Command Palette
Search for a command to run...
LMEB:Long-horizon Memory Embedding Benchmark
LMEB:Long-horizon Memory Embedding Benchmark
概要
メモリ埋め込みは、OpenClaw などのメモリ拡張型システムにおいて不可欠であるが、現在のテキスト埋め込みベンチマークではその評価が十分に探求されていない。既存のベンチマークは従来のパッセージ検索に狭く焦点を当てており、断片的で文脈依存性が高く、時間的に遠隔な情報を含む長期的なメモリ検索タスクに対するモデルの能力を評価できていない。この課題に対処するため、本研究では Long-horizon Memory Embedding Benchmark(LMEB)を提案する。LMEB は、複雑な長期的なメモリ検索タスクにおける埋め込みモデルの能力を包括的に評価するフレームワークである。LMEB は、エピソード的、対話的、意味的、手続き的という 4 つのメモリタイプに跨り、AI 生成データと人間によるアノテーションデータの両方を含めて、22 のデータセットおよび 193 のゼロショット検索タスクを網羅している。これらのメモリタイプは、抽象化の度合いと時間的依存性において異なり、現実世界の多様な課題を反映するメモリ検索の異なる側面を捉えている。本研究では、パラメータ数が数億から百億規模に及ぶ 15 の広く利用されている埋め込みモデルを評価した。その結果、(1) LMEB は適切な難易度を提供する、(2) 大規模モデルが常に優れた性能を発揮するわけではない、(3) LMEB と MTEB は直交性を示す、という 3 つの知見が得られた。これらの結果は、すべてのメモリ検索タスクで卓越する汎用モデルへの収束がまだ達成されていないこと、ならびに従来のパッセージ検索における性能が長期的なメモリ検索に一般化しない可能性を示唆している。要約すると、LMEB は標準化され再現可能な評価フレームワークを提供することで、メモリ埋め込み評価における重要なギャップを埋め、長期的かつ文脈依存性の高いメモリ検索に対応するテキスト埋め込みのさらなる進展を促進するものである。LMEB は https://github.com/KaLM-Embedding/LMEB で公開されている。
One-sentence Summary
Researchers from Harbin Institute of Technology and Shenzhen Loop Area Institute introduce LMEB, a comprehensive benchmark evaluating memory embeddings across diverse long-horizon retrieval tasks. Unlike traditional benchmarks, LMEB reveals that larger models do not always excel, highlighting a critical gap in current text embedding capabilities for complex, context-dependent memory scenarios.
Key Contributions
- Current text embedding benchmarks fail to assess long-horizon memory retrieval involving fragmented, context-dependent, and temporally distant information, creating a gap in evaluating memory-augmented systems.
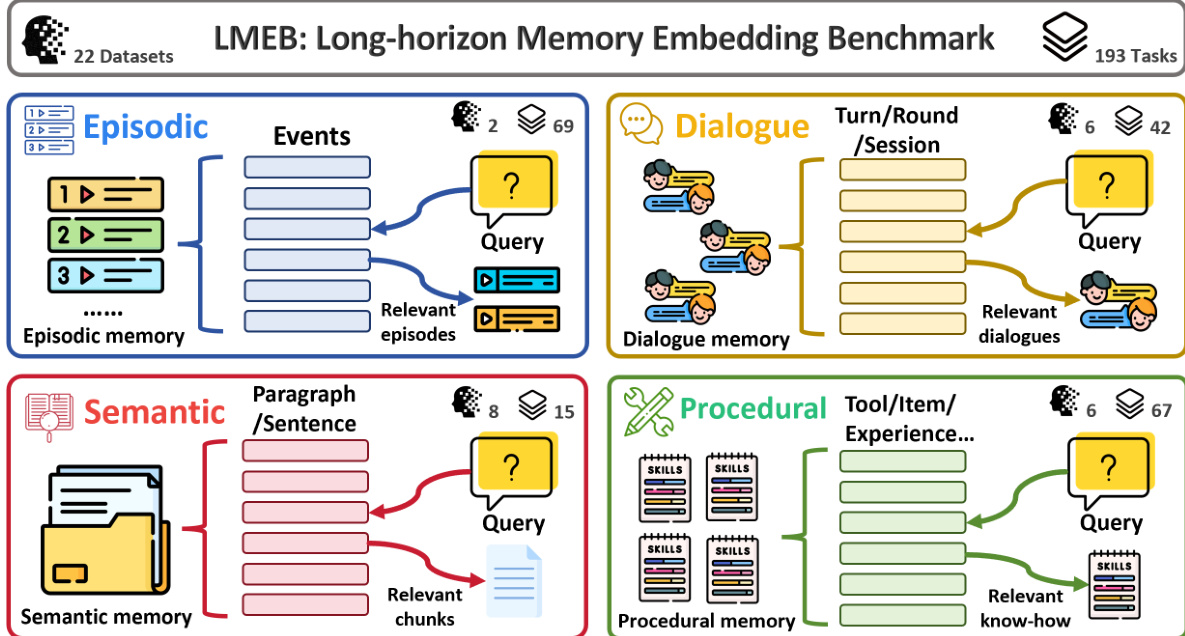
- The authors introduce the Long-horizon Memory Embedding Benchmark (LMEB), a comprehensive framework spanning 22 datasets and 193 zero-shot tasks across episodic, dialogue, semantic, and procedural memory types.
- Evaluation of 15 embedding models reveals that larger models do not consistently outperform smaller ones and that LMEB performance is orthogonal to traditional benchmarks like MTEB, indicating a lack of universal models for this domain.
Introduction
Text embedding models are critical for enabling efficient similarity search and powering downstream applications like retrieval and classification, yet current evaluation standards fall short in assessing their ability to handle long-horizon memory tasks. Existing benchmarks primarily focus on sentence-level similarity or standard retrieval across domains but rarely test scenarios requiring the synthesis of fragmented, context-dependent, and temporally distant evidence. To address this gap, the authors introduce LMEB, a specialized benchmark designed to evaluate how well embedding models support complex memory-centric retrieval that traditional metrics overlook.
Dataset
LMEB Dataset Overview
The authors introduce the Long-horizon Memory Embedding Benchmark (LMEB), a comprehensive framework designed to evaluate embedding models on complex, long-term memory retrieval tasks that traditional benchmarks like MTEB fail to address.
-
Dataset Composition and Sources
- The benchmark consolidates 22 English datasets into a unified schema, covering 193 zero-shot retrieval tasks.
- Data sources include a mix of AI-generated content and human-annotated material derived from crowdsourcing, academic papers, novels, and real-world logs.
- The datasets are categorized into four distinct memory types: Episodic, Dialogue, Semantic, and Procedural.
-
Key Details by Subset
- Episodic Memory: Focuses on recalling past events with temporal and spatial cues using datasets like EPBench (synthetic events) and KnowMeBench (autobiographical narratives).
- Dialogue Memory: Targets multi-turn context retention and user preferences using long-form conversations from LoCoMo, LongMemEval, REALTALK, and TMD.
- Semantic Memory: Assesses retrieval of stable, general knowledge from scientific papers (QASPER, SciFact), novels (NovelQA), and reports (ESG-Reports).
- Procedural Memory: Evaluates the retrieval of skills and action sequences using API documentation (Gorilla, ToolBench) and task trajectories (ReMe, DeepPlanning).
-
Usage in Model Evaluation
- The authors utilize the entire collection for zero-shot evaluation, meaning models are tested on their pre-trained capabilities without task-specific fine-tuning.
- The benchmark serves as a diagnostic tool to measure performance across varying levels of abstraction and temporal dependency.
- Results indicate that LMEB and MTEB are orthogonal, suggesting that high performance in traditional passage retrieval does not guarantee success in long-horizon memory tasks.
-
Processing and Construction Details
- Unified Schema: All resources are converted into a standard Information Retrieval format containing
queries.jsonl,corpus.jsonl,qrels.csv, and an optionalcandidates.jsonl. - Temporal Anchoring: For queries with relative time expressions, the authors append explicit time anchors (e.g., "Current time: 11:17 AM on Sunday") to disambiguate references.
- Metadata Encoding: Timestamps and hierarchical structures (such as session or turn levels in dialogues) are preserved in the title or text fields to support time-sensitive and scope-specific queries.
- Text Segmentation: Long documents in semantic tasks, such as novels and research papers, are segmented into passages or sentences using tools like
semchunkwith a chunk size of 256 tokens. - Candidate Constraints: An optional candidates file restricts retrieval to specific memory scopes, such as a single conversation history, rather than the full corpus.
- Unified Schema: All resources are converted into a standard Information Retrieval format containing
Method
The authors introduce the Long-horizon Memory Embedding Benchmark (LMEB) to systematically evaluate memory capabilities across diverse scenarios. The framework categorizes tasks into four distinct memory types: Episodic, Dialogue, Semantic, and Procedural. Each type involves a query retrieving relevant information from a specific memory store.
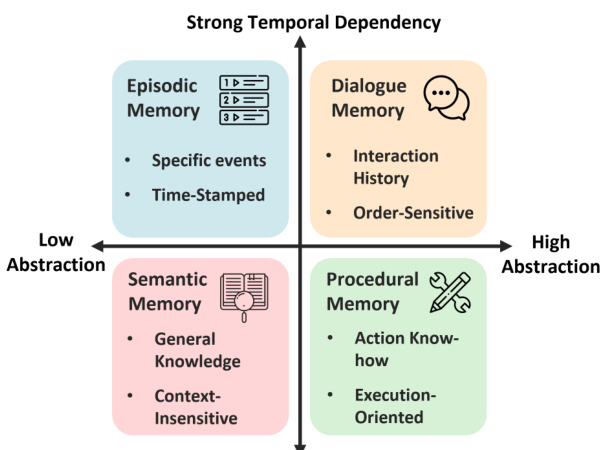
To structure these evaluations, the authors define a taxonomy based on abstraction and temporal dependency. As shown in the figure below, Episodic and Dialogue memories exhibit strong temporal dependencies, while Semantic and Procedural memories vary in abstraction levels.
To ensure embeddings follow instructions during downstream tasks, the authors prepend specific task instructions to the queries. The instructed query is formulated as follows:
qinst=Instruct: {task instruction} \nQuery: q
where q denotes the original query and qinst is the instructed query. This mechanism allows the model to adapt its retrieval and processing based on the specific requirements of the task.
Experiment
- The LMEB benchmark evaluation validates a unified pipeline for testing embedding models across episodic, dialogue, semantic, and procedural memory tasks, demonstrating that the benchmark offers a balanced difficulty level that effectively challenges current models.
- Experiments comparing models of varying scales reveal that larger parameter counts do not guarantee superior performance, as smaller models often achieve comparable or better results depending on architecture and training data.
- Analysis of task instructions shows that their impact on retrieval performance is model-dependent, with some models benefiting from instructions while others perform better without them or remain unaffected.
- Correlation studies confirm that LMEB evaluates capabilities orthogonal to traditional benchmarks like MTEB, particularly showing that strong performance in standard passage retrieval does not generalize well to complex episodic or dialogue memory scenarios.