Command Palette
Search for a command to run...
DreamVideo-Omni:潜在アイデンティティ強化学習によるオムニモーション制御マルチサブジェクト動画カスタマイズ
DreamVideo-Omni:潜在アイデンティティ強化学習によるオムニモーション制御マルチサブジェクト動画カスタマイズ
概要
大規模拡散モデルは動画合成の分野に革命的な変化をもたらしましたが、複数の被写体の同一性と多粒度の動きを同時に精密に制御することは依然として大きな課題です。このギャップを埋めようとする最近の試みは、動きの粒度の限界、制御の曖昧さ、および同一性の劣化に悩まされ、同一性保持と動き制御の面で最適ではない性能を示しています。本研究では、段階的な2段階学習パラダイムを通じて、複数の被写体のカスタマイズと包括的な動き制御を調和させる統合フレームワーク「DreamVideo-Omni」を提案します。第一段階では、被写体の外観、グローバルな動き、ローカルなダイナミクス、およびカメラ移動を含む包括的な制御信号を統合し、これらを共同で学習します。堅牢かつ精密な制御性を確保するため、異種入力間の調整を可能にする条件感知型3D回転位置埋め込みを導入するとともに、グローバルな動きガイダンスを強化する階層的動き注入戦略を採用しました。さらに、複数被写体間の曖昧さを解消するため、グループ埋め込みと役割埋め込みを導入し、動き信号を特定の同一性に明示的にアラインすることで、複雑なシーンを独立して制御可能なインスタンスへと効果的に分解します。第二段階では、同一性の劣化を緩和するため、事前学習済みの動画拡散バックボーン上で潜在空間における同一性報酬モデルを学習させる「潜在同一性報酬フィードバック学習パラダイム」を設計しました。これにより、潜在空間内で動きを考慮した同一性報酬を提供し、人間の嗜好に合致した同一性保持を優先的に実現します。我々が編成した大規模データセットと、複数被写体および包括的動き制御の評価を目的とした包括的なベンチマーク「DreamOmni Bench」に支えられ、DreamVideo-Omniは、高精度な制御性を備えた高品質な動画生成において卓越した性能を示しました。
One-sentence Summary
Researchers from Alibaba and HKUST propose DreamVideo-Omni, a unified framework that achieves precise multi-subject video customization with omni-motion control by introducing group embeddings to resolve ambiguity and a latent identity reward model to preserve fidelity during complex movements.
Key Contributions
- DreamVideo-Omni addresses the critical challenge of simultaneously preserving multiple subject identities while enabling precise, multi-granularity motion control, a task where existing methods suffer from limited signal types, control ambiguity, and identity degradation.
- The framework introduces a progressive two-stage training paradigm featuring condition-aware 3D rotary positional embeddings and group-role embeddings to explicitly anchor heterogeneous motion signals to specific subjects, alongside a latent identity reward model that aligns generation with human preferences to prevent identity loss.
- Validated on a curated large-scale dataset and the comprehensive DreamOmni Bench, the method demonstrates superior performance in generating high-quality videos with harmonious multi-subject customization and robust omni-motion control compared to prior approaches.
Introduction
Video diffusion models have transformed synthesis, yet real-world applications demand simultaneous preservation of multiple subject identities and precise control over global motion, local dynamics, and camera movement. Prior approaches struggle with this dual objective because they often rely on single motion signals, fail to explicitly bind motion to specific subjects causing ambiguity, and suffer from identity degradation when reconciling static appearance with dynamic movement. The authors leverage a unified framework called DreamVideo-Omni that employs a progressive two-stage training paradigm to resolve these issues. They introduce architectural innovations like group and role embeddings to disambiguate multi-subject signals and a latent identity reward feedback learning system that aligns optimization with human preferences to maintain identity fidelity during complex motion.
Dataset
-
Dataset Composition and Sources: The authors construct a large-scale, densely annotated video dataset specifically for the supervised fine-tuning (SFT) stage of DreamVideo-Omni. This corpus is designed to support multi-subject customization and comprehensive motion control, distinguishing it from previous datasets that often lack these combined capabilities.
-
Key Details for Each Subset:
- Training Dataset: An automated pipeline filters raw video data to ensure high quality and significant temporal dynamics. It includes videos with precise annotations for global bounding boxes, subject masks, and motion trajectories.
- DreamOmni Bench: A separate evaluation set comprising 1,027 high-quality real-world videos sourced independently from the training data to ensure zero-shot assessment. This benchmark is split into 436 single-subject and 591 multi-subject samples covering humans, animals, general objects, and faces.
-
Data Usage and Processing Pipeline:
- Motion Filtering: The authors use RAFT to estimate dense optical flow and discard videos with low motion magnitude to focus on meaningful dynamics.
- Subject Discovery: Semantic tags are extracted via RAM++, refined by Qwen3 Max to identify significant moving subjects, and then used by Qwen3-VL to generate detailed captions.
- Spatiotemporal Annotation: Grounding DINO detects bounding boxes, which feed into SAM 2 to create precise binary segmentation masks. CoTracker3 performs dense point tracking, classifying trajectories as either object or camera motion based on the masks.
- Reference Image Construction: To prevent trivial copy-paste solutions and enable zero-shot customization, reference images are sampled from frames temporally disjoint from the training clip, isolated using segmentation masks, and subjected to extensive data augmentation.
-
Benchmark Construction and Filtering: For the DreamOmni Bench, the authors apply manual filtering to retain high-resolution videos with meaningful motion while explicitly excluding static content, text overlays, and watermarks. The resulting dataset provides a unified evaluation framework for identity preservation and motion control precision using metrics for bounding box and trajectory accuracy.
Method
The authors propose DreamVideo-Omni, a unified video diffusion transformer framework designed for harmonious multi-subject customization with omni-motion control. The system follows a progressive two-stage training paradigm to resolve the conflict between identity preservation and complex motion control. Refer to the framework diagram for the overall architecture, which illustrates the transition from supervised fine-tuning to reinforcement learning.
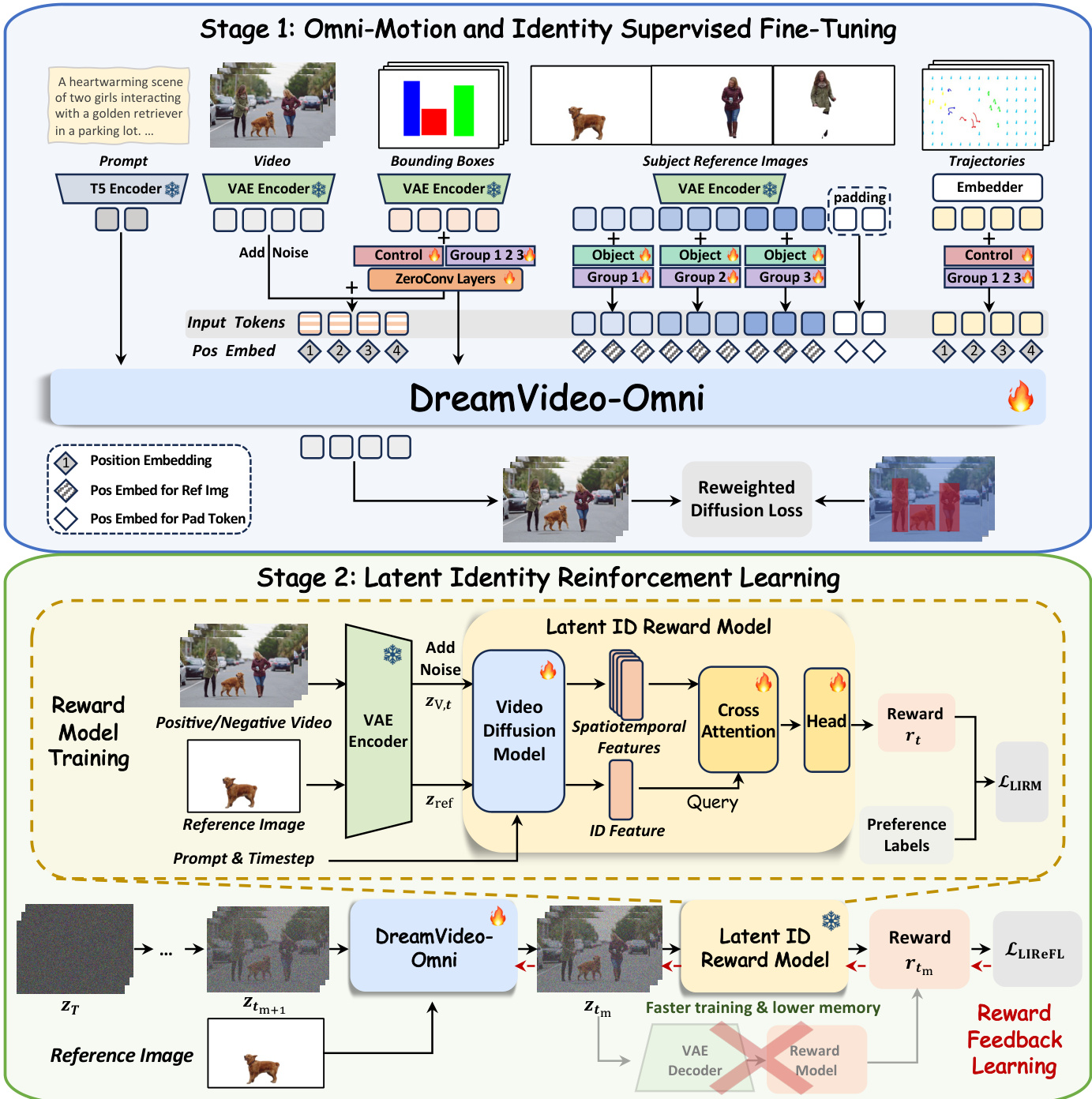
In the first stage, Omni-Motion and Identity Supervised Fine-Tuning, the model is trained on a comprehensive set of tasks including single- and multi-subject customization, global and local object motion control, and camera movement. To enable precise composition, the authors craft four compact conditioning signals. The data preparation for these signals involves a rigorous automated pipeline.
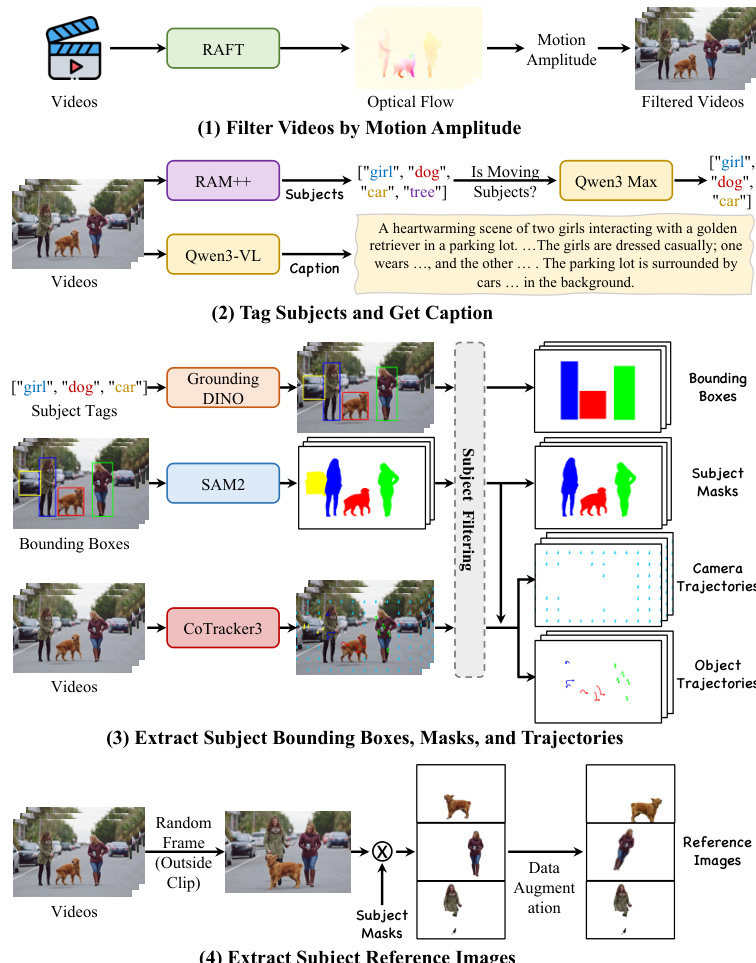
This pipeline filters videos by motion amplitude, tags subjects, and extracts bounding boxes, masks, and trajectories. The resulting comprehensive annotations provide detailed captions, bounding boxes, trajectories, and subject masks for training.

The model architecture employs a condition-aware 3D Rotary Positional Embedding (RoPE) to process heterogeneous inputs. Video frame tokens receive sequential temporal indices, while reference image tokens are assigned a shared distinct time index to decouple them from the video sequence. Trajectory tokens inherit the video frame indices to ensure spatiotemporal alignment. To mitigate control ambiguity, the authors introduce group and role embeddings. A unique group embedding binds a reference subject to its corresponding bounding box and trajectories, while role embeddings distinguish between visual appearance assets and motion control guidance.
For conditioning signal injection, the authors implement a hierarchical motion injection strategy for bounding boxes. The bounding box latents are added to both the noisy input latents and the output of each DiT block via learnable, layer-specific zero-convolutions, formulated as:
h0=zt+Zin(zbox),hl+1=Blockl(hl)+Zl(zbox).where zt and zbox are the input noisy video latents and bounding box latents, respectively. Local object motion and camera movement are controlled via point-wise trajectories using a hybrid sampling strategy that alternates between random grid sampling and object-aware sampling. The training objective utilizes a reweighted diffusion loss that amplifies contributions within bounding boxes to enhance subject learning:
Lsft=Ez,ϵ,C,t[(1+λ1M)⋅∣∣ϵ−ϵθ(zt,C,t)∣∣22],where C represents the comprehensive conditioning set and M denotes the binary bounding box masks.
The second stage, Latent Identity Reinforcement Learning, addresses the insufficiency of low-level reconstruction losses for preserving fine-grained appearance details. The authors introduce a Latent Identity Reward Model (LIRM) that operates directly in latent space to mitigate computational overhead. The LIRM architecture comprises a video diffusion model backbone, an identity cross-attention layer, and a reward prediction head. The identity features from the reference image serve as the query Q to attend to the video's spatiotemporal features acting as key K and value V:
hattn=Attention(Q,K,V)=Softmax(dQK⊤)V,The resulting representation is passed through a lightweight MLP head to predict the scalar reward rt:
rt=H(hattn+Q).Leveraging this model, the authors perform Latent Identity Reward Feedback Learning (LIReFL). This approach bypasses the expensive VAE decoder by performing reward feedback directly on intermediate noisy latents. The model executes a single gradient-enabled denoising step to derive the predicted latent ztm, which is evaluated by the frozen LIRM. The reinforcement loss is formulated to maximize the expected identity fidelity:
LLIReFL=−Etm,cixt,zref[rtm].To prevent reward hacking, the final training objective combines the supervised SFT objective with the reward feedback loss:
L=Lsft+λ2LLIReFL,where λ2 controls the strength of the reward feedback. This balanced strategy ensures the model aligns with human identity preferences while preserving precise motion control.
Experiment
- Joint subject customization and motion control experiments validate that the proposed framework successfully balances high-fidelity identity preservation with precise trajectory adherence, outperforming baselines that struggle with identity degradation or motion drift.
- Pure subject customization evaluations confirm the method's ability to prevent identity mixing and leakage in multi-subject scenarios while maintaining superior text alignment and facial details compared to existing approaches.
- Motion control benchmarks demonstrate that the model achieves significantly higher spatial layout accuracy and trajectory precision than larger parameter models, proving its efficiency and robustness in complex movement tasks.
- Emergent capability tests reveal that the unified training paradigm enables zero-shot Image-to-Video generation and first-frame-conditioned trajectory control without requiring task-specific fine-tuning.
- Ablation studies establish that condition-aware 3D RoPE, group and role embeddings, and hierarchical bounding box injection are critical components, while the latent identity reinforcement learning stage is essential for refining identity details and avoiding reward hacking.