Command Palette
Search for a command to run...
Holi-Spatial:動画ストリームを包括的な 3D 空間知能へと進化させる
Holi-Spatial:動画ストリームを包括的な 3D 空間知能へと進化させる
概要
空間知性の探求は、本質的に大規模かつ微細な3次元データへのアクセスに依存する。しかし、既存のアプローチは、限られた数の手動注釈データセットから質問・回答(QA)対を生成することによって空間理解ベンチマークを構築する傾向にあり、生ウェブデータから新規の大規模3次元シーンを体系的に注釈する手法は採用されていない。その結果、拡張性は著しく制約され、また、これらの狭く精選されたデータセットに内在するドメインギャップによってモデル性能がさらに阻害される。本研究では、提案するデータキュレーションパイプラインを用いて、人間の介入なしに生動画入力から構築された、初の完全自動化・大規模・空間認識型マルチモーダルデータセット「Holi-Spatial」を提案する。Holi-Spatialは、レンダリング深度マップを伴う幾何学的に正確な3次元ガウススプラッティング(3DGS)再構成から、オブジェクトレベルおよび関係性に基づくセマンティック注釈に至るまで、多段階の空間的監督を提供し、対応する空間QA対も併せて包含する。体系的かつ原理的なパイプラインに従い、さらに「Holi-Spatial-4M」を構築した。これは、1万2千件の最適化された3DGSシーン、130万枚の2次元マスク、32万個の3次元バウンディングボックス、32万件のインスタンスキャプション、120万件の3次元グラウンディングインスタンス、および幾何学的・関係的・意味論的推論タスクにわたる120万件の空間QA対を含む、初の大規模かつ高品質な3次元セマンティックデータセットである。Holi-Spatialは、データキュレーションの品質において顕著な性能を示し、ScanNet、ScanNet++、DL3DVなどのデータセットにおいて、既存のフィードフォワード手法およびシーンごとの最適化手法を大幅に上回る結果を得た。さらに、本データセットを用いて空間推論タスクに対するビジョン・ランゲージモデル(VLM)のファインチューニングを行うことで、モデル性能の大幅な向上も実現した。
One-sentence Summary
Researchers from Shanghai AI Lab and multiple universities introduce Holi-Spatial, a fully automated pipeline that converts raw videos into high-fidelity 3D scenes using 3D Gaussian Splatting and VLMs. This approach overcomes manual annotation limits to create the Holi-Spatial-4M dataset, significantly boosting spatial reasoning and grounding in Vision-Language Models.
Key Contributions
- Holi-Spatial addresses the scarcity and imbalance of raw spatial data by introducing a fully automated framework that converts raw video streams into high-fidelity 3D geometry and holistic semantic annotations without requiring explicit 3D sensors or human-in-the-loop labeling.
- The method employs a three-stage pipeline combining geometric optimization with 3D Gaussian Splatting, image-level perception using open-vocabulary VLMs and SAM3, and scene-level refinement to merge instances and generate detailed captions and grounding pairs.
- Evaluation on benchmarks like ScanNet++ and DL3DV-10K demonstrates that the resulting Holi-Spatial-4M dataset improves multi-view depth estimation by up to 0.5 F1 and boosts 3D detection AP50 by 64%, while fine-tuning Qwen3-VL yields a 15% gain in 3D grounding accuracy.
Introduction
Spatial intelligence is essential for enabling large multimodal models to perceive and reason about the real 3D world, which is critical for applications like robotic manipulation, navigation, and augmented reality. Current approaches struggle with scalability because they depend on scarce, manually annotated 3D datasets or specialized scanning hardware, resulting in limited semantic coverage and high annotation costs. To overcome these barriers, the authors introduce Holi-Spatial, a fully automated framework that converts raw video streams into high-fidelity 3D geometry with holistic semantic annotations without requiring human labeling or explicit 3D sensors. This system unifies geometric optimization, image-level perception, and scene-level refinement to generate a massive, diverse dataset that significantly improves the performance of downstream 3D grounding and spatial reasoning tasks.
Dataset
-
Dataset Composition and Sources: The authors introduce Holi-Spatial-4M, a fully automated, large-scale dataset derived from raw video streams sourced from ScanNet, ScanNet++, and DL3DV-10K. This collection represents the first large-scale 3D semantic dataset constructed without human intervention, featuring over 12,000 optimized 3D Gaussian Splatting (3DGS) scenes.
-
Key Details for Each Subset: The dataset contains more than 4 million high-quality spatial annotations, including 1.3 million 2D instance masks, 320,000 3D bounding boxes, 320,000 detailed instance captions, and 1.2 million 3D grounding instances. It supports open-vocabulary diversity by leveraging Vision-Language Models to annotate a vast array of fine-grained indoor items rather than relying on a closed set of categories.
-
Usage in Model Training: The authors utilize the data to fine-tune Vision-Language Models for robust spatial reasoning. The 1.25 million generated Spatial Question-Answering pairs are structured into a comprehensive taxonomy covering Camera-centric tasks (such as rotation and movement direction) and Object-centric tasks (including object-to-object distance and size measurement).
-
Processing and Construction Details: The pipeline converts raw video inputs into holistic 3D spatial annotations through geometric optimization and scene-level refinement stages. This automated process generates multi-level supervision ranging from geometrically accurate 3DGS reconstructions with rendered depth maps to object-level and relational semantic annotations, ensuring a balanced distribution of tasks for holistic 3D space understanding.
Method
The authors present Holi-Spatial, a fully automated pipeline designed to transform raw video inputs into high-fidelity 3D geometry and comprehensive spatial annotations. As illustrated in the framework overview, the system supports multi-modal tasks ranging from 3D object detection and reconstruction to spatial reasoning and 3D grounding, ultimately generating over 4 million labels.

The curation framework consists of three core stages. The first stage, Geometric Optimization, distills raw video streams into robust 3D structures. The authors first employ Structure-from-Motion to resolve camera intrinsics and extrinsics, followed by leveraging a spatial foundation model to initialize a dense point cloud. To address noise and outliers inherent in feed-forward depth estimations, the method incorporates 3D Gaussian Splatting (3DGS) for per-scene optimization. This process integrates geometric regularization to enforce multi-view depth consistency, effectively eliminating large-scale floaters that would otherwise interfere with 3D bounding box generation.
The second stage, Image-level Perception, extracts spatially consistent object labels. Keyframes are uniformly sampled from the video stream, and a Vision-Language Model (VLM) generates captions while maintaining a dynamic class-label memory to ensure semantic consistency. Guided by these prompts, SAM3 performs open-vocabulary instance segmentation to produce binary masks and confidence scores.
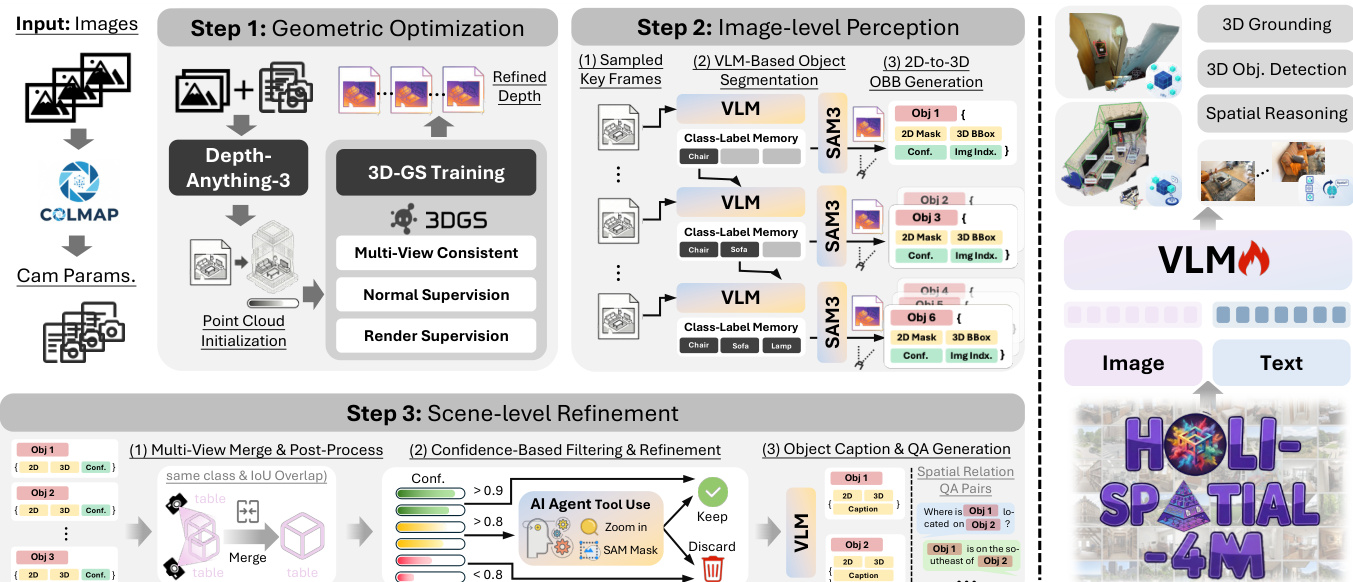
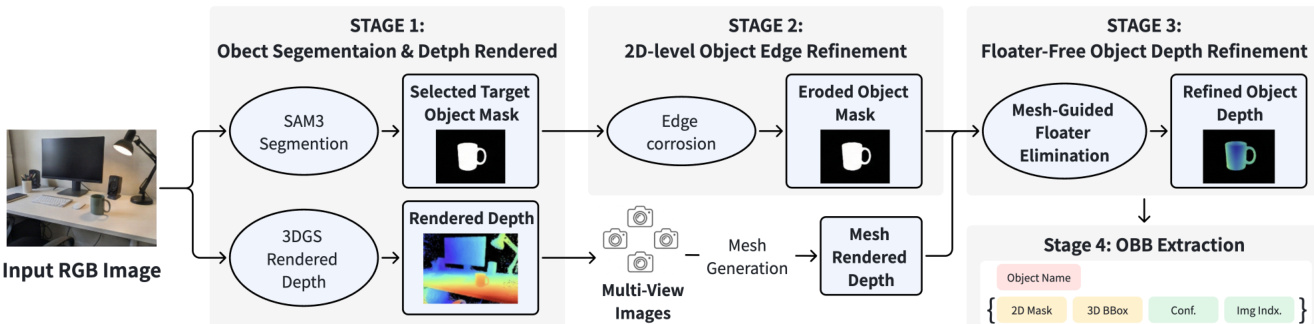
To lift these 2D masks into 3D, the authors unproject pixels using the refined depth map rendered from the optimized 3DGS. The 3D point P is calculated as: P=Dt(u)⋅K−1u~ where K is the camera intrinsic matrix and u~ represents the homogeneous coordinate. To mitigate depth floaters and boundary errors, a geometry-aware filtering strategy is applied. This involves eroding object masks near contours to remove 2D boundary errors and using multi-view-consistent mesh depth to filter 3D outliers, ensuring the estimated initial 3D Oriented Bounding Boxes (OBBs) are derived from a reliable geometry subset.
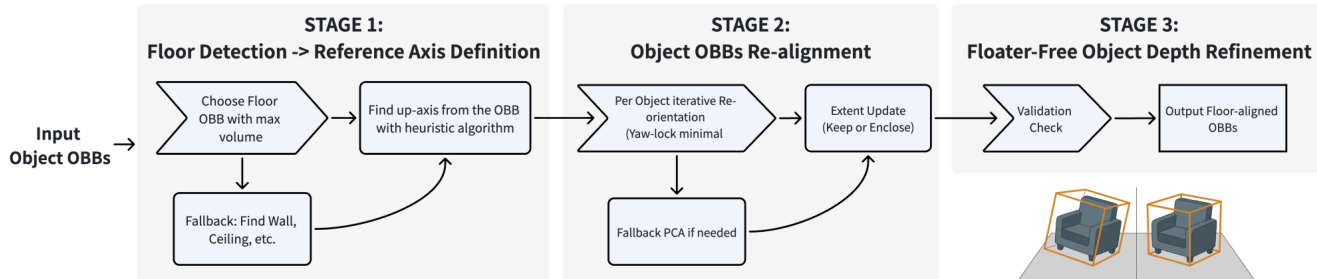
The final stage is Scene-level Refinement. This coarse-to-fine strategy consolidates redundant detections and verifies instances. First, spatial clustering merges instances that share the same category and have sufficient 3D overlap, defined by the condition: ci=cj∧IoU3D(Bi,Bj)>τmerge where τmerge is set to 0.2. Following merging, a post-processing module aligns the 3D OBBs to the global gravity axis. This involves detecting the floor or a fallback planar structure to infer a global up-axis and re-orienting the vertical axis of each instance.
Confidence-based filtering is then applied using a tri-level decision rule. Proposals with high confidence (sk≥0.9) are kept, while low-confidence noise (sk<0.8) is discarded. Ambiguous cases undergo verification by a VLM-based agent equipped with zoom-in and re-segmentation tools.

Upon establishing the final set of validated instances, the system generates dense semantic annotations. It retrieves the optimal source image for each instance and employs a large VLM to generate fine-grained captions and procedurally synthesize spatial QA pairs.
Experiment
- Framework evaluation demonstrates that the proposed method uniquely achieves high-quality performance across 3D object detection, 2D segmentation, and depth estimation simultaneously, outperforming single-modality baselines.
- Qualitative results show the framework produces cleaner 3D geometry with significantly fewer ghosting artifacts and floaters compared to prior works, while generating sharper segmentation boundaries and more accurate 3D bounding boxes.
- VLM finetuning on the curated dataset substantially improves spatial reasoning and 3D grounding capabilities, effectively eliminating viewpoint bias and enabling reliable object localization across different views and depths.
- Ablation studies confirm that geometric training with refined depth is critical for preventing instance fragmentation and false merging caused by occlusions or depth artifacts.
- The combination of confidence filtering and agent-based verification successfully balances precision and recall by removing false positives while recovering challenging instances that might otherwise be discarded.
- Multi-view merging is validated as essential for correcting image-level instance fragmentation and ensuring spatial consistency, leading to robust detection across diverse indoor scenes.