Command Palette
Search for a command to run...
現実の大都市における世界シミュレーションモデルのグラウンディング
現実の大都市における世界シミュレーションモデルのグラウンディング
概要
もし、世界シミュレーションモデルが架空の環境ではなく、実際に存在する都市をレンダリングできるならどうなるでしょうか?従来の生成型世界モデルは、すべてのコンテンツを想像することで視覚的に説得力はあるが人工的な環境を合成します。本研究では、ソウルという実在の都市を基盤とした都市規模の世界モデル「Seoul World Model(SWM)」を提案します。SWM は、近傍のストリートビュー画像を用いた検索拡張条件付けにより、自己回帰型動画生成を現実の空間にアンカーリングします。しかし、この設計にはいくつかの課題が生じます。具体的には、検索された参照画像と動的な対象シーンとの間の時間的不一致、車両搭載カメラによる不規則な間隔での撮影に起因する軌道の多様性の制限、およびデータのスパース性です。これらの課題に対し、本研究ではクロスタイムペアリング、多様なカメラ軌道を可能にする大規模合成データセット、およびスパースなストリートビュー画像から整合性の高い訓練動画を合成するビュー補間パイプラインを導入して解決を図ります。さらに、長視野生成を安定化させるため、各チャンクを将来の位置における検索画像に継続的に再アンカーリングする「バーチャル・リーホールド・シンク」を新たに提案します。SWM をソウル、釜山、アナーバーの 3 都市において、最新の動画世界モデルと比較評価しました。その結果、SWM は数百メートルに及ぶ軌道にわたって、実在の都市環境に基づき、空間的に忠実かつ時間的に一貫した長視野動画を生成する点で既存手法を上回り、多様なカメラ運動やテキストプロンプトによるシナリオ変異にも対応可能であることを示しました。
One-sentence Summary
Researchers from KAIST AI, NAVER AI Lab, and SNU AIIS introduce Seoul World Model, a city-scale simulation system that grounds video generation in real urban environments by retrieving street-view images. Unlike prior models that imagine artificial worlds, this approach uses cross-temporal pairing and a Virtual Lookahead Sink to ensure spatial fidelity and long-horizon stability for applications like urban planning and autonomous driving.
Key Contributions
- The paper introduces Seoul World Model, a city-scale world simulation system that anchors autoregressive video generation to real urban environments by retrieving and conditioning on nearby street-view images based on geographic coordinates and camera actions.
- To overcome data sparsity and trajectory limitations, the work presents a large-scale synthetic dataset with diverse camera paths and a view interpolation pipeline that synthesizes coherent training videos from sparse street-view captures using an intermittent freeze-frame strategy.
- A Virtual Lookahead Sink is proposed to stabilize long-horizon generation by continuously re-grounding each video chunk to a retrieved image at a future location, which experimental results show enables spatially faithful and temporally consistent videos over trajectories reaching hundreds of meters.
Introduction
World simulation models currently generate dynamic environments by imagining all content beyond an initial frame, which limits their utility for applications requiring strict fidelity to real-world locations like urban planning or autonomous driving testing. Existing approaches struggle to ground generation in specific physical cities because they lack mechanisms to anchor predictions to actual geometry, while traditional 3D reconstruction systems remain static and unable to simulate dynamic scenarios. The authors introduce the Seoul World Model, which grounds autoregressive video generation in a real metropolis by retrieving nearby street-view images to condition the output. To overcome challenges such as temporal misalignment between static references and dynamic scenes, sparse data coverage, and long-horizon drift, they employ cross-temporal pairing, a large-scale synthetic dataset with diverse trajectories, and a Virtual Lookahead Sink that continuously re-anchors generation to future locations.
Dataset
Dataset Composition and Sources
The authors construct the Street-View Motion (SWM) dataset by aligning street-view references with target video sequences to ground generation in real-world geometry. The data originates from three primary sources:
- Real Street-View Data: 1.2 million panoramic images captured across major urban areas of Seoul, sourced from NAVER Map.
- Synthetic Urban Data: 12.7K videos rendered using the CARLA simulator across six urban maps.
- Public Driving Dataset: A supplementary publicly available driving video dataset used to increase scenario diversity.
Key Details for Each Subset
- Real Street-View Subset:
- Size: 1.2M raw panoramas reduced to 440K images for training after processing.
- Metadata: Includes GPS coordinates and timestamps; license plates and pedestrians are blurred for privacy.
- Coverage: Spans approximately 44.8 km east-west and 31.0 km north-south within the Seoul Metropolitan Area.
- Synthetic Subset:
- Size: 12.7K videos covering 431,500 square meters.
- Trajectory Types: Includes pedestrian paths (sidewalks/crossings), vehicle paths (highways/turns), and free-camera navigation.
- References: 4K street-view positions rendered with eight directional views each, totaling 32K reference frames.
- Stylized Augmentation: 10K additional videos generated by applying style transfers (e.g., weather changes, day-to-night) to the interpolated street-view data.
Data Usage and Training Strategy
- Cross-Temporal Pairing: The authors enforce a strict rule where reference images and target sequences are captured at different timestamps. This prevents the model from learning transient objects like specific cars or pedestrians, forcing it to rely on persistent spatial structures.
- Training Splits: The 440K processed real images and the full synthetic set are used to train the video generation model.
- Text Prompts: Videos are captioned using Qwen2.5-VL-72B to generate long and short descriptions of scenery and events. These are combined with predefined camera action tags (e.g., "straight," "left turn") derived from pose sequences.
- Mixture: The training mixture combines real-world data, synthetic data, and stylized augmentations to balance geometric fidelity with diverse camera paths and environmental conditions.
Processing and Construction Details
- View Interpolation: To bridge the gap between sparse panoramic captures (5–20m intervals) and continuous video requirements, the authors use a pretrained latent video model to synthesize smooth T-frame videos from N sparse keyframes.
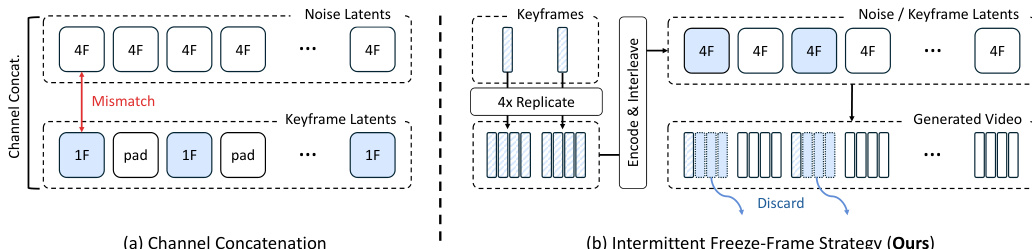
- Intermittent Freeze-Frame Strategy: To ensure compatibility with the 3D VAE's 4-frame temporal compression, keyframes are repeated four times during encoding. At inference, these repeated frames are discarded to recover the intended smooth video.
- Geometric Alignment: Depth maps and 6-DoF camera poses are estimated using Depth Anything V3. These are aligned to real-world metric scales using GPS metadata to ensure global coordinate consistency across the database.
- Retrieval Pipeline: For inference, the system performs a two-stage retrieval: nearest-neighbor search identifies candidate locations, followed by depth-based reprojection filtering to select references that provide sufficient pixel coverage for the target view.
Method
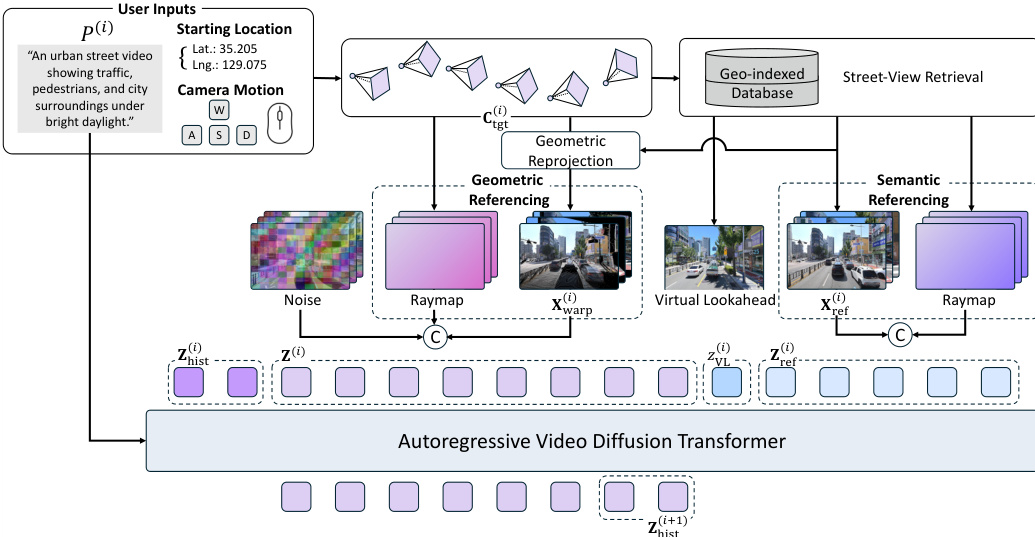
The proposed Street-View World Model (SWM) generates videos grounded in real cities using a retrieval-augmented autoregressive framework. The system builds upon a pretrained Diffusion Transformer (DiT) that operates in a latent space compressed from pixel-space frames via a 3D VAE. Generation proceeds autoregressively in chunks, where each chunk conditions on a text prompt, a target camera trajectory, and noisy latents. To ensure temporal continuity, subsequent chunks condition on history latents from the tail of the preceding chunk's output.
Refer to the framework diagram for the overall architecture. User inputs, including a starting location and camera motion, drive a geo-indexed database retrieval process. This retrieves relevant street-view images which serve dual purposes: acting as a Virtual Lookahead Sink for long-horizon stability and providing conditioning for geometric and semantic referencing to ground the generation in real-world geometry and appearance.
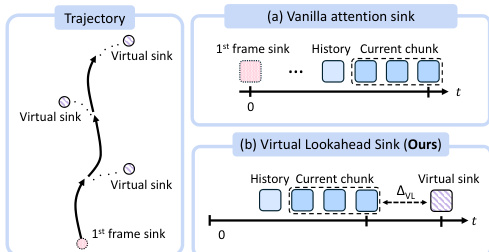
To mitigate error accumulation inherent in autoregressive generation over city-scale distances, the authors introduce a Virtual Lookahead Sink. As shown in the figure below, standard attention sinks typically anchor to the initial frame, which becomes increasingly irrelevant as the camera moves away. In contrast, the proposed method dynamically retrieves the nearest street-view image to the target trajectory's endpoint for each chunk. This image is treated as a virtual future destination and placed with a sufficient temporal gap from the current generation chunk. By providing a clean, error-free anchor ahead of the current frame, the model has a stable target to converge toward, ensuring the grounding remains relevant to the region being generated.
The model employs two complementary conditioning pathways to utilize the retrieved references. Geometric referencing reprojects a reference image into the target viewpoint via depth-based forward splatting, providing dense spatial layout cues. This warped video is encoded and channel-wise concatenated with the noisy target latent. Semantic referencing preserves appearance detail by injecting the original references into the transformer's latent sequence. Each reference is encoded into a single latent and concatenated with the target latents along the temporal axis. To handle dynamic objects that may differ between the reference and the generated scene, the authors leverage a cross-temporal pairing strategy, encouraging the model to focus on persistent scene structure rather than transient content.
For training data generation involving keyframes, the authors utilize an Intermittent Freeze-Frame strategy. Refer to the comparison diagram which contrasts this with standard channel concatenation. The channel concatenation baseline suffers from weak keyframe adherence because isolated keyframes do not form valid groups for the 3D VAE's temporal compression. The proposed strategy ensures each keyframe forms a complete 4-frame group matching the VAE's temporal stride by repeating the keyframe 4 consecutive times. During inference, the input keyframe is encoded into a single clean latent, which replaces the corresponding position in the noisy input latent at every diffusion step, ensuring exact keyframe conditioning.
Experiment
- Real-world grounded world simulation benchmarks validate that the model generates high-fidelity, dynamic videos consistent with actual urban layouts and target camera trajectories, outperforming existing world models that suffer from drift and structural collapse over long horizons.
- Ablation studies confirm that cross-temporal data pairing is essential for handling dynamic objects, while combining geometric and semantic referencing strategies ensures both structural alignment and visual fidelity.
- The Virtual Lookahead Sink design is critical for maintaining stability during extended generation, significantly reducing error accumulation and preserving scene coherence compared to conventional attention sink methods.
- Comparisons with static scene generators demonstrate that explicit modeling of scene dynamics is necessary to produce temporally coherent videos from real-world references, as static models fail to synthesize plausible motion.