and alignment compared to real-world data.
- Visualization of high-frequency injection reveals a dynamic, coarse-to-fine mechanism where high-frequency signals are sparsely used for initial contours but intensify in later stages to refine textures and local details.
- Ablation studies demonstrate that joint training for understanding and generation does not compromise comprehension and that high-frequency injection is essential for producing sharp, detailed images.
- Experiments on architectural design prove that reconstructing pixels before semantic encoding is necessary to preserve fine-grained visual details required for OCR tasks.
- Evaluation of emergent abilities shows that the unified visual tokenizer enables strong generalization to untrained tasks like image editing and multi-image composition through shared feature representation.