HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

Generative World Renderer

潜在空間:基盤、進化、メカニズム、能力、および展望

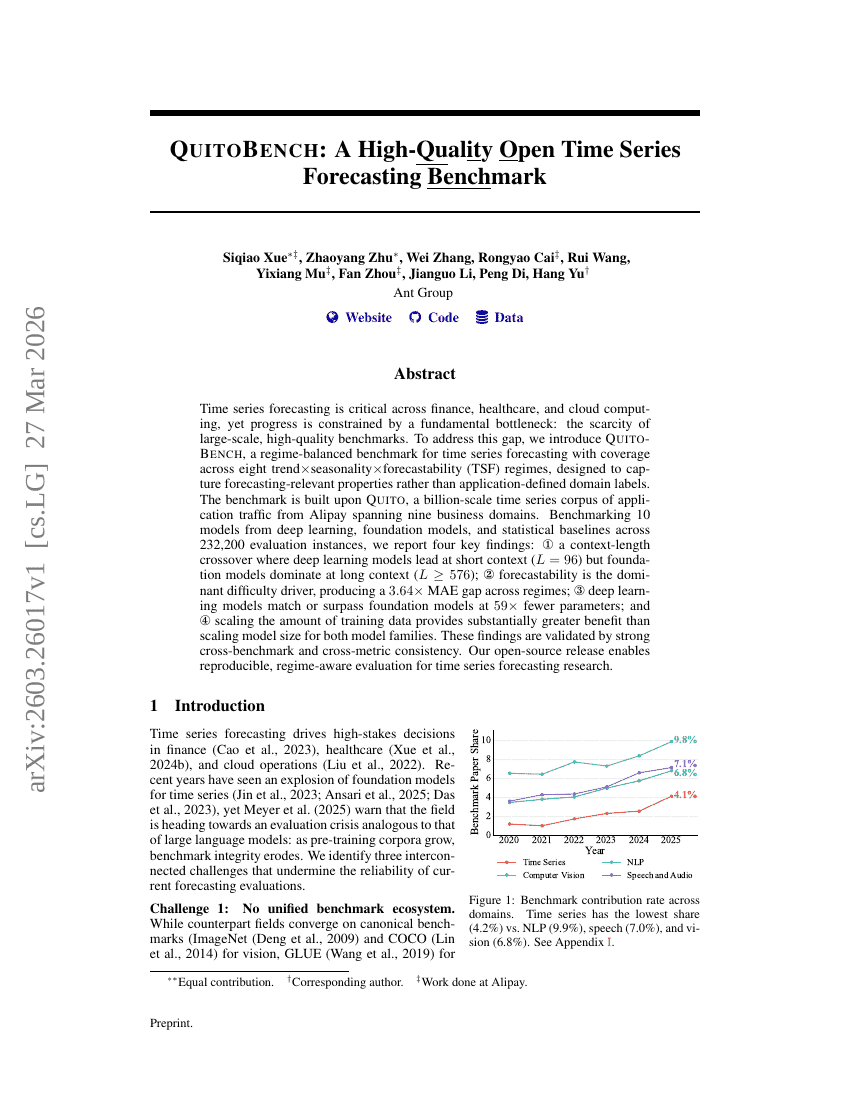


















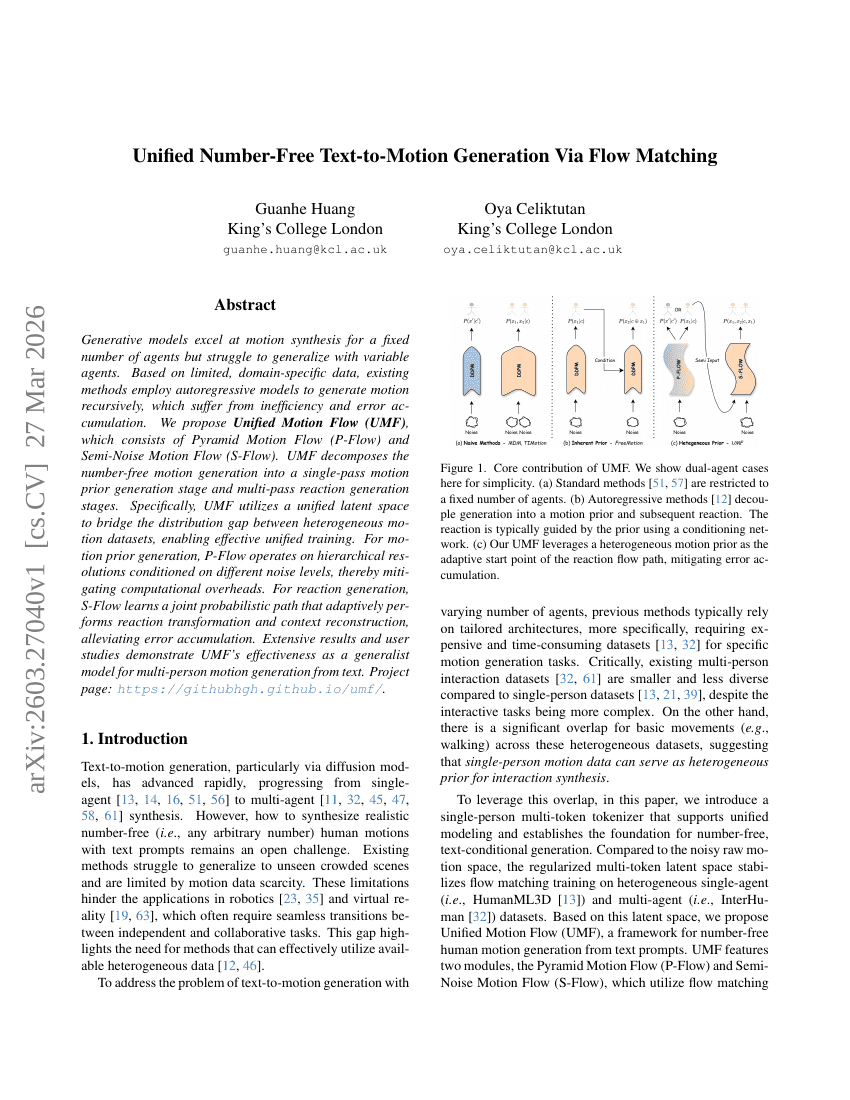






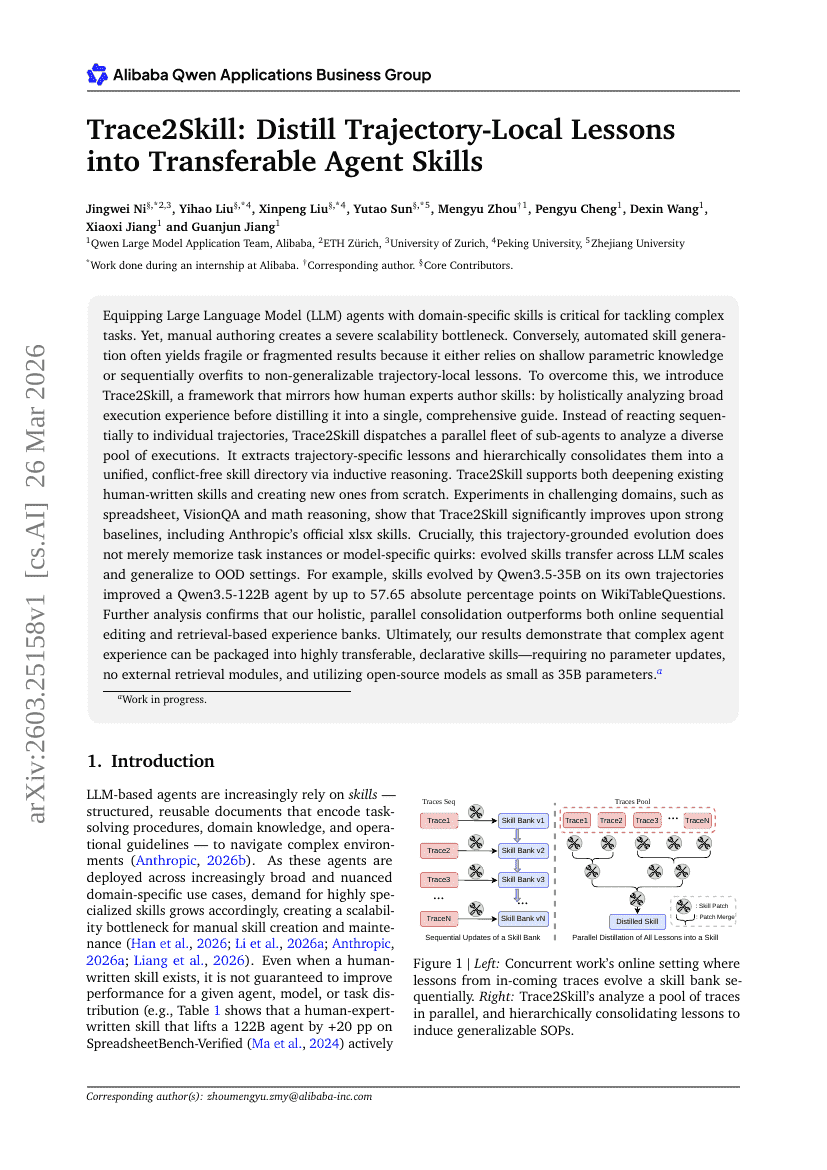


Generative World Renderer
潜在空間:基盤、進化、メカニズム、能力、および展望
DataFlex: 大規模言語モデルのデータ中心動的学習のための統合フレームワーク
QuitoBench:高品質なオープンタイムシリーズ予測ベンチマーク
Vision2Web:エージェント検証を備えた視覚的ウェブサイト開発のための階層的ベンチマーク
ViGoR-Bench:視覚生成モデルはゼロショット視覚推論器からどれほど遠いのか?
MiroEval: プロセスと成果におけるマルチモーダル深層研究エージェントのベンチマーク評価
エンタープライズ自動化にはターミナル Agent で十分である
ClawKeeper: スキル、プラグイン、およびウォッチャーを通じた OpenClaw エージェントのための包括的な安全保護
確率的勾配降下法の高速な不確実性定量化のための安価なブートストラップ
Generative AI Enables Structural Brain Network Construction from fMRI via Symmetric Diffusion Learning
エッジ AI 向けの早期退出型予測符号化ニューラルネットワーク
二次勾配:ヘッシアンと勾配の統合による勾配降下法とニュートン型手法の架け橋となる統一フレームワーク
製品ブロードキャストチャネルのクラスにおける容量領域
Colon-Bench: 全手技大腸内視鏡検査動画におけるスケーラブルな高密度病変注釈のためのアジェンティックワークフロー
TOOLACE:LLM 関数呼び出しにおける優位性の確立
LightMover: 色と強度の制御を備えた生成光移動
強化学習と対戦相手のポーズ推定を用いた自律的な追い越し軌道最適化
Make It Up:一般化された少数ショット意味セグメンテーションにおける偽造画像による実質的な性能向上
LLM ベースのマルチトークヤースピーチ認識に向けた、ゲート付きクロスアテンションアダプタを用いた 2 段階音響適応手法
外科 AI における比較研究:データセット、ファウンデーションモデル、および Med-AGI への障壁
テキストデータ統合
フローマッチングによる統一された数値不要のテキストからモーションへの生成
SEAR:LLM Gateway 向けスキーマベースの評価とルーティング
拡散 Transformer における文脈空間内でのオンザフライ反発による多様性の向上
EpochX:創発的エージェント文明の基盤構築
TAPS:Speculative Sampling 用の Task Aware Proposal Distributions
LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
RealChart2Code:実データとマルチタスク評価によるチャートからコードへの生成の進展
Trace2Skill: 軌道局所的な教訓を転移可能な Agent 技能へ蒸留する
PackForcing:短時間の動画トレーニングが、長時間の動画サンプリングおよび長文脈推論に十分である
ShotStream: 対話型ストーリーテリングのためのストリーミング・マルチショット動画生成
DataFlex: 大規模言語モデルのデータ中心動的学習のための統合フレームワーク
QuitoBench:高品質なオープンタイムシリーズ予測ベンチマーク
Vision2Web:エージェント検証を備えた視覚的ウェブサイト開発のための階層的ベンチマーク
ViGoR-Bench:視覚生成モデルはゼロショット視覚推論器からどれほど遠いのか?
MiroEval: プロセスと成果におけるマルチモーダル深層研究エージェントのベンチマーク評価
エンタープライズ自動化にはターミナル Agent で十分である
ClawKeeper: スキル、プラグイン、およびウォッチャーを通じた OpenClaw エージェントのための包括的な安全保護
確率的勾配降下法の高速な不確実性定量化のための安価なブートストラップ
Generative AI Enables Structural Brain Network Construction from fMRI via Symmetric Diffusion Learning
エッジ AI 向けの早期退出型予測符号化ニューラルネットワーク
二次勾配:ヘッシアンと勾配の統合による勾配降下法とニュートン型手法の架け橋となる統一フレームワーク
製品ブロードキャストチャネルのクラスにおける容量領域
Colon-Bench: 全手技大腸内視鏡検査動画におけるスケーラブルな高密度病変注釈のためのアジェンティックワークフロー
TOOLACE:LLM 関数呼び出しにおける優位性の確立
LightMover: 色と強度の制御を備えた生成光移動
強化学習と対戦相手のポーズ推定を用いた自律的な追い越し軌道最適化
Make It Up:一般化された少数ショット意味セグメンテーションにおける偽造画像による実質的な性能向上
LLM ベースのマルチトークヤースピーチ認識に向けた、ゲート付きクロスアテンションアダプタを用いた 2 段階音響適応手法
外科 AI における比較研究:データセット、ファウンデーションモデル、および Med-AGI への障壁
テキストデータ統合
フローマッチングによる統一された数値不要のテキストからモーションへの生成
SEAR:LLM Gateway 向けスキーマベースの評価とルーティング
拡散 Transformer における文脈空間内でのオンザフライ反発による多様性の向上
EpochX:創発的エージェント文明の基盤構築
TAPS:Speculative Sampling 用の Task Aware Proposal Distributions
LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
RealChart2Code:実データとマルチタスク評価によるチャートからコードへの生成の進展
Trace2Skill: 軌道局所的な教訓を転移可能な Agent 技能へ蒸留する
PackForcing:短時間の動画トレーニングが、長時間の動画サンプリングおよび長文脈推論に十分である
ShotStream: 対話型ストーリーテリングのためのストリーミング・マルチショット動画生成