Command Palette
Search for a command to run...
Flash-KMeans:高速かつメモリ効率に優れた厳密 K-Means
Flash-KMeans:高速かつメモリ効率に優れた厳密 K-Means
概要
k-means は歴史的に、主にオフライン処理のプリミティブとして位置づけられており、データセットの整理や埋め込みの前処理に用いられることが多く、オンラインシステムにおける第一級のコンポーネントとしては扱われてこなかった。本研究では、この古典的アルゴリズムを現代の AI システム設計の観点から再考し、k-means をオンラインプリミティブとして実現可能にする。我々は、既存の k-means の GPU 実装が、理論的なアルゴリズム計算量ではなく、低レベルのシステム制約によって本質的にボトルネックに直面している点を指摘する。具体的には、割り当てステージにおいて、高帯域幅メモリ(HBM)への N×K 距離行列の明示的な大規模な材料化により、深刻な I/O ボトルネックが生じている。同時に、セントロイド更新ステージでは、不規則でスキャッター型のトークン集約に起因するハードウェアレベルのアトミック書き込み競合によって、著しいペナルティが課されている。この性能ギャップを埋めるため、我々は現代の GPU ワークロード向けに I/O 感知かつ競合フリーな k-means 実装「flash-kmeans」を提案する。Flash-kmeans は、カーネルレベルで 2 つの中核的革新を導入する。(1) FlashAssign:距離計算とオンライン argmin を融合させ、中間メモリの材料化を完全に回避する。(2) ソート逆更新:逆マッピングを明示的に構築し、高競合のアトミックスキャッターを、高帯域幅のセグメントレベル局所化集約に変換する。さらに、チャンク化ストリームのオーバーラップやキャッシュ感知コンパイルヒューリスティクスなど、アルゴリズムとシステムの共設計を統合し、実用的な展開可能性を確保している。NVIDIA H200 GPU 上での広範な評価により、flash-kmeans は最良のベースラインに対して最大 17.9 倍のエンドツーエンド速度向上を達成し、業界標準ライブラリである cuML および FAISS をそれぞれ 33 倍および 200 倍以上上回る性能を示したことが確認された。
One-sentence Summary
Researchers from UC Berkeley, MIT, and UT Austin propose flash-kmeans, an IO-aware GPU implementation that eliminates distance matrix materialization and atomic contention via FlashAssign and sort-inverse update, delivering up to 17.9x speedup for scalable online clustering in modern AI workloads.
Key Contributions
- Existing GPU implementations of k-means are hindered by severe IO bottlenecks from materializing massive distance matrices and hardware-level atomic contention during centroid updates, preventing their use as efficient online primitives.
- Flash-KMeans addresses these issues with two core kernel innovations: FlashAssign, which fuses distance computation with online argmin to bypass intermediate memory storage, and sort-inverse update, which transforms high-contention atomic scatters into localized reductions.
- Evaluations on NVIDIA H200 GPUs show up to a 17.9x end-to-end speedup over best baselines and over 200x improvement compared to FAISS, while enabling seamless out-of-core execution on up to one billion points.
Introduction
K-means clustering is evolving from an offline data processing tool into a critical online primitive for modern AI systems, including vector quantization, sparse routing in large language models, and generative video pipelines. Despite this shift, existing GPU implementations fail to meet latency requirements because they remain bottlenecked by hardware constraints rather than algorithmic complexity. Prior approaches suffer from severe memory bandwidth waste due to the explicit materialization of massive distance matrices and suffer from hardware-level serialization caused by atomic write contention during centroid updates. To address these issues, the authors introduce Flash-KMeans, an exact and IO-aware implementation that fuses distance computation with online argmin to bypass intermediate memory storage and replaces irregular atomic scatters with a sort-inverse update strategy for efficient aggregation. This system-level redesign eliminates key bottlenecks, delivering up to 17.9 times end-to-end speedup over baselines while enabling scalable execution on datasets exceeding one billion points.
Method
The authors introduce flash-kmeans, a highly optimized implementation designed to overcome the severe memory and synchronization bottlenecks inherent in standard GPU-based k-means clustering. The methodology focuses on restructuring the execution dataflow to eliminate IO overheads and resolve write-side contention without altering the underlying mathematical objective.
FlashAssign: Materialization-Free Assignment
To address the memory wall caused by materializing the massive distance matrix D∈RN×K, the authors propose FlashAssign. This module fuses the distance computation and row-wise reduction into a single streaming procedure. Instead of writing the full distance matrix to High Bandwidth Memory (HBM) and reading it back, FlashAssign maintains running states for the minimum distance and corresponding centroid index directly in registers.
The process utilizes an online argmin update. For each data point, the kernel scans centroids in tiles. It computes local distances on-chip, identifies the local minimum within the tile, and compares it with the running minimum to update the global assignment. This approach ensures that the N×K distance matrix is never explicitly constructed in memory.
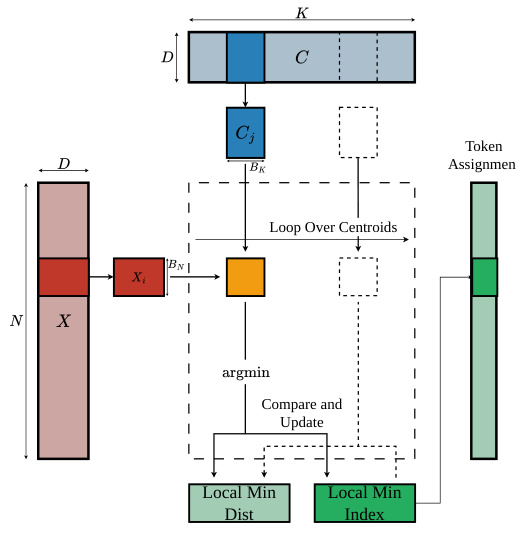
As illustrated in the framework diagram above, the algorithm loops over centroid tiles. For each point Xi, it computes distances against a centroid block Cj, finds the local minimum, and updates the global minimum index. By employing two-dimensional tiling and asynchronous prefetching, the kernel hides memory latency while ensuring that the IO complexity is reduced from O(NK) to O(Nd+Kd).
Sort-Inverse Update: Low-Contention Aggregation
In the centroid update stage, standard implementations suffer from severe atomic write contention because multiple threads frequently attempt to update the same centroid simultaneously using scatter-style atomic additions. To resolve this, the authors propose the sort-inverse update strategy.
The core idea is to transform the token-to-cluster update into a cluster-to-token gather operation. The system first applies an argsort operation to the assignment vector a to obtain a permutation index. This reorders the tokens such that identical cluster IDs are grouped into contiguous segments.
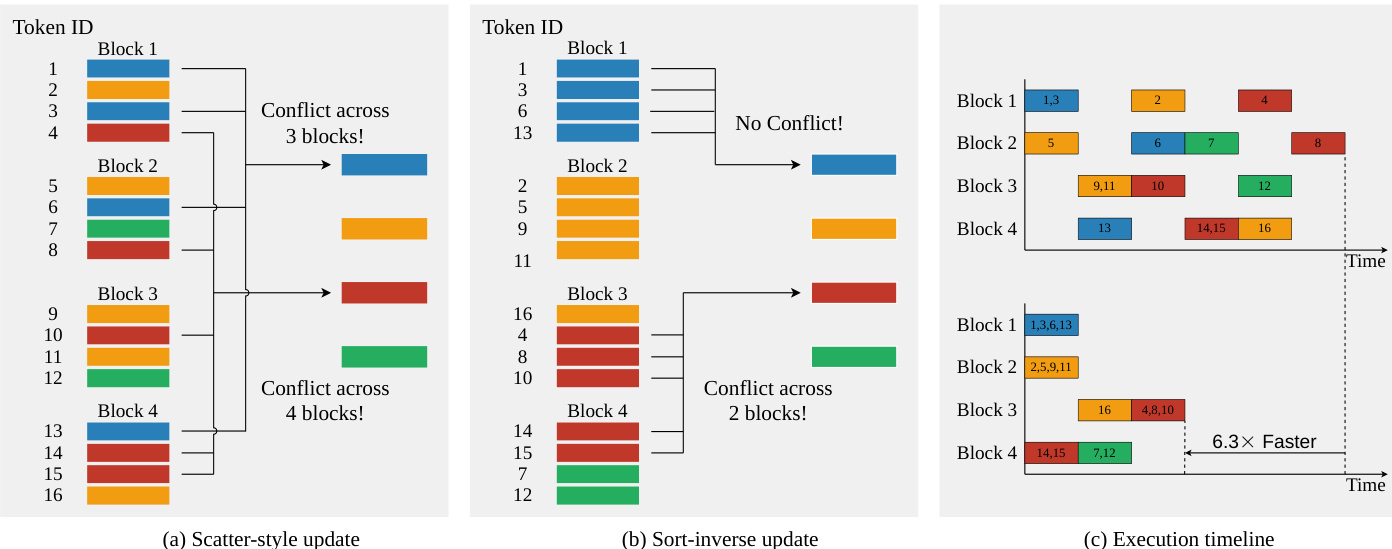
The figure below contrasts the standard scatter-style update with the proposed sort-inverse approach. In the standard method (a), tokens are scattered irregularly, causing conflicts across multiple blocks. In the sort-inverse method (b), tokens are sorted by cluster ID, creating contiguous segments. This allows each Cooperative Thread Array (CTA) to process a chunk of the sorted sequence, gathering features from the original matrix and accumulating partial sums entirely in fast on-chip memory. Global atomic operations are only issued at segment boundaries.
This reorganization drastically reduces the number of atomic operations from O(Nd) to O((K+⌈N/BN⌉)d). As shown in the execution timeline (c), this eliminates the frequent stalls caused by atomic lock contention, enabling contention-free memory writes and significantly accelerating the reduction phase.
Algorithm-System Co-design
To ensure deployability in real systems, flash-kmeans incorporates several system-level optimizations. For large-scale data that exceeds GPU memory, the authors implement a chunked stream overlap design. This partitions data into chunks and uses CUDA streams to coordinate asynchronous host-to-device transfers with computation, following a double-buffer streaming pattern. Additionally, a cache-aware compile heuristic is employed to select high-quality kernel configurations based on hardware characteristics and problem shape, minimizing the time-to-first-run overhead typically associated with exhaustive tuning.
Experiment
- Efficiency evaluations demonstrate that flash-kmeans consistently outperforms optimized baselines across diverse workloads, achieving up to 17.9× speedup in compute-intensive scenarios and 15.3× in highly batched settings while preventing out-of-memory failures in memory-intensive regimes.
- Kernel-level analysis confirms that custom FlashAssign and Sort-Inverse Update modules effectively eliminate distance matrix materialization and atomic contention bottlenecks, delivering up to 21.2× and 6.3× speedups respectively.
- Large-scale out-of-core experiments validate that the system successfully processes datasets up to one billion points by bounding peak memory usage, resulting in 6.3× to 10.5× faster iteration times compared to the most robust existing baseline.
- Algorithm-system co-design tests show that a cache-aware compile heuristic reduces configuration search time by up to 175× compared to exhaustive tuning while maintaining near-optimal runtime performance with negligible degradation.