Command Palette
Search for a command to run...
IndexCache: クロスレイヤーインデックスの再利用によるスパースアテンションの高速化
IndexCache: クロスレイヤーインデックスの再利用によるスパースアテンションの高速化
Yushi Bai Qian Dong Ting Jiang Xin Lv Zhengxiao Du Aohan Zeng Jie Tang Juanzi Li
概要
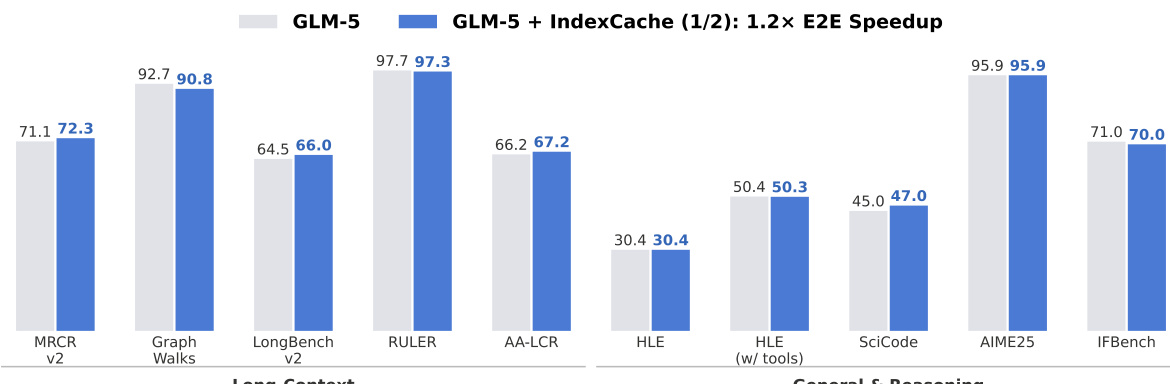
長文脈を伴うエージェント型ワークフローは、大規模言語モデル(LLM)の決定的なユースケースとして浮上しており、推論速度とサービスコストの両面からアテンション効率の向上が不可欠となっています。スパースアテンションはこの課題に効果的に対処する手法であり、DeepSeek Sparse Attention(DSA)はその代表的なプロダクショングレードのソリューションです。DSA は軽量なライトニングインデクサを用いて、各クエリに対して top-k の最も関連性の高いトークンを選択することで、コアアテンションの計算量を O(L^2) から O(Lk) に削減します。しかしながら、インデクサ自体は依然として O(L^2) の計算複雑性を持ち、連続する層間で生成される top-k 選択が極めて類似しているにもかかわらず、各層ごとに独立して実行される必要があります。本研究では、この層間冗長性を利用する IndexCache を提案します。IndexCache は、インデクサを独立して実行する少数の「フル層」と、最も近いフル層の top-k インデックスを単純に再利用する多数の「共有層」に層を分割することで、計算コストを削減します。本手法では、この構成を決定・最適化するための 2 つの相補的なアプローチを提案します。第一に、トレーニング不要な IndexCache は、校正データセット上の言語モデル損失を直接最小化するように、インデクサを保持する層を貪欲探索アルゴリズムで選択する手法であり、重みの更新を一切必要としません。第二に、トレーニングを考慮した IndexCache は、マルチ層蒸留損失を導入し、保持された各インデクサを、自身がサービス提供するすべての層の平均アテンション分布に対して訓練することで、単純な交互配置パターンであってもフルインデクサと同等の精度を達成可能にします。30B パラメータの DSA モデルを用いた実験結果によると、IndexCache はインデクサ計算量を 75% 削減しながらも品質低下を無視できるレベルに抑え、標準的な DSA に比べてプレフィル速度を最大 1.82 倍、デコード速度を最大 1.48 倍向上させることができました。これらの有望な結果は、プロダクション規模の GLM-5 モデルにおける予備実験(図 1)によってもさらに裏付けられています。
One-sentence Summary
Researchers from Tsinghua University and Z.ai introduce IndexCache, a technique that optimizes DeepSeek Sparse Attention by exploiting cross-layer redundancy to share token indices. This approach eliminates up to 75% of indexer computations in long-context workflows, delivering significant inference speedups without requiring model retraining or degrading output quality.
Key Contributions
- Long-context agentic workflows rely on DeepSeek Sparse Attention to reduce core attention complexity, yet the required lightning indexer still incurs quadratic O(L2) cost at every layer, creating a significant bottleneck for inference speed and serving costs.
- IndexCache addresses this redundancy by partitioning layers into Full layers that compute indices and Shared layers that reuse the nearest Full layer's top-k selections, utilizing either a training-free greedy search or a training-aware multi-layer distillation loss to optimize the configuration.
- Experiments on a 30B DSA model demonstrate that IndexCache removes 75% of indexer computations with negligible quality degradation, achieving up to 1.82x prefetch and 1.48x decode speedups while maintaining performance across nine long-context and reasoning benchmarks.
Introduction
Large language models face a critical bottleneck in long-context inference due to the quadratic complexity of self-attention, which sparse mechanisms like DeepSeek Sparse Attention (DSA) address by selecting only the most relevant tokens. While DSA reduces core attention costs, its reliance on a lightweight indexer at every layer still incurs quadratic overhead that dominates latency during the prefill stage. The authors leverage the observation that token selection patterns remain highly stable across consecutive layers to introduce IndexCache, a method that eliminates up to 75% of indexer computations by reusing indices from a small subset of retained layers. They propose both a training-free approach using greedy layer selection and a training-aware strategy with multi-layer distillation to maintain model quality while achieving significant speedups in long-context scenarios.
Method
The authors leverage the observation that sparse attention indexers exhibit significant redundancy across consecutive layers to reduce computational overhead. In standard DeepSeek Sparse Attention, a lightweight lightning indexer scores all preceding tokens at every layer to select the top-k positions. While this reduces core attention complexity from O(L2) to O(Lk), the indexer itself retains O(L2) complexity. IndexCache addresses this by partitioning the N transformer layers into two categories: Full layers and Shared layers. Full layers retain their indexers to compute fresh top-k sets, while Shared layers skip the indexer forward pass and reuse the index set from the nearest preceding Full layer. This design allows the system to eliminate a large fraction of the total indexer cost with minimal architectural changes.
To determine the optimal configuration of Full and Shared layers without retraining, the authors propose a training-free greedy search algorithm. The process begins with all layers designated as Full. The algorithm iteratively evaluates the language modeling loss on a calibration set for each candidate layer conversion. At each step, the layer whose conversion to Shared status results in the lowest loss increase is selected. This data-driven approach identifies which indexers are expendable based on their intrinsic importance to the model's performance rather than relying on uniform interleaving patterns.
For models trained from scratch or via continued pre-training, a training-aware approach further optimizes the indexer parameters for cross-layer sharing. Standard training distills the indexer against the attention distribution of its own layer. IndexCache generalizes this by introducing a multi-layer distillation loss. This objective encourages the retained indexer to predict a top-k set that is jointly useful for itself and all subsequent Shared layers it serves. The loss function is defined as:
LmultiI=j=0∑mm+11t∑DKL(pt(ℓ+j)qt(ℓ)),where pt(ℓ+j) represents the aggregated attention distribution at layer ℓ+j and qt(ℓ) is the indexer's output distribution. Theoretical analysis shows that this multi-layer loss produces gradients equivalent to distilling against the averaged attention distribution of all served layers. This ensures the indexer learns a consensus top-k selection that covers important tokens across the entire group of layers.
Experimental evaluations on a 30B parameter model demonstrate the efficiency gains achieved by removing indexer computations. The method successfully eliminates up to 75% of indexer costs while maintaining comparable quality. Performance metrics regarding prefill time and decode throughput are summarized below.
The results confirm that IndexCache delivers significant speedups in both prefill and decode phases without degrading model capabilities.
Experiment
- End-to-end inference experiments demonstrate that IndexCache significantly accelerates both prefill latency and decode throughput for long-context scenarios, with speedups increasing as context length grows, while maintaining comparable performance on general reasoning tasks.
- Training-free IndexCache evaluations reveal that greedy-searched sharing patterns are essential for preserving long-context accuracy at aggressive retention ratios, whereas uniform interleaving causes substantial degradation; however, general reasoning capabilities remain robust across most configurations.
- Training-aware IndexCache results show that retraining the model to adapt to index sharing eliminates the sensitivity to specific patterns, allowing simple uniform interleaving to match full-indexer performance and confirming the effectiveness of cross-layer distillation.
- Scaling experiments on a 744B-parameter model validate that the trends observed in smaller models hold true, with searched patterns providing stable quality recovery even at high sparsity levels.
- Analysis of cross-layer index overlap confirms high redundancy between adjacent layers but reveals that local similarity metrics fail to identify optimal sharing patterns, necessitating end-to-end loss-based search to prevent cascading errors in deep networks.